The machine learning practitioner has a tradition of algorithms and a pragmatic focus on results and model skill above other concerns such as model interpretability.
Statisticians work on much the same type of modeling problems under the names of applied statistics and statistical learning. Coming from a mathematical background, they have more of a focus on the behavior of models and explainability of predictions.
The very close relationship between the two approaches to the same problem means that both fields have a lot to learn from each other. The statisticians need to consider algorithmic methods was called out in the classic “two cultures” paper. Machine learning practitioners must also take heed, keep an open mind, and learn both the terminology and relevant methods from applied statistics.
In this post, you will discover that machine learning and statistical learning are two closely related but different perspectives on the same problem.
After reading this post, you will know:
- “Machine learning” and “predictive modeling” are a computer science perspective on modeling data with a focus on algorithmic methods and model skill.
- “Statistics” and “statistical learning” are a mathematical perspective on modeling data with a focus on data models and on goodness of fit.
- Machine learning practitioners must keep an open mind and leverage methods and understand the terminology from the closely related fields of applied statistics and statistical learning.
Kick-start your project with my new book Statistics for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

The Close Relationship Between Applied Statistics and Machine Learning
Photo by James Loesch, some rights reserved.
Machine Learning
Machine learning is a subfield of artificial intelligence and is related to the broader field of computer science.
When it comes to developing machine learning models in order to make predictions, there is a heavy focus on algorithms, code, and results.
Machine learning is a lot broader than developing models in order to make predictions, as can be seen by the definition in the classic 1997 textbook by Tom Mitchell.
The field of machine learning is concerned with the question of how to construct computer programs that automatically improve with experience.
— Page xv, Machine Learning, 1997.
Here, we can see that from a research perspective, machine learning is really the study of learning with computer programs. It just so happens that some of these learning programs are useful for predictive modeling problems, and some in fact have been borrowed from other fields, such as statistics.
Linear regression is a perfect example. It is a more-than-a-century-old method from the (at the time: nascent) field of statistics that is used for fitting a line or plane to real-valued data. From a machine learning perspective, we look at it as a system for learning weights (coefficients) in response to examples from a domain.
Many methods have been developed in the field of artificial intelligence and machine learning, sometimes by statisticians, that prove very useful for the task of predictive modeling. A good example is classification and regression trees that bears no resemblance to classical methods in statistics.
Need help with Statistics for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Predictive Modeling
The useful part of machine learning for the practitioner may be called predictive modeling.
This explicitly ignores distinctions between statistics and machine learning. It also shucks off the broader objectives of statistics (understanding data) and machine learning (understanding learning in software) and only concerns itself, as its name suggests, with developing models that make predictions.
The term predictive modeling may stir associations such as machine learning, pattern recognition, and data mining. Indeed, these associations are appropriate and the methods implied by these terms are an integral piece of the predictive modeling process. But predictive modeling encompasses much more than the tools and techniques for uncovering patterns within data. The practice of predictive modeling defines the process of developing a model in a way that we can understand and quantify the model’s prediction accuracy on future, yet-to-be-seen data.
— Page vii, Applied Predictive Modeling, 2013
Predictive modeling provides a laser-focus on developing models with the objective of getting the best possible results with regard to some measure of model skill. This pragmatic approach often means that results in the form of maximum skill or minimum error are sought at the expense of almost everything else.
It doesn’t really matter what we call the process, machine learning or predictive modeling. In some sense it is marketing and group identification. Getting results and delivering value matters more to the practitioner.
Statistical Learning
The process of working with a dataset and developing a predictive model is also a task in statistics.
A statistician may have traditionally referred to the activity as applied statistics.
Statistics is a subfield of mathematics, and this heritage gives a focus of well defined, carefully chosen methods. A need to understand not only why a specific model was chosen, but also how and why specific predictions are made.
From this perspective, often model skill is important, but less important than the interpretability of the model.
Nevertheless, modern statisticians have formulated a new perspective as a subfield of applied statistics called “statistical learning“. It may be the statistics equivalent of “predictive modeling” where model skill is important, but perhaps a stronger emphasis is given to careful selection and introduction of the learning models.
