Compared to other programming exercises, a machine learning project is a blend of code and data. You need both to achieve the result and do something useful. Over the years, many well-known datasets have been created, and many have become standards or benchmarks. In this tutorial, we are going to see how we can obtain those well-known public datasets easily. We will also learn how to make a synthetic dataset if none of the existing datasets fits our needs.
After finishing this tutorial, you will know:
Where to look for freely available datasets for machine learning projects
How to download datasets using libraries in Python
How to generate synthetic datasets using scikit-learn
Kick-start your project with my new book Python for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
A Guide to Getting Datasets for Machine Learning in Python Photo by Olha Ruskykh. Some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Dataset repositories
Retrieving dataset in scikit-learn and Seaborn
Retrieving dataset in TensorFlow
Generating dataset in scikit-learn
Dataset Repositories
Machine learning has been developed for decades, and therefore there are some datasets of historical significance. One of the most well-known repositories for these datasets is the UCI Machine Learning Repository. Most of the datasets over there are small in size because the technology at the time was not advanced enough to handle larger size data. Some famous datasets located in this repository are the iris flower dataset (introduced by Ronald Fisher in 1936) and the 20 newsgroups dataset (textual data usually referred to by information retrieval literature).
Newer datasets are usually larger in size. For example, the ImageNet dataset is over 160 GB. These datasets are commonly found in Kaggle, and we can search them by name. If we need to download them, it is recommended to use Kaggle’s command line tool after registering for an account.
OpenML is a newer repository that hosts a lot of datasets. It is convenient because you can search for the dataset by name, but it also has a standardized web API for users to retrieve data. It would be useful if you want to use Weka since it provides files in ARFF format.
