Before you can select and prepare your data for modeling, you need to understand what you’ve got to start with.
If you’re a using the Python stack for machine learning, a library that you can use to better understand your data is Pandas.
In this post you will discover some quick and dirty recipes for Pandas to improve the understanding of your data in terms of it’s structure, distribution and relationships.
Kick-start your project with my new book Machine Learning Mastery With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Update March/2018: Added alternate link to download the dataset as the original appears to have been taken down.
Data Analysis
Data analysis is about asking and answering questions about your data.
As a machine learning practitioner, you may not be very familiar with the domain in which you’re working. It’s ideal to have subject matter experts on hand, but this is not always possible.
These problems also apply when you are learning applied machine learning either with standard machine learning data sets, consulting or working on competition data sets.
You need to spark questions about your data that you can pursue. You need to better understand the data that you have. You can do that by summarizing and visualizing your data.
Pandas
The Pandas Python library is built for fast data analysis and manipulation. It’s both amazing in its simplicity and familiar if you have worked on this task on other platforms like R.
The strength of Pandas seems to be in the data manipulation side, but it comes with very handy and easy to use tools for data analysis, providing wrappers around standard statistical methods in statsmodels and graphing methods in matplotlib.
Onset of Diabetes
We need a small dataset that you can use to explore the different data analysis recipes with Pandas.
The UIC Machine Learning repository provides a vast array of different standard machine learning datasets you can use to study and practice applied machine learning. A favorite of mine is the Pima Indians diabetes dataset.
The dataset describes the onset or lack of onset of diabetes in female Pima Indians using details from their medical records. (update: download from here). Download the dataset and save it into your current working directory with the name pima-indians-diabetes.data.
Summarize Data
We will start out by understanding the data that we have by looking at it’s structure.
Load Data
Start by loading the CSV data from file into memory as a data frame. We know the names of the data provided, so we will set those names when loading the data from the file.
We can take a look at the first 60 rows of data by printing the data frame directly.
Python
1
print(data)
We can see that all of the data is numeric and that the class value on the end is the dependent variable that we want to make predictions about.
At the end of the data dump we can see the description of the data frame itself as a 768 rows and 9 columns. So now we have idea of the shape of our data.
Next we can get a feeling for the distribution of each attribute by reviewing summary statistics.
Python
1
print(data.describe())
This displays a table of detailed distribution information for each of the 9 attributes in our data frame. Specifically: the count, mean, standard deviation, min, max, and 25th, 50th (median), 75th percentiles.
We can review these statistics and start noting interesting facts about our problem. Such as the average number of pregnancies is 3.8, the minimum age is 21 and some people have a body mass index of 0, which is impossible and a sign that some of the attribute values should be marked as missing.
A graph is a lot more telling about the distribution and relationships of attributes.
Nevertheless, it is important to take your time and review the statistics first. Each time you review the data a different way, you open yourself up to noticing different aspects and potentially achieving different insights into the problem.
The first and easy property to review is the distribution of each attribute.
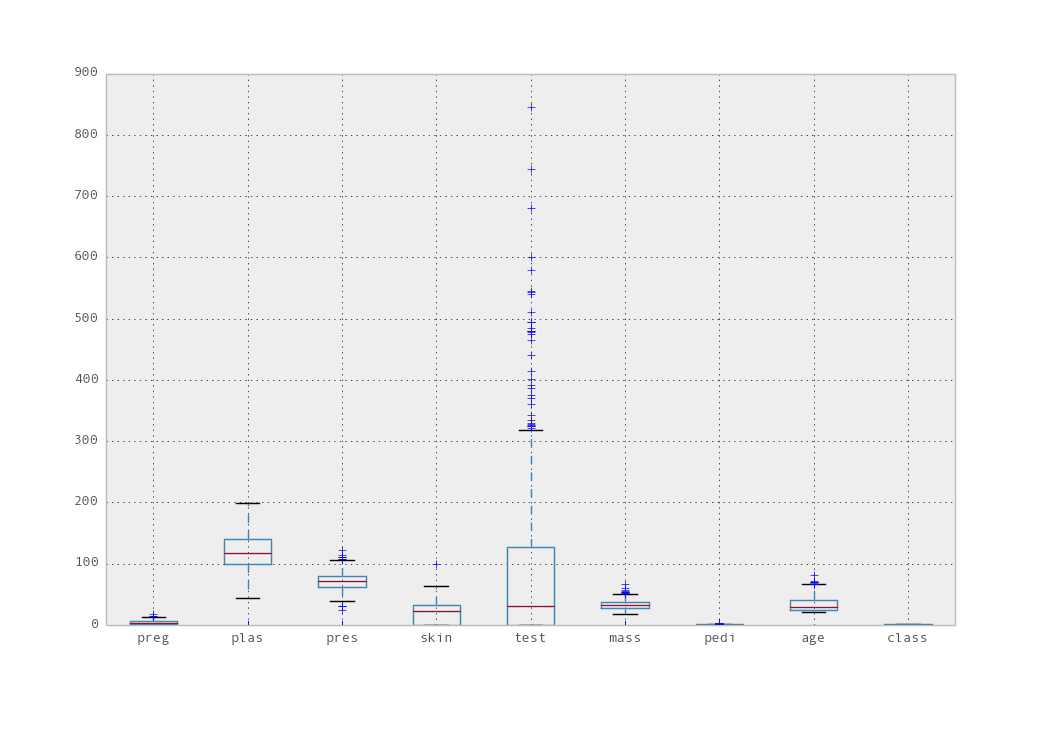
We can start out and review the spread of each attribute by looking at box and whisker plots.
