Deep learning neural networks are very easy to create and evaluate in Python with Keras, but you must follow a strict model life-cycle.
In this post you will discover the step-by-step life-cycle for creating, training and evaluating deep learning neural networks in Keras and how to make predictions with a trained model.
After reading this post you will know:
How to define, compile, fit and evaluate a deep learning neural network in Keras.
How to select standard defaults for regression and classification predictive modeling problems.
How to tie it all together to develop and run your first Multilayer Perceptron network in Keras.
Kick-start your project with my new book Deep Learning With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Update Mar/2017: Updated example for Keras 2.0.2, TensorFlow 1.0.1 and Theano 0.9.0.
Update Mar/2018: Added alternate link to download the dataset as the original appears to have been taken down.
Deep Learning Neural Network Life-Cycle in Keras Photo by Martin Stitchener, some rights reserved.
Overview
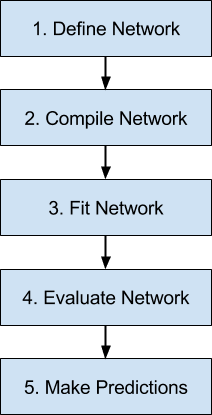
Below is an overview of the 5 steps in the neural network model life-cycle in Keras that we are going to look at.
Define Network.
Compile Network.
Fit Network.
Evaluate Network.
Make Predictions.
5 Step Life-Cycle for Neural Network Models in Keras
Need help with Deep Learning in Python?
Take my free 2-week email course and discover MLPs, CNNs and LSTMs (with code).
Click to sign-up now and also get a free PDF Ebook version of the course.
Step 1. Define Network
The first step is to define your neural network.
Neural networks are defined in Keras as a sequence of layers. The container for these layers is the Sequential class.
The first step is to create an instance of the Sequential class. Then you can create your layers and add them in the order that they should be connected.
For example, we can do this in two steps:
1
2
model=Sequential()
model.add(Dense(2))
But we can also do this in one step by creating an array of layers and passing it to the constructor of the Sequential.
1
2
layers=[Dense(2)]
model=Sequential(layers)
The first layer in the network must define the number of inputs to expect. The way that this is specified can differ depending on the network type, but for a Multilayer Perceptron model this is specified by the input_dim attribute.
For example, a small Multilayer Perceptron model with 2 inputs in the visible layer, 5 neurons in the hidden layer and one neuron in the output layer can be defined as:
1
2
3
model=Sequential()
model.add(Dense(5,input_dim=2))
model.add(Dense(1))
Think of a Sequential model as a pipeline with your raw data fed in at the bottom and predictions that come out at the top.
This is a helpful conception in Keras as concerns that were traditionally associated with a layer can also be split out and added as separate layers, clearly showing their role in the transform of data from input to prediction. For example, activation functions that transform a summed signal from each neuron in a layer can be extracted and added to the Sequential as a layer-like object called Activation.
1
2
3
4
5
model=Sequential()
model.add(Dense(5,input_dim=2))
model.add(Activation('relu'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
The choice of activation function is most important for the output layer as it will define the format that predictions will take.
For example, below are some common predictive modeling problem types and the structure and standard activation function that you can use in the output layer:
Regression: Linear activation function or ‘linear’ and the number of neurons matching the number of outputs.
Binary Classification (2 class): Logistic activation function or ‘sigmoid’ and one neuron the output layer.
Multiclass Classification (>2 class): Softmax activation function or ‘softmax’ and one output neuron per class value, assuming a one-hot encoded output pattern.
Step 2. Compile Network
Once we have defined our network, we must compile it.
Compilation is an efficiency step. It transforms the simple sequence of layers that we defined into a highly efficient series of matrix transforms in a format intended to be executed on your GPU or CPU, depending on how Keras is configured.
Think of compilation as a precompute step for your network.
Compilation is always required after defining a model. This includes both before training it using an optimization scheme as well as loading a set of pre-trained weights from a save file. The reason is that the compilation step prepares an efficient representation of the network that is also required to make predictions on your hardware.
Compilation requires a number of parameters to be specified, specifically tailored to training your network. Specifically the optimization algorithm to use to train the network and the loss function used to evaluate the network that is minimized by the optimization algorithm.
