Whether you implement a neural network yourself or you use a built in library for neural network learning, it is of paramount importance to understand the significance of a sigmoid function. The sigmoid function is the key to understanding how a neural network learns complex problems. This function also served as a basis for discovering other functions that lead to efficient and good solutions for supervised learning in deep learning architectures.
In this tutorial, you will discover the sigmoid function and its role in learning from examples in neural networks.
After completing this tutorial, you will know:
- The sigmoid function
- Linear vs. non-linear separability
- Why a neural network can make complex decision boundaries if a sigmoid unit is used
Let’s get started.

A Gentle Introduction to sigmoid function. Photo by Mehreen Saeed, some rights reserved.
Tutorial Overview
This tutorial is divided into 3 parts; they are:
- The sigmoid function
- The sigmoid function and its properties
- Linear vs. non-linearly separable problems
- Using a sigmoid as an activation function in neural networks
Sigmoid Function
The sigmoid function is a special form of the logistic function and is usually denoted by σ(x) or sig(x). It is given by:
σ(x) = 1/(1+exp(-x))
Properties and Identities Of Sigmoid Function
The graph of sigmoid function is an S-shaped curve as shown by the green line in the graph below. The figure also shows the graph of the derivative in pink color. The expression for the derivative, along with some important properties are shown on the right.
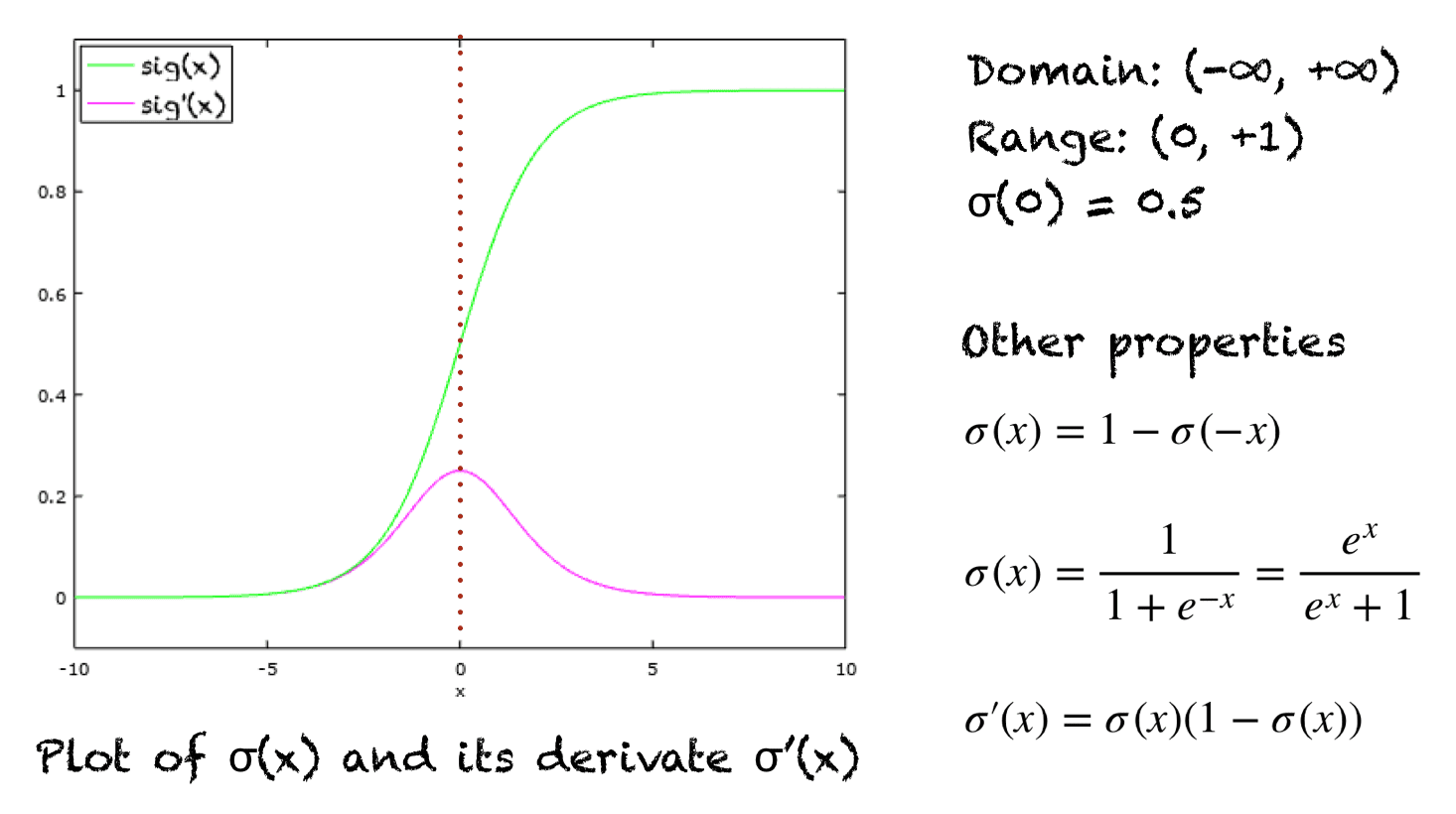
Graph of the sigmoid function and its derivative. Some important properties are also shown.
