Data visualization provides insight into the distribution and relationships between variables in a dataset.
This insight can be helpful in selecting data preparation techniques to apply prior to modeling and the types of algorithms that may be most suited to the data.
Seaborn is a data visualization library for Python that runs on top of the popular Matplotlib data visualization library, although it provides a simple interface and aesthetically better-looking plots.
In this tutorial, you will discover a gentle introduction to Seaborn data visualization for machine learning.
After completing this tutorial, you will know:
- How to summarize the distribution of variables using bar charts, histograms, and box and whisker plots.
- How to summarize relationships using line plots and scatter plots.
- How to compare the distribution and relationships of variables for different class values on the same plot.
Kick-start your project with my new book Machine Learning Mastery With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

How to use Seaborn Data Visualization for Machine Learning
Photo by Martin Pettitt, some rights reserved.
Tutorial Overview
This tutorial is divided into six parts; they are:
- Seaborn Data Visualization Library
- Line Plots
- Bar Chart Plots
- Histogram Plots
- Box and Whisker Plots
- Scatter Plots
Seaborn Data Visualization Library
The primary plotting library for Python is called Matplotlib.
Seaborn is a plotting library that offers a simpler interface, sensible defaults for plots needed for machine learning, and most importantly, the plots are aesthetically better looking than those in Matplotlib.
Seaborn requires that Matplotlib is installed first.
You can install Matplotlib directly using pip, as follows:
|
1 |
sudo pip install matplotlib |
Once installed, you can confirm that the library can be loaded and used by printing the version number, as follows:
|
1 2 3 |
# matplotlib import matplotlib print('matplotlib: %s' % matplotlib.__version__) |
Running the example prints the current version of the Matplotlib library.
|
1 |
matplotlib: 3.1.2 |
Next, the Seaborn library can be installed, also using pip:
|
1 |
sudo pip install seaborn |
Once installed, we can also confirm the library can be loaded and used by printing the version number, as follows:
|
1 2 3 |
# seaborn import seaborn print('seaborn: %s' % seaborn.__version__) |
Running the example prints the current version of the Seaborn library.
|
1 |
seaborn: 0.10.0 |
To create Seaborn plots, you must import the Seaborn library and call functions to create the plots.
Importantly, Seaborn plotting functions expect data to be provided as Pandas DataFrames. This means that if you are loading your data from CSV files, you must use Pandas functions like read_csv() to load your data as a DataFrame. When plotting, columns can then be specified via the DataFrame name or column index.
To show the plot, you can call the show() function on Matplotlib library.
|
1 2 3 |
... # display the plot pyplot.show() |
Alternatively, the plots can be saved to file, such as a PNG formatted image file. The savefig() Matplotlib function can be used to save images.
|
1 2 3 |
... # save the plot pyplot.savefig('my_image.png') |
Now that we have Seaborn installed, let’s look at some common plots we may need when working with machine learning data.
Line Plots
A line plot is generally used to present observations collected at regular intervals.
The x-axis represents the regular interval, such as time. The y-axis shows the observations, ordered by the x-axis and connected by a line.
A line plot can be created in Seaborn by calling the lineplot() function and passing the x-axis data for the regular interval, and y-axis for the observations.
We can demonstrate a line plot using a time series dataset of monthly car sales.
The dataset has two columns: “Month” and “Sales.” Month will be used as the x-axis and Sales will be plotted on the y-axis.
|
1 2 3 |
... # create line plot lineplot(x='Month', y='Sales', data=dataset) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# line plot of a time series dataset from pandas import read_csv from seaborn import lineplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' dataset = read_csv(url, header=0) # create line plot lineplot(x='Month', y='Sales', data=dataset) # show plot pyplot.show() |
Running the example first loads the time series dataset and creates a line plot of the data, clearly showing a trend and seasonality in the sales data.

Line Plot of a Time Series Dataset
For more great examples of line plots with Seaborn, see: Visualizing statistical relationships.
