In the old days, it was a tedious job to collect data, and it was sometimes very expensive. Machine learning projects cannot live without data. Luckily, we have a lot of data on the web at our disposal nowadays. We can copy data from the web to create our dataset. We can manually download files and save them to the disk. But we can do it more efficiently by automating the data harvesting. There are several tools in Python that can help the automation.
After finishing this tutorial, you will learn:
- How to use the requests library to read online data using HTTP
- How to read tables on web pages using pandas
- How to use Selenium to emulate browser operations
Kick-start your project with my new book Python for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started!
Web Crawling in Python
Photo by Ray Bilcliff. Some rights reserved.
Overview
This tutorial is divided into three parts; they are:
- Using the requests library
- Reading tables on the web using pandas
- Reading dynamic content with Selenium
Using the Requests Library
When we talk about writing a Python program to read from the web, it is inevitable that we can’t avoid the requests library. You need to install it (as well as BeautifulSoup and lxml that we will cover later):
|
1 |
pip install requests beautifulsoup4 lxml |
It provides you with an interface that allows you to interact with the web easily.
The very simple use case would be to read a web page from a URL:
|
1 2 3 4 5 6 7 |
import requests # Lat-Lon of New York URL = "https://weather.com/weather/today/l/40.75,-73.98" resp = requests.get(URL) print(resp.status_code) print(resp.text) |
|
1 2 3 4 5 |
200 <!doctype html><html dir="ltr" lang="en-US"><head> <meta data-react-helmet="true" charset="utf-8"/><meta data-react-helmet="true" name="viewport" content="width=device-width, initial-scale=1, viewport-fit=cover"/> ... |
If you’re familiar with HTTP, you can probably recall that a status code of 200 means the request is successfully fulfilled. Then we can read the response. In the above, we read the textual response and get the HTML of the web page. Should it be a CSV or some other textual data, we can get them in the text attribute of the response object. For example, this is how we can read a CSV from the Federal Reserve Economics Data:
|
1 2 3 4 5 6 7 8 9 10 11 |
import io import pandas as pd import requests URL = "https://fred.stlouisfed.org/graph/fredgraph.csv?id=T10YIE&cosd=2017-04-14&coed=2022-04-14" resp = requests.get(URL) if resp.status_code == 200: csvtext = resp.text csvbuffer = io.StringIO(csvtext) df = pd.read_csv(csvbuffer) print(df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DATE T10YIE 0 2017-04-17 1.88 1 2017-04-18 1.85 2 2017-04-19 1.85 3 2017-04-20 1.85 4 2017-04-21 1.84 ... ... ... 1299 2022-04-08 2.87 1300 2022-04-11 2.91 1301 2022-04-12 2.86 1302 2022-04-13 2.8 1303 2022-04-14 2.89 [1304 rows x 2 columns] |
If the data is in the form of JSON, we can read it as text or even let requests decode it for you. For example, the following is to pull some data from GitHub in JSON format and convert it into a Python dictionary:
|
1 2 3 4 5 6 7 |
import requests URL = "https://api.github.com/users/jbrownlee" resp = requests.get(URL) if resp.status_code == 200: data = resp.json() print(data) |
|
1 2 3 4 5 6 7 8 9 10 11 |
{'login': 'jbrownlee', 'id': 12891, 'node_id': 'MDQ6VXNlcjEyODkx', 'avatar_url': 'https://avatars.githubusercontent.com/u/12891?v=4', 'gravatar_id': '', 'url': 'https://api.github.com/users/jbrownlee', 'html_url': 'https://github.com/jbrownlee', ... 'company': 'Machine Learning Mastery', 'blog': 'https://machinelearningmastery.com', 'location': None, 'email': None, 'hireable': None, 'bio': 'Making developers awesome at machine learning.', 'twitter_username': None, 'public_repos': 5, 'public_gists': 0, 'followers': 1752, 'following': 0, 'created_at': '2008-06-07T02:20:58Z', 'updated_at': '2022-02-22T19:56:27Z' } |
But if the URL gives you some binary data, such as a ZIP file or a JPEG image, you need to get them in the content attribute instead, as this would be the binary data. For example, this is how we can download an image (the logo of Wikipedia):
|
1 2 3 4 5 6 7 |
import requests URL = "https://en.wikipedia.org/static/images/project-logos/enwiki.png" wikilogo = requests.get(URL) if wikilogo.status_code == 200: with open("enwiki.png", "wb") as fp: fp.write(wikilogo.content) |
Given we already obtained the web page, how should we extract the data? This is beyond what the requests library can provide to us, but we can use a different library to help. There are two ways we can do it, depending on how we want to specify the data.