Statistical learning refers to a set of tools for modeling and understanding complex datasets. It is a recently developed area in statistics and blends with parallel developments in computer science and, in particular, machine learning.
— Page vii, An Introduction to Statistical Learning with Applications in R, 2013.
We can see that there is a bleeding of ideas between fields and subfields in statistics. The machine learning practitioner must be aware of both the machine learning and statistical-based approach to the problem. This is especially important given the use of different terminology in both domains.
In his course on statistics, Rob Tibshirani, a statistician who also has a foot in machine learning, provides a glossary that maps terms in statistics to terms in machine learning, reproduced below.
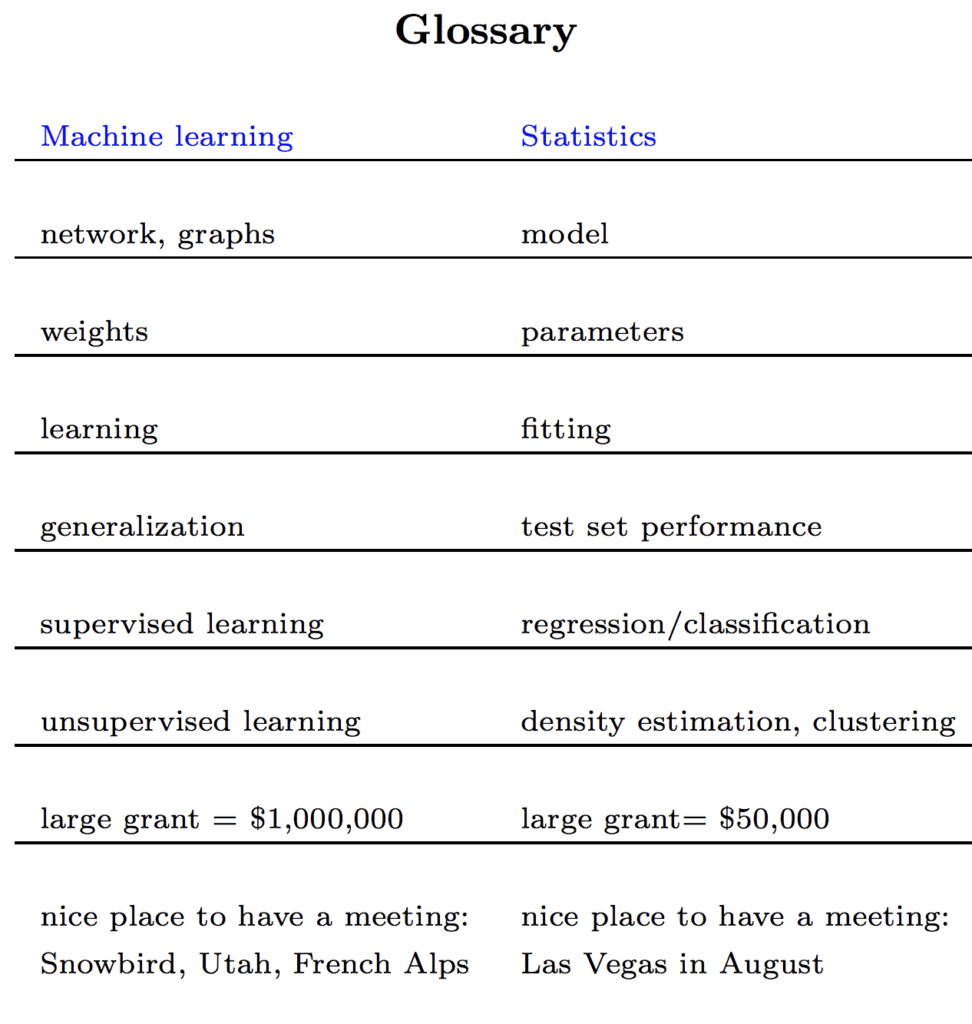
Glossary Mapping Terms in Statistics to Terms in Machine Learning
This highlights the deeper need for the machine learning practitioner to focus on predictive modeling and stay open to methods, ideas, and terminology, regardless of the field of origin. This may apply to modern fields like bioinformatics and econometrics but applies more so to the tightly related and much older field of statistics.
Two Cultures
Recently, and perhaps still now, applied statisticians looked down the field of machine learning and the practice of results-at-any-cost predictive modeling.