Bar Chart Plots
A bar chart is generally used to present relative quantities for multiple categories.
The x-axis represents the categories that are spaced evenly. The y-axis represents the quantity for each category and is drawn as a bar from the baseline to the appropriate level on the y-axis.
A bar chart can be created in Seaborn by calling the countplot() function and passing the data.
We will demonstrate a bar chart with a variable from the breast cancer classification dataset that is comprised of categorical input variables.
We will just plot one variable, in this case, the first variable which is the age bracket.
|
1 2 3 |
... # create line plot countplot(x=0, data=dataset) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# bar chart plot of a categorical variable from pandas import read_csv from seaborn import countplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv' dataset = read_csv(url, header=None) # create bar chart plot countplot(x=0, data=dataset) # show plot pyplot.show() |
Running the example first loads the breast cancer dataset and creates a bar chart plot of the data, showing each age group and the number of individuals (samples) that fall within reach group.
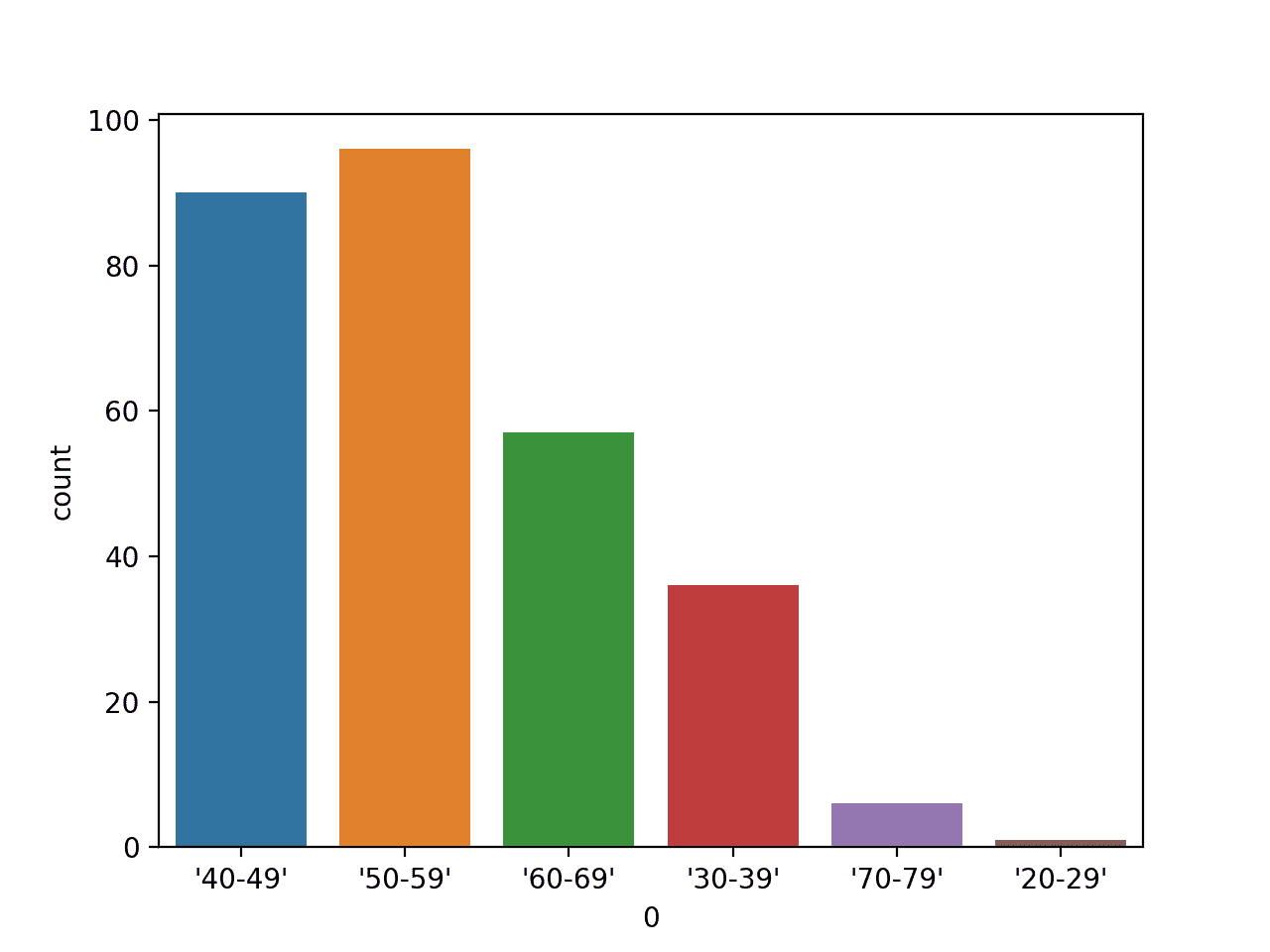
Bar Chart Plot of Age Range Categorical Variable
We might also want to plot the counts for each category for a variable, such as the first variable, against the class label.
