In this article, you will learn how logits, temperature, and top-p sampling work together to control next-token prediction in large language models.
Topics we will cover include:
- What logits are and how they are produced by a transformer’s final linear layer.
- How temperature and top-p (nucleus sampling) shape the probability distribution used for token selection.
- How these three components fit into a sequential pipeline that governs LLM output generation.
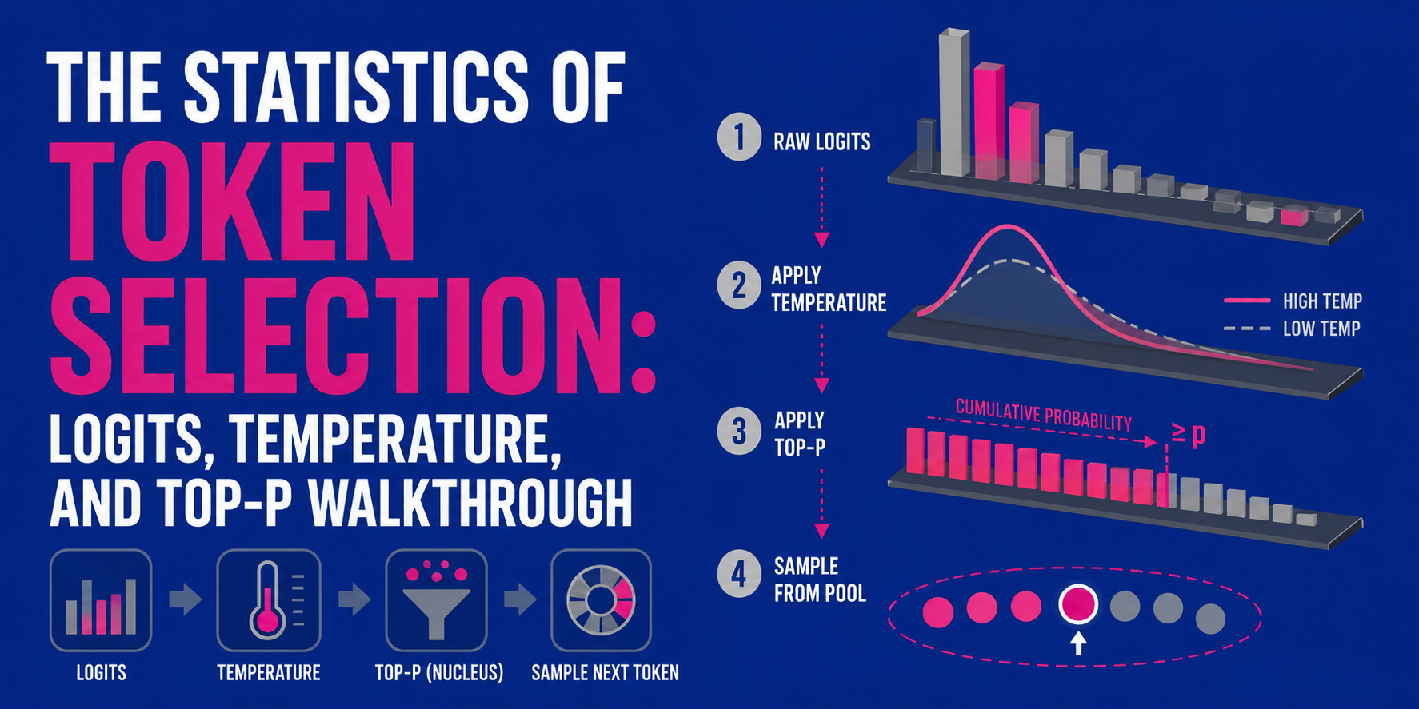
The Statistics of Token Selection: Logits, Temperature, and Top-P Walkthrough
Introduction
When large language models, or LLMs for short, produce outputs, several criteria are at stake, including not only overall response relevance but also coherence and creativity. Since deep inside the models operate by building their response word by word — or more precisely, token by token — capturing these desirable properties is a matter of mathematically adjusting the output probability distributions that govern the next-token prediction process.
