Big data, labeled data, noisy data. Machine learning projects all need to look at data. Data is a critical aspect of machine learning projects, and how we handle that data is an important consideration for our project. When the amount of data grows, and there is a need to manage them, allow them to serve multiple projects, or simply have a better way to retrieve data, it is natural to consider using a database system. It can be a relational database or a flat-file format. It can be local or remote.
In this post, we explore different formats and libraries that you can use to store and retrieve your data in Python.
After completing this tutorial, you will learn:
Managing data using SQLite, Python dbm library, Excel, and Google Sheets
How to use the data stored externally for training your machine learning model
What are the pros and cons of using a database in a machine learning project
Kick-start your project with my new book Python for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started!
Managing Data with Python Photo by Bill Benzon. Some rights reserved.
Overview
This tutorial is divided into seven parts; they are:
Managing data in SQLite
SQLite in action
Managing data in dbm
Using the dbm database in a machine learning pipeline
Managing data in Excel
Managing data in Google Sheets
Other uses of the database
Managing Data in SQLite
When we mention a database, it often means a relational database that stores data in a tabular format.
To start off, let’s grab a tabular dataset from sklearn.dataset (to learn more about getting datasets for machine learning, look at our previous article).
The above lines read the “Pima Indians diabetes dataset” from OpenML and create a pandas DataFrame. This is a classification dataset with multiple numerical features and one binary class label. We can explore the DataFrame with:
This is not a very large dataset, but if it was too large, we might not fit it in memory. A relational database is a tool to help us manage tabular data efficiently without keeping everything in memory. Usually, a relational database would understand a dialect of SQL, which is a language describing the operation to the data. SQLite is a serverless database system that does not need any setup, and we have built-in library support in Python. In the following, we will demonstrate how we can make use of SQLite to manage data but using a different database such as MariaDB or PostgreSQL, which would be very similar.
Now, let’s start by creating an in-memory database in SQLite and getting a cursor object for us to execute queries to our new database:
1
2
3
4
import sqlite3
conn=sqlite3.connect(":memory:")
cur=conn.cursor()
If we want to store our data on a disk so that we can reuse it another time or share it with another program, we can store the database in a database file instead of replacing the magic string :memory: in the above code snippet with the filename (e.g., example.db), as such:
1
conn=sqlite3.connect("example.db")
Now, let’s go ahead and create a new table for our diabetes data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
...
create_sql="""
CREATE TABLE diabetes(
preg NUM,
plas NUM,
pres NUM,
skin NUM,
insu NUM,
mass NUM,
pedi NUM,
age NUM,
class TEXT
)
"""
cur.execute(create_sql)
The cur.execute() method executes the SQL query that we have passed into it as an argument. In this case, the SQL query creates the diabetes table with the different columns and their respective data types. The language of SQL is not described here, but you may learn more from many database books and courses.
Next, we can go ahead and insert data from our diabetes dataset, which is stored in a pandas DataFrame, into our newly created diabetes table in our in-memory SQL database.
1
2
3
4
# Prepare a parameterized SQL for insert
insert_sql="INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)"
# execute the SQL multiple times with each element in dataset.to_numpy().tolist()
Let’s break down the above code: dataset.to_numpy().tolist() gives us a list of rows of the data in dataset, which we will pass as an argument into cur.executemany(). Then, cur.executemany() runs the SQL statement multiple times, each time with an element from dataset.to_numpy().tolist(), which is a row of data from dataset. The parameterized SQL expects a list of values each time, and hence we should pass a list of the list into executemany(), which is what dataset.to_numpy().tolist() creates.
Now, we can check to confirm that all data are stored in the database:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import pandas aspd
def cursor2dataframe(cur):
"""Read the column header from the cursor and then the rows of
data from it. Afterwards, create a DataFrame"""
header=[x[0]forxincur.description]
# gets data from the last executed SQL query
data=cur.fetchall()
# convert the data into a pandas DataFrame
returnpd.DataFrame(data,columns=header)
# get 5 random rows from the diabetes table
select_sql="SELECT * FROM diabetes ORDER BY random() LIMIT 5"
cur.execute(select_sql)
sample=cursor2dataframe(cur)
print(sample)
In the above, we use the SELECT statement in SQL to query the table diabetes for 5 random rows. The result will be returned as a list of tuples (one tuple for each row). Then we convert the list of tuples into a pandas DataFrame by associating a name to each column. Running the above code snippet, we get this output:
1
2
3
4
5
6
preg plas pres skin insu mass pedi age class
0 2 90 68 42 0 38.2 0.503 27 tested_positive
1 9 124 70 33 402 35.4 0.282 34 tested_negative
2 7 160 54 32 175 30.5 0.588 39 tested_positive
3 7 105 0 0 0 0.0 0.305 24 tested_negative
4 1 107 68 19 0 26.5 0.165 24 tested_negative
Here’s the complete code for creating, inserting, and retrieving a sample from a relational database for the diabetes dataset using sqlite3:
# Insert data into the table using a parameterized SQL
insert_sql="INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)"
rows=dataset.to_numpy().tolist()
cur.executemany(insert_sql,rows)
def cursor2dataframe(cur):
"""Read the column header from the cursor and then the rows of
data from it. Afterwards, create a DataFrame"""
header=[x[0]forxincur.description]
# gets data from the last executed SQL query
data=cur.fetchall()
# convert the data into a pandas DataFrame
returnpd.DataFrame(data,columns=header)
# get 5 random rows from the diabetes table
select_sql="SELECT * FROM diabetes ORDER BY random() LIMIT 5"
cur.execute(select_sql)
sample=cursor2dataframe(cur)
print("Data from SQLite database:")
print(sample)
# close database connection
conn.commit()
conn.close()
The benefit of using a database is pronounced when the dataset is not obtained from the Internet but collected by you over time. For example, you may be collecting data from sensors over many days. You may write the data you collected each hour into the database using an automated job. Then your machine learning project can run using the dataset from the database, and you may see a different result as your data accumulates.
Let’s see how we can build our relational database into our machine learning pipeline!
SQLite in Action
Now that we’ve explored how to store and retrieve data from a relational database using sqlite3, we might be interested in how to integrate it into our machine learning pipeline.
Usually, in this situation, we will have a process to collect the data and write it to the database (e.g., read from sensors over many days). This will be similar to the code in the previous section, except we would prefer to write the database onto a disk for persistent storage. Then we will read from the database in the machine learning process, either for training or for prediction. Depending on the model, there are different ways to use the data. Let’s consider a binary classification model in Keras for the diabetes dataset. We may build a generator to read a random batch of data from the database:
The above code is a generator function that gets the batch_size number of rows from the SQLite database and returns them as a NumPy array. We may use data from this generator for training in our classification network:
Note that we read only the batch in the generator function and not everything. We rely on the database to provide us with the data, and we are not concerned about how large the dataset is in the database. Although SQLite is not a client-server database system, and hence it is not scalable to networks, there are other database systems that can do that. Thus you can imagine an extraordinarily large dataset can be used while only a limited amount of memory is provided for our machine learning application.