But still, many datasets are publicly available but not in these repositories for various reasons. You may also want to check out the “List of datasets for machine-learning research” on Wikipedia. That page contains a long list of datasets attributed to different categories, with links to download them.
Retrieving Datasets in scikit-learn and Seaborn
Trivially, you may obtain those datasets by downloading them from the web, either through the browser, via command line, using the wget tool, or using network libraries such as requests in Python. Since some of those datasets have become a standard or benchmark, many machine learning libraries have created functions to help retrieve them. For practical reasons, often, the datasets are not shipped with the libraries but downloaded in real time when you invoke the functions. Therefore, you need to have a steady internet connection to use them.
Scikit-learn is an example where you can download the dataset using its API. The related functions are defined under sklearn.datasets,and you may see the list of functions at:
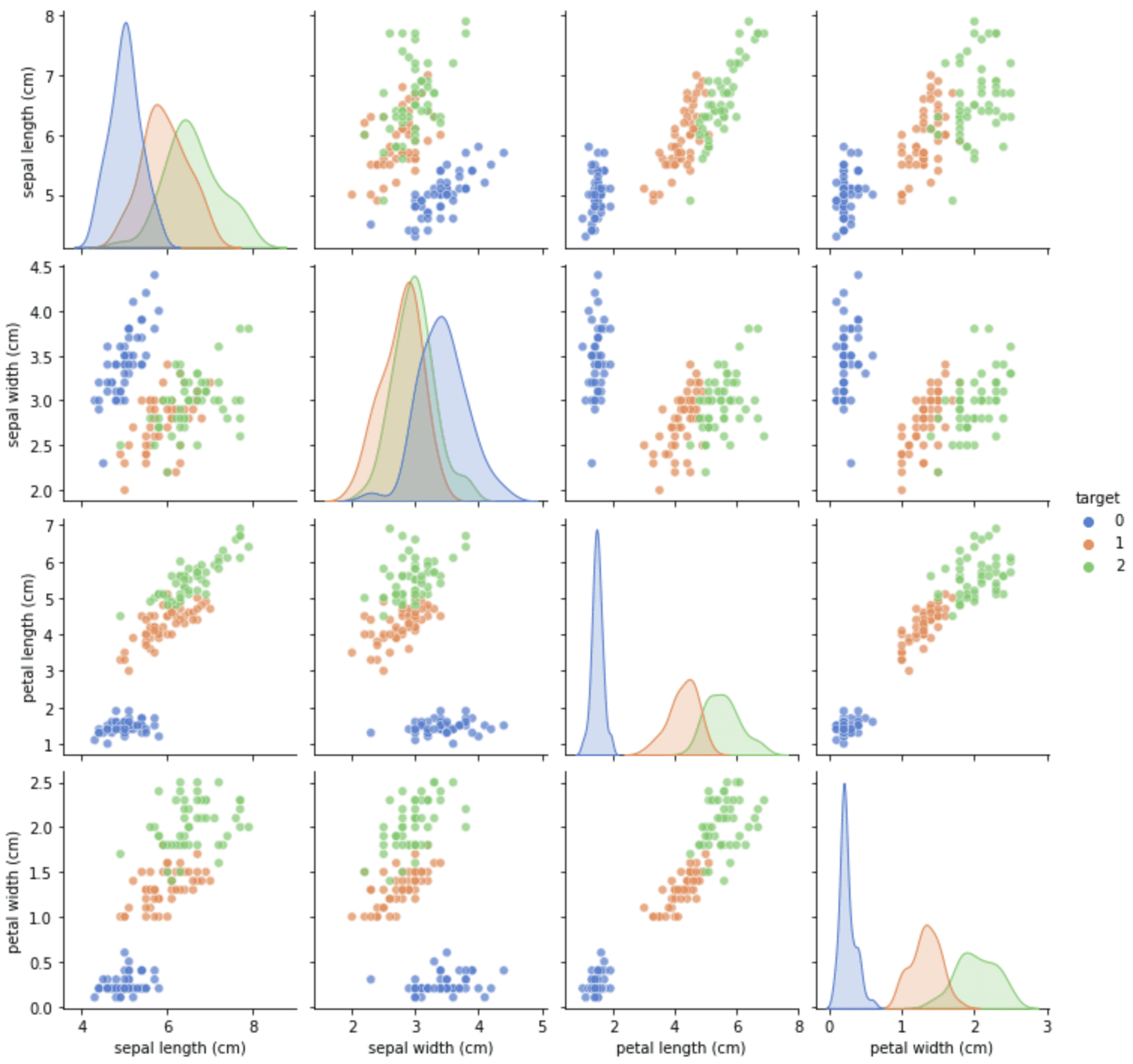
The load_iris() function would return numpy arrays (i.e., does not have column headers) instead of pandas DataFrame unless the argument as_frame=True is specified. Also, we pass return_X_y=True to the function, so only the machine learning features and targets are returned, rather than some metadata such as the description of the dataset. The above code prints the following:
Separating the features and targets is convenient for training a scikit-learn model, but combining them would be helpful for visualization. For example, we may combine the DataFrame as above and then visualize the correlogram using Seaborn:
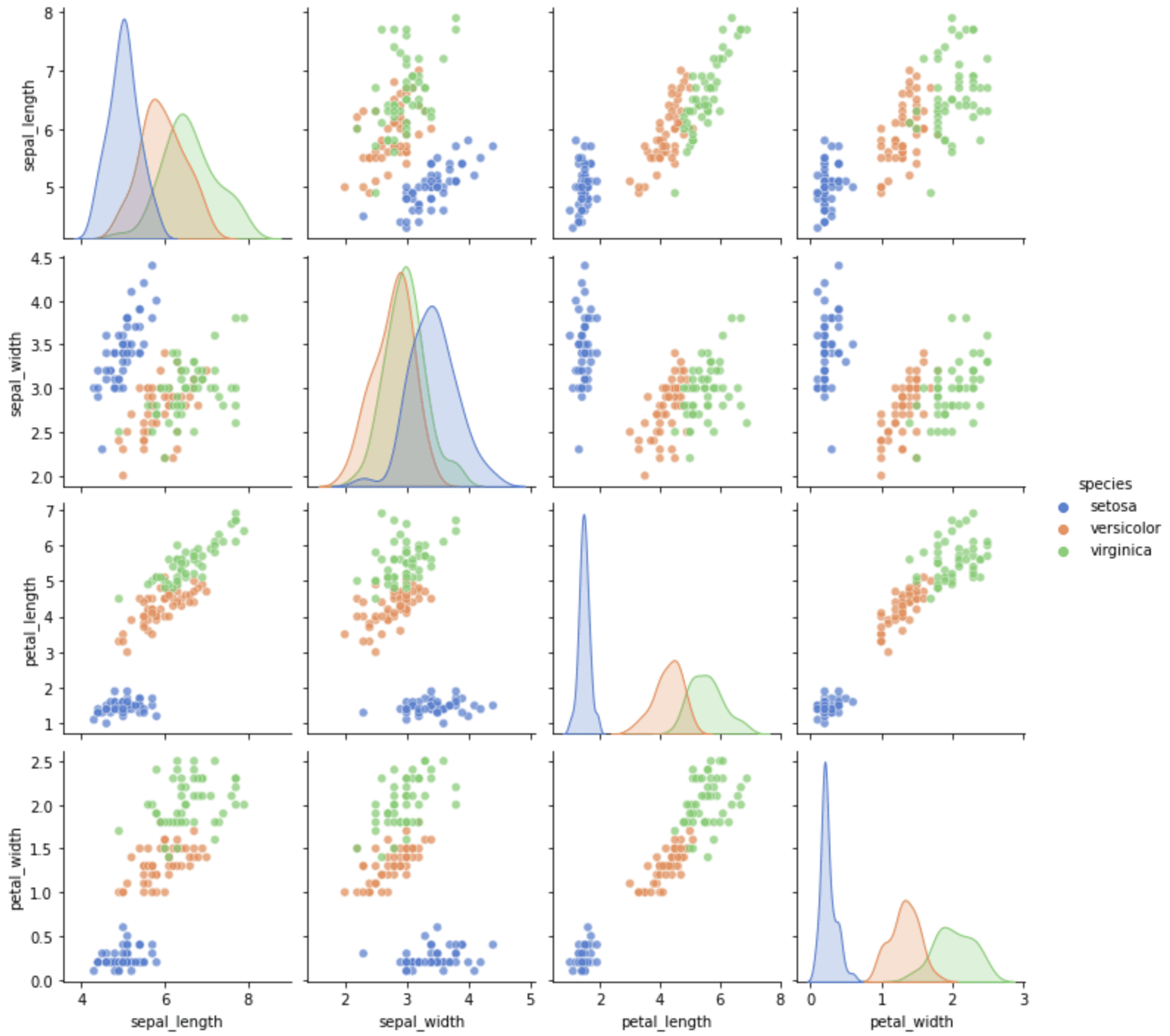
From the correlogram, we can see that target 0 is easy to distinguish, but targets 1 and 2 usually have some overlap. Because this dataset is also useful to demonstrate plotting functions, we can find the equivalent data loading function from Seaborn. We can rewrite the above into the following:
There are a handful of similar functions to load the “toy datasets” from scikit-learn. For example, we have load_wine() and load_diabetes() defined in similar fashion.
Larger datasets are also similar. We have fetch_california_housing(), for example, that needs to download the dataset from the internet (hence the “fetch” in the function name). Scikit-learn documentation calls these the “real-world datasets,” but, in fact, the toy datasets are equally real.