A few other properties include:
- Domain: (-∞, +∞)
- Range: (0, +1)
- σ(0) = 0.5
- The function is monotonically increasing.
- The function is continuous everywhere.
- The function is differentiable everywhere in its domain.
- Numerically, it is enough to compute this function’s value over a small range of numbers, e.g., [-10, +10]. For values less than -10, the function’s value is almost zero. For values greater than 10, the function’s values are almost one.
The Sigmoid As A Squashing Function
The sigmoid function is also called a squashing function as its domain is the set of all real numbers, and its range is (0, 1). Hence, if the input to the function is either a very large negative number or a very large positive number, the output is always between 0 and 1. Same goes for any number between -∞ and +∞.
Sigmoid As An Activation Function In Neural Networks
The sigmoid function is used as an activation function in neural networks. Just to review what is an activation function, the figure below shows the role of an activation function in one layer of a neural network. A weighted sum of inputs is passed through an activation function and this output serves as an input to the next layer.
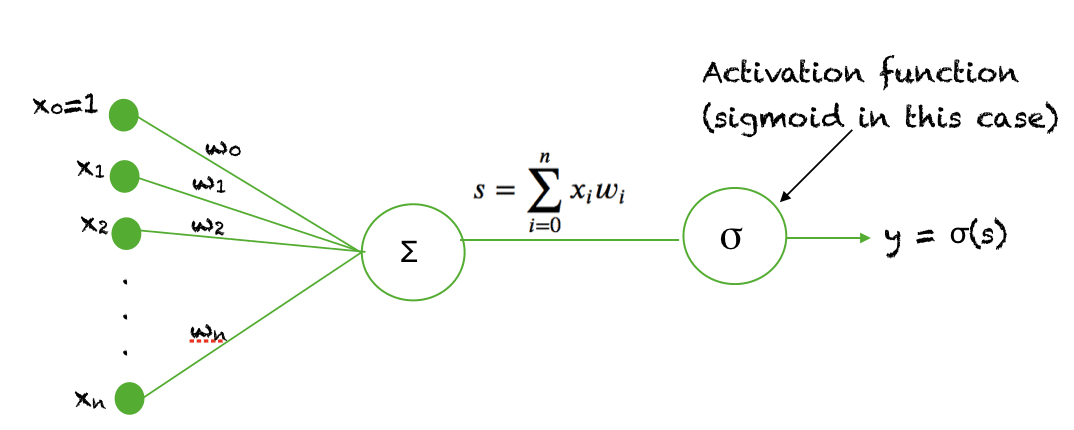
A sigmoid unit in a neural network
When the activation function for a neuron is a sigmoid function it is a guarantee that the output of this unit will always be between 0 and 1. Also, as the sigmoid is a non-linear function, the output of this unit would be a non-linear function of the weighted sum of inputs. Such a neuron that employs a sigmoid function as an activation function is termed as a sigmoid unit.
Linear Vs. Non-Linear Separability?
Suppose we have a typical classification problem, where we have a set of points in space and each point is assigned a class label. If a straight line (or a hyperplane in an n-dimensional space) can divide the two classes, then we have a linearly separable problem. On the other hand, if a straight line is not enough to divide the two classes, then we have a non-linearly separable problem. The figure below shows data in the 2 dimensional space. Each point is assigned a red or blue class label. The left figure shows a linearly separable problem that requires a linear boundary to distinguish between the two classes. The right figure shows a non-linearly separable problem, where a non-linear decision boundary is required.