The following is the full code, from preparing the database to training a Keras model using data read in realtime from it:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
import sqlite3
import numpy asnp
from sklearn.datasets import fetch_openml
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Create database
conn=sqlite3.connect("diabetes.db")
cur=conn.cursor()
cur.execute("DROP TABLE IF EXISTS diabetes")
create_sql="""
CREATE TABLE diabetes(
preg NUM,
plas NUM,
pres NUM,
skin NUM,
insu NUM,
mass NUM,
pedi NUM,
age NUM,
class TEXT
)
"""
cur.execute(create_sql)
# Read data from OpenML, insert data into the table using a parameterized SQL
Before moving on to the next section, we should emphasize that all databases are a bit different. The SQL statement we use may not be optimal in other database implementations. Also, note that SQLite is not very advanced as its objective is to be a database that requires no server setup. Using a large-scale database and how to optimize the usage is a big topic, but the concept demonstrated here should still apply.
Want to Get Started With Python for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Managing Data in dbm
A relational database is great for tabular data, but not all datasets are in a tabular structure. Sometimes, data are best stored in a structure like Python’s dictionary, namely, a key-value store. There are many key-value data stores. MongoDB is probably the most well-known one, and it needs a server deployment just like PostgreSQL. GNU dbm is a serverless store just like SQLite, and it is installed in almost every Linux system. In Python’s standard library, we have the dbm module to work with it.
Let’s explore Python’s dbm library. This library supports two different dbm implementations: the GNU dbm and the ndbm. If neither is installed in the system, there is Python’s own implementation as a fallback. Regardless of the underlying dbm implementation, the same syntax is used in our Python program.
This time, we’ll demonstrate using scikit-learn’s digits dataset:
1
2
3
4
import sklearn.datasets
# get digits dataset (8x8 images of digits)
digits=sklearn.datasets.load_digits()
The dbm library uses a dictionary-like interface to store and retrieve data from a dbm file, mapping keys to values where both keys and values are strings. The code to store the digits dataset in the file digits.dbm is as follows:
1
2
3
4
5
6
7
import dbm
import pickle
# create file if not exists, otherwise open for read/write
The above code snippet creates a new file digits.dbm if it does not exist yet. Then we pick each digits image (from digits.images) and the label (from digits.target) and create a tuple. We use the offset of the data as the key and the pickled string of the tuple as a value to store in the database. Unlike Python’s dictionary, dbm allows only string keys and serialized values. Hence we cast the key into the string using str(idx) and store only the pickled data.
The following is how we can read the data back from the database:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import random
import numpy asnp
# number of images that we want in our sample
batchsize=4
images=[]
targets=[]
# open the database and read a sample
with dbm.open("digits.dbm","r")asdb:
# get all keys from the database
keys=db.keys()
# randomly samples n keys
forkey inrandom.sample(keys,batchsize):
# go through each key in the random sample
image,target=pickle.loads(db[key])
images.append(image)
targets.append(target)
print(np.asarray(images),np.asarray(targets))
In the above code snippet, we get 4 random keys from the database, then get their corresponding values and deserialize using pickle.loads(). As we know, the deserialized data will be a tuple; we assign them to the variables image and target and then collect each of the random samples in the list images and targets. For convenience in training in scikit-learn or Keras, we usually prefer to have the entire batch as a NumPy array.
Running the code above gets us the output:
1
2
3
4
5
6
7
8
9
10
[[[ 0. 0. 1. 9. 14. 11. 1. 0.]
[ 0. 0. 10. 15. 9. 13. 5. 0.]
[ 0. 3. 16. 7. 0. 0. 0. 0.]
[ 0. 5. 16. 16. 16. 10. 0. 0.]
[ 0. 7. 16. 11. 10. 16. 5. 0.]
[ 0. 2. 16. 5. 0. 12. 8. 0.]
[ 0. 0. 10. 15. 13. 16. 5. 0.]
[ 0. 0. 0. 9. 12. 7. 0. 0.]]
...
] [6 8 7 3]
Putting everything together, this is what the code for retrieving the digits dataset, then creating, inserting, and sampling from a dbm database looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import dbm
import pickle
import random
import numpy asnp
import sklearn.datasets
# get digits dataset (8x8 images of digits)
digits=sklearn.datasets.load_digits()
# create file if not exists, otherwise open for read/write
Next, let’s look at how to use our newly created dbm database in our machine learning pipeline!
Using dbm Database in a Machine Learning Pipeline
Here, you probably realized that we can create a generator and a Keras model for digits classification, just like what we did in the example of the SQLite database. Here is how we can modify the code. First is our generator function. We just need to select a random batch of keys in a loop and fetch data from the dbm store:
In more advanced systems such as MongoDB or Couchbase, we may simply ask the database system to read random records for us instead of picking random samples from the list of all keys. But the idea is still the same; we can rely on an external store to keep our data and manage our dataset rather than doing it in our Python script.
Managing Data in Excel
Sometimes, memory is not why we keep our data outside of our machine learning script. It’s because there are better tools to manipulate the data. Maybe we want to have tools to show us all data on the screen and allow us to scroll, with formatting and highlight, etc. Or perhaps we want to share the data with someone else who doesn’t care about our Python program. It is quite common to see people using Excel to manage data in situations where a relational database can be used. While Excel can read and export CSV files, the chances are that we may want to deal with Excel files directly.
In Python, there are several libraries to handle Excel files, and OpenPyXL is one of the most famous. We need to install this library before we can use it:
1
pip install openpyxl
Today, Excel uses the “Open XML Spreadsheet” format with the filename ending in .xlsx. The older Excel files are in a binary format with filename suffix .xls, and it is not supported by OpenPyXL (in which you can use xlrd and xlwt modules for reading and writing).