For example, below is a case of compiling a defined model and specifying the stochastic gradient descent (sgd) optimization algorithm and the mean squared error (mse) loss function, intended for a regression type problem.
1
model.compile(optimizer='sgd',loss='mse')
The type of predictive modeling problem imposes constraints on the type of loss function that can be used.
For example, below are some standard loss functions for different predictive model types:
Regression: Mean Squared Error or ‘mse‘.
Binary Classification (2 class): Logarithmic Loss, also called cross entropy or ‘binary_crossentropy‘.
Multiclass Classification (>2 class): Multiclass Logarithmic Loss or ‘categorical_crossentropy‘.
Perhaps the most commonly used optimization algorithms because of their generally better performance are:
Stochastic Gradient Descent or ‘sgd‘ that requires the tuning of a learning rate and momentum.
ADAM or ‘adam‘ that requires the tuning of learning rate.
RMSprop or ‘rmsprop‘ that requires the tuning of learning rate.
Finally, you can also specify metrics to collect while fitting your model in addition to the loss function. Generally, the most useful additional metric to collect is accuracy for classification problems. The metrics to collect are specified by name in an array.
Once the network is compiled, it can be fit, which means adapt the weights on a training dataset.
Fitting the network requires the training data to be specified, both a matrix of input patterns X and an array of matching output patterns y.
The network is trained using the backpropagation algorithm and optimized according to the optimization algorithm and loss function specified when compiling the model.
The backpropagation algorithm requires that the network be trained for a specified number of epochs or exposures to the training dataset.
Each epoch can be partitioned into groups of input-output pattern pairs called batches. This define the number of patterns that the network is exposed to before the weights are updated within an epoch. It is also an efficiency optimization, ensuring that not too many input patterns are loaded into memory at a time.
A minimal example of fitting a network is as follows:
1
history=model.fit(X,y,batch_size=10,epochs=100)
Once fit, a history object is returned that provides a summary of the performance of the model during training. This includes both the loss and any additional metrics specified when compiling the model, recorded each epoch.
Step 4. Evaluate Network
Once the network is trained, it can be evaluated.
The network can be evaluated on the training data, but this will not provide a useful indication of the performance of the network as a predictive model, as it has seen all of this data before.
We can evaluate the performance of the network on a separate dataset, unseen during testing. This will provide an estimate of the performance of the network at making predictions for unseen data in the future.
The model evaluates the loss across all of the test patterns, as well as any other metrics specified when the model was compiled, like classification accuracy. A list of evaluation metrics is returned.
For example, for a model compiled with the accuracy metric, we could evaluate it on a new dataset as follows:
1
loss,accuracy=model.evaluate(X,y)
Step 5. Make Predictions
Finally, once we are satisfied with the performance of our fit model, we can use it to make predictions on new data.
This is as easy as calling the predict() function on the model with an array of new input patterns.
For example:
1
predictions=model.predict(x)
The predictions will be returned in the format provided by the output layer of the network.
In the case of a regression problem, these predictions may be in the format of the problem directly, provided by a linear activation function.
For a binary classification problem, the predictions may be an array of probabilities for the first class that can be converted to a 1 or 0 by rounding.
For a multiclass classification problem, the results may be in the form of an array of probabilities (assuming a one hot encoded output variable) that may need to be converted to a single class output prediction using the argmax function.
End-to-End Worked Example
Let’s tie all of this together with a small worked example.
This example will use the Pima Indians onset of diabetes binary classification problem.
Download the dataset and save it to your current working directory.
The problem has 8 input variables and a single output class variable with the integer values 0 and 1.
We will construct a Multilayer Perceptron neural network with a 8 inputs in the visible layer, 12 neurons in the hidden layer with a rectifier activation function and 1 neuron in the output layer with a sigmoid activation function.
We will train the network for 100 epochs with a batch size of 10, optimized using the ADAM optimization algorithm and the logarithmic loss function.
Once fit, we will evaluate the model on the training data and then make standalone predictions for the training data. This is for brevity, normally we would evaluate the model on a separate test dataset and make predictions for new data.
The complete code listing is provided below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Sample Multilayer Perceptron Neural Network in Keras
Running this example produces the following output:
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this post you discovered the 5-step life-cycle of a deep learning neural network using the Keras library.
Specifically, you learned:
How to define, compile, fit, evaluate and make predictions for a neural network in Keras.
