In this article, you will learn how to evaluate AI agents rigorously by examining their full execution process rather than only their final outputs.
Topics we will cover include:
- Why agent evaluation differs from traditional language model evaluation, and where agents fail across the reasoning and action layers.
- How to grade agents with deterministic code-based checks and model-based judges, matched to the type of agent you are building.
- How to account for non-determinism using metrics like pass@k and pass^k, and how to extend evaluation from development into production monitoring.

The Roadmap to Mastering AI Agent Evaluation
Let’s not waste any more time.
Introduction
Many teams building AI agents still evaluate them the same way they evaluate large language models: run a few tasks, inspect the final output, and assume everything is working. That approach often misses the failures that matter most. The model may select an inappropriate tool or generate incorrect tool arguments, while the agent system may handle tool failures poorly or follow an inefficient sequence of actions. Evaluating only the final response often makes it difficult to identify where these failures occurred.
Agent evaluation addresses this gap. Rather than focusing solely on outcomes, it examines the full execution process — how an agent reasons, makes decisions, uses tools, and adapts as a task unfolds. This provides a more accurate picture of reliability, efficiency, and overall performance, helping teams identify issues before they reach production.
The principles covered in this article form the foundation of a systematic approach to measuring and improving agent performance.
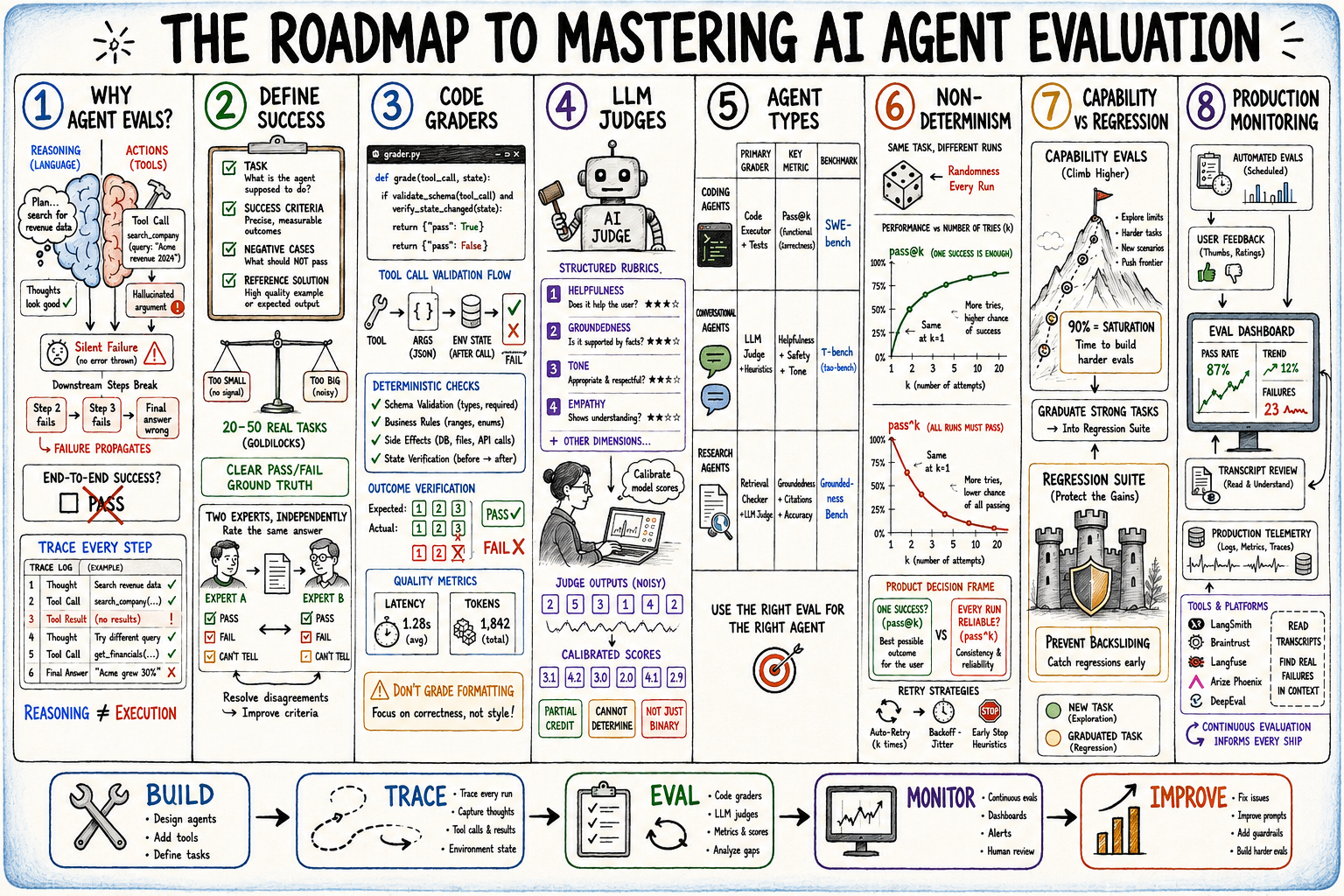
The Roadmap (click to enlarge)
Step 1: Understanding Why Agent Evaluation Is Important
The instinct when an agent fails is to treat it as a prompting problem: the system prompt needs to be clearer. Sometimes that is true. More often the failure is a measurement problem: the eval was not designed to catch what broke.
