When we talk about managing data, it is quite inevitable to see data presented in tables. With column header, and sometimes with names for rows, it makes understanding data easier. In fact, it often happens that we see data of different types staying together. For example, we have quantity as numbers and name as strings in a table of ingredients for a recipe. In Python, we have the pandas library to help us handle tabular data.
After finishing this tutorial, you will learn:
- What the pandas library provides
- What is a DataFrame and a Series in pandas
- How to manipulate DataFrame and Series beyond the trivial array operations
Kick-start your project with my new book Python for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started!
Massaging Data Using Pandas
Photo by Mark de Jong. Some rights reserved.
Overview
This tutorial is divided into five parts:
- DataFrame and Series
- Essential functions in DataFrame
- Manipulating DataFrames and Series
- Aggregation in DataFrames
- Handling time series data in pandas
DataFrame and Series
To begin, let’s start with an example dataset. We will import pandas and read the U.S. air pollutant emission data into a DataFrame:
|
1 2 3 4 5 6 |
import pandas as pd URL = "https://www.epa.gov/sites/default/files/2021-03/state_tier1_caps.xlsx" df = pd.read_excel(URL, sheet_name="State_Trends", header=1) print(df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
State FIPS State Tier 1 Code Tier 1 Description ... emissions18 emissions19 emissions20 emissions21 0 1 AL 1 FUEL COMB. ELEC. UTIL. ... 10.050146 8.243679 8.243679 8.243679 1 1 AL 1 FUEL COMB. ELEC. UTIL. ... 0.455760 0.417551 0.417551 0.417551 2 1 AL 1 FUEL COMB. ELEC. UTIL. ... 26.233104 19.592480 13.752790 11.162100 3 1 AL 1 FUEL COMB. ELEC. UTIL. ... 2.601011 2.868642 2.868642 2.868642 4 1 AL 1 FUEL COMB. ELEC. UTIL. ... 1.941267 2.659792 2.659792 2.659792 ... ... ... ... ... ... ... ... ... ... 5314 56 WY 16 PRESCRIBED FIRES ... 0.893848 0.374873 0.374873 0.374873 5315 56 WY 16 PRESCRIBED FIRES ... 7.118097 2.857886 2.857886 2.857886 5316 56 WY 16 PRESCRIBED FIRES ... 6.032286 2.421937 2.421937 2.421937 5317 56 WY 16 PRESCRIBED FIRES ... 0.509242 0.208817 0.208817 0.208817 5318 56 WY 16 PRESCRIBED FIRES ... 16.632343 6.645249 6.645249 6.645249 [5319 rows x 32 columns] |
This is a table of pollutant emissions for each year, with the information on what kind of pollutant and the amount of emission per year.
Here we demonstrated one useful feature from pandas: You can read a CSV file using read_csv() or read an Excel file using read_excel(), as above. The filename can be a local file in your machine or an URL from where the file can be downloaded. We learned about this URL from the U.S. Environmental Protection Agency’s website. We know which worksheet contains the data and from which row the data starts, hence the extra arguments to the read_excel() function.
The pandas object created above is a DataFrame, presented as a table. Similar to NumPy, data in Pandas are organized in arrays. But Pandas assign a data type to columns rather than an entire array. This allows data of different types to be included in the same data structure. We can check the data type by either calling the info() function from the DataFrame:
|
1 2 |
... df.info() # print info to screen |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<class 'pandas.core.frame.DataFrame'> RangeIndex: 5319 entries, 0 to 5318 Data columns (total 32 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 State FIPS 5319 non-null int64 1 State 5319 non-null object 2 Tier 1 Code 5319 non-null int64 3 Tier 1 Description 5319 non-null object 4 Pollutant 5319 non-null object 5 emissions90 3926 non-null float64 6 emissions96 4163 non-null float64 7 emissions97 4163 non-null float64 ... 29 emissions19 5052 non-null float64 30 emissions20 5052 non-null float64 31 emissions21 5052 non-null float64 dtypes: float64(27), int64(2), object(3) memory usage: 1.3+ MB |
or we can also get the type as a pandas Series:
|
1 2 3 |
... coltypes = df.dtypes print(coltypes) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
State FIPS int64 State object Tier 1 Code int64 Tier 1 Description object Pollutant object emissions90 float64 emissions96 float64 emissions97 float64 ... emissions19 float64 emissions20 float64 emissions21 float64 dtype: object |
In pandas, a DataFrame is a table, while a Series is a column of the table. This distinction is important because data behind a DataFrame is a 2D array while a Series is a 1D array.