This can be achieved using the countplot() function and specifying the class variable (column index 9) via the “hue” argument, as follows:
|
1 2 3 |
... # create bar chart plot countplot(x=0, hue=9, data=dataset) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# bar chart plot of a categorical variable against a class variable from pandas import read_csv from seaborn import countplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv' dataset = read_csv(url, header=None) # create bar chart plot countplot(x=0, hue=9, data=dataset) # show plot pyplot.show() |
Running the example first loads the breast cancer dataset and creates a bar chart plot of the data, showing each age group and the number of individuals (samples) that fall within each group separated by the two class labels for the dataset.
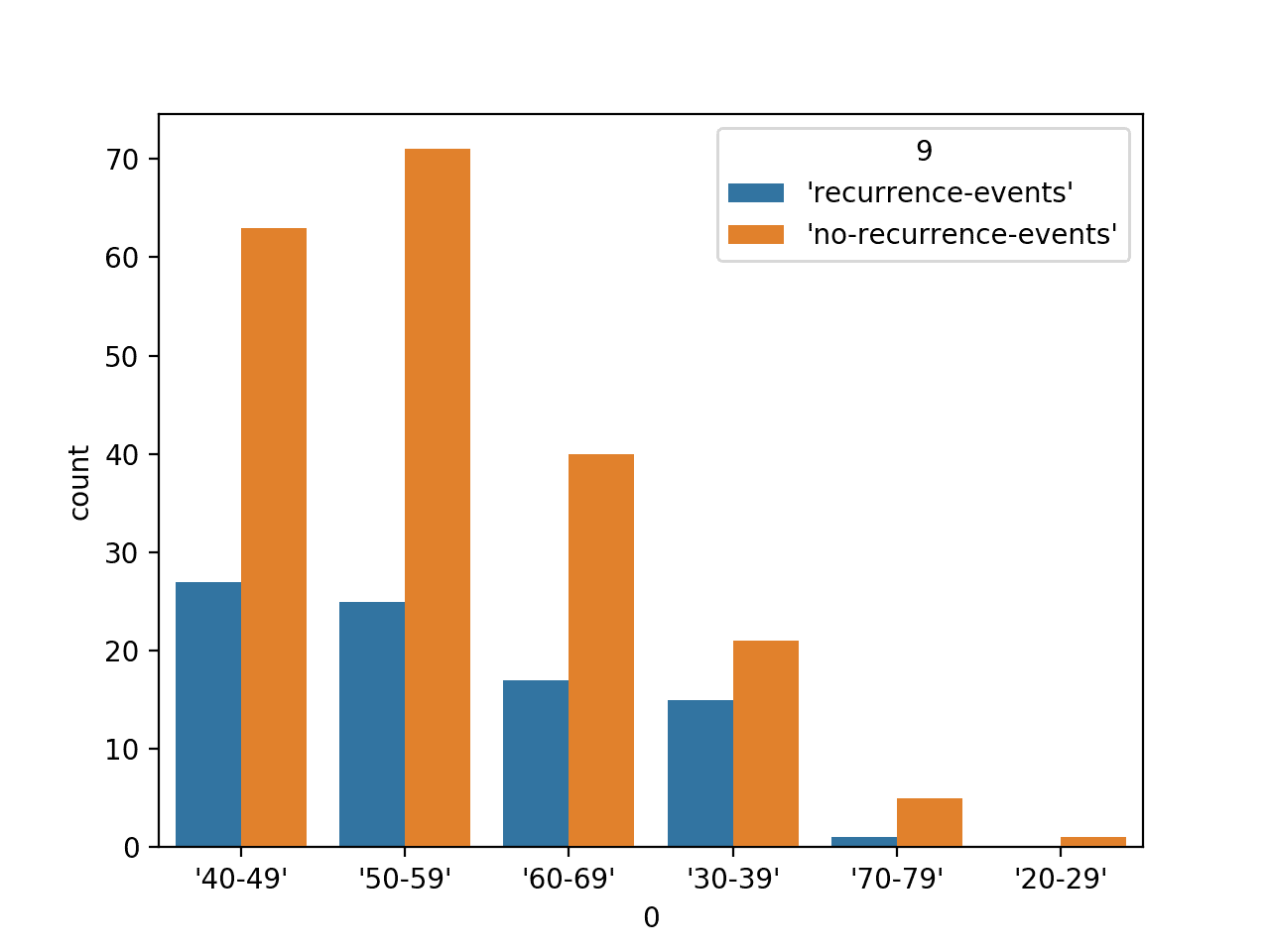
Bar Chart Plot of Age Range Categorical Variable by Class Label
For more great examples of bar chart plots with Seaborn, see: Plotting with categorical data.
Histogram Plots
A histogram plot is generally used to summarize the distribution of a numerical data sample.
The x-axis represents discrete bins or intervals for the observations. For example, observations with values between 1 and 10 may be split into five bins, the values [1,2] would be allocated to the first bin, [3,4] would be allocated to the second bin, and so on.
The y-axis represents the frequency or count of the number of observations in the dataset that belong to each bin.
Essentially, a data sample is transformed into a bar chart where each category on the x-axis represents an interval of observation values.
A histogram can be created in Seaborn by calling the distplot() function and passing the variable.
We will demonstrate a boxplot with a numerical variable from the diabetes classification dataset. We will just plot one variable, in this case, the first variable, which is the number of times that a patient was pregnant.
|
1 2 3 |
... # create histogram plot distplot(dataset[[0]]) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# histogram plot of a numerical variable from pandas import read_csv from seaborn import distplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # create histogram plot distplot(dataset[[0]]) # show plot pyplot.show() |
Running the example first loads the diabetes dataset and creates a histogram plot of the variable, showing the distribution of the values with a hard cut-off at zero.
The plot shows both the histogram (counts of bins) as well as a smooth estimate of the probability density function.