This article introduces the mechanics behind LLM decoding strategies from a statistical vantage point. In particular, we will explore how raw model scores, known as logits, interact with two other model settings — temperature and top-p — which are three key parameters utilized to control the token selection process.
While we will focus on exploring what happens inside the very final stages of the LLMs’ underlying architecture, a.k.a. the transformer, you can check this article if you need a concise overview of the whole process and journey made by tokens from beginning to end.
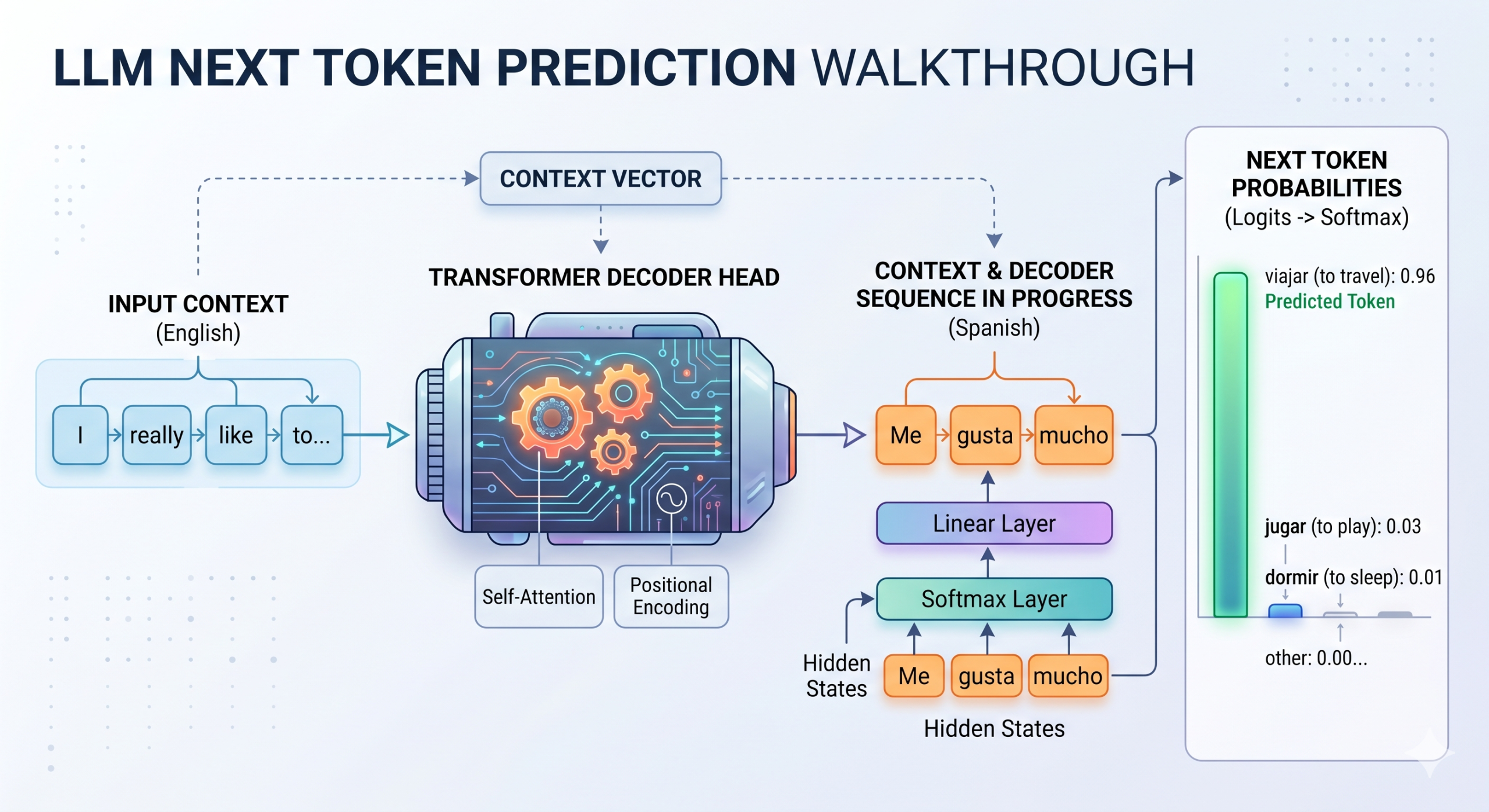
Token selection process in LLMs
What Are Logits?