Similar to the fancy indexing in NumPy, we can extract columns from one DataFrame to create another:
|
1 2 3 4 |
... cols = ["State", "Pollutant", "emissions19", "emissions20", "emissions21"] last3years = df[cols] print(last3years) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
State Pollutant emissions19 emissions20 emissions21 0 AL CO 8.243679 8.243679 8.243679 1 AL NH3 0.417551 0.417551 0.417551 2 AL NOX 19.592480 13.752790 11.162100 3 AL PM10-PRI 2.868642 2.868642 2.868642 4 AL PM25-PRI 2.659792 2.659792 2.659792 ... ... ... ... ... ... 5314 WY NOX 0.374873 0.374873 0.374873 5315 WY PM10-PRI 2.857886 2.857886 2.857886 5316 WY PM25-PRI 2.421937 2.421937 2.421937 5317 WY SO2 0.208817 0.208817 0.208817 5318 WY VOC 6.645249 6.645249 6.645249 [5319 rows x 5 columns] |
Or, if we pass in a column name as a string rather than a list of column names, we extract a column from a DataFrame as a Series:
|
1 2 3 |
... data2021 = df["emissions21"] print(data2021) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
0 8.243679 1 0.417551 2 11.162100 3 2.868642 4 2.659792 ... 5314 0.374873 5315 2.857886 5316 2.421937 5317 0.208817 5318 6.645249 Name: emissions21, Length: 5319, dtype: float64 |
Essential Functions in DataFrame
Pandas is feature-rich. Many essential operations on a table or a column are provided as functions defined on the DataFrame or Series. For example, we can see a list of pollutants covered in the table above by using:
|
1 2 |
... print(df["Pollutant"].unique()) |
|
1 |
['CO' 'NH3' 'NOX' 'PM10-PRI' 'PM25-PRI' 'SO2' 'VOC'] |
And we can find the mean (mean()), standard deviation (std()), minimum (min()), and maximum (max()) of a series similarly:
|
1 2 |
... print(df["emissions21"].mean()) |
But in fact, we are more likely to use the describe() function to explore a new DataFrame. Since the DataFrame in this example has too many columns, it is better to transpose the resulting DataFrame from describe():
|
1 2 |
... print(df.describe().T) |
|
1 2 3 4 5 6 7 8 9 10 |
count mean std min 25% 50% 75% max State FIPS 5319.0 29.039481 15.667352 1.00000 16.000000 29.000000 42.000000 56.000000 Tier 1 Code 5319.0 8.213198 4.610970 1.00000 4.000000 8.000000 12.000000 16.000000 emissions90 3926.0 67.885173 373.308888 0.00000 0.474330 4.042665 20.610050 11893.764890 emissions96 4163.0 54.576353 264.951584 0.00001 0.338420 3.351860 16.804540 6890.969060 emissions97 4163.0 51.635867 249.057529 0.00001 0.335830 3.339820 16.679675 6547.791030 ... emissions19 5052.0 19.846244 98.392126 0.00000 0.125881 1.180123 7.906181 4562.151689 emissions20 5052.0 19.507828 97.515187 0.00000 0.125066 1.165284 7.737705 4562.151689 emissions21 5052.0 19.264532 96.702411 0.00000 0.125066 1.151917 7.754584 4562.151689 |
Indeed, the DataFrame produced by describe() can help us get a sense of the data. From there, we can tell how much missing data there is (by looking at the count), how the data are distributed, whether there are outliers, and so on.
Want to Get Started With Python for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Manipulating DataFrame and Series
Similar to the Boolean indexing in NumPy, we can extract a subset of rows from a DataFrame. For example, this is how we can select the data for carbon monoxide emissions only:
|
1 2 3 |
... df_CO = df[df["Pollutant"] == "CO"] print(df_CO) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
State FIPS State Tier 1 Code Tier 1 Description ... emissions18 emissions19 emissions20 emissions21 0 1 AL 1 FUEL COMB. ELEC. UTIL. ... 10.050146 8.243679 8.243679 8.243679 7 1 AL 2 FUEL COMB. INDUSTRIAL ... 19.148024 17.291741 17.291741 17.291741 14 1 AL 3 FUEL COMB. OTHER ... 29.207209 29.201838 29.201838 29.201838 21 1 AL 4 CHEMICAL & ALLIED PRODUCT MFG ... 2.774257 2.626484 2.626484 2.626484 28 1 AL 5 METALS PROCESSING ... 12.534726 12.167189 12.167189 12.167189 ... ... ... ... ... ... ... ... ... ... 5284 56 WY 11 HIGHWAY VEHICLES ... 70.776546 69.268149 64.493724 59.719298 5291 56 WY 12 OFF-HIGHWAY ... 31.092228 30.594383 30.603392 30.612400 5298 56 WY 14 MISCELLANEOUS ... 3.269705 3.828401 3.828401 3.828401 5305 56 WY 15 WILDFIRES ... 302.235376 89.399972 89.399972 89.399972 5312 56 WY 16 PRESCRIBED FIRES ... 70.578540 28.177445 28.177445 28.177445 [760 rows x 32 columns] |
As you may expect, the == operator compares each element from a series df["Pollutant"] , resulting in a series of Boolean. If the lengths match, the DataFrame understands it is to select the rows based on the Boolean value. In fact, we can combine Booleans using bitwise operators. For example, this is how we select the rows of carbon monoxide emissions due to highway vehicles:
|
1 2 3 |
... df_CO_HW = df[(df["Pollutant"] == "CO") & (df["Tier 1 Description"] == "HIGHWAY VEHICLES")] print(df_CO_HW) |
|
1 2 3 4 5 6 7 8 9 10 11 |
State FIPS State Tier 1 Code Tier 1 Description ... emissions18 emissions19 emissions20 emissions21 70 1 AL 11 HIGHWAY VEHICLES ... 532.140445 518.259811 492.182583 466.105354 171 2 AK 11 HIGHWAY VEHICLES ... 70.674008 70.674008 63.883471 57.092934 276 4 AZ 11 HIGHWAY VEHICLES ... 433.685363 413.347655 398.958109 384.568563 381 5 AR 11 HIGHWAY VEHICLES ... 228.213685 227.902883 215.937225 203.971567 ... 5074 54 WV 11 HIGHWAY VEHICLES ... 133.628312 126.836047 118.621857 110.407667 5179 55 WI 11 HIGHWAY VEHICLES ... 344.340392 374.804865 342.392977 309.981089 5284 56 WY 11 HIGHWAY VEHICLES ... 70.776546 69.268149 64.493724 59.719298 [51 rows x 32 columns] |
If you prefer to select rows like a Python list, you may do so via the iloc interface. This is how we can select rows 5 to 10 (zero-indexed) or columns 1 to 6 and rows 5 to 10:
|
1 2 3 |
... df_r5 = df.iloc[5:11] df_c1_r5 = df.iloc[5:11, 1:7] |
If you’re familiar with Excel, you probably know one of its exciting features called a “pivot table.” Pandas allows you to do the same. Let’s consider the pollution of carbon monoxide from all states in 2021 from this dataset:
|
1 2 3 |
... df_all_co = df[df["Pollutant"]=="CO"][["State", "Tier 1 Description", "emissions21"]] print(df_all_co) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
State FIPS State Tier 1 Code Tier 1 Description ... emissions18 emissions19 emissions20 emissions21 0 1 AL 1 FUEL COMB. ELEC. UTIL. ... 10.050146 8.243679 8.243679 8.243679 7 1 AL 2 FUEL COMB. INDUSTRIAL ... 19.148024 17.291741 17.291741 17.291741 14 1 AL 3 FUEL COMB. OTHER ... 29.207209 29.201838 29.201838 29.201838 21 1 AL 4 CHEMICAL & ALLIED PRODUCT MFG ... 2.774257 2.626484 2.626484 2.626484 28 1 AL 5 METALS PROCESSING ... 12.534726 12.167189 12.167189 12.167189 ... ... ... ... ... ... ... ... ... ... 5284 56 WY 11 HIGHWAY VEHICLES ... 70.776546 69.268149 64.493724 59.719298 5291 56 WY 12 OFF-HIGHWAY ... 31.092228 30.594383 30.603392 30.612400 5298 56 WY 14 MISCELLANEOUS ... 3.269705 3.828401 3.828401 3.828401 5305 56 WY 15 WILDFIRES ... 302.235376 89.399972 89.399972 89.399972 5312 56 WY 16 PRESCRIBED FIRES ... 70.578540 28.177445 28.177445 28.177445 [760 rows x 32 columns] |
Through the pivot table, we can make the different ways of emitting carbon monoxide as columns and different states as rows:
|
1 2 3 |
... df_pivot = df_all_co.pivot_table(index="State", columns="Tier 1 Description", values="emissions21") print(df_pivot) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Tier 1 Description CHEMICAL & ALLIED PRODUCT MFG FUEL COMB. ELEC. UTIL. ... WASTE DISPOSAL & RECYCLING WILDFIRES State ... AK NaN 4.679098 ... 0.146018 4562.151689 AL 2.626484 8.243679 ... 47.241253 38.780562 AR 0.307811 5.027354 ... 26.234267 3.125529 AZ 0.000000 4.483514 ... 6.438484 248.713896 ... WA 0.116416 4.831139 ... 2.334996 160.284327 WI 0.023691 7.422521 ... 35.670128 0.911783 WV 0.206324 7.836174 ... 16.012414 5.086241 WY 14.296860 14.617882 ... 1.952702 89.399972 [51 rows x 15 columns] |
The pivot_table() function above does not require the values to be unique to the index and columns. In other words, should there be two “wildfire” rows in a state in the original DataFrame, this function will aggregate the two (the default is to take the mean). To reverse the pivot operation, we have the melt() function:
|
1 2 3 |
... df_melt = df_pivot.melt(value_name="emissions 2021", var_name="Tier 1 Description", ignore_index=False) print(df_melt) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Tier 1 Description emissions 2021 State AK CHEMICAL & ALLIED PRODUCT MFG NaN AL CHEMICAL & ALLIED PRODUCT MFG 2.626484 AR CHEMICAL & ALLIED PRODUCT MFG 0.307811 AZ CHEMICAL & ALLIED PRODUCT MFG 0.000000 CA CHEMICAL & ALLIED PRODUCT MFG 0.876666 ... ... ... VT WILDFIRES 0.000000 WA WILDFIRES 160.284327 WI WILDFIRES 0.911783 WV WILDFIRES 5.086241 WY WILDFIRES 89.399972 [765 rows x 2 columns] |
There is way more we can do with a DataFrame. For example, we can sort the rows (using the sort_values() function), rename columns (using the rename() function), remove redundant rows (drop_duplicates() function), and so on.