How to select activation functions and output layer configurations for classification and regression problems.
How to develop and run your first Multilayer Perceptron model in Keras.
Do you have any questions about neural network models in Keras or about this post? Ask your questions in the comments and I will do my best to answer them.
The simplest solution that will work in both Python versions 2 & 3:
put “numpy.” in front of “round”.
i.e.
predictions = [float(numpy.round(x)) for x in probabilities]
Thanks for the great intro to Keras. I would like to constrain predictions in my regression problem to a certain range. Is there a way to accomplish this in Keras?
Thanks for the quick reply. To force outputs to be of a specific interval (e.g. [0 5]), I tried Keras lambda layers keras.layers.Lambda(function, output_shape=None, mask=None, arguments=None) with Keras probability distributions as the function (https://www.tensorflow.org/probability). However, it does not work this way. Do you have a hint on how to accomplish this?
Great posts!
I am planning to try Keras on a device with very limited memory. Is there a clean way of doing online training, ie read x nr of lines from file then train and so on until the large dataset is processed?
Hi again, one question. Where is “backpropagation algorithm” you wrote in the beginning? Do we do explicitly do something to forward iterate, calculate error, backpropate error, then update weights? Or is backpropagation happens magically when we use some specific LOSS and OPTIMIZER ? I have Feedforward network with ‘mse’ and ‘sgd’ Thanks
The beauty of using Keras is that it implements the algorithm for you. You only need to choose the loss function and optimization algorithm then call fit().
Very nice posts and simple tutorials. Thank you!
I am new with Keras and I am wondering whereas fit() function does a one-vs-all-remaining training and evaluation or just training on all data in X and evaluating on the same data?
Thank you very much for this useful tutorial,
I was asking how can i give bio-metrics dataset to a neural network for verification? since these datasets consist of separate individuals (genuine and forgery)
Should i split the dataset into small pieces, one for each individual, and measure the accuracy for each individual separately. In this case, I have multiple Binary Classification (2 class) problems or i should give the whole dataset for all individual to the network? but how?
My advice is to brainstorm a suite of different framings of your problem, then test each and see what results in the best model skill for your specific dataset.
The skill of a model is specific to a given dataset. How good a model may perform really depends on the difficulty of the specific modeling problem and the chosen modeling algorithm.
Hi Jason!
I’m wondering the accuracy printed is the training accuracy or validation accuracy. I suppose it’s training accuracy since I didn’t see you split the dataset or do cross-validation. How can I checkI validation accuracy?
Hey thankyou for this tutroial but i dont know for certain reason i am not able to load the PIMA dataset using the code mentioned above.
it throw’s an error ‘ OSError: pima-indians-diabetes.csv not found .’
Any idea why this is happening?
Thankyou for your help in advance.
Hi,
i have build a model , compiled and fit successfully with 0.15 validation error. but when i predict x_test , it gives me a constant value for all inputs. i have tried many variation like changing learning rate with many values but not get affected in predicted result.
can you please tell me why this happens in keras
Hi, I have a doubt. When I train on matlab I have to define the training algorithm. For instance the levenberg marquardt algorithm to compute the gradients. On this case, how the gradients are computed on Keras?. Which training algorithm uses.
You say here that for a Regression problem, the # of neurons is equal to the number of outputs. In your Regression tutorial with Keras, you use just one neuron for a regression problem that has 13 outputs. Do you mean to say the neurons should be equal to # of outputs per training example?
I’m asking because Keras throws an error when I put in the total number of outputs as the number of neurons in the final layer. The error says:
Error when checking target: expected dense_18 to have shape (199605,) but got array with shape (1,)
Hi Jason, Thanks for thee awesome articles. On the model.fit method, when we do not provide any split_validation parameter or validation_data, how does the model validate the model?
Compared with the example in “Develop Your First Neural Network in Python With Keras Step-By-Step”, why here you do not have a hidden layer: model.add(Dense(8, activation=’relu’)). For usual ANN, is this also good?
Automatic differentiation is used to calculate the derivatives rather than having to specify how they are calculated, which is very cool.
Backpropagation is the algorithm used to update model weights during the optimization process using the gradients calculated by automatic differentiation.