The first way is to consider the HTML as a kind of XML document and use the XPath language to extract the element. In this case, we can make use of the lxml library to first create a document object model (DOM) and then search by XPath:
|
1 2 3 4 5 6 7 8 |
... from lxml import etree # Create DOM from HTML text dom = etree.HTML(resp.text) # Search for the temperature element and get the content elements = dom.xpath("//span[@data-testid='TemperatureValue' and contains(@class,'CurrentConditions')]") print(elements[0].text) |
|
1 |
61° |
XPath is a string that specifies how to find an element. The lxml object provides a function xpath() to search the DOM for elements that match the XPath string, which can be multiple matches. The XPath above means to find an HTML element anywhere with the <span> tag and with the attribute data-testid matching “TemperatureValue” and class beginning with “CurrentConditions.” We can learn this from the developer tools of the browser (e.g., the Chrome screenshot below) by inspecting the HTML source.
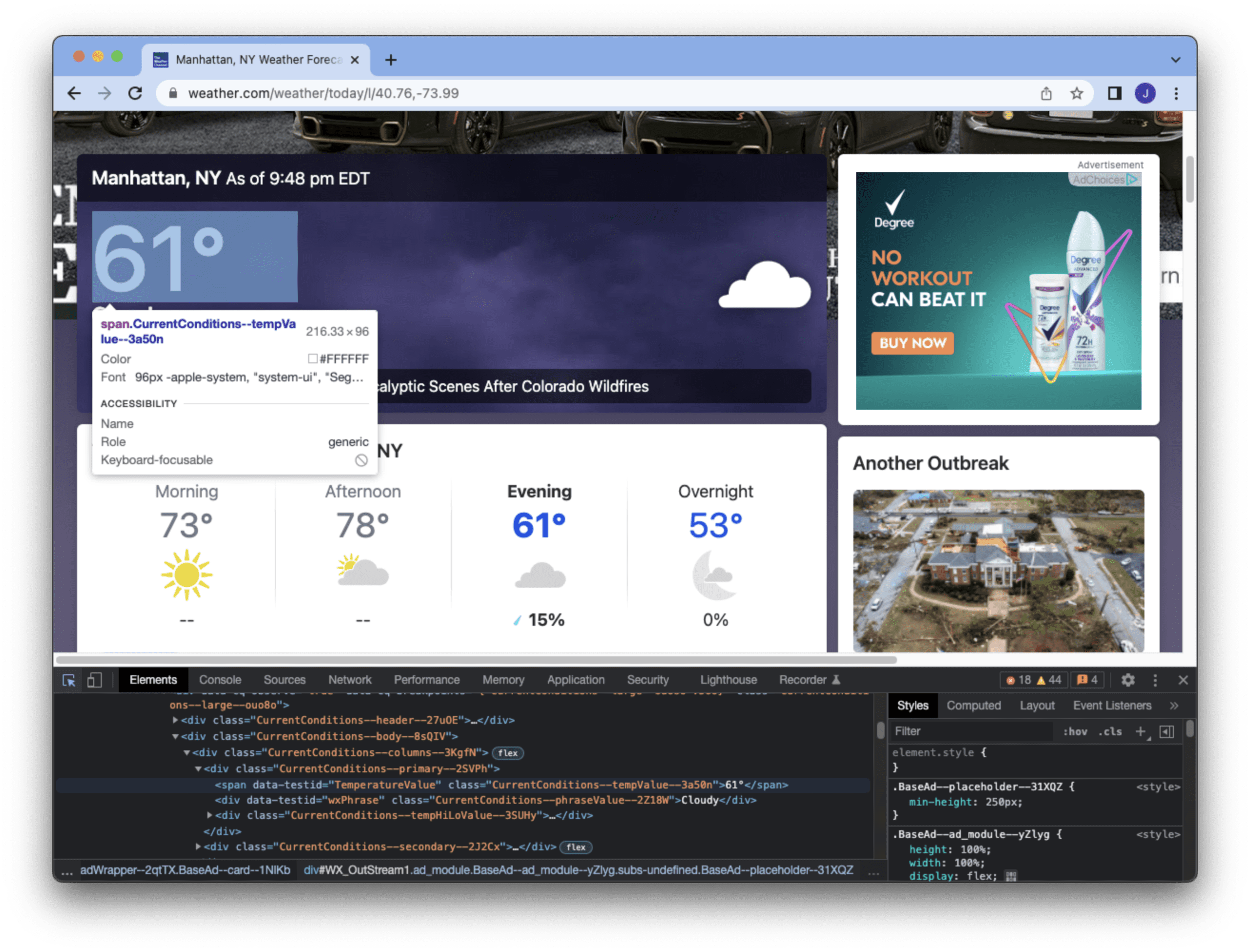
This example is to find the temperature of New York City, provided by this particular element we get from this web page. We know the first element matched by the XPath is what we need, and we can read the text inside the <span> tag.