Python
1
2
importmatplotlib.pyplot asplt
data.boxplot()
This snippet changes the style for drawing graphs (via matplotlib) to the default style, which looks better.
Attribute box and whisker plots
We can see that the test attribute has a lot of outliers. We can also see that the plas attribute seems to have a relatively even normal distribution. We can also look at the distribution of each attribute by discretization the values into buckets and review the frequency in each bucket as histograms.
Python
1
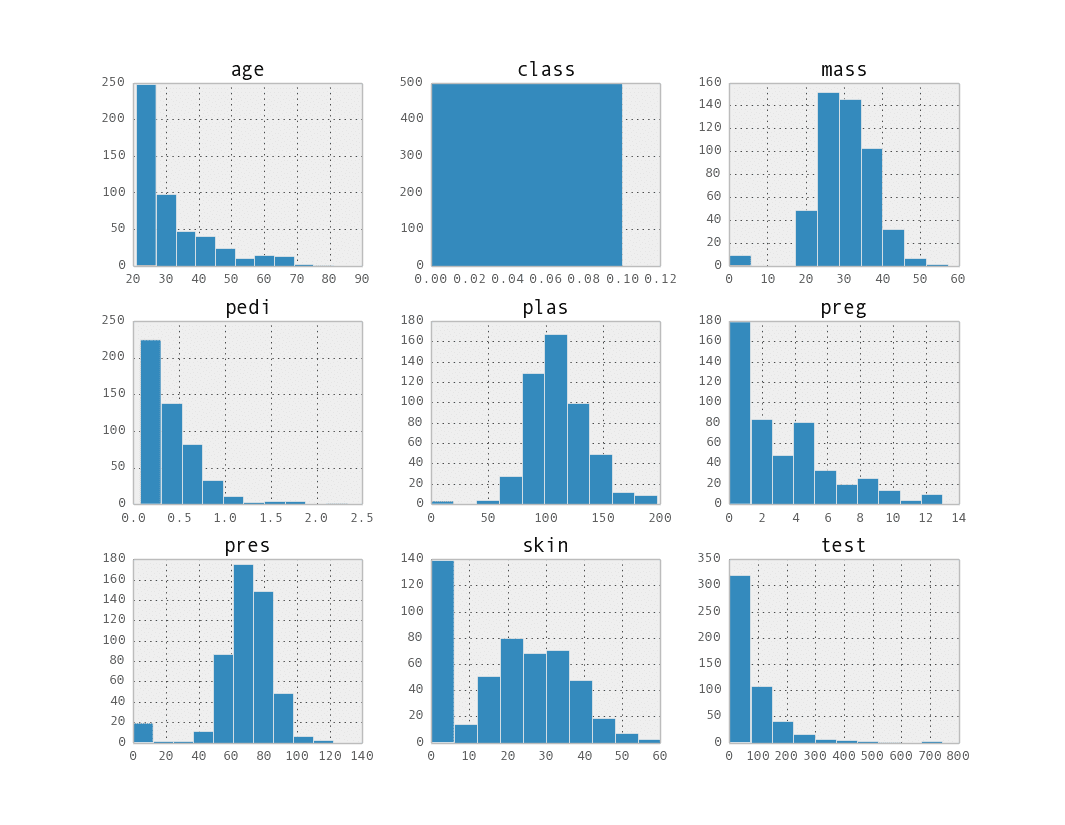
data.hist()
This lets you note interesting properties of the attribute distributions such as the possible normal distribution of attributes like pres and skin.