In neural networks, the raw, unnormalized scores produced (typically at final linear layers) before converting them into probabilities of possible outcomes (e.g. classes) are known as logits. While logits have been used since the era of classical machine learning classification models like softmax regression, the same principle still applies to the final linear layer of transformer models. This final layer processes hidden states — which contain gradually accumulated linguistic knowledge about the input text gathered throughout the transformer — and outputs a vector of logits. How many? As many as the model’s vocabulary size, i.e. the number of possible tokens the model can generate.
See the diagram at the top, for instance. If an LLM trained for English-to-Spanish translation is predicting the next word after the generated sequence “me gusta mucho” (the translation of “I really like to”), it might output a raw logit score of 12.5 for “viajar” (travel), 8.2 for “jugar” (play), and -3.1 for “dormir” (sleep). These raw values are unbounded, making them difficult to interpret directly; hence, a softmax function is applied on top of the final linear layer to transform these logits into a standard, interpretable probability distribution over vocabulary tokens, such that all values sum to 1.
What Are Temperature and Top-p?
Once we have a probability distribution over the target vocabulary, do LLMs simply choose the token with the highest probability as the next one to generate? Not exactly, but the true process closely resembles that scenario. The next token is sampled from the distribution, and how this sampling works depends on several decoding parameters, two of the most important being temperature and top-p.
- Temperature is a scaling factor applied to the logits before the softmax step. A high temperature (e.g. above 1) flattens the resulting probabilities, making them more uniform. As a result, uncertainty and unpredictability increase, and the model behaves more creatively. A low temperature (e.g. well below 1) sharpens the differences between high- and low-probability tokens, increasing certainty and strongly favoring the most likely tokens in the original distribution. More about temperature can be found in this related article.
- Top-p, also called nucleus sampling, is another approach to controlling the randomness of next-token selection. Rather than scaling probabilities, it limits the pool of candidates to sample from. While similar strategies like top-k consider only the k highest-probability tokens, top-p identifies the smallest set of tokens whose cumulative probability meets or exceeds a threshold p, making it more adaptive and flexible. In other words, if we set p=0.9, top-p sorts tokens by probability and keeps adding them to a candidate pool until their cumulative probability reaches 0.9.
The Full Walkthrough: How Do These Concepts Relate to Each Other?
Logit-to-probability calculation, temperature, and top-p can be combined into a sequential multi-step pipeline for producing LLM outputs, i.e. next-token predictions.
First, the model generates raw logits for all possible tokens, as described above. Temperature then enters the picture by scaling these raw logits — note that this happens before the softmax function converts them into probabilities. Depending on the temperature value, the resulting distribution will look more uniform (high temperature, more uncertainty) or sharper (low temperature, higher certainty).