AI agents operate across layers, and those layers may fail independently:
- The reasoning layer — powered by the language model — handles planning, task decomposition, and tool selection.
- The action layer — powered by tool calls and external system responses — handles execution.
An agent can reason correctly about what to do and then call the right tool with malformed arguments. Treating agent evaluation as a single end-to-end accuracy check misses both failure surfaces.
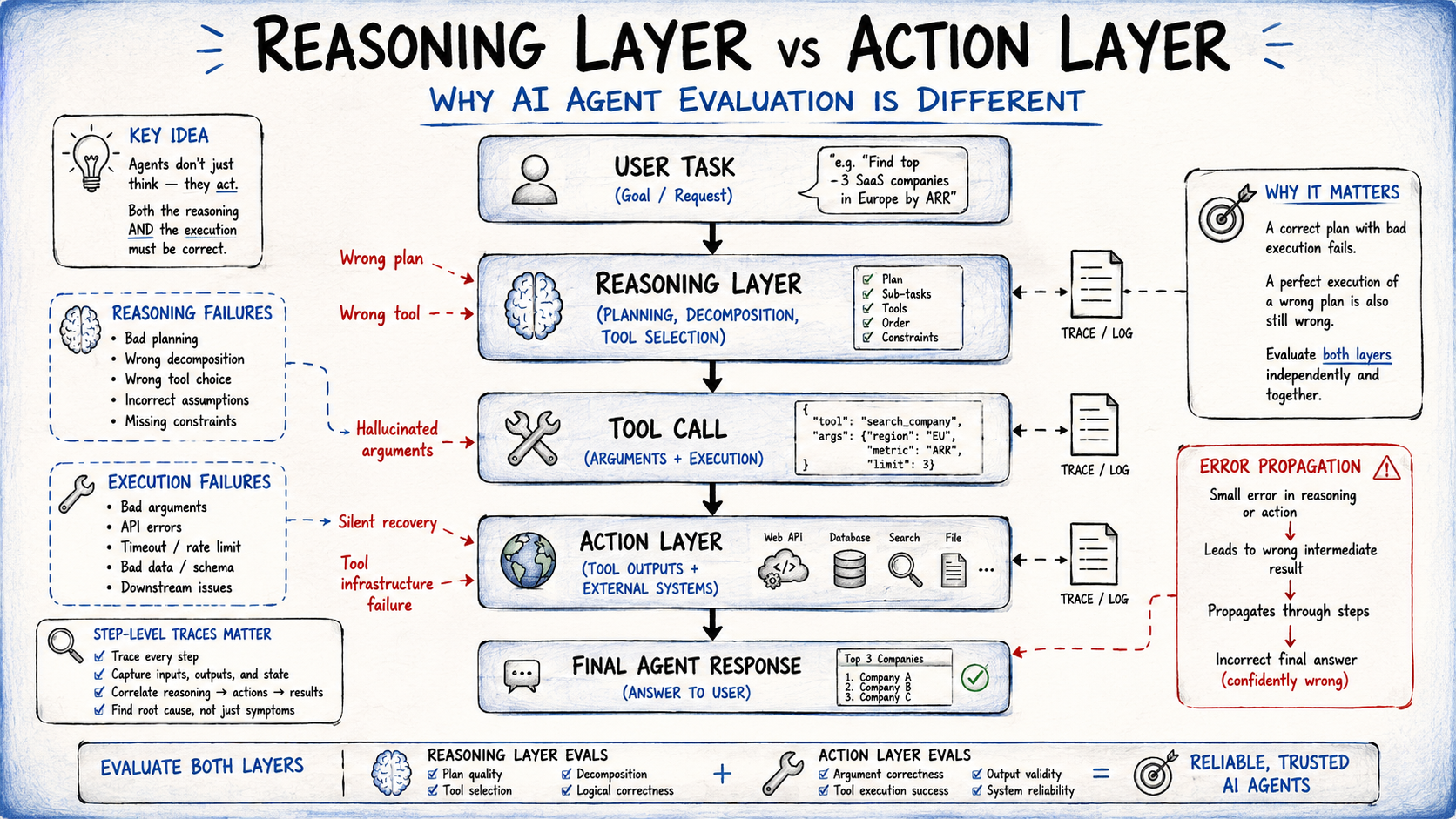
Reasoning vs Action Layer
Useful agent evaluation runs at two scopes:
- Component-level evaluation: measuring reasoning quality and tool-calling accuracy in isolation
- End-to-end evaluation: measuring task completion and execution efficiency
A task completion rate of 80% tells you nothing about whether the 20% failure comes from bad planning, wrong tool selection, incorrect arguments, or tool infrastructure failures. Step-level traces — logs capturing each tool call, its arguments, its result, and the subsequent model decision — are what make that diagnosis possible. Without traces, debugging a production failure is guesswork.
Step 2: Defining What Agent Evaluation Success Looks Like
Evaluation is only as good as its success criteria. A well-formed eval task is one where two domain experts, working independently, would reach the same pass/fail verdict.
Start with unambiguous task specifications paired with reference solutions — known-correct outputs that pass all graders. They prove the task is solvable and verify that grading logic is correctly configured.
You need the following defined for evals before any grading runs:
- The task: what inputs the agent receives, what it’s expected to do, and what the environment looks like going in
- The success criteria: not just the final answer, but the intermediate outcomes that matter: Was the right tool called? Was the state correctly updated? Was the response grounded in the retrieved context?
- The negative cases: one-sided evals create one-sided optimization. Balanced datasets — covering both when a behavior should occur and when it should not — prevent agents that over-trigger or under-trigger on a capability
A set of well-specified tasks drawn from real usage failures is a better starting point than waiting for the perfect dataset. Evals get harder to build the longer you wait.
Step 3: Grading the Agent Action Layer with Code-Based Checks
Deterministic graders — code that checks specific conditions without model-in-the-loop judgment — are the fastest, cheapest, and most reproducible option in any agent eval stack. For the action layer, they should always be the starting point:
- Tool call verification: whether the agent called the right tool in the correct sequence
- Argument validation: whether inputs have correct types, required parameters, and valid values
- Outcome verification: whether the environment ends in the expected state
- Transcript analysis: number of turns, tokens consumed, and latency
These are often fast, objective, and easy to debug, but brittle. A grader checking for “confirmation_code”: “CONF-789” will miss a correct response that formats the same data differently.
Step 4: Grading Agent Reasoning and Output Quality with Model-Based Judges
Some agent evaluation dimensions resist deterministic checking — output quality, tone, faithfulness to retrieved context, appropriate empathy. For these, a language model used as a judge or LLM-as-a-Judge is the right tool: flexible and capable of handling open-ended output, but introducing non-determinism and calibration drift that code-based graders don’t have.
The following practices keep model-based graders reliable:
Write structured rubrics. “Evaluate whether the response is helpful” produces noise. A rubric specifying that the response must address the user’s question, ground claims in retrieved context, and avoid out-of-scope suggestions produces a signal. Grade each dimension with a separate, isolated judgment.
Calibrate against human judgment regularly. LLM-as-judge accuracy should be checked against a sample graded by domain experts. Where divergence shows up, the rubric is almost always the problem. Give the grader an explicit “Cannot determine” option to avoid forced judgments on ambiguous cases.
Build in partial credit for multi-component tasks. A support agent that correctly identifies the problem and verifies the customer but fails to process the refund is meaningfully better than one that fails on step one. Binary pass/fail hides where the agent is actually breaking down.
Step 5: Matching Agent Evaluation Strategy to Agent Type
Grading strategies apply broadly, but agent type determines which graders carry the most weight and which failure modes to prioritize.
Coding agents write, test, and debug code. Software is largely deterministic: does the code run, do the tests pass, does the fix close the issue without breaking existing functionality? Benchmarks like SWE-bench Verified and Terminal-Bench follow this pass/fail approach, supplemented by rubric-based quality checks for security, readability, and edge case handling.