The next important relationship to explore is that of each attribute to the class attribute.
One approach is to visualize the distribution of attributes for data instances for each class and note and differences. You can generate a matrix of histograms for each attribute and one matrix of histograms for each class value, as follows:
Python
1
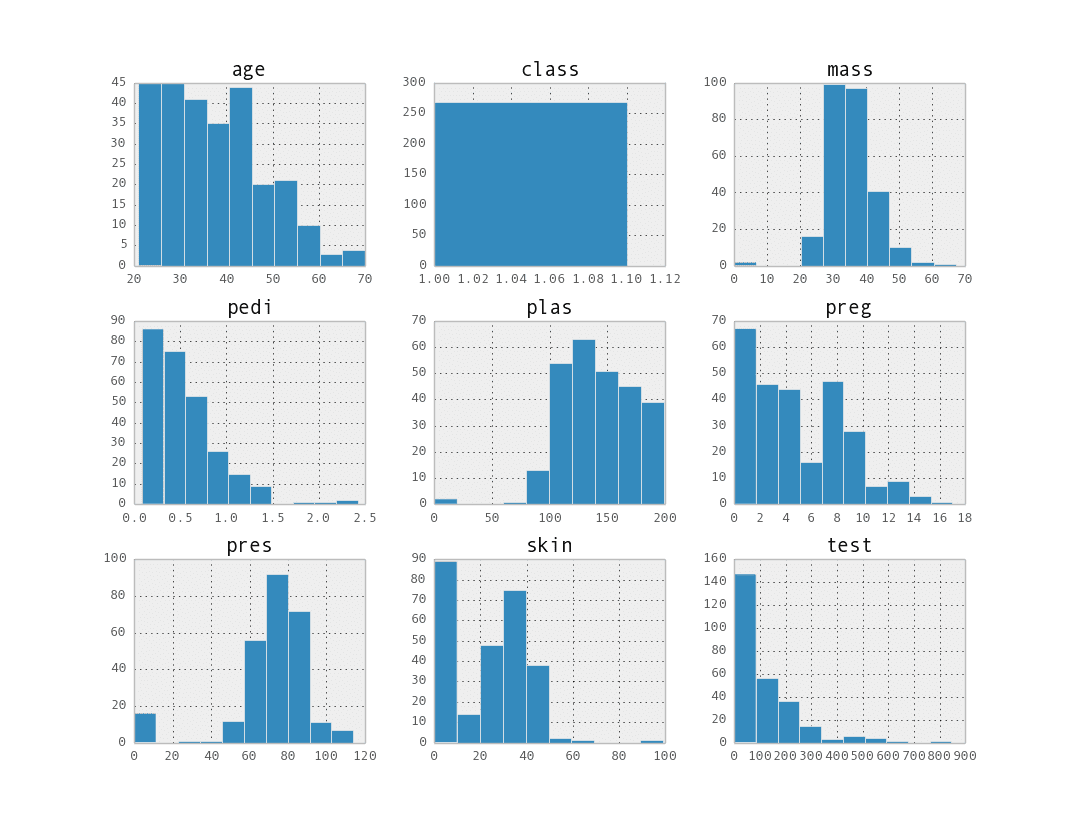
data.groupby('class').hist()
The data is grouped by the class attribute (two groups) then a matrix of histograms is created for the attributes is in each group. The result is two images.
Attribute Histogram Matrix for Class 0
Attribute Histogram Matrix for Class 1
This helps to point out differences in the distributions between the classes like those for the plas attribute.