.
thanks for your reply Jason
from your reply i understand that it is the feature of keras to do automatic differntiation.
my question is how we can see or how keras does automatic differentiation and when?is it possible to see or any link that can help..
thanks alot for your reply
can i have github link for it?
one more thing kindly clear it please keras does automatic differentiation and BP uses that during optimization process to update weights i got it, my question is do we still need to use BP in our code or keras do it for us and keras uses framework for BP, ?because i read many other comments and also yours that keras uses BP to update weights,
Thanks for the tutorial and all of your content is very helpful. I can’t thank you enough.
I have a question.
I have trained a deep learning (feed-forward neural network) model using tensorflow on train data say X ie
model = tf.keras.models.Sequential([……])
Now I want to predict on an independent dataset?For which I wrote:
dt = pd.read_csv(‘IndependentData.csv’)
dt=dt.drop([‘Col1’],axis=1)
dt=dt.drop([‘Col2’],axis=1)
X1 = dt.values
predictions=model.predict(X1).round()
#Col1 and Col2 identify the rows uniquely
But this doesn’t give me an expected output. (Is this correct what I wrote?). I want to calculate the confusion matrix and plot AuROC and AUPR. How to do that? Also, I want to identify which rows n the independent were predicted to be TP, TN, FP and FN(I don’t want to drop those Col1 and Col2). Could you please help me how to go about it?
Hi Jason. I’ve trained my own network using this tutorial and I had accuracy that I’m satisfied with. I’m planning to implement this using arduino. I need the trained weight for my sketch in arduino to make feed forward propagation for prediction. How do I get the weight from my keras trained network ?
Thanks
I was wondering about the bias unit, whether keras understands that there is a bias unit, or an extra “column” of ones that represent this bias.
For instance, if the number of features we have is 10, then, should our input dimension be 10 + 1 (11), or should we keep the dimensions of our array where input_dim = 10 ( len ( array.shape[1] ) )




")



predictions = [float(round(x)) for x in probabilities]
The code throws an error,
type numpy.ndarray doesn’t define __round__ method
Then I change it to
predictions = [float(round(x[0])) for x in probabilities]
And it works!
It seems that round() doesn’t work for numpy.
https://mail.scipy.org/pipermail/numpy-discussion/2010-March/049584.html
Thanks Ming that may be a Python 3 issue, it executes fine in my py27 environment.
The simplest solution that will work in both Python versions 2 & 3:
put “numpy.” in front of “round”.
i.e.
predictions = [float(numpy.round(x)) for x in probabilities]
Thank you for this tutorial!
Thanks Eric.
Use:
rounded = [ ‘%.2f’ % x for x in predictions ]
Thanks for the great intro to Keras. I would like to constrain predictions in my regression problem to a certain range. Is there a way to accomplish this in Keras?
Yes, you could use a custom activation function in the output layer, or interpret the prediction from the model.
Thanks for the quick reply. To force outputs to be of a specific interval (e.g. [0 5]), I tried Keras lambda layers keras.layers.Lambda(function, output_shape=None, mask=None, arguments=None) with Keras probability distributions as the function (https://www.tensorflow.org/probability). However, it does not work this way. Do you have a hint on how to accomplish this?
The simplest is to use a linear output and post-process the predictions with a function.
Once that works, use the lambda layer to call your custom function.
Hi Jason!
Great posts!
I am planning to try Keras on a device with very limited memory. Is there a clean way of doing online training, ie read x nr of lines from file then train and so on until the large dataset is processed?
Thanks
BR
Magnus
With limited memory and CPU, I would recommend creating your own implementations, perhaps starting with simpler methods.
I would suggest the Python stack as too heavy/resource intensive.
Hi again, one question. Where is “backpropagation algorithm” you wrote in the beginning? Do we do explicitly do something to forward iterate, calculate error, backpropate error, then update weights? Or is backpropagation happens magically when we use some specific LOSS and OPTIMIZER ? I have Feedforward network with ‘mse’ and ‘sgd’ Thanks
The beauty of using Keras is that it implements the algorithm for you. You only need to choose the loss function and optimization algorithm then call fit().
Can we see:
X = training data set
y = testing data set
here?
Train and test data must both consist of X and y components.
I try to adapt the above example and get the following error message:
ValueError: Error when checking model input: expected dense_1_input to have shape (None, 2) but got array with shape (29, 1)
My raw data has a column of dates and a column of integers.