Sometimes, we should not use the name to identify a dataset in OpenML as there may be multiple datasets of the same name. We can search for the data ID on OpenML and use it in the function as follows:
The data ID in the code above refers to the titanic dataset. We can extend the code into the following to show how we can obtain the titanic dataset and then run the logistic regression:
1
2
3
4
5
6
7
from sklearn.linear_model import LogisticRegression
Want to Get Started With Python for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Retrieving Datasets in TensorFlow
Besides scikit-learn, TensorFlow is another tool that we can use for machine learning projects. For similar reasons, there is also a dataset API for TensorFlow that gives you the dataset in a format that works best with TensorFlow. Unlike scikit-learn, the API is not part of the standard TensorFlow package. You need to install it using the command:
1
pip install tensorflow-datasets
The list of all datasets is available on the catalog:
If we provided as_supervised=True, the dataset would be records of tuples (features, targets) instead of the dictionary. It is required for Keras. Moreover, to use the dataset in the fit() function, we need to create an iterable of batches. This is done by setting up the batch size of the dataset to convert it from OptionsDataset object into BatchDataset object.
We applied the LeNet5 model for the image classification. But since the target in the dataset is a numerical value (0 to 9) rather than a Boolean vector, we ask Keras to convert the softmax output vector into a number before computing accuracy and loss by specifying sparse_categorical_accuracy and sparse_categorical_crossentropy in the compile() function.
The key here is to understand every dataset is in a different shape. When you use it with your TensorFlow model, you need to adapt your model to fit the dataset.
Generating Datasets in scikit-learn
In scikit-learn, there is a set of very useful functions to generate a dataset with particular properties. Because we can control the properties of the synthetic dataset, it is helpful to evaluate the performance of our models in a specific situation that is not commonly seen in other datasets.