You can better contrast the attribute values for each class on the same plot
1
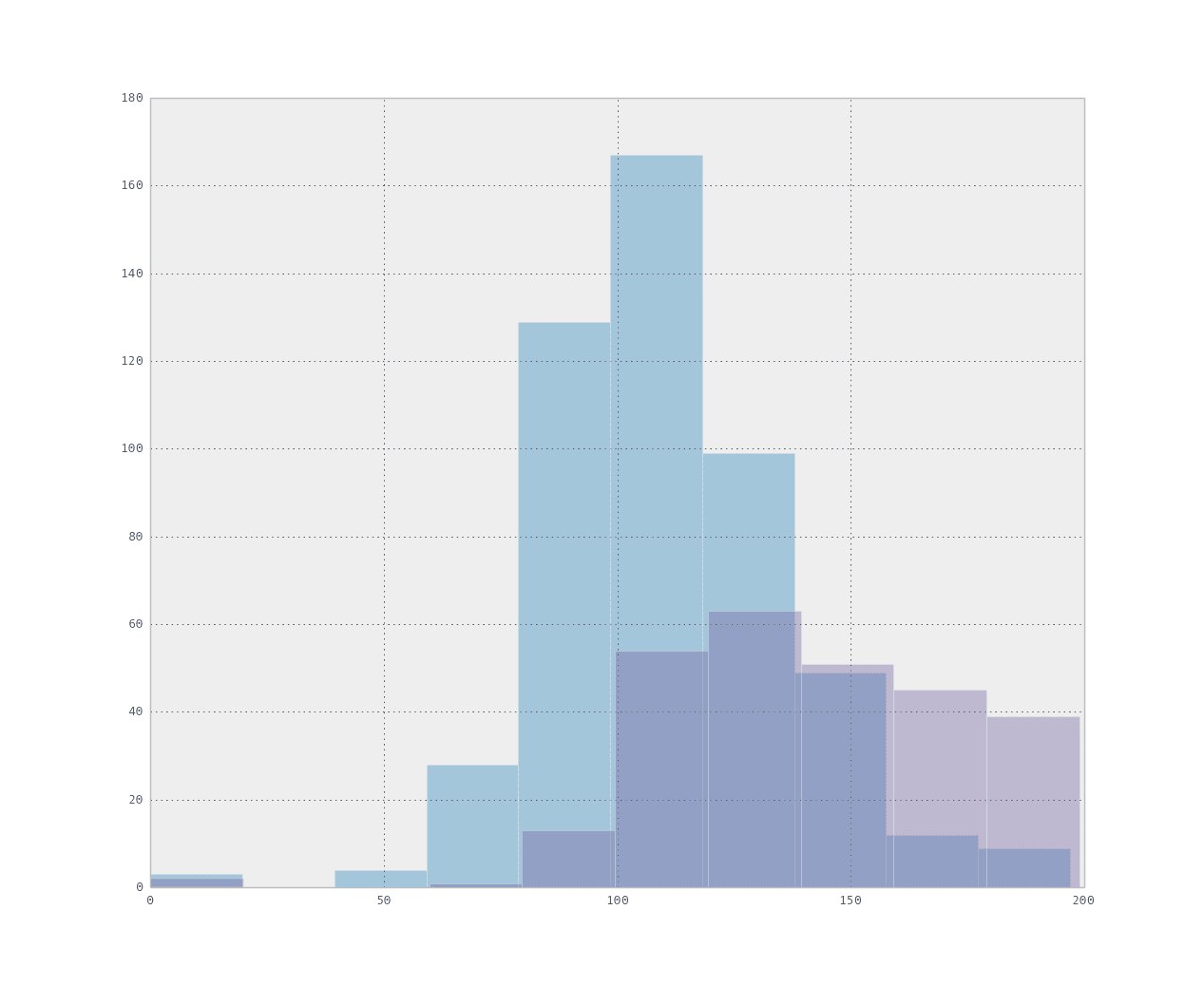
data.groupby('class').plas.hist(alpha=0.4)
This groups the data by class by only plots the histogram of plas showing the class value of 0 in red and the class value of 1 in blue. You can see a similar shaped normal distribution, but a shift. This attribute is likely going to be useful to discriminate the classes.