The other way is to use CSS selectors on the HTML document, which we can make use of the BeautifulSoup library:
|
1 2 3 4 5 6 |
... from bs4 import BeautifulSoup soup = BeautifulSoup(resp.text, "lxml") elements = soup.select('span[data-testid="TemperatureValue"][class^="CurrentConditions"]') print(elements[0].text) |
|
1 |
61° |
In the above, we first pass our HTML text to BeautifulSoup. BeautifulSoup supports various HTML parsers, each with different capabilities. In the above, we use the lxml library as the parser as recommended by BeautifulSoup (and it is also often the fastest). CSS selector is a different mini-language, with pros and cons compared to XPath. The selector above is identical to the XPath we used in the previous example. Therefore, we can get the same temperature from the first matched element.
The following is a complete code to print the current temperature of New York according to the real-time information on the web:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import requests from lxml import etree # Reading temperature of New York URL = "https://weather.com/weather/today/l/40.75,-73.98" resp = requests.get(URL) if resp.status_code == 200: # Using lxml dom = etree.HTML(resp.text) elements = dom.xpath("//span[@data-testid='TemperatureValue' and contains(@class,'CurrentConditions')]") print(elements[0].text) # Using BeautifulSoup soup = BeautifulSoup(resp.text, "lxml") elements = soup.select('span[data-testid="TemperatureValue"][class^="CurrentConditions"]') print(elements[0].text) |
As you can imagine, you can collect a time series of the temperature by running this script on a regular schedule. Similarly, we can collect data automatically from various websites. This is how we can obtain data for our machine learning projects.
Reading Tables on the Web Using Pandas
Very often, web pages will use tables to carry data. If the page is simple enough, we may even skip inspecting it to find out the XPath or CSS selector and use pandas to get all tables on the page in one shot. It is simple enough to be done in one line:
|
1 2 3 4 |
import pandas as pd tables = pd.read_html("https://www.federalreserve.gov/releases/h15/") print(tables) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
[ Instruments 2022Apr7 2022Apr8 2022Apr11 2022Apr12 2022Apr13 0 Federal funds (effective) 1 2 3 0.33 0.33 0.33 0.33 0.33 1 Commercial Paper 3 4 5 6 NaN NaN NaN NaN NaN 2 Nonfinancial NaN NaN NaN NaN NaN 3 1-month 0.30 0.34 0.36 0.39 0.39 4 2-month n.a. 0.48 n.a. n.a. n.a. 5 3-month n.a. n.a. n.a. 0.78 0.78 6 Financial NaN NaN NaN NaN NaN 7 1-month 0.49 0.45 0.46 0.39 0.46 8 2-month n.a. n.a. 0.60 0.71 n.a. 9 3-month 0.85 0.81 0.75 n.a. 0.86 10 Bank prime loan 2 3 7 3.50 3.50 3.50 3.50 3.50 11 Discount window primary credit 2 8 0.50 0.50 0.50 0.50 0.50 12 U.S. government securities NaN NaN NaN NaN NaN 13 Treasury bills (secondary market) 3 4 NaN NaN NaN NaN NaN 14 4-week 0.21 0.20 0.21 0.19 0.23 15 3-month 0.68 0.69 0.78 0.74 0.75 16 6-month 1.12 1.16 1.22 1.18 1.17 17 1-year 1.69 1.72 1.75 1.67 1.67 18 Treasury constant maturities NaN NaN NaN NaN NaN 19 Nominal 9 NaN NaN NaN NaN NaN 20 1-month 0.21 0.20 0.22 0.21 0.26 21 3-month 0.68 0.70 0.77 0.74 0.75 22 6-month 1.15 1.19 1.23 1.20 1.20 23 1-year 1.78 1.81 1.85 1.77 1.78 24 2-year 2.47 2.53 2.50 2.39 2.37 25 3-year 2.66 2.73 2.73 2.58 2.57 26 5-year 2.70 2.76 2.79 2.66 2.66 27 7-year 2.73 2.79 2.84 2.73 2.71 28 10-year 2.66 2.72 2.79 2.72 2.70 29 20-year 2.87 2.94 3.02 2.99 2.97 30 30-year 2.69 2.76 2.84 2.82 2.81 31 Inflation indexed 10 NaN NaN NaN NaN NaN 32 5-year -0.56 -0.57 -0.58 -0.65 -0.59 33 7-year -0.34 -0.33 -0.32 -0.36 -0.31 34 10-year -0.16 -0.15 -0.12 -0.14 -0.10 35 20-year 0.09 0.11 0.15 0.15 0.18 36 30-year 0.21 0.23 0.27 0.28 0.30 37 Inflation-indexed long-term average 11 0.23 0.26 0.30 0.30 0.33, 0 1 0 n.a. Not available.] |
The read_html() function in pandas reads a URL and finds all the tables on the page. Each table is converted into a pandas DataFrame and then returns all of them in a list. In this example, we are reading the various interest rates from the Federal Reserve, which happens to have only one table on this page. The table columns are identified by pandas automatically.