Conversational agents interact with users across support, sales, and coaching workflows. The quality of the interaction is part of what’s being evaluated — not only whether the ticket was resolved, but whether the tone was appropriate and the resolution clearly explained. This requires a second language model simulating the user; τ-bench models exactly this, with graders assessing both task completion and interaction quality across turns.
Research agents gather and synthesize information across sources. Groundedness checks verify claims are supported by retrieved sources, coverage checks define what a good answer must include, and source quality checks confirm the agent consulted authoritative material.
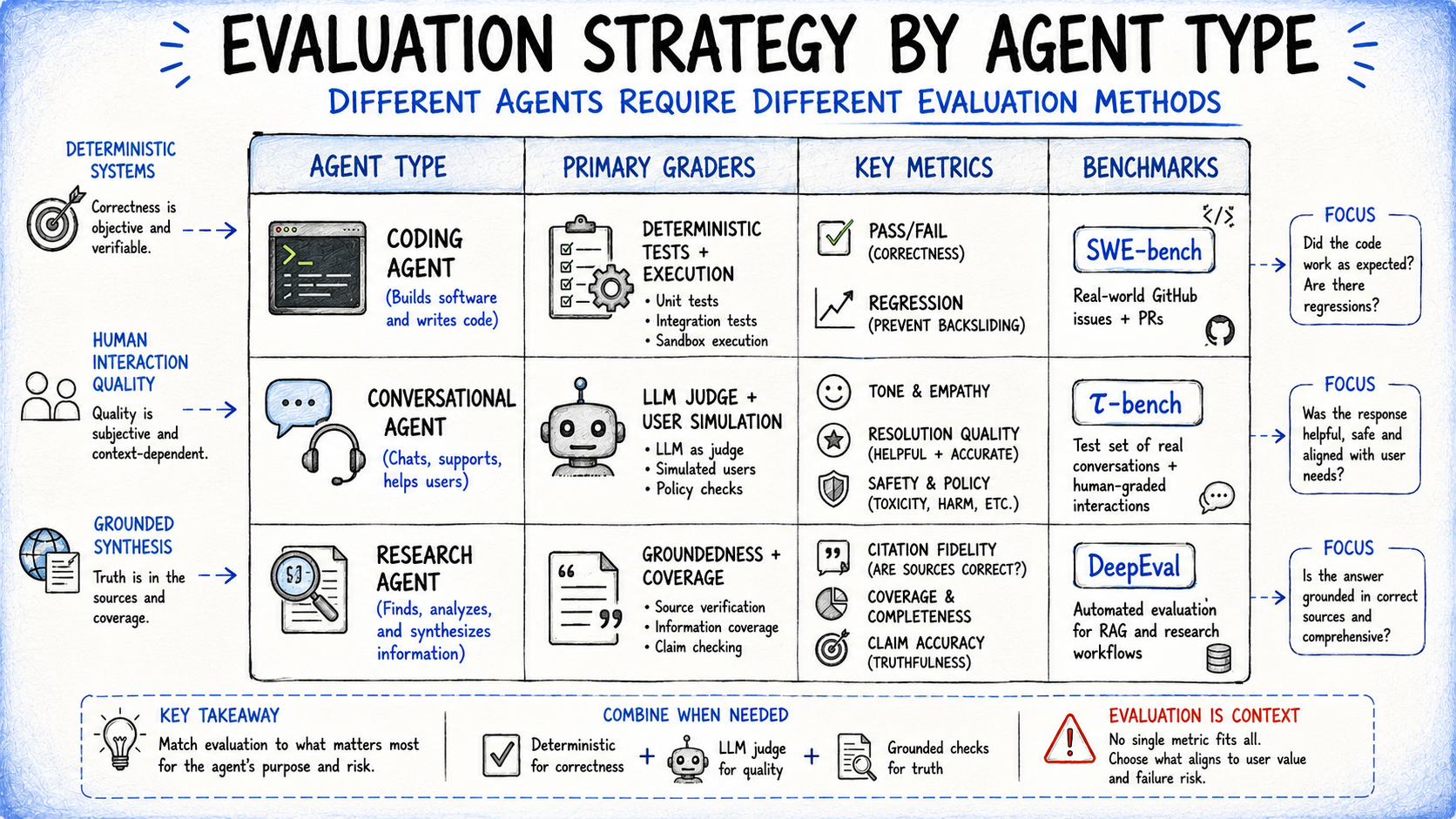
Matching Agent Evaluation Strategy to Agent Type
Step 6: Accounting for Non-Determinism in Agent Evaluation Results
Agent behavior varies between runs; the same task, same inputs, same agent can produce different tool selections, reasoning paths, and outcomes. Single-trial evaluation can therefore be misleading, since it hides variability that simple accuracy metrics fail to capture.