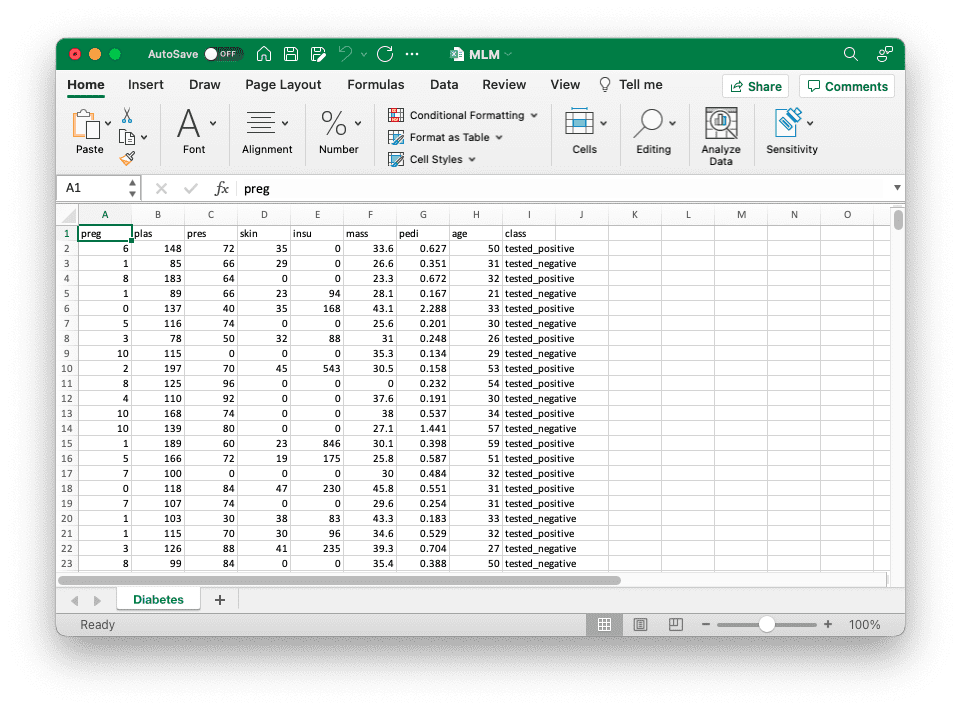
Let’s consider the same example we used in the case of SQLite above. We can open a new Excel workbook and write our diabetes dataset as a worksheet:
# Create Excel workbook and write data into the default worksheet
wb=openpyxl.Workbook()
sheet=wb.active# use the default worksheet
sheet.title="Diabetes"
forn,colname inenumerate(header):
sheet.cell(row=1,column=1+n,value=colname)
forn,row inenumerate(data):
form,cell inenumerate(row):
sheet.cell(row=2+n,column=1+m,value=cell)
# Save
wb.save("MLM.xlsx")
The code above is to prepare data for each cell in the worksheet (specified by the rows and columns). When we create a new Excel file, there will be one worksheet by default. Then the cells are identified by the row and column offset, beginning with 1. We write to a cell with the syntax:
1
sheet.cell(row=3,column=4,value="my data")
To read from a cell, we use:
1
sheet.cell(row=3,column=4).value
Writing data into Excel cell by cell is tedious, and indeed we can add data row by row. The following is how we can modify the code above to operate in rows rather than cells:
# Create Excel workbook and write data into the default worksheet
wb=openpyxl.Workbook()
sheet=wb.create_sheet("Diabetes")# or wb.active for default sheet
sheet.append(header)
forrow indata:
sheet.append(row)
# Save
wb.save("MLM.xlsx")
Once we have written our data into the file, we may use Excel to visually browse the data, add formatting, and so on:
To use it for a machine learning project is not any harder than using an SQLite database. The following is the same binary classification model in Keras, but the generator is reading from the Excel file instead:
In the above, we deliberately give the argument steps_per_epoch=20 to the fit() function because the code above will be extremely slow. This is because OpenPyXL is implemented in Python to maximize compatibility but trades off the speed that a compiled module can provide. Hence it’s best to avoid reading data row by row every time from Excel. If we need to use Excel, a better option is to read the entire data into memory in one shot and use it directly afterward:
Besides an Excel workbook, sometimes we may find Google Sheets more convenient to handle data because it is “in the cloud.” We may also manage data using Google Sheets in a similar logic as Excel. But to begin, we need to install some modules before we can access it in Python:
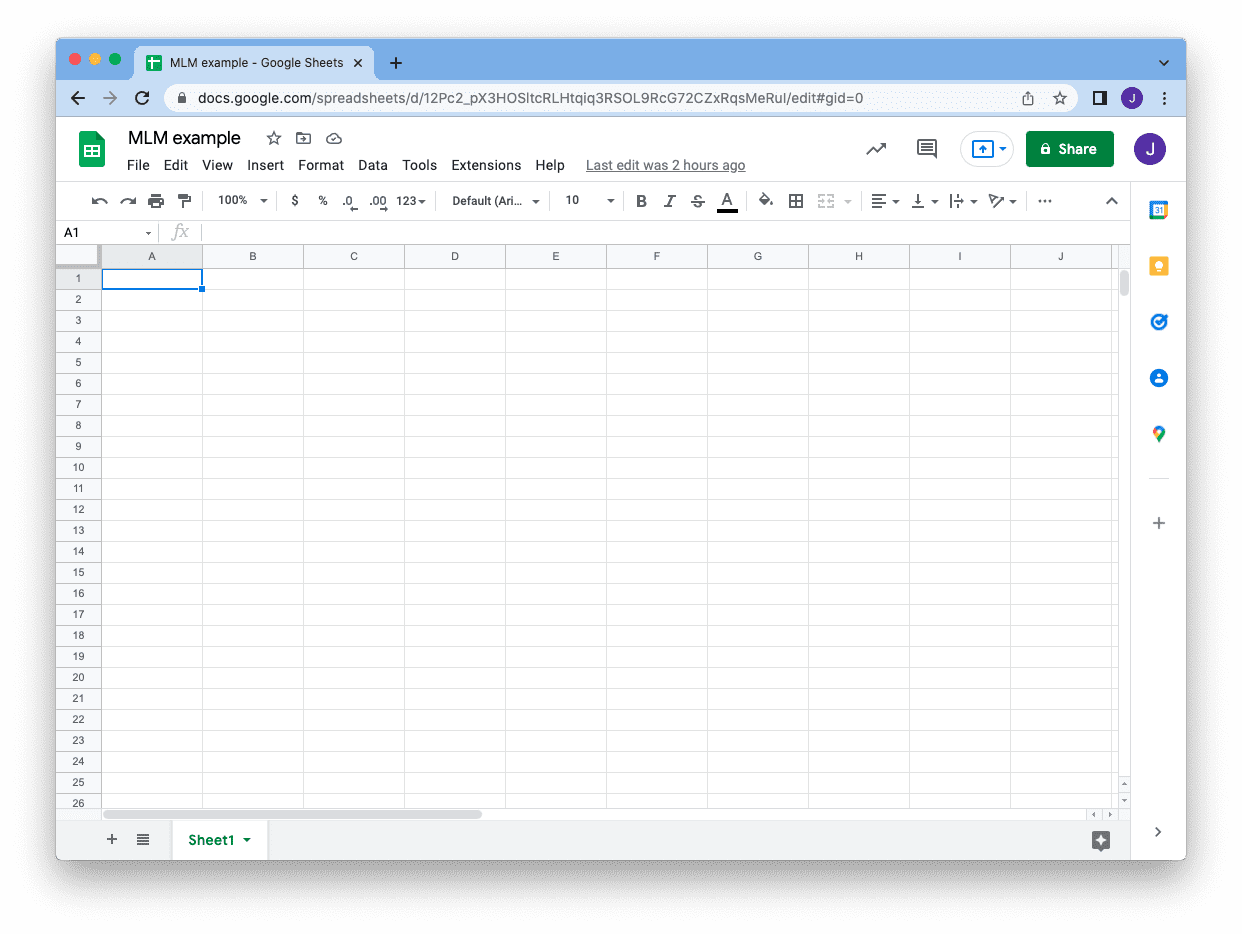
Assume you have a Gmail account, and you created a Google Sheet. The URL you saw on the address bar, right before the /edit part, tells you the ID of the sheet, and we will use this ID later:
To access this sheet from a Python program, it is best if you create a service account for your code. This is a machine-operable account that authenticates using a key but is manageable by the account owner. You can control what this service account can do and when it will expire. You may also revoke the service account at any time as it is separate from your Gmail account.