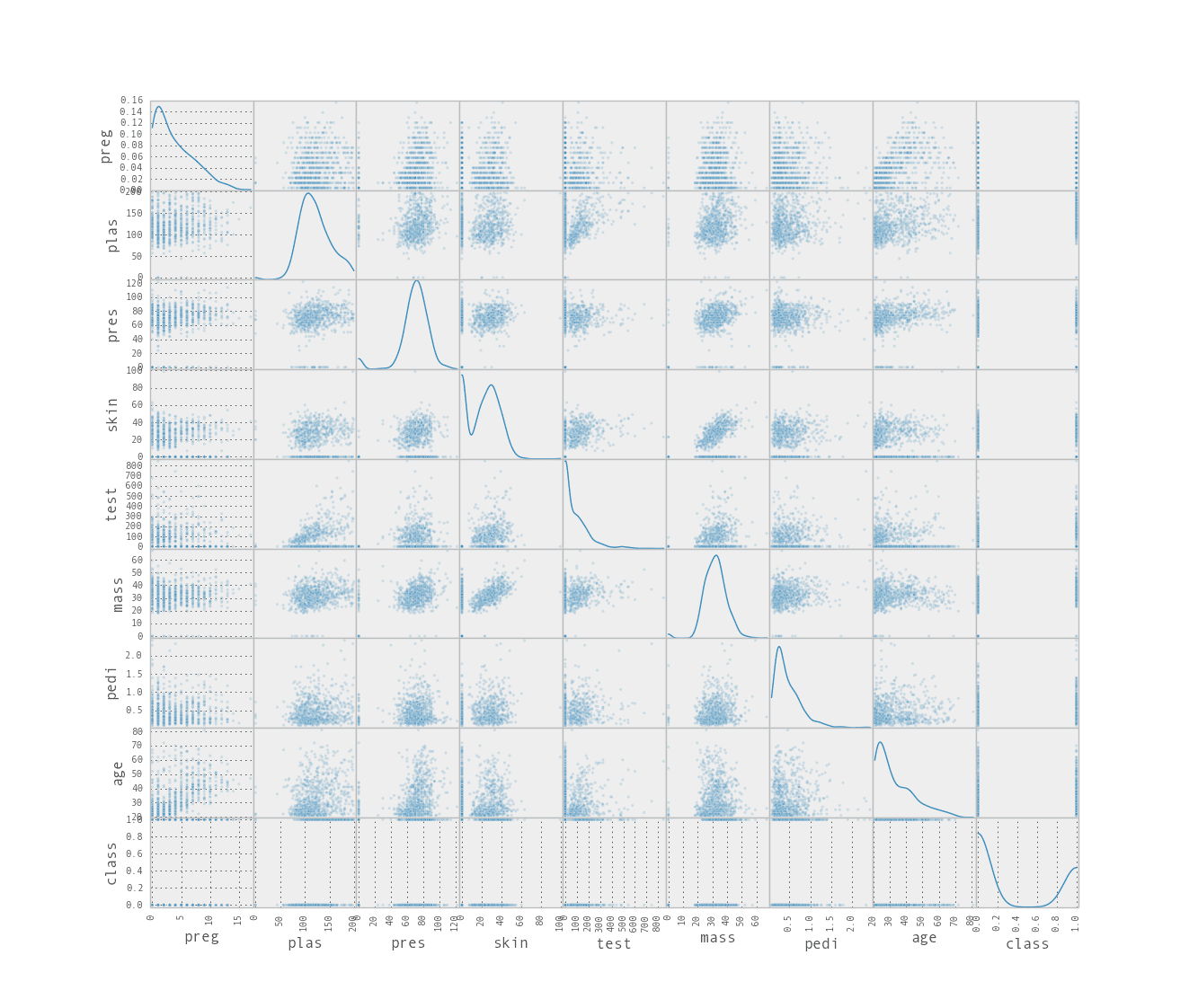
This uses a built function to create a matrix of scatter plots of all attributes versus all attributes. The diagonal where each attribute would be plotted against itself shows the Kernel Density Estimation of the attribute instead.
Attribute Scatter Plot Matrix
This is a powerful plot from which a lot of inspiration about the data can be drawn. For example, we can see a possible correlation between age and preg and another possible relationship between skin and mass.
Summary
We have covered a lot of ground in this post.
We started out looking at quick and dirty one-liners for loading our data in CSV format and describing it using summary statistics.
Next we looked at various different approaches to plotting our data to expose interesting structures. We looked at the distribution of the data in box and whisker plots and histograms, then we looked at the distribution of attributes compared to the class attribute and finally at the relationships between attributes in pair-wise scatter plots.
The first four plots appear, but the last one doesn’t. Changing the position of the line has no impact. Only when I comment the first four plots will the last one appear.
For me even the first plot not coming up. I get this error when I run that command?
_IceTransSocketUNIXConnect: Cannot connect to non-local host vl-sankumar-ice
_IceTransSocketUNIXConnect: Cannot connect to non-local host vl-sankumar-ice
Qt: Session management error: Could not open network socket
Hi, this is a very nice post about first exploratory techniques to use.
I have a few questions :
– How did you save your figures to have such nice layouts ? Could you please complete your script with the adequate lines ?
– Do you know a way to have a scatter matrix with in diagonals kde for each class ?
No related to this work but, i am new to ML and CNN and would like to do something with signal processing involving time series filtring… any place where i can get some directions please?