Both fields offer tremendous value, but perhaps on subtly different flavors of the same general problem of predictive modeling.
Real and valuable contributions have been made to modeling from the computer science perspective of machine learning such as decision trees mentioned above and artificial neural networks, more recently relabeled deep learning, to name two well known examples.
Just as the machine learning practitioner must keep an eye on applied statistics and statistical learning, the statistician must keep an eye on machine learning.
This call was made clearly in the now (perhaps famous) 2001 paper titled “Statistical Modeling: The Two Cultures” by Leo Breiman.
In it, he contrasts the “data modeling culture” of statisticians to the “algorithmic modeling culture” of all other fields, to which machine learning belongs. He highlights these cultures as ways of thinking about the same problem of mapping inputs to outputs, where the statistical approach is to focus on goodness of fit tests and the algorithmic approach focuses on predictive accuracy.
He suggests that the field of statistics will suffer both by losing relevance and in the fragility of the methods by ignoring the algorithmic approach. The classical approach he refers to as “data models,” a subtle but important shift in focus where a practitioner chooses and focuses on the behavior of the model (e.g. logistic regression) rather than the data and processes that may have generated it.
This might be characterized (perhaps unfairly) as focusing on making the data fit the model rather than choosing or adapting the model to fit the data.
The statistical community has been committed to the almost exclusive use of data models. This commitment has led to irrelevant theory, questionable conclusions, and has kept statisticians from working on a large range of interesting current problems. […] If our goal as a field is to use data to solve problems, then we need to move away from exclusive dependence on data models and adopt a more diverse set of tools.
It’s an important paper, still relevant and a great read more than 15 years later.
The emergence of subfields like “statistical learning” by statisticians suggests that headway is being made.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Statistical Modeling: The Two Cultures, 2001.
- Statistics vs. Machine Learning, fight!, 2008.
- The Two Cultures: statistics vs. machine learning? on Cross Validated
- Glossary: machine learning vs statistics, Modern Applied Statistics: Elements of Statistical Learning.
Summary
In this post, you discovered that machine learning and statistical learning are two closely related but different perspectives on the same problem.
Specifically, you learned:
- “Machine learning” and “predictive modeling” are a computer science perspective on modeling data with a focus on algorithmic methods and model skill.
- “Statistics” and “statistical learning” are a mathematical perspective on modeling data with a focus on data models and on goodness of fit.
- Machine learning practitioners must keep an open mind and leverage methods and understand the terminology from the closely related fields of applied statistics and statistical learning.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Get a Handle on Statistics for Machine Learning!

Develop a working understanding of statistics
...by writing lines of code in python
Discover how in my new Ebook:
Statistical Methods for Machine Learning
It provides self-study tutorials on topics like:
Hypothesis Tests, Correlation, Nonparametric Stats, Resampling, and much more...
Discover how to Transform Data into Knowledge
Skip the Academics. Just Results.






Reminds me of when I was an engineering undergrad (a long time ago). There was a similar cultural divide. The mathematicians thought engineers were “crude” for taking formulas and applying them just because they worked, while not really knowing why. And the engineers thought the mathematicians were impractical with all their theorizing for the sake of it!
Dear Ken and Dr Jason,
It reminds me of my first year mathematics lecturer who said to his students that the calculus involved in producing CT scans was developed in the 1930s. In the 1930s the technology to process images was non-existent, let alone computers. Thus the engineering and application of the calculus was not possible. It may well be that pure mathematics may be ahead of engineering and the pure mathematicians have to wait for their theories to come to reality.
Regards
Anthony of Sydney
It may be and there is a place for it for sure.
But today we need results and must focus on what is working.
Yep.
Deep learning, which is supposed to replace most of machine learning in the near future rarely makes use of statistics.
I could not disagree more.
Deep learning is not replacing all classical or ml methods, it is just one more method to use.
You cannot choose/understand training data or evaluate/present model performance without stats, deep learning or otherwise.
Perhaps skim this post for more reasons:
https://machinelearningmastery.com/what-is-statistics/
Why aren’t you monetizing your site? How can I support?
Thanks for asking, this is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/how-can-i-support-you