To create a service account, first, you need to go to the Google developers console, https://console.developers.google.com, and create a project by clicking the “Create Project” button:
You need to provide a name, and then you can click “Create”:
It will bring you back to the console, but your project name will appear next to the search box. The next step is to enable the APIs by clicking “Enable APIs and Services” beneath the search box:
Since we are to create a service account to use Google Sheets, we search for “sheets” on the search box:
and then click on the Google Sheets API:
and enable it
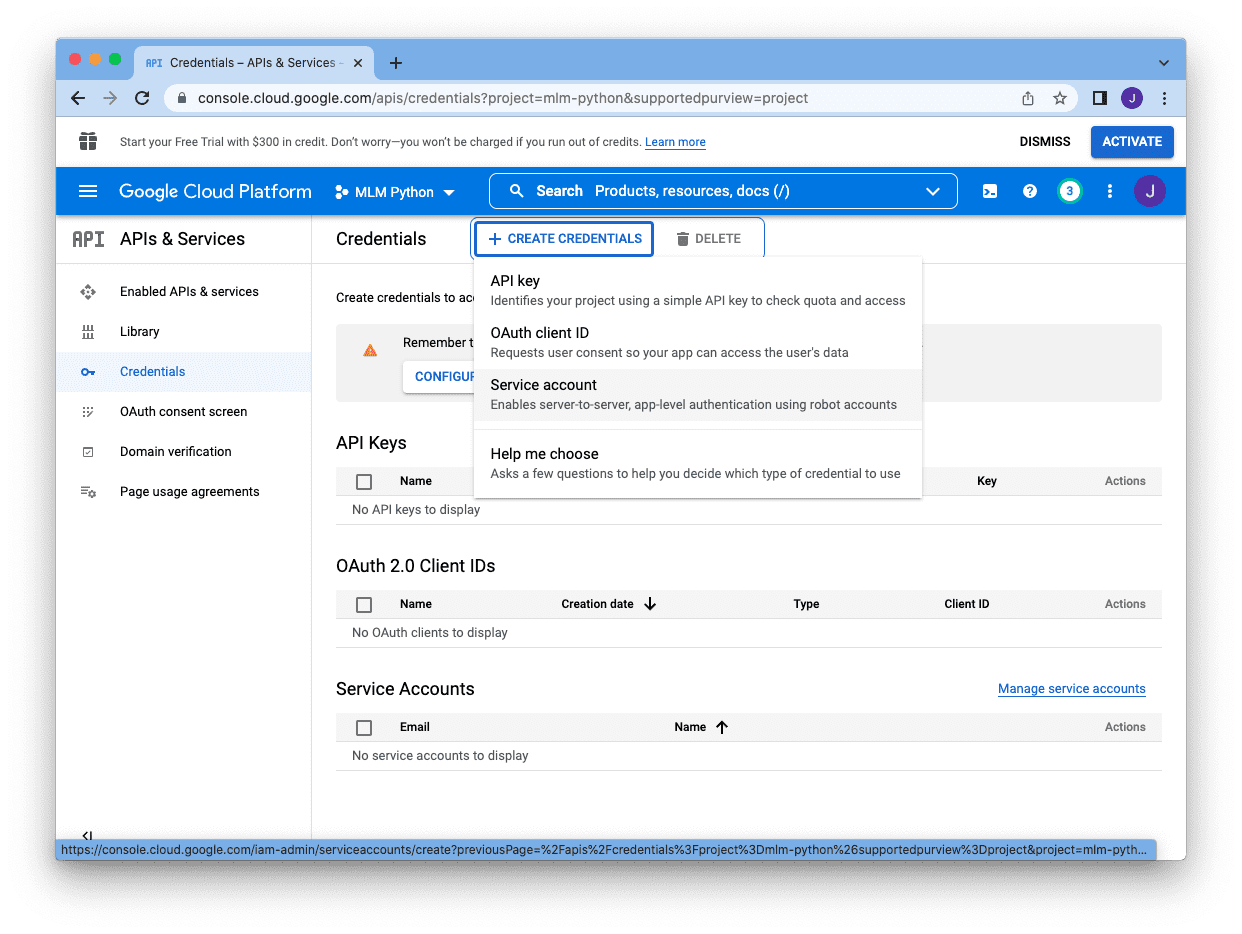
Afterward, we will be sent back to the console main screen, and we can click on “Create Credentials” at the top right corner to create the service account:
There are different types of credentials, and we select “Service Account”:
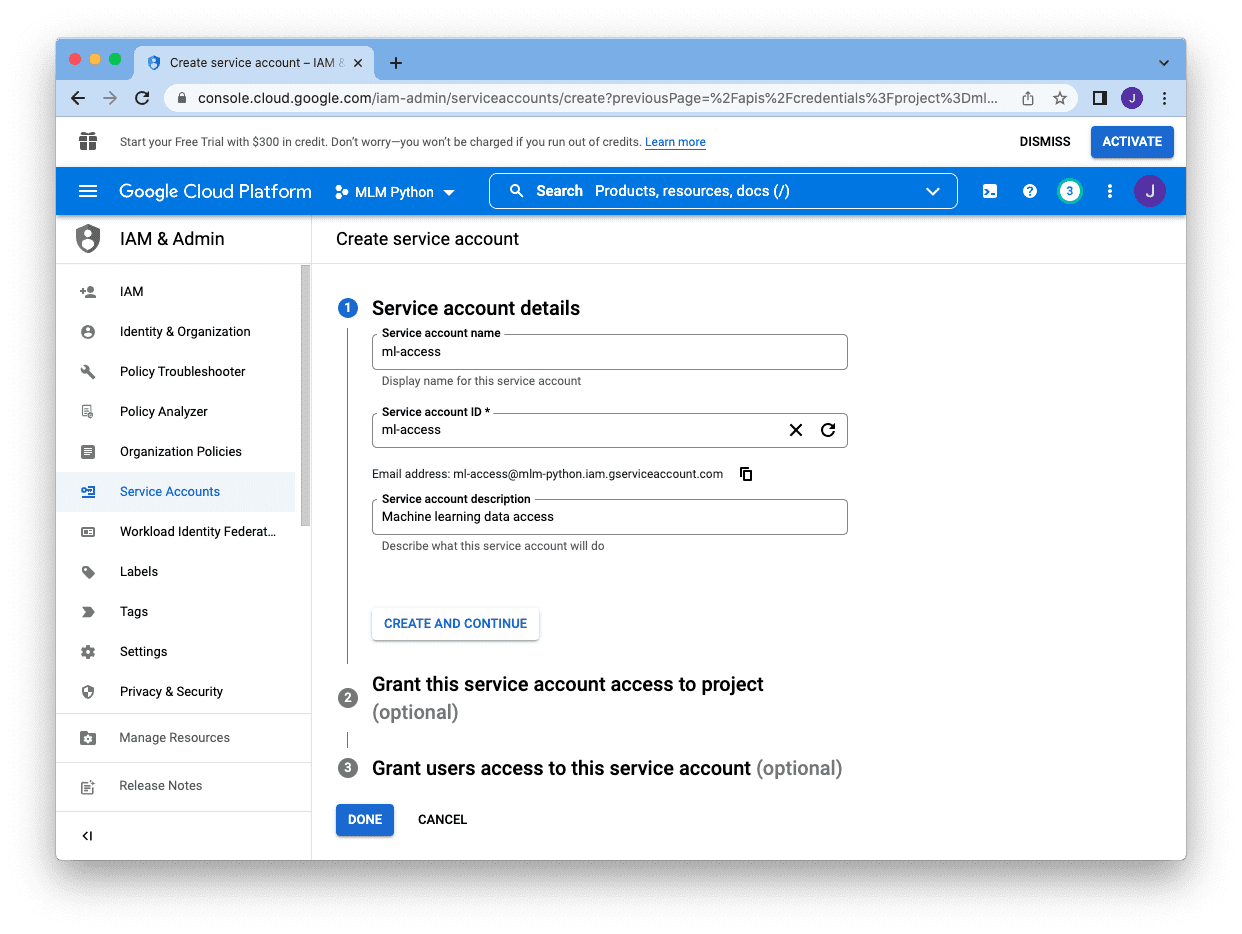
We need to provide a name (for our reference), an account ID (as a unique identifier for the project), and a description. The email address shown beneath the “Service account ID” box is the email for this service account. Copy it, and we will add it to our Google Sheet later. After we have created all these, we can skip the rest and click “Done”:
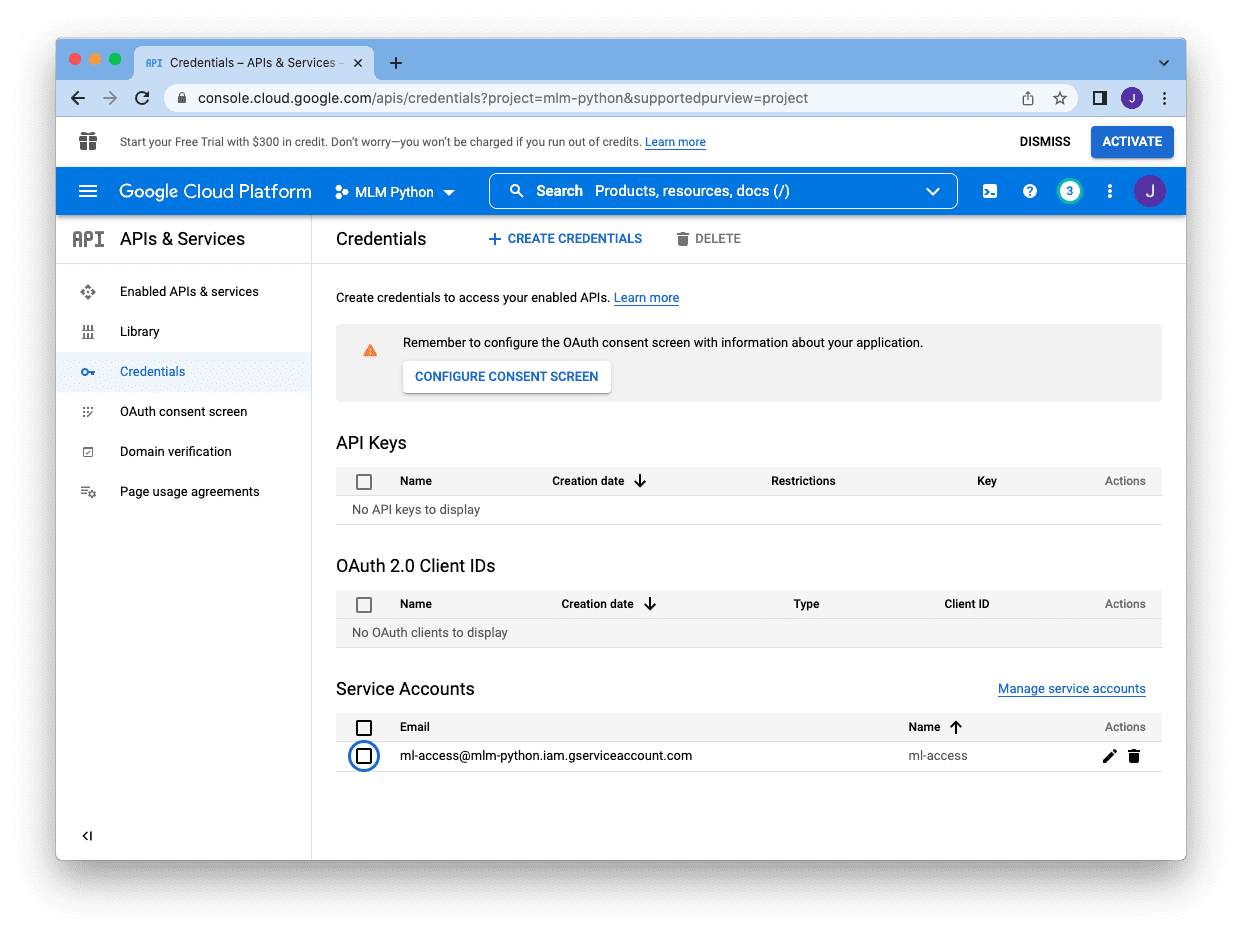
When we finish, we will be sent back to the main console screen, and we know the service account is created if we see it under the “Service Account” section:
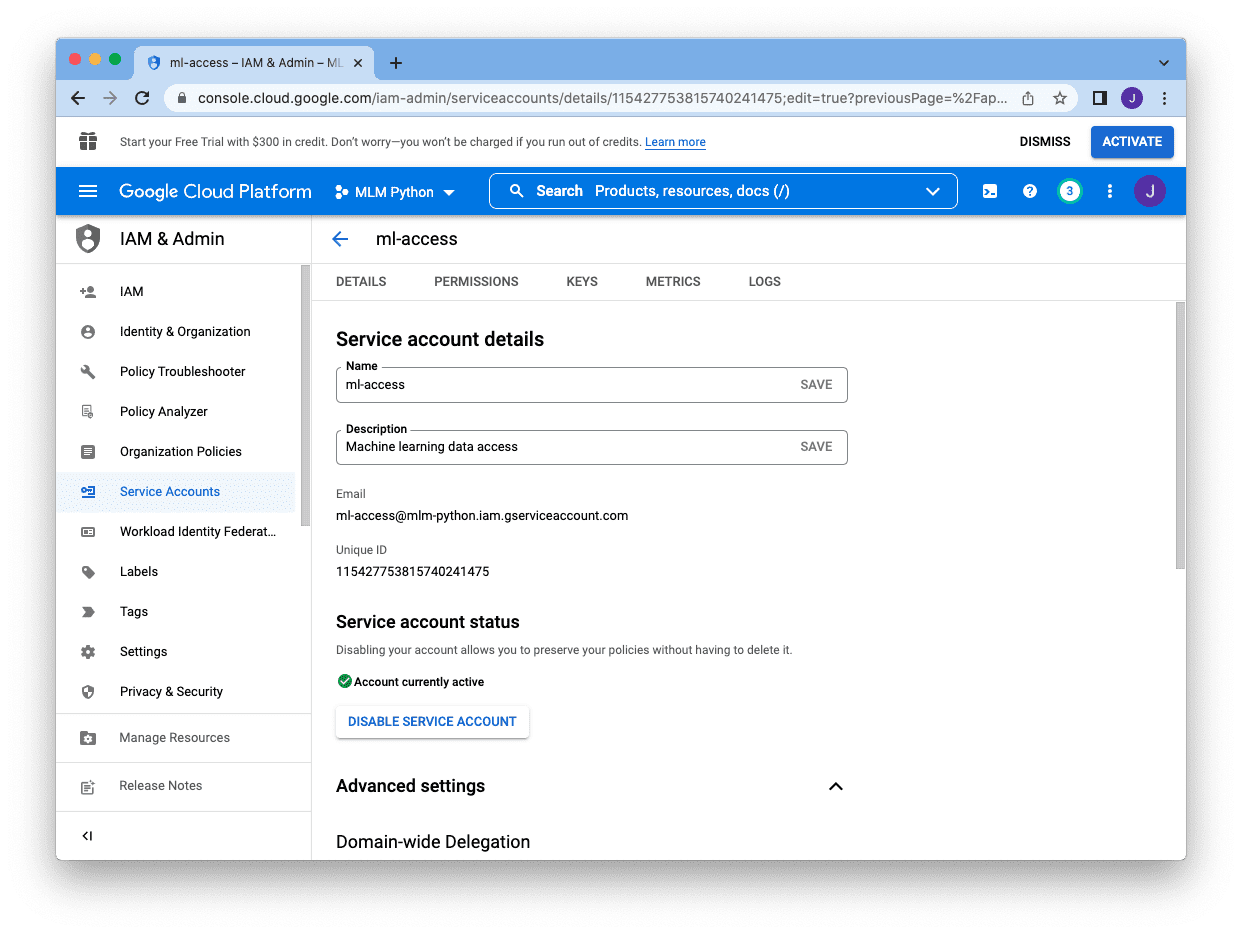