In a machine learning project, we often need to do some clean-up before we can use the data. It is handy to use pandas for this purpose. The df_pivot DataFrame we just created has some values marked as NaN for no data available. We can replace all those with zero with any of the following:
|
1 2 3 |
df_pivot.fillna(0) df_pivot.where(df_pivot.notna(), 0) df_pivot.mask(df_pivot.isna(), 0) |
Aggregation in DataFrames
In fact, pandas can provide table manipulation that otherwise can only be easily done using database SQL statements. Reusing the above example dataset, each pollutant in the table is broken down into different sources. If we want to know the aggregated pollutant emissions, we can just sum up all the sources. Similar to SQL, this is a “group by” operation. We can do so with the following:
|
1 2 3 |
... df_sum = df[df["Pollutant"]=="CO"].groupby("State").sum() print(df_sum) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
State FIPS Tier 1 Code emissions90 emissions96 ... emissions18 emissions19 emissions20 emissions21 State ... AK 28 115 4502.12238 883.50805 ... 5216.369575 5218.919502 5211.711803 5204.504105 AL 15 123 3404.01163 2440.95216 ... 1574.068371 1350.711872 1324.945132 1299.178392 AR 75 123 1706.69006 1356.08524 ... 1168.110471 1055.635824 1043.724418 1031.813011 AZ 60 123 2563.04249 1876.55422 ... 1000.976184 977.916197 964.504353 951.092509 ... WA 795 123 3604.39515 2852.52146 ... 1703.948955 1286.715920 1266.983767 1247.251614 WI 825 123 2849.49820 2679.75457 ... 922.375165 872.231181 838.232783 804.234385 WV 810 123 1270.81719 941.39753 ... 424.120829 395.720171 387.565561 379.410950 WY 840 123 467.80484 1598.56712 ... 549.270377 306.461296 301.695879 296.930461 [51 rows x 29 columns] |
The result of the groupby() function will use the grouping column as the row index. It works by putting rows that have the same value for that grouping column into a group. Then as a group, some aggregate function is applied to reduce the many rows into one. In the above example, we are taking the sum across each column. Pandas comes with many other aggregate functions, such as taking the mean or just counting the number of rows. Since we are doing sum(), the non-numeric columns are dropped from the output as they do not apply to the operation.
This allows us to do some interesting tasks. Let’s say, using the data in the DataFrame above, we create a table of the total emission of carbon monoxide (CO) and sulfur dioxide (SO2) in 2021 in each state. The reasoning on how to do that would be:
- Group by “State” and “Pollutant,” then sum up each group. This is how we get the total emission of each pollutant in each state.
- Select only the column for 2021
- Run pivot table to make states the rows and the pollutants the columns with the total emission as the values
- Select only the column for CO and SO2
In code, this can be:
|
1 2 3 4 5 6 7 8 9 |
... df_2021 = ( df.groupby(["State", "Pollutant"]) .sum() # get total emissions of each year [["emissions21"]] # select only year 2021 .reset_index() .pivot(index="State", columns="Pollutant", values="emissions21") .filter(["CO","SO2"]) ) print(df_2021) |
|
1 2 3 4 5 6 7 8 9 10 11 |
Pollutant CO SO2 State AK 5204.504105 32.748621 AL 1299.178392 52.698696 AR 1031.813011 55.288823 AZ 951.092509 15.281760 ... WA 1247.251614 13.178053 WI 804.234385 21.141688 WV 379.410950 49.159621 WY 296.930461 37.056612 |
In the above code, each step after the groupby() function is to create a new DataFrame. Since we are using functions defined under DataFrame, we have the above functional chained invocation syntax.
The sum() function will create a DataFrame from the GroupBy object that has the grouped columns “State” and “Pollutant” as an index. Therefore, after we diced the DataFrame to only one column, we used reset_index() to make the index as columns (i.e., there will be three columns, State, Pollutant, and emissions21). Since there will be more pollutants than we need, we use filter() to select only the columns for CO and SO2 from the resulting DataFrame. This is similar to using fancy indexing to select columns.