Chances are that not all tables are what we are interested in. Sometimes, the web page will use a table merely as a way to format the page, but pandas may not be smart enough to tell. Hence we need to test and cherry-pick the result returned by the read_html() function.
Want to Get Started With Python for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Reading Dynamic Content With Selenium
A significant portion of modern-day web pages is full of JavaScripts. This gives us a fancier experience but becomes a hurdle to use as a program to extract data. One example is Yahoo’s home page, which, if we just load the page and find all news headlines, there are far fewer than what we can see on the browser:
|
1 2 3 4 5 6 7 8 9 10 11 |
import requests # Read Yahoo home page URL = "https://www.yahoo.com/" resp = requests.get(URL) dom = etree.HTML(resp.text) # Print news headlines elements = dom.xpath("//h3/a[u[@class='StretchedBox']]") for elem in elements: print(etree.tostring(elem, method="text", encoding="unicode")) |
This is because web pages like this rely on JavaScript to populate the content. Famous web frameworks such as AngularJS or React are behind powering this category. The Python library, such as requests, does not understand JavaScript. Therefore, you will see the result differently. If the data you want to fetch from the web is one of them, you can study how the JavaScript is invoked and mimic the browser’s behavior in your program. But this is probably too tedious to make it work.
The other way is to ask a real browser to read the web page rather than using requests. This is what Selenium can do. Before we can use it, we need to install the library:
|
1 |
pip install selenium |
But Selenium is only a framework to control browsers. You need to have the browser installed on your computer as well as the driver to connect Selenium to the browser. If you intend to use Chrome, you need to download and install ChromeDriver too. You need to put the driver in the executable path so that Selenium can invoke it like a normal command. For example, in Linux, you just need to get the chromedriver executable from the ZIP file downloaded and put it in /usr/local/bin.
Similarly, if you’re using Firefox, you need the GeckoDriver. For more details on setting up Selenium, you should refer to its documentation.
Afterward, you can use a Python script to control the browser behavior. For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import time from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By # Launch Chrome browser in headless mode options = webdriver.ChromeOptions() options.add_argument("headless") browser = webdriver.Chrome(options=options) # Load web page browser.get("https://www.yahoo.com") # Network transport takes time. Wait until the page is fully loaded def is_ready(browser): return browser.execute_script(r""" return document.readyState === 'complete' """) WebDriverWait(browser, 30).until(is_ready) # Scroll to bottom of the page to trigger JavaScript action browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(1) WebDriverWait(browser, 30).until(is_ready) # Search for news headlines and print elements = browser.find_elements(By.XPATH, "//h3/a[u[@class='StretchedBox']]") for elem in elements: print(elem.text) # Close the browser once finish browser.close() |
The above code works as follows. We first launch the browser in headless mode, meaning we ask Chrome to start but not display on the screen. This is important if we want to run our script remotely as there may not be any GUI support. Note that every browser is developed differently, and thus the options syntax we used is specific to Chrome. If we use Firefox, the code would be this instead:
|
1 2 3 |
options = webdriver.FirefoxOptions() options.set_headless() browser = webdriver.Firefox(firefox_options=options) |
After we launch the browser, we give it a URL to load. But since it takes time for the network to deliver the page, and the browser will take time to render it, we should wait until the browser is ready before we proceed to the next operation. We detect if the browser has finished rendering by using JavaScript. We make Selenium run a JavaScript code for us and tell us the result using the execute_script() function. We leverage Selenium’s WebDriverWait tool to run it until it succeeds or until a 30-second timeout. As the page is loaded, we scroll to the bottom of the page so the JavaScript can be triggered to load more content. Then we wait for one second unconditionally to make sure the browser triggered the JavaScript, then wait until the page is ready again. Afterward, we can extract the news headline element using XPath (or alternatively using a CSS selector). Because the browser is an external program, we are responsible for closing it in our script.