Next, we need to click on the pencil icon at the right of the account, which brings us to the following screen:
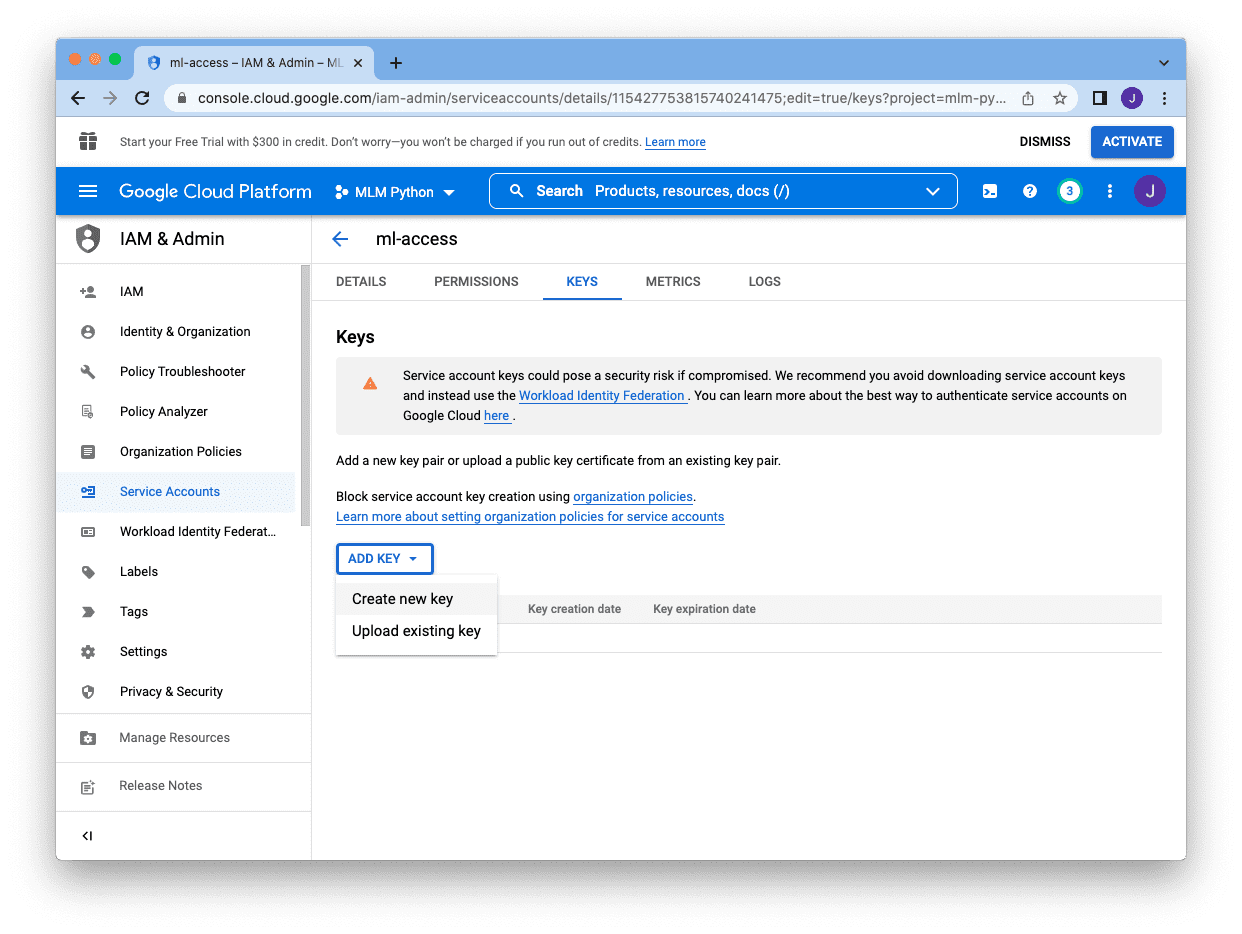
Instead of a password, we need to create a key for this account. We click on the “Keys” page at the top, and then click “Add Key” and select “Create new key”:
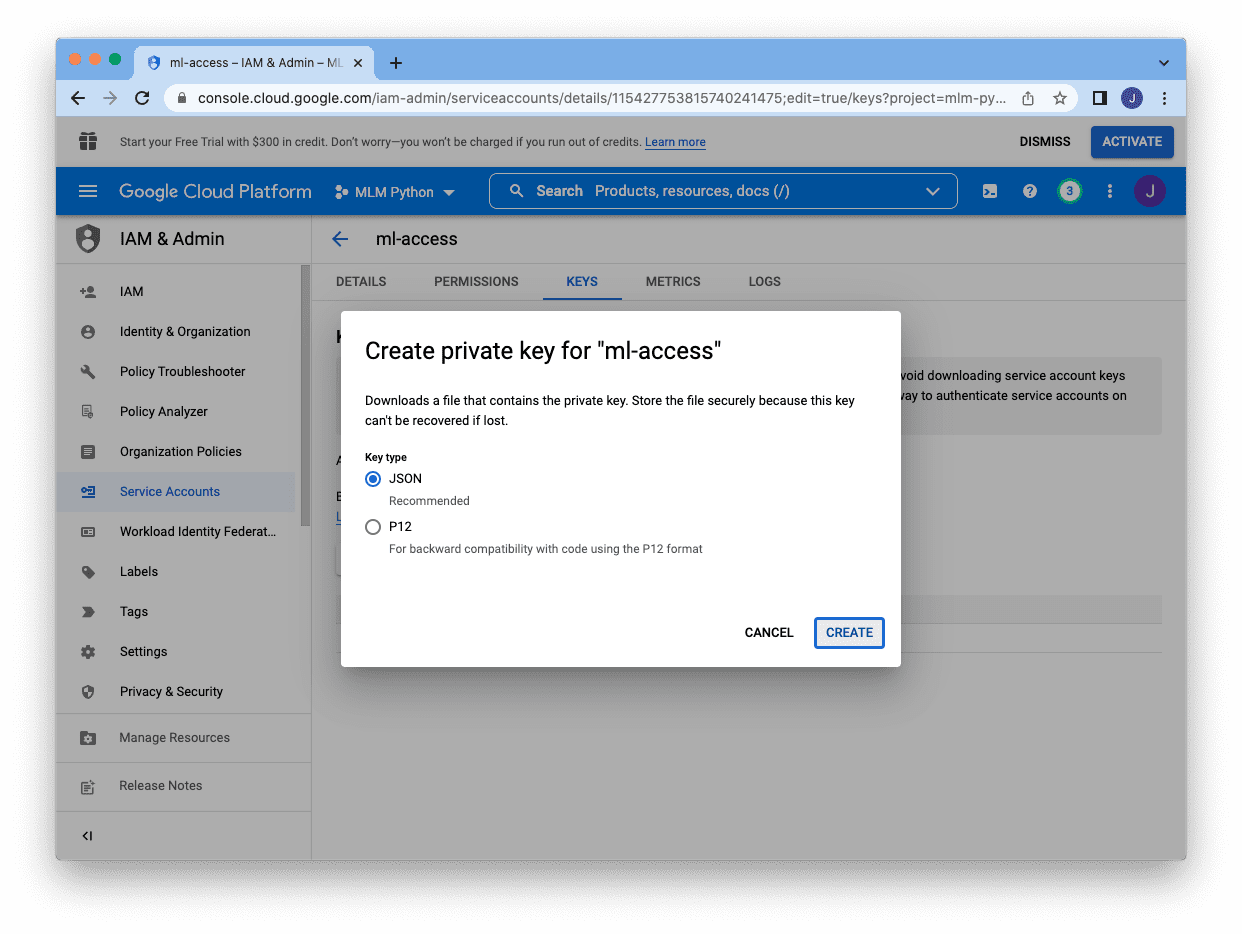
There are two different formats for the keys, and JSON is the preferred one. Selecting JSON and clicking “Create” at the bottom will download the key in a JSON file:
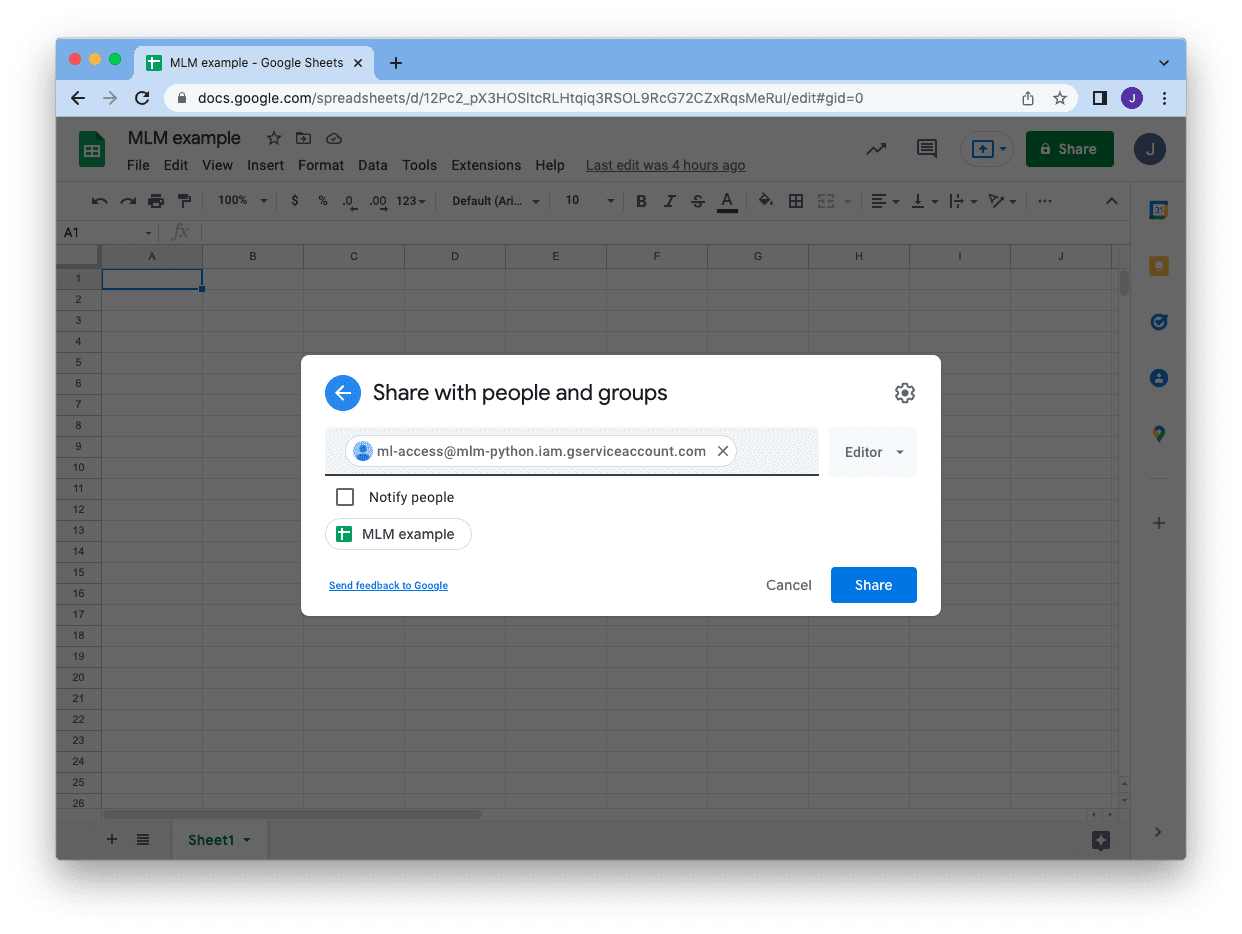
After saving the JSON file, then we can go back to our Google Sheet and share the sheet with our service account. Click on the “Share” button at the top right corner and enter the email address of the service account. You can skip the notification and just click “Share.” Then we are all set!
At this point, we are ready to access this particular Google Sheet using the service account from our Python program. To write to a Google Sheet, we can use Google’s API. We depend on the JSON file we just downloaded for the service account (mlm-python.json in this example) to create a connection first:
1
2
3
4
5
6
7
8
9
from oauth2client.service_account import ServiceAccountCredentials
If we just created it, there should be only one sheet in the file, and it has ID 0. All operation using Google’s API is in the form of a JSON format. For example, the following is how we can delete everything on the entire sheet using the connection we just created:
Assume we read the diabetes dataset into a DataFrame as in our first example above. Then, we can write the entire dataset into the Google Sheet in one shot. To do so, we need to create a list of lists to reflect the 2D array structure of the cells on the sheet, then put the data into the API query:
1
2
3
4
5
6
7
8
9
10
11
12
...
rows=[list(dataset.columns)]
rows+=dataset.to_numpy().tolist()
maxcol=max(len(row)forrow inrows)
maxcol=chr(ord("A")-1+maxcol)
action=sheet.values().append(
spreadsheetId=sheet_id,
body={"values":rows},
valueInputOption="RAW",
range="Sheet1!A1:%s"%maxcol
)
action.execute()
In the above, we assumed the sheet has the name “Sheet1” (the default, as you can see at the bottom of the screen). We will write our data aligned at the top left corner, filling cell A1 (top left corner) onward. We use dataset.to_numpy().tolist() to collect all data into a list of lists, but we also add the column header as the extra row at the beginning.
Reading the data back from the Google Sheet is similar. The following is how we can read a random row of data:
As we have only one sheet, the list contains only one properties dictionary. Using this information, we can select a random row and specify the range to read. The variable data above will be a dictionary like the following, and the data will be in the form of a list of lists and can be accessed using data["values"]:
1
2
3
4
5
6
7
8
9
10
11
{'range': 'Sheet1!A536:I536',
'majorDimension': 'ROWS',
'values': [['1',
'77',
'56',
'30',
'56',
'33.3',
'1.251',
'24',
'tested_negative']]}