Indeed, we can do the same differently:
- Select only the rows for CO and compute the total emission; select only the data for 2021
- Do the same for SO2
- Combine the resulting DataFrame in the previous two steps
In pandas, there is a join() function in DataFrame that helps us combine the columns with another DataFrame by matching the index. In code, the above steps are as follows:
|
1 2 3 4 |
... df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}) df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}) df_joined = df_co.join(df_so2) |
The join() function is limited to index matching. If you’re familiar with SQL, the JOIN clause’s equivalent in pandas is the merge() function. If the two DataFrames we created for CO and SO2 have the states as a separate column, we can do the same as follows:
|
1 2 3 |
df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}).reset_index() df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}).reset_index() df_merged = df_co.merge(df_so2, on="State", how="outer") |
The merge() function in pandas can do all types of SQL joins. We can match different columns from a different DataFrame, and we can do left join, right join, inner join, and outer join. This will be very useful when wrangling the data for your project.
The groupby() function in a DataFrame is powerful as it allows us to manipulate the DataFrame flexibly and opens the door to many sophisticated transformations. There may be a case that no built-in function can help after groupby(), but we can always provide our own. For example, this is how we can create a function to operate on a sub-DataFrame (on all columns except the group-by column) and apply it to find the years of minimum and maximum emissions:
|
1 2 3 4 5 6 7 8 9 |
... def minmaxyear(subdf): sum_series = subdf.sum() year_indices = [x for x in sum_series if x.startswith("emissions")] minyear = sum_series[year_indices].astype(float).idxmin() maxyear = sum_series[year_indices].astype(float).idxmax() return pd.Series({"min year": minyear[-2:], "max year": maxyear[-2:]}) df_years = df[df["Pollutant"]=="CO"].groupby("State").apply(minmaxyear) |
The apply() function is the last resort to provide us the maximum flexibility. Besides GroupBy objects, there are also apply() interfaces in DataFrames and Series.
The following is the complete code to demonstrate all operations we introduced above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
import pandas as pd # Pollutants data from Environmental Protection Agency URL = "https://www.epa.gov/sites/default/files/2021-03/state_tier1_caps.xlsx" # Read the Excel file and print df = pd.read_excel(URL, sheet_name="State_Trends", header=1) print("US air pollutant emission data:") print(df) # Show info print("\nInformation about the DataFrame:") df.info() # print dtyes coltypes = df.dtypes print("\nColumn data types of the DataFrame:") print(coltypes) # Get last 3 columns cols = ["State", "Pollutant", "emissions19", "emissions20", "emissions21"] last3years = df[cols] print("\nDataFrame of last 3 years data:") print(last3years) # Get a series data2021 = df["emissions21"] print("\nSeries of 2021 data:") print(data2021) # Print unique pollutants print("\nUnique pollutants:") print(df["Pollutant"].unique()) # print mean emission print("\nMean on the 2021 series:") print(df["emissions21"].mean()) # Describe print("\nBasic statistics about each column in the DataFrame:") print(df.describe().T) # Get CO only df_CO = df[df["Pollutant"] == "CO"] print("\nDataFrame of only CO pollutant:") print(df_CO) # Get CO and Highway only df_CO_HW = df[(df["Pollutant"] == "CO") & (df["Tier 1 Description"] == "HIGHWAY VEHICLES")] print("\nDataFrame of only CO pollutant from Highway vehicles:") print(df_CO_HW) # Get DF of all CO df_all_co = df[df["Pollutant"]=="CO"][["State", "Tier 1 Description", "emissions21"]] print("\nDataFrame of only CO pollutant, keep only essential columns:") print(df_all_co) # Pivot df_pivot = df_all_co.pivot_table(index="State", columns="Tier 1 Description", values="emissions21") print("\nPivot table of state vs CO emission source:") print(df_pivot) # melt df_melt = df_pivot.melt(value_name="emissions 2021", var_name="Tier 1 Description", ignore_index=False) print("\nMelting the pivot table:") print(df_melt) # all three are the same df_filled = df_pivot.fillna(0) df_filled = df_pivot.where(df_pivot.notna(), 0) df_filled = df_pivot.mask(df_pivot.isna(), 0) print("\nFilled missing value as zero:") print(df_filled) # aggregation df_sum = df[df["Pollutant"]=="CO"].groupby("State").sum() print("\nTotal