This is a direct consequence of non-determinism in agent systems. Stochastic model outputs, tool latency, partial failures, and adaptive decision-making all introduce variability across runs. As a result, evaluating an agent requires reasoning over distributions of outcomes rather than a single execution trace.
To account for this variability, metrics like pass@k and pass^k are commonly used:
- pass@k: the probability that at least one of k independent trials succeeds, useful when multiple attempts are acceptable
- pass^k: the probability that all k trials succeed, important when every interaction must be reliable
For example, an agent with a 75 percent single-trial success rate succeeds on all three attempts only about 42 percent of the time, showing how quickly reliability degrades across repeated runs.
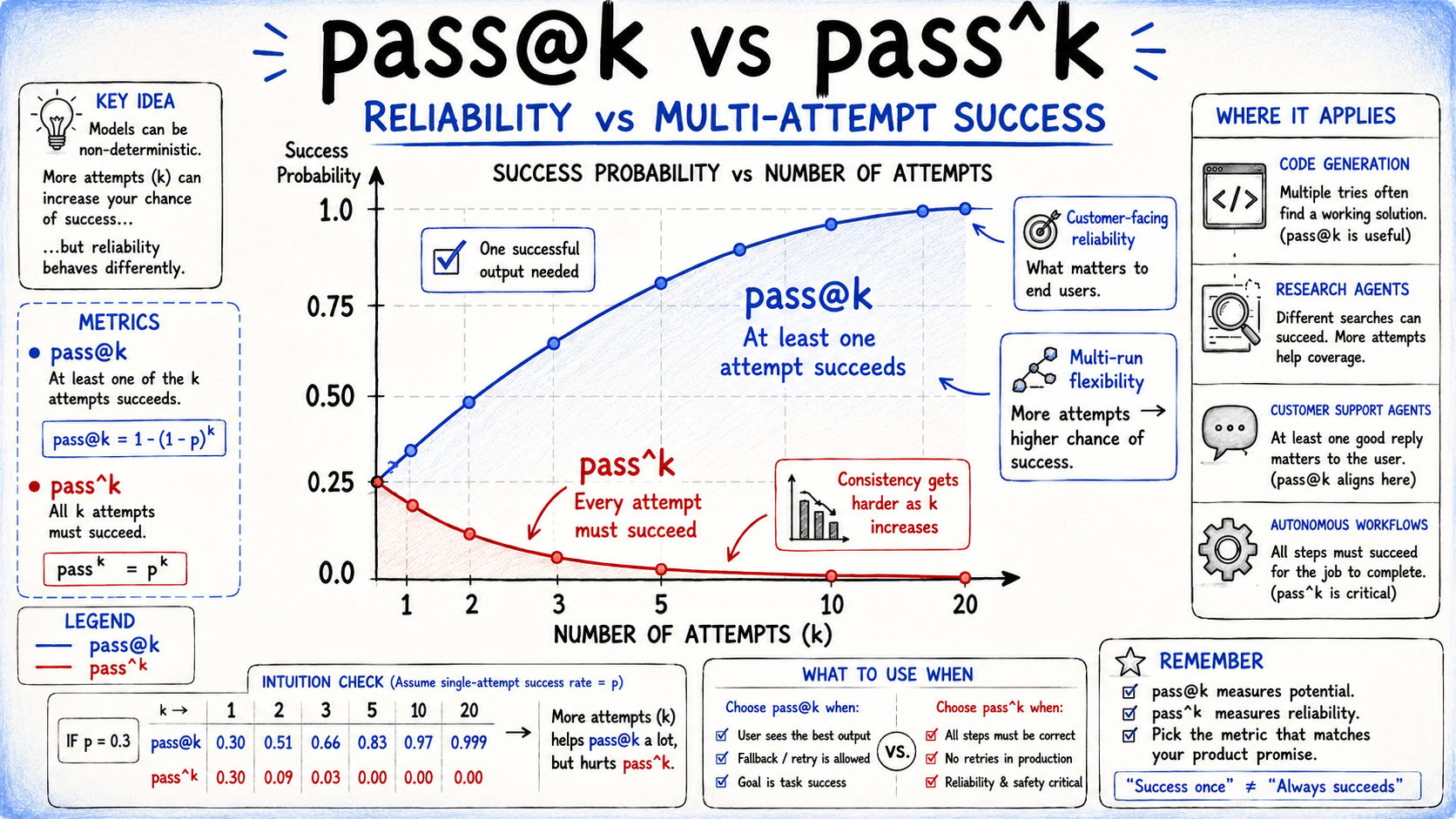
pass@k and pass^k
The choice between these metrics is ultimately a product decision rather than a purely technical one. If only one correct outcome is needed, pass@1 or pass@k is useful. If every interaction must succeed consistently, pass^k is the more meaningful measure.