Tying all these together, the following is the complete code to load data into Google Sheet and read a random row from it: (be sure to change the sheet_id when you run it)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
import random
from googleapiclient.discovery import build
from httplib2 import Http
from oauth2client.service_account import ServiceAccountCredentials
Undeniably, accessing Google Sheets in this way is too verbose. Hence we have a third-party module gspread available to simplify the operation. After we install the module, we can check the size of the spreadsheet as simple as the following:
Similar to reading Excel, using the dataset stored in a Google Sheet, it is better to read it in one shot rather than reading row by row during the training loop. This is because every time you read, you send a network request and wait for the reply from Google’s server. This cannot be fast and hence is better avoided. The following is an example of how we can combine data from a Google Sheet with Keras code for training:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import random
import numpy asnp
import gspread
from sklearn.datasets import fetch_openml
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Google Sheet ID, as granted access to the service account
The examples above show you how to access a database from a spreadsheet. We assume the dataset is stored and consumed by a machine learning model in the training loop. While this is one way of using external data storage, it’s not the only way. Some other use cases of a database would be:
As storage for logs to keep a record of the details of the program, e.g., at what time some script is executed. This is particularly useful to keep track of changes if the script is going to mutate something, e.g., downloading some file and overwriting the old version
As a tool to collect data. Just like we may use GridSearchCV from scikit-learn, very often, we might evaluate the model performance with different combinations of hyperparameters. If the model is large and complex, we may want to distribute the evaluation to different machines and collect the result. It would be handy to add a few lines at the end of the program to write the cross-validation result to a database of a spreadsheet so we can tabulate the result with the hyperparameters selected. Having these data stored in a structural format allows us to report our conclusion later.
As a tool to configure the model. Instead of writing the hyperparameter combination and the validation score, we can use it as a tool to provide us with the hyperparameter selection for running our program. Should we decide to change the parameters, we can simply open up a Google Sheet, for example, to make the change instead of modifying the code.
Further Reading
The following are some resources for you to go deeper:
It provides self-study tutorials with hundreds of working code to equip you with skills including: debugging, profiling, duck typing, decorators, deployment,
and much more...
Showing You the Python Toolbox at a High Level for Your Projects









No comments yet.