CO emission by state:") print(df_sum) # group by df_2021 = ( df.groupby(["State", "Pollutant"]) .sum() # get total emissions of each year [["emissions21"]] # select only year 2021 .reset_index() .pivot(index="State", columns="Pollutant", values="emissions21") .filter(["CO","SO2"]) ) print("\nComparing CO and SO2 emission:") print(df_2021) # join df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}) df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}) df_joined = df_co.join(df_so2) print("\nComparing CO and SO2 emission:") print(df_joined) # merge df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}).reset_index() df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}).reset_index() df_merged = df_co.merge(df_so2, on="State", how="outer") print("\nComparing CO and SO2 emission:") print(df_merged) def minmaxyear(subdf): sum_series = subdf.sum() year_indices = [x for x in sum_series if x.startswith("emissions")] minyear = sum_series[year_indices].astype(float).idxmin() maxyear = sum_series[year_indices].astype(float).idxmax() return pd.Series({"min year": minyear[-2:], "max year": maxyear[-2:]}) df_years = df[df["Pollutant"]=="CO"].groupby("State").apply(minmaxyear) print("\nYears of minimum and maximum emissions:") print(df_years) |
Handling Time Series Data in Pandas
You will find another powerful feature from pandas if you are dealing with time series data. To begin, let’s consider some daily pollution data. We can select and download some from the EPA’s website:
For illustration purposes, we downloaded the PM2.5 data of Texas in 2021. We can import the downloaded CSV file, ad_viz_plotval_data.csv, as follows:
|
1 2 |
df = pd.read_csv("ad_viz_plotval_data.csv", parse_dates=[0]) print(df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Date Source Site ID POC ... COUNTY_CODE COUNTY SITE_LATITUDE SITE_LONGITUDE 0 2021-01-01 AQS 480131090 1 ... 13 Atascosa 29.162997 -98.589158 1 2021-01-02 AQS 480131090 1 ... 13 Atascosa 29.162997 -98.589158 2 2021-01-03 AQS 480131090 1 ... 13 Atascosa 29.162997 -98.589158 3 2021-01-04 AQS 480131090 1 ... 13 Atascosa 29.162997 -98.589158 4 2021-01-05 AQS 480131090 1 ... 13 Atascosa 29.162997 -98.589158 ... ... ... ... ... ... ... ... ... ... 19695 2021-12-27 AQS 484790313 1 ... 479 Webb 27.599444 -99.533333 19696 2021-12-28 AQS 484790313 1 ... 479 Webb 27.599444 -99.533333 19697 2021-12-29 AQS 484790313 1 ... 479 Webb 27.599444 -99.533333 19698 2021-12-30 AQS 484790313 1 ... 479 Webb 27.599444 -99.533333 19699 2021-12-31 AQS 484790313 1 ... 479 Webb 27.599444 -99.533333 [19700 rows x 20 columns] |
The read_csv() function from pandas allows us to specify some columns as the date and parse them into datetime objects rather than a string. This is essential for further processing time series data. As we know, the first column (zero-indexed) is the date column; we provide the argument parse_dates=[0] above.
For manipulating time series data, it is important to use time as an index in your DataFrame. We can make one of the columns an index by the set_index() function:
|
1 2 3 |
... df_pm25 = df.set_index("Date") print(df_pm25) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Source Site ID POC Daily Mean PM2.5 Concentration ... COUNTY_CODE COUNTY SITE_LATITUDE SITE_LONGITUDE Date ... 2021-01-01 AQS 480131090 1 4.6 ... 13 Atascosa 29.162997 -98.589158 2021-01-02 AQS 480131090 1 3.7 ... 13 Atascosa 29.162997 -98.589158 2021-01-03 AQS 480131090 1 6.3 ... 13 Atascosa 29.162997 -98.589158 2021-01-04 AQS 480131090 1 6.4 ... 13 Atascosa 29.162997 -98.589158 2021-01-05 AQS 480131090 1 7.7 ... 13 Atascosa 29.162997 -98.589158 ... ... ... ... ... ... ... ... ... ... 2021-12-27 AQS 484790313 1 15.7 ... 479 Webb 27.599444 -99.533333 2021-12-28 AQS 484790313 1 17.6 ... 479 Webb 27.599444 -99.533333 2021-12-29 AQS 484790313 1 14.1 ... 479 Webb 27.599444 -99.533333 2021-12-30 AQS 484790313 1 18.5 ... 479 Webb 27.599444 -99.533333 2021-12-31 AQS 484790313 1 21.5 ... 479 Webb 27.599444 -99.533333 [19700 rows x 19 columns] |
If we examine the index of this DataFrame, we will see the following:
|
1 2 |
... print(df_pm25.index) |
|
1 2 3 4 5 6 7 8 |
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08', '2021-01-09', '2021-01-10', ... '2021-12-22', '2021-12-23', '2021-12-24', '2021-12-25', '2021-12-26', '2021-12-27', '2021-12-28', '2021-12-29', '2021-12-30', '2021-12-31'], dtype='datetime64[ns]', name='Date', length=19700, freq=None) |
We know its type is datetime64, which is a timestamp object in pandas.