Step 7: Separating Agent Capability Evals from Regression Suites
Capability evals are designed to answer a forward-looking question: what can this agent do that it couldn’t do before? Because of that, they should begin with relatively low pass rates and focus on tasks that are still challenging for the system. When a capability eval reaches very high scores — say 90 percent — it is often no longer measuring capability, but simply confirming reliability on already solved problems.
Regression evals serve a different purpose. They ask whether the agent can still perform everything it previously could. These tests should run close to 100 percent and act as a safeguard against performance regressions. Any meaningful drop in score is a signal that something has broken and should be investigated before release.
Over time, capability evals naturally become easier for the agent. As pass rates rise and performance stabilizes, those tasks can be promoted into the regression suite. However, once a suite fully saturates, it becomes less sensitive to real improvements — meaning meaningful progress may appear as noise rather than signal. For this reason, new and more challenging evals should be introduced before the existing suite saturates, not after.
Step 8: Extending Agent Evaluation into Production Monitoring
Development evals capture what you expect to fail; production reveals what actually does. Real users introduce inputs, edge cases, and contexts that rarely appear in synthetic test suites, making production monitoring a necessary extension of evaluation.
A complete evaluation system combines several complementary signals:
| Method | What it Captures |
|---|---|
| Automated evals | Run on every commit, covering known failure modes at scale before users are impacted. Can create false confidence when real-world usage diverges from the test distribution. |
| Production monitoring | Tracks latency, error rates, tool failures, and token usage. Surfaces issues synthetic tests miss, but typically only after they occur. |
| User feedback | Highlights cases where the agent seems correct by metrics but fails the user’s intent. Sparse and self-selected, but often highly informative. |
| Manual transcript review | Provides qualitative insight into reasoning, tool use, and decision paths, and helps validate whether automated graders are measuring the right behaviors. |
Together, these layers form a more complete view of agent performance in practice. Step-level traces — capturing reasoning, tool calls, arguments, results, and decisions at each point in the loop — are the infrastructure that makes all of this work. Tools like LangSmith, Arize Phoenix, Braintrust, and Langfuse provide tracing and eval frameworks;Harbor and DeepEval handle the harness layer.
Summary of Key Agent Evaluation Steps
Here’s a quick overview of the steps we’ve discussed:
| Step | Why it Matters |
|---|---|
| Agent evaluation as a distinct problem | Agents fail across reasoning and action layers. End-to-end accuracy can hide both types of failures. |
| Defining success before measuring it | Clear specifications and reference outputs reduce noise and make evaluation metrics more meaningful. |
| Code-based graders for the action layer | Deterministic checks quickly identify tool usage, argument, and execution errors. |
| Model-based judges for reasoning and output quality | LLM-based grading captures nuanced qualities such as correctness, faithfulness, and tone. |
| Evaluation strategy by agent type | Different agents fail in different ways, requiring evaluation methods tailored to each use case. |
| pass@k and pass^k for non-determinism | Single-run results can be misleading. Metrics should reflect whether one or all attempts must succeed. |
| Capability vs regression evals | Capability evaluations measure progress, while regression evaluations protect existing performance. |
| Extending evaluation into production | Monitoring, user feedback, and transcript reviews reveal real-world failures that offline evaluations may miss. |
As a next step, read Anthropic’s Demystifying evals for AI agents guide, especially the section Going from zero to one: a roadmap to great evals for agents.






Great insights on AI agent evaluation. The explanation of reasoning vs. action layers, deterministic grading, and production monitoring clearly demonstrates why evaluating only the final output is not enough. This is a valuable resource for teams building reliable AI-powered applications.
Thank you for your feedback and support zensys! Keep us posted on your progress!