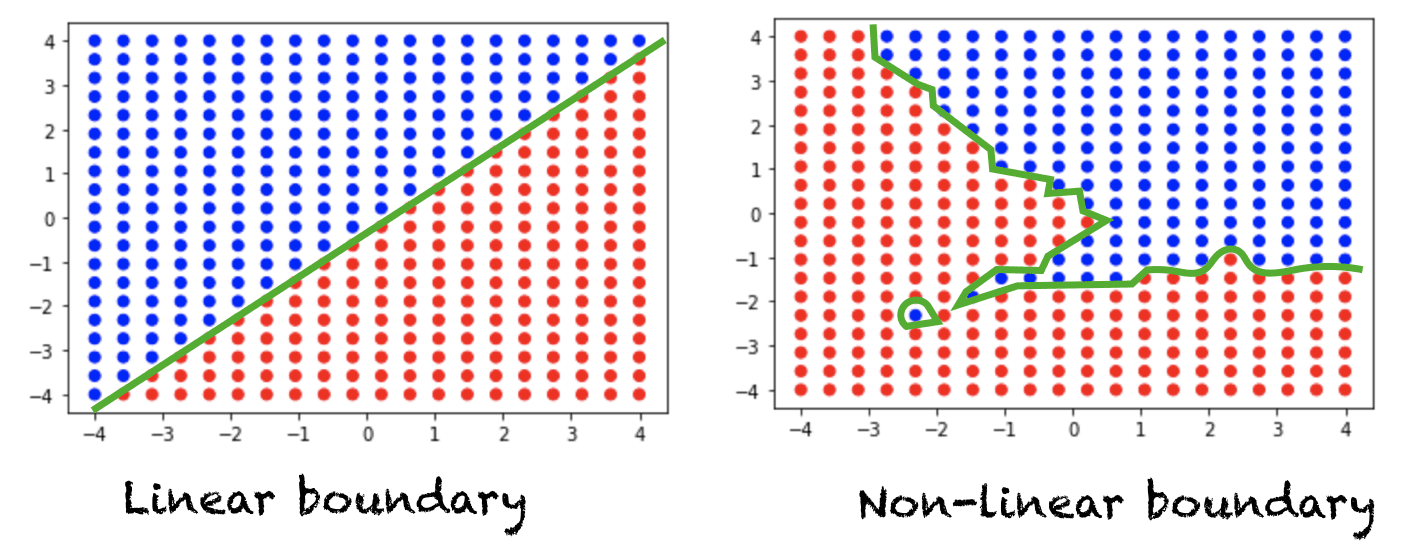
Linera Vs. Non-Linearly separable problems
For three dimensional space, a linear decision boundary can be described via the equation of a plane. For an n-dimensional space, the linear decision boundary is described by the equation of a hyperplane.
Why The Sigmoid Function Is Important In Neural Networks?
If we use a linear activation function in a neural network, then this model can only learn linearly separable problems. However, with the addition of just one hidden layer and a sigmoid activation function in the hidden layer, the neural network can easily learn a non-linearly separable problem. Using a non-linear function produces non-linear boundaries and hence, the sigmoid function can be used in neural networks for learning complex decision functions.
The only non-linear function that can be used as an activation function in a neural network is one which is monotonically increasing. So for example, sin(x) or cos(x) cannot be used as activation functions. Also, the activation function should be defined everywhere and should be continuous everywhere in the space of real numbers. The function is also required to be differentiable over the entire space of real numbers.
Typically a back propagation algorithm uses gradient descent to learn the weights of a neural network. To derive this algorithm, the derivative of the activation function is required.
The fact that the sigmoid function is monotonic, continuous and differentiable everywhere, coupled with the property that its derivative can be expressed in terms of itself, makes it easy to derive the update equations for learning the weights in a neural network when using back propagation algorithm.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Other non-linear activation functions, e.g., tanh function
- A Gentle Introduction to the Rectified Linear Unit (ReLU)
- Deep learning
If you explore any of these extensions, I’d love to know. Post your findings in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
- Calculus in action: Neural networks
- A gentle introduction to gradient descent procedure
- Neural networks are function approximation algorithms
- How to Choose an Activation Function for Deep Learning
Resources
- Jason Brownlee’s excellent resource on Calculus Books for Machine Learning
Books
- Pattern recognition and machine learning by Christopher M. Bishop.
- Deep learning by Ian Goodfellow, Joshua Begio, Aaron Courville.
- Thomas Calculus, 14th edition, 2017. (based on the original works of George B. Thomas, revised by Joel Hass, Christopher Heil, Maurice Weir)
Summary
In this tutorial, you discovered what is a sigmoid function. Specifically, you learned:
- The sigmoid function and its properties
- Linear vs. non-linear decision boundaries
- Why adding a sigmoid function at the hidden layer enables a neural network to learn complex non-linear boundaries
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer






Knowledgeable content!!
This was a wonderful blog.
I have a question though-
Since sigmoid function gives an output between 0 and 1, does it mean it is only used for Binary classification?
Yes. In case of multiclass classification, we use multiple sigmoid functions. An example is here: https://machinelearningmastery.com/multi-label-classification-with-deep-learning/
As its any value is between 0 and 1, you have a continuous output. For a regression problem, you can rescale it back to the output values. Alternatively, you can use linear units in the output layer for all regression problems.
Why does the function always have to be increasing?
By convention. Technically not necessarily to be.
An excellent Introduction to Sigmoid.. Thank you.
You are very welcome Shekar! We appreciate the feedback and support!
Does Sigmoid function gives us probabilistic values of 0 and 1?