From the index above, we can see each date is not unique. This is because the PM2.5 concentration is observed in different sites, and each will contribute a row to the DataFrame. We can filter the DataFrame to only one site to make the index unique. Alternatively, we can use pivot_table() to transform the DataFrame, where the pivot operation guarantees the resulting DataFrame will have unique index:
|
1 2 3 4 5 6 |
df_2021 = ( df[["Date", "Daily Mean PM2.5 Concentration", "Site Name"]] .pivot_table(index="Date", columns="Site Name", values="Daily Mean PM2.5 Concentration") ) print(df_2021) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Site Name Amarillo A&M Ascarate Park SE Austin North Hills Drive ... Von Ormy Highway 16 Waco Mazanec World Trade Bridge Date ... 2021-01-01 1.7 11.9 3.0 ... 4.6 2.7 4.4 2021-01-02 2.2 7.8 6.1 ... 3.7 2.2 6.1 2021-01-03 2.5 4.2 4.3 ... 6.3 4.2 8.5 2021-01-04 3.7 8.1 3.7 ... 6.4 4.2 5.7 2021-01-05 4.5 10.0 5.2 ... 7.7 6.1 7.1 ... ... ... ... ... ... ... ... 2021-12-27 1.9 5.8 11.0 ... 13.8 10.5 15.7 2021-12-28 1.8 6.6 14.1 ... 17.7 9.7 17.6 2021-12-29 NaN 8.1 21.8 ... 28.6 12.5 14.1 2021-12-30 4.0 9.5 13.1 ... 20.4 13.4 18.5 2021-12-31 3.6 3.7 16.3 ... 18.3 11.8 21.5 [365 rows x 53 columns] |
We can check the uniqueness with:
|
1 |
df_2021.index.is_unique |
Now, every column in this DataFrame is a time series. While pandas does not provide any forecasting function on the time series, it comes with tools to help you clean and transform the data. Setting a DateTimeIndex to a DataFrame will be handy for time series analysis projects because we can easily extract data for a time interval, e.g., the train-test split of the time series. Below is how we can extract a 3-month subset from the above DataFrame:
|
1 |
df_3month = df_2021["2021-04-01":"2021-07-01"] |
One commonly used function in a time series is to resample the data. Considering the daily data in this DataFrame, we can transform it into weekly observations instead. We can specify the resulting data to be indexed on every Sunday. But we still have to tell what we want the resampled data to be like. If it is sales data, we probably want to sum over the entire week to get the weekly revenue. In this case, we can take the average over a week to smooth out the fluctuations. An alternative is to take the first observation over each period, like below:
|
1 2 3 |
... df_resample = df_2021.resample("W-SUN").first() print(df_resample) |
|
1 2 3 4 5 6 7 8 9 10 11 |
Site Name Amarillo A&M Ascarate Park SE Austin North Hills Drive ... Von Ormy Highway 16 Waco Mazanec World Trade Bridge Date ... 2021-01-03 1.7 11.9 3.0 ... 4.6 2.7 4.4 2021-01-10 3.7 8.1 3.7 ... 6.4 4.2 5.7 2021-01-17 5.8 5.3 7.0 ... 5.4 6.9 4.8 ... 2021-12-19 3.6 13.0 6.3 ... 6.9 5.9 5.5 2021-12-26 5.3 10.4 5.7 ... 5.5 5.4 3.9 2022-01-02 1.9 5.8 11.0 ... 13.8 10.5 15.7 [53 rows x 53 columns] |
The string “W-SUN” is to determine the mean weekly on Sundays. It is called the “offset alias.” You can find the list of all offset alias from below:
Resampling is particularly useful in financial market data. Imagine if we have the price data from the market, where the raw data does not come in regular intervals. We can still use resampling to convert the data into regular intervals. Because it is so commonly used, pandas even provides you the open-high-low-close (known as OHLC, i.e., first, maximum, minimum, and last observations over a period) from the resampling. We demonstrate below how to get the OHLC over a week on one of the observation sites:
|
1 2 |
df_ohlc = df_2021["San Antonio Interstate 35"].resample("W-SUN").ohlc() print(df_ohlc) |
|
1 2 3 4 5 6 7 8 9 10 11 |
open high low close Date 2021-01-03 4.2 12.6 4.2 12.6 2021-01-10 9.7 9.7 3.0 5.7 2021-01-17 5.4 13.8 3.0 13.8 2021-01-24 9.5 11.5 5.7 9.0 ... 2021-12-12 5.7 20.0 5.7 20.0 2021-12-19 9.7 9.7 3.9 3.9 2021-12-26 6.1 14.7 6.0 14.7 2022-01-02 10.9 23.7 10.9 16.3 |
In particular, if we resample a time series from a coarser frequency into a finer frequency, it is called upsampling. Pandas usually inserts NaN values during upsampling as the original time series does not have data during the in-between time instances. One way to avoid these NaN values during upsampling is to ask pandas to forward-fill (carry over values from an earlier time) or back-fill (using values from a later time) the data. For example, the following is to forward-fill the daily PM2.5 observations from one site into hourly:
|
1 2 3 |
... series_ffill = df_2021["San Antonio Interstate 35"].resample("H").ffill() print(series_ffill) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Date 2021-01-01 00:00:00 4.2 2021-01-01 01:00:00 4.2 2021-01-01 02:00:00 4.2 2021-01-01 03:00:00 4.2 2021-01-01 04:00:00 4.2 ... 2021-12-30 20:00:00 18.2 2021-12-30 21:00:00 18.2 2021-12-30 22:00:00 18.2 2021-12-30 23:00:00 18.2 2021-12-31 00:00:00 16.3 Freq: H, Name: San Antonio Interstate 35, Length: 8737, dtype: float64 |
Besides resampling, we can also transform the data using a sliding window. For example, below is how we can make a 10-day moving average from the time series. It is not a resampling because the resulting data is still daily. But for each data point, it is the mean of the past 10 days. Similarly, we can find the 10-day standard deviation or 10-day maximum by applying a different function to the rolling object.