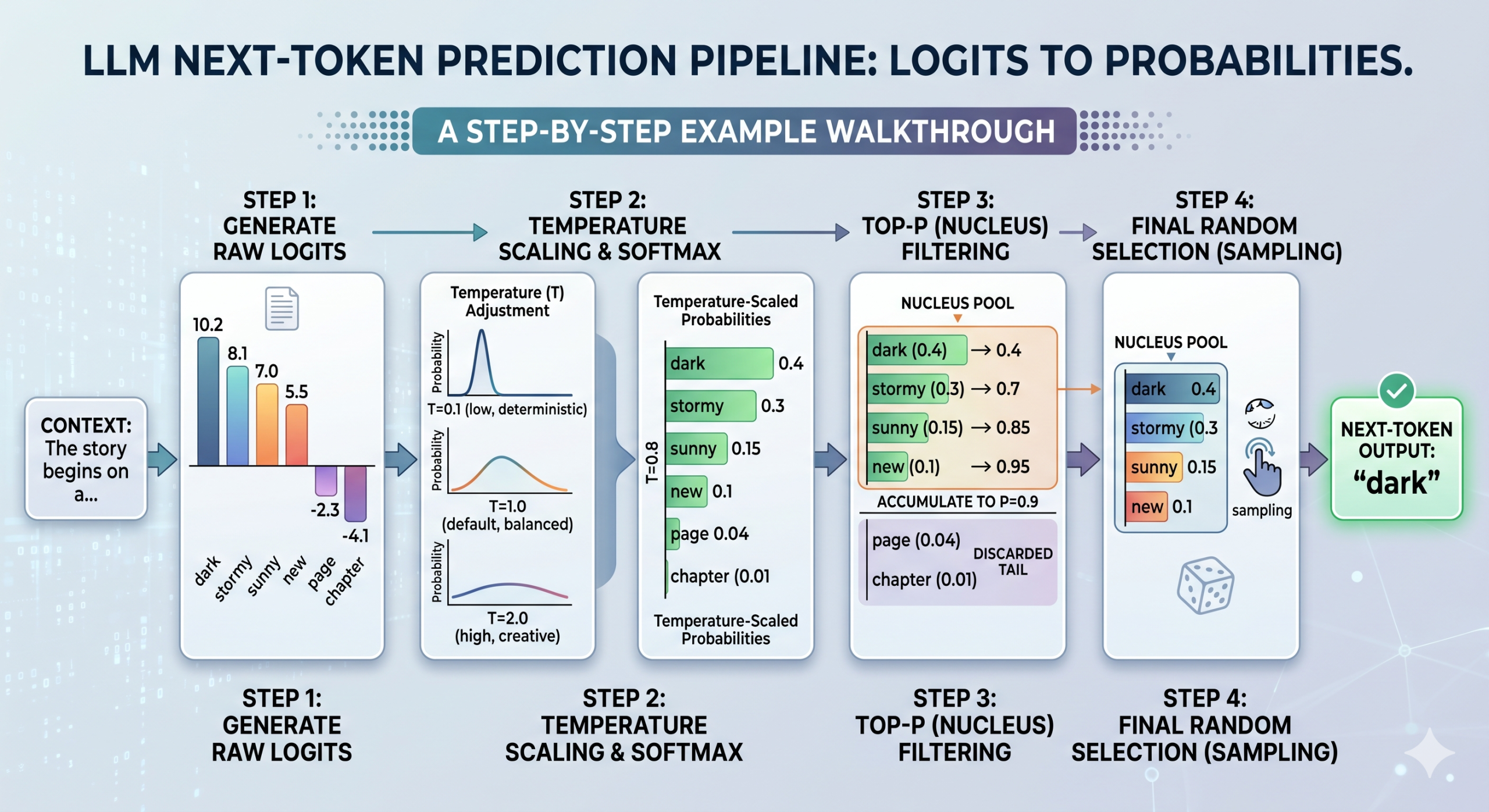
Token selection walkthrough based on logits, temperature, and top-p
Once the scaled logits are converted into probabilities, top-p is applied to filter the resulting distribution, calculating cumulative probabilities to retain only a core “nucleus pool” of the most likely tokens (see step 3 in the image above). Finally, the model samples randomly from within that pool to select the next token.
Closing Remarks
Now that we have demystified the statistical process behind token selection in LLMs, it is useful to consider how to choose values for temperature and top-p in practice. As a developer, you will want to define the right balance between predictability and creativity for your use case. For factual, high-stakes scenarios like coding or legal analysis, a low temperature and a stricter top-p are advisable — e.g. t=0.1 and p=0.5 — which yields highly deterministic model responses. For creative domains like poetry generation or brainstorming, a higher temperature and top-p, such as t=0.8 and p=0.95, allow for a richer variety of candidate tokens in the selection pool.





?")
No comments yet.