Scikit-learn documentation calls these functions the samples generator. It is easy to use; for example:
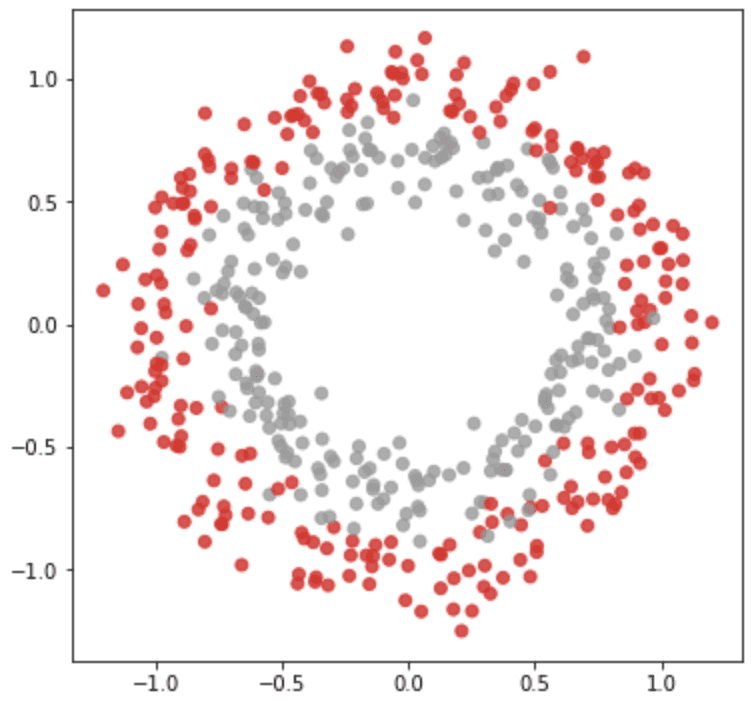
The make_circles() function generates coordinates of scattered points in a 2D plane such that there are two classes positioned in the form of concentric circles. We can control the size and overlap of the circles with the parameters factor and noise in the argument. This synthetic dataset is helpful to evaluate classification models such as a support vector machine since there is no linear separator available.
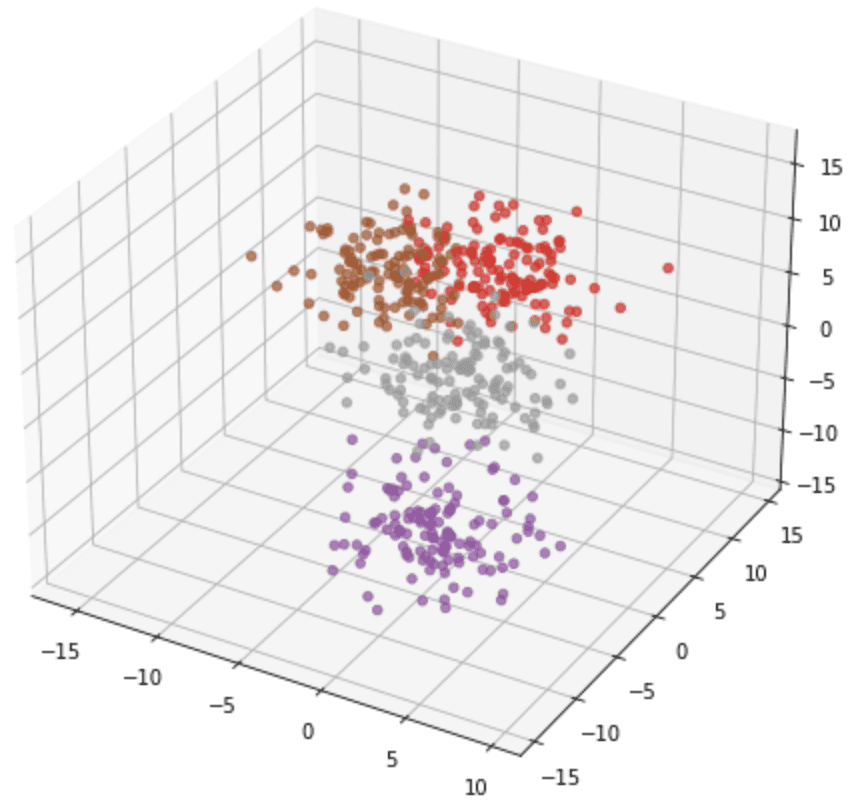
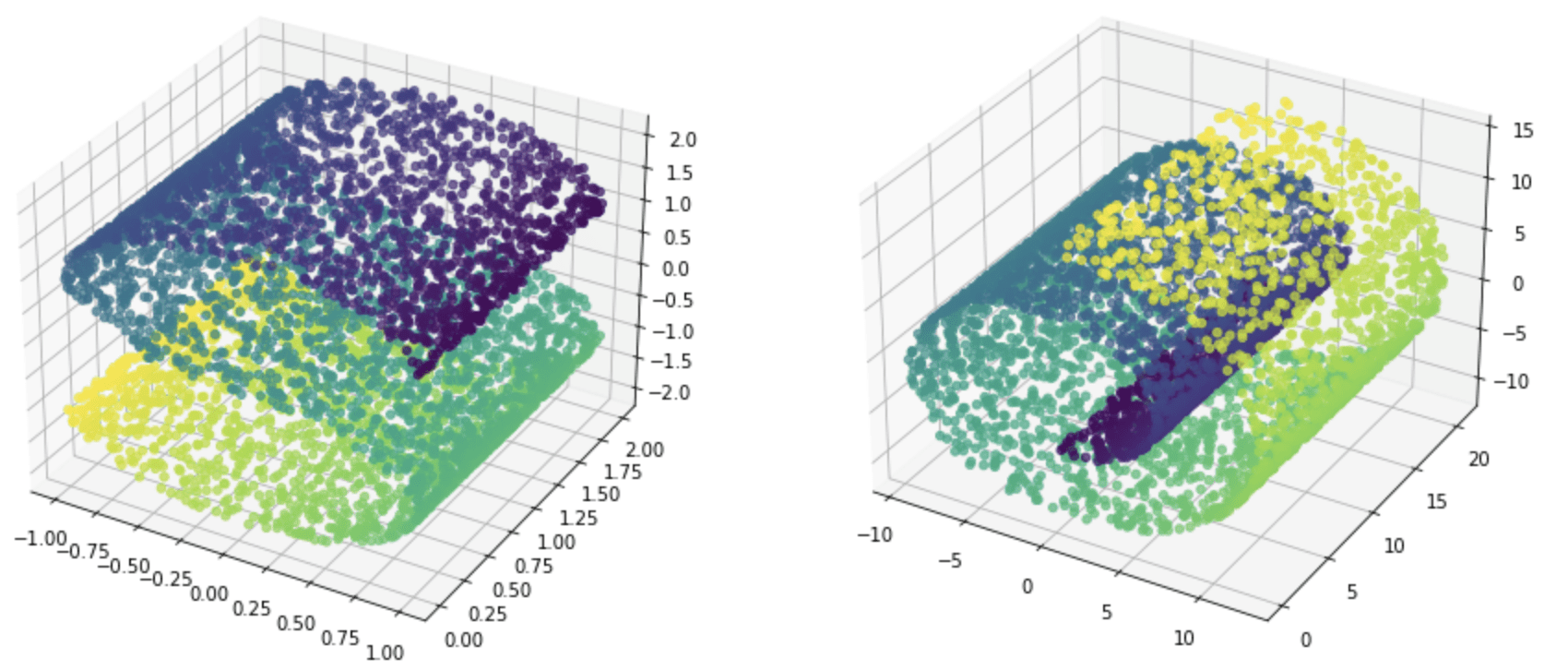
The output from make_circles() is always in two classes, and the coordinates are always in 2D. But some other functions can generate points of more classes or in higher dimensions, such as make_blob(). In the example below, we generate a dataset in 3D with 4 classes:
There are also some functions to generate a dataset for regression problems. For example, make_s_curve() and make_swiss_roll() will generate coordinates in 3D with targets as continuous values.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from sklearn.datasets import make_s_curve,make_swiss_roll
If we prefer not to look at the data from a geometric perspective, there are also make_classification() and make_regression(). Compared to the other functions, these two provide us more control over the feature sets, such as introducing some redundant or irrelevant features.
Below is an example of using make_regression() to generate a dataset and run linear regression with it:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