|
1 2 3 |
... df_mean = df_2021["San Antonio Interstate 35"].rolling(10).mean() print(df_mean) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Date 2021-01-01 NaN 2021-01-02 NaN 2021-01-03 NaN 2021-01-04 NaN 2021-01-05 NaN ... 2021-12-27 8.30 2021-12-28 9.59 2021-12-29 11.57 2021-12-30 12.78 2021-12-31 13.24 Name: San Antonio Interstate 35, Length: 365, dtype: float64 |
To show how the original and rolling average time series differs, below shows you the plot. We added the argument min_periods=5 to the rolling() function because the original data has missing data on some days. This produces gaps in the daily data, but we ask that the mean still be computed as long as there are 5 data points over the window of the past 10 days.
|
1 2 3 4 5 6 7 8 9 |
... import matplotlib.pyplot as plt fig = plt.figure(figsize=(12,6)) plt.plot(df_2021["San Antonio Interstate 35"], label="daily") plt.plot(df_2021["San Antonio Interstate 35"].rolling(10, min_periods=5).mean(), label="10-day MA") plt.legend() plt.ylabel("PM 2.5") plt.show() |
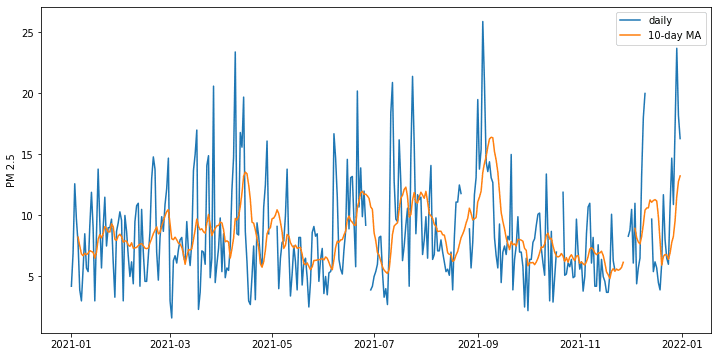
The following is the complete code to demonstrate the time series operations we introduced above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import pandas as pd import matplotlib.pyplot as plt # Load time series df = pd.read_csv("ad_viz_plotval_data.csv", parse_dates=[0]) print("Input data:") print(df) # Set date index df_pm25 = df.set_index("Date") print("\nUsing date index:") print(df_pm25) print(df_pm25.index) # 2021 daily df_2021 = ( df[["Date", "Daily Mean PM2.5 Concentration", "Site Name"]] .pivot_table(index="Date", columns="Site Name", values="Daily Mean PM2.5 Concentration") ) print("\nUsing date index:") print(df_2021) print(df_2021.index.is_unique) # Time interval df_3mon = df_2021["2021-04-01":"2021-07-01"] print("\nInterval selection:") print(df_3mon) # Resample print("\nResampling dataframe:") df_resample = df_2021.resample("W-SUN").first() print(df_resample) print("\nResampling series for OHLC:") df_ohlc = df_2021["San Antonio Interstate 35"].resample("W-SUN").ohlc() print(df_ohlc) print("\nResampling series with forward fill:") series_ffill = df_2021["San Antonio Interstate 35"].resample("H").ffill() print(series_ffill) # rolling print("\nRolling mean:") df_mean = df_2021["San Antonio Interstate 35"].rolling(10).mean() print(df_mean) # Plot moving average fig = plt.figure(figsize=(12,6)) plt.plot(df_2021["San Antonio Interstate 35"], label="daily") plt.plot(df_2021["San Antonio Interstate 35"].rolling(10, min_periods=5).mean(), label="10-day MA") plt.legend() plt.ylabel("PM 2.5") plt.show() |
Further Reading
Pandas is a feature-rich library with far more details than we can cover above. The following are some resources for you to go deeper:
API documentation
Books
- Python for Data Analysis, 2nd edition, by Wes McKinney
Summary
In this tutorial, you saw a brief overview of the functions provided by pandas.
Specifically, you learned:
- How to work with pandas DataFrames and Series
- How to manipulate DataFrames in a way similar to table operations in a relational database
- How to make use of pandas to help manipulate time series data
Get a Handle on Python for Machine Learning!

Be More Confident to Code in Python
...from learning the practical Python tricks
Discover how in my new Ebook:
Python for Machine Learning
It provides self-study tutorials with hundreds of working code to equip you with skills including:
debugging, profiling, duck typing, decorators, deployment,
and much more...






No comments yet.