Any ideas?
Code:
def parser(x):
return datetime.strptime(x, ‘%Y-%m-%d’)
# load dataset
series = read_csv(‘./data/myData.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
values = series.values
X, Y = values[0:-6], values[-6:]
model = Sequential()
model.add(Dense(5, input_dim=2, activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
model.compile(optimizer=’sgd’, loss=’mse’)
history = model.fit(X, Y, epochs=1, batch_size=1)
For an example of how to use an MLP with time series data, see this post:
https://machinelearningmastery.com/time-series-prediction-with-deep-learning-in-python-with-keras/
Beside of the nice keras concepts and tutorial, you share us Nice Photos, Jason 🙂
Thanks,
Are your books for kindle and ebooks? or in amazon ??
cheers.
Jose Miguel
Thanks Jose.
My training material are PDF Ebooks only available from my website:
https://machinelearningmastery.com/products
Why 12 neurons in the hidden layer?
Trial and error.
That doesn’t help a learner – how do you decide what to start with?
Great question.
A good starting point is to copy another neural net from the literature applied to a similar problem.
You could try having the number of neurons in the hidden layer equal to the number of inputs.
These are just heuristics, and the best results will come when you test a suite of different configurations and see what works best on your problem.
Hi Jason,
Very nice posts and simple tutorials. Thank you!
I am new with Keras and I am wondering whereas fit() function does a one-vs-all-remaining training and evaluation or just training on all data in X and evaluating on the same data?
Thanks,
The fit() function updates the model with the provided data. It does not evaluate the model.
Thank you very much for this useful tutorial,
I was asking how can i give bio-metrics dataset to a neural network for verification? since these datasets consist of separate individuals (genuine and forgery)
Should i split the dataset into small pieces, one for each individual, and measure the accuracy for each individual separately. In this case, I have multiple Binary Classification (2 class) problems or i should give the whole dataset for all individual to the network? but how?
Great question.
My advice is to brainstorm a suite of different framings of your problem, then test each and see what results in the best model skill for your specific dataset.
Hi Jason, thank you for this tutorial.
I implemented the code and see that the accuracy is ~76%. If I increase the number of layers and/or the epochs, it goes up to ~79%.
Since we are training and evaluating on the same dataset, shouldn’t we expect close to 90% accuracy?
Where is the loss?
The skill of a model is specific to a given dataset. How good a model may perform really depends on the difficulty of the specific modeling problem and the chosen modeling algorithm.
Hi Jason!
I’m wondering the accuracy printed is the training accuracy or validation accuracy. I suppose it’s training accuracy since I didn’t see you split the dataset or do cross-validation. How can I checkI validation accuracy?
Best,
Jenny
You can split the data into train/test and use the test data in the call to evaluate().
Here is more information on how to effectively evaluate deep learning models:
https://machinelearningmastery.com/evaluate-skill-deep-learning-models/
Hey thankyou for this tutroial but i dont know for certain reason i am not able to load the PIMA dataset using the code mentioned above.
it throw’s an error ‘ OSError: pima-indians-diabetes.csv not found .’
Any idea why this is happening?
Thankyou for your help in advance.
You need to download the dataset and place it in the same directory as your code file.
Hi,
i have build a model , compiled and fit successfully with 0.15 validation error. but when i predict x_test , it gives me a constant value for all inputs. i have tried many variation like changing learning rate with many values but not get affected in predicted result.
can you please tell me why this happens in keras
Sounds like the model is underfit for your problem.
Perhaps try other model configurations?
Hi, I have a doubt. When I train on matlab I have to define the training algorithm. For instance the levenberg marquardt algorithm to compute the gradients. On this case, how the gradients are computed on Keras?. Which training algorithm uses.
Thank You.
The algorithm is specified via the ‘optimizer’ argument. Only variants of SGD are supported.
Hi Jason,
Firstly, love the tutorial.
You say here that for a Regression problem, the # of neurons is equal to the number of outputs. In your Regression tutorial with Keras, you use just one neuron for a regression problem that has 13 outputs. Do you mean to say the neurons should be equal to # of outputs per training example?
I’m asking because Keras throws an error when I put in the total number of outputs as the number of neurons in the final layer. The error says:
Error when checking target: expected dense_18 to have shape (199605,) but got array with shape (1,)
Thanks!