Using Selenium is different from using the requests library in several aspects. First, you never have the web content in your Python code directly. Instead, you refer to the browser’s content whenever you need it. Hence the web elements returned by the find_elements() function refer to objects inside the external browser, so we must not close the browser before we finish consuming them. Secondly, all operations should be based on browser interaction rather than network requests. Thus you need to control the browser by emulating keyboard and mouse movements. But in return, you have the full-featured browser with JavaScript support. For example, you can use JavaScript to check the size and position of an element on the page, which you will know only after the HTML elements are rendered.
There are a lot more functions provided by the Selenium framework that we can cover here. It is powerful, but since it is connected to the browser, using it is more demanding than the requests library and much slower. Usually, this is the last resort for harvesting information from the web.
Further Reading
Another famous web crawling library in Python that we didn’t cover above is Scrapy. It is like combining the requests library with BeautifulSoup into one. The web protocol is complex. Sometimes we need to manage web cookies or provide extra data to the requests using the POST method. All these can be done with the requests library with a different function or extra arguments. The following are some resources for you to go deeper:
Articles
- An overview of HTTP from MDN
- XPath from MDN
- XPath tutorial from W3Schools
- CSS Selector Reference from W3Schools
- Selenium Python binding
API documentation
Books
- Python Web Scraping, 2nd Edition, by Katharine Jarmul and Richard Lawson
- Web Scraping with Python, 2nd Edition, by Ryan Mitchell
- Learning Scrapy, by Dimitrios Kouzis-Loukas
- Python Testing with Selenium, by Sujay Raghavendra
- Hands-On Web Scraping with Python, by Anish Chapagain
Summary
In this tutorial, you saw the tools we can use to fetch content from the web.
Specifically, you learned:
- How to use the requests library to send the HTTP request and extract data from its response
- How to build a document object model from HTML so we can find some specific information on a web page
- How to read tables on a web page quickly and easily using pandas
- How to use Selenium to control a browser to tackle dynamic content on a web page
Get a Handle on Python for Machine Learning!

Be More Confident to Code in Python
...from learning the practical Python tricks
Discover how in my new Ebook:
Python for Machine Learning
It provides self-study tutorials with hundreds of working code to equip you with skills including:
debugging, profiling, duck typing, decorators, deployment,
and much more...






there is a typo here.
df = ppd.read_csv(csvbuffer)
the “ppd” should be “pd”
Thank you for the feedback YF!
Thank you for this detailed and useful page. One thing though, isn’t this web scraping? As far as I know web crawling is finding or discovering URLs or links on the web.
Hi Selda…Yes, this technique is often referred to as web scraping.
error:
df = ppd.read_csv(csvbuffer)
correct:
df = pd.read_csv(csvbuffer)
Hi Luis…Thank you for the feedback!
Great and comprehensive article. It helps in understanding different approaches. However, without any standard template for website development it is really difficult to have a generic tool to collect data from the web pages. Do you have any thought on this?
Hi Suchi…the following may be of interest:
https://machinelearningmastery.com/web-crawling-in-python/
Thank your for the comprehensive steps. Can I know how to crawl Tweets data? Can anyone here provide the link?
Hi Rina…The following resource may be of interest to you:
https://machinelearningmastery.com/web-crawling-in-python/
Thank you for the tutorial. Can I know how to crawl data from private github repos?
Thank you for the feedback Billie! I am not aware of a method to perform that task.
Hy , hope you are fine .
Can I Know how to Crawl any Data from Any Website?
Hi Abdul…The following resource may be of interest to you:
https://medium.com/dataseries/build-a-crawler-to-extract-web-data-in-10-mins-691b2cc4f1c3