import numpy asnp
# Generate 10-dimensional features and 1-dimensional targets
with np.printoptions(precision=5,linewidth=100,suppress=True):
print(np.array(reg.coef_))
print(reg.intercept_)
In the example above, we created 10-dimensional features, but only 4 of them are informative. Hence from the result of the regression, we found only 4 of the coefficients are significantly non-zero.
It provides self-study tutorials with hundreds of working code to equip you with skills including: debugging, profiling, duck typing, decorators, deployment,
and much more...
Showing You the Python Toolbox at a High Level for Your Projects
This is a classic problem for much of IT, whether training an Artificial Intelligence or building a SAAS platform; getting data for launch. I appreciate the technical instructions of this article, as that’s not something I see a lot of right now out in the wilds of Internet land.
Getting datasets is not much easier for me. But here I got some algorithms which makes me to think of applying and learn. Thanks for such a article!
Here are some of my works:https://www.annotationsupport.com/services.php








This is a classic problem for much of IT, whether training an Artificial Intelligence or building a SAAS platform; getting data for launch. I appreciate the technical instructions of this article, as that’s not something I see a lot of right now out in the wilds of Internet land.
Great feedback Bret!
Getting datasets is not much easier for me. But here I got some algorithms which makes me to think of applying and learn. Thanks for such a article!
Here are some of my works:https://www.annotationsupport.com/services.php