If you want to predict 13 values, you must have 13 nodes in the output layer, and your data must match.
Hi Jason, Thanks for thee awesome articles. On the model.fit method, when we do not provide any split_validation parameter or validation_data, how does the model validate the model?
Good question.
We can evaluate the performance of the model after the fit using the model.evalaute() function.
Hi Jason,
Compared with the example in “Develop Your First Neural Network in Python With Keras Step-By-Step”, why here you do not have a hidden layer: model.add(Dense(8, activation=’relu’)). For usual ANN, is this also good?
Best,
Chris
We do have a hidden layer, perhaps this will make things clearer:
https://machinelearningmastery.com/faq/single-faq/how-do-you-define-the-input-layer-in-keras
theano or tensoeflow do autodifferenciation in keras for BP or adam do that for BP ? how?
Adam is just an optimization algorithm.
Automatic differentiation is used to calculate the derivatives rather than having to specify how they are calculated, which is very cool.
Backpropagation is the algorithm used to update model weights during the optimization process using the gradients calculated by automatic differentiation.
.
thanks for your reply Jason
from your reply i understand that it is the feature of keras to do automatic differntiation.
my question is how we can see or how keras does automatic differentiation and when?is it possible to see or any link that can help..
Keras uses TensorFlow to perform these operations.
The source code for Keras and TensorFlow is on github if you want to step through it.
thanks alot for your reply
can i have github link for it?
one more thing kindly clear it please keras does automatic differentiation and BP uses that during optimization process to update weights i got it, my question is do we still need to use BP in our code or keras do it for us and keras uses framework for BP, ?because i read many other comments and also yours that keras uses BP to update weights,
Keras: https://github.com/keras-team/keras
TF: https://github.com/tensorflow/tensorflow
Yes, backprop is used to update model weights.
Keras/TF do it all for you.
i mean we dont need to write code for BP in keras?? tensorflow will do it
No, it is all taken care of.
thank alot for your reply and help ,
No problem.
Hi Jason .
Thanks for the tutorial and all of your content is very helpful. I can’t thank you enough.
I have a question.
I have trained a deep learning (feed-forward neural network) model using tensorflow on train data say X ie
model = tf.keras.models.Sequential([……])
Now I want to predict on an independent dataset?For which I wrote:
dt = pd.read_csv(‘IndependentData.csv’)
dt=dt.drop([‘Col1’],axis=1)
dt=dt.drop([‘Col2’],axis=1)
X1 = dt.values
predictions=model.predict(X1).round()
#Col1 and Col2 identify the rows uniquely
But this doesn’t give me an expected output. (Is this correct what I wrote?). I want to calculate the confusion matrix and plot AuROC and AUPR. How to do that? Also, I want to identify which rows n the independent were predicted to be TP, TN, FP and FN(I don’t want to drop those Col1 and Col2). Could you please help me how to go about it?
Thanks.
You’re welcome.
Perhaps this will help:
https://machinelearningmastery.com/how-to-calculate-precision-recall-f1-and-more-for-deep-learning-models/
Hi Jason. I’ve trained my own network using this tutorial and I had accuracy that I’m satisfied with. I’m planning to implement this using arduino. I need the trained weight for my sketch in arduino to make feed forward propagation for prediction. How do I get the weight from my keras trained network ?
Thanks
You can save them using the Keras API, here’s an example:
https://machinelearningmastery.com/save-load-keras-deep-learning-models/
Thanks, Jason. I am new to Neural network and your blog is amazing.
Thanks!
Hello Jason,
Thank you for the post.
I was wondering about the bias unit, whether keras understands that there is a bias unit, or an extra “column” of ones that represent this bias.
For instance, if the number of features we have is 10, then, should our input dimension be 10 + 1 (11), or should we keep the dimensions of our array where input_dim = 10 ( len ( array.shape[1] ) )
The bias input is internal to each node, no need to add anything.
I get this at the end. What does it mean
TypeError: type numpy.ndarray doesn’t define __round__ method
Perhaps you need to update your version of your Python libraries.
How do I use a pipeline for a neural network?
Thanks for guiding me.
I do not recommend it, but you can use a pipeline with the keras wrapper objects.
simple tutorial for very important and useful information
your way is very helpful
thank you