Wow! have been using pandas a while for machine learning but I never knew that it had integrated plotting functions, incredible information. Willful ignorance on my part I guess but thanks a lot Jason! Great insight as always.








This post is a great tool, but I encounter a bug I can’t overcome. I’m running the following script (in python 2.7) :
pima = pan.read_csv(PIMA_FILE, names = COLUMN_NAMES)
pan.options.display.mpl_style = ‘default’
pima.boxplot()
pima.hist()
pima.groupby(‘diabetic’).hist()
scatter_matrix(pima, alpha=0.2, figsize=(6, 6), diagonal=’kde’)
pima.groupby(‘diabetic’).glucose.hist(alpha=0.4)
The first four plots appear, but the last one doesn’t. Changing the position of the line has no impact. Only when I comment the first four plots will the last one appear.
Hi,
For me even the first plot not coming up. I get this error when I run that command?
_IceTransSocketUNIXConnect: Cannot connect to non-local host vl-sankumar-ice
_IceTransSocketUNIXConnect: Cannot connect to non-local host vl-sankumar-ice
Qt: Session management error: Could not open network socket
Regards,
Santosh
I really like this hands-on post, thanks!
Thanks Andreas!
Hi, this is a very nice post about first exploratory techniques to use.
I have a few questions :
– How did you save your figures to have such nice layouts ? Could you please complete your script with the adequate lines ?
– Do you know a way to have a scatter matrix with in diagonals kde for each class ?
Thanks in advance
Jason. Nice post.
In my Ubuntu, windows show up, but in 2 seconds they close…….
Help.
hi,
write plt.rcParams.get(‘axes.color_cycle’) instead of pd.options.display.mpl_style = ‘default’ , and it worked for me
Jason,
Many thanks for this helpful post , a total value add.
I have enjoyed following the algorithm.
You’re welcome Benson.
Nice Post. Thanks Jason for sharing!
Thanks Nitin.
Hi Jason,
Good day. Your posts are really helpful.
Could you provide an example for doing the scatter_matrix, but with two histograms overlaid in the diagonals?
Thanks,
Tal
Great suggestion Tal, perhaps in the future.
Hello, i have some question..
1. i try data.groupby(‘class’).plas.hist(alpha=0.4) and got this error “‘DataFrameGroupBy’ object has no attribute ‘plas'”. how to fix this ?
2. How to change the scale of x and y value ?
3. How to ignore the outlier in data when visualize it ?
Perhaps your loaded data does not have column names?
There are examples of scaling here:
https://machinelearningmastery.com/prepare-data-machine-learning-python-scikit-learn/
Consider removing the outliers prior to visualization.
Excellent post, really helped me to learn some techniques to explore data sets quickly. Thank you.
I’m glad to hear that!
Can you please tell me how to add How to add the chart that shows which color is showing which class in top right corner for this:
data.groupby(‘class’).plas.hist(alpha=0.4)
This is called the legend.
You can learn more about the matplotlib library here:
https://matplotlib.org/
You can learn more about legends in matplotlib here:
https://matplotlib.org/users/legend_guide.html
This is an amazing post on data analysis with pandas. I learnt new techniques. I suggested this post to all my friends. Thanks a lot Jason Brownlee
Thanks, I’m glad to hear that.
Wow, great material! I’ll definitely bookmark it!
Thanks.
No related to this work but, i am new to ML and CNN and would like to do something with signal processing involving time series filtring… any place where i can get some directions please?
I am working on tutorials on this topic now. I hope to post them soon.
Very good work.
Congratulations!
Thanks.
Very helpful! Thanks.
Thanks, I’m happy to hear that.
I used:
> plt.style.use(‘ggplot’)
instead of:
>pd.options.display.mpl_style = ‘default’
This fixed some error.
Great tutorial!
Thanks for sharing.
Great post, especially when you are a novice and don’t know where and how to start exploring your data. thanks
Thanks. I’m happy it helped.
Hi, very good tutorial but I get this error:
OptionError: ‘You can only set the value of existing options’
I thought it might be due to my data but when I copy your example with your dataset I get the same error. Are you able to shed some light on this?
Thanks, I have updated the example.
Wow! have been using pandas a while for machine learning but I never knew that it had integrated plotting functions, incredible information. Willful ignorance on my part I guess but thanks a lot Jason! Great insight as always.
Thanks, I’m happy it helps!
Dataframes in Pandas have also the .corr() function that calculates the correlation matrix as well as .cov() that measures the covariance matrix!
Great tip!