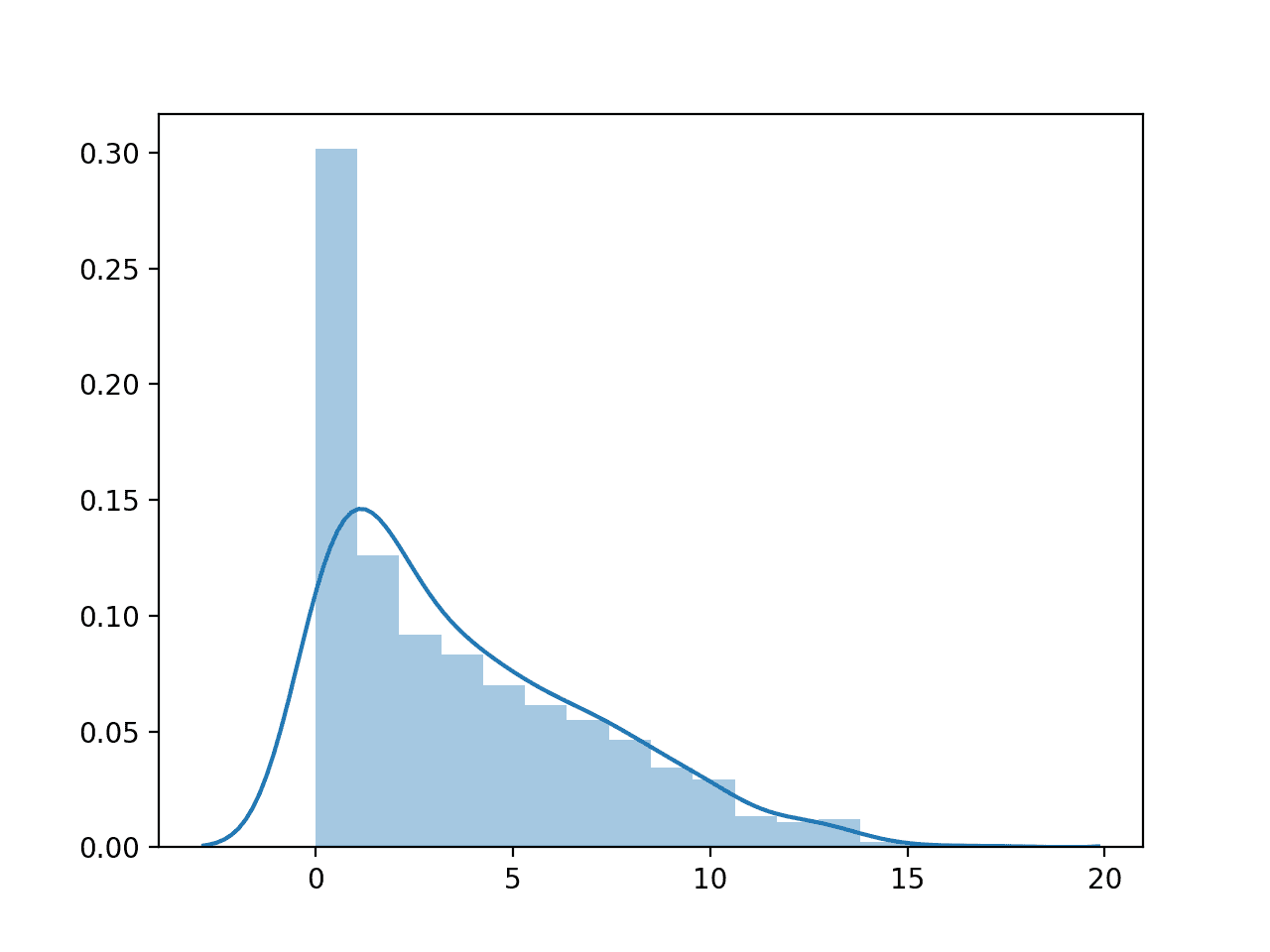
Histogram Plot of Number of Times Pregnant Numerical Variable
For more great examples of histogram plots with Seaborn, see: Visualizing the distribution of a dataset.
Box and Whisker Plots
A box and whisker plot, or boxplot for short, is generally used to summarize the distribution of a data sample.
The x-axis is used to represent the data sample, where multiple boxplots can be drawn side by side on the x-axis if desired.
The y-axis represents the observation values. A box is drawn to summarize the middle 50 percent of the dataset starting at the observation at the 25th percentile and ending at the 75th percentile. This is called the interquartile range, or IQR. The median, or 50th percentile, is drawn with a line.
Lines called whiskers are drawn extending from both ends of the box, calculated as (1.5 * IQR) to demonstrate the expected range of sensible values in the distribution. Observations outside the whiskers might be outliers and are drawn with small circles.
A boxplot can be created in Seaborn by calling the boxplot() function and passing the data.
We will demonstrate a boxplot with a numerical variable from the diabetes classification dataset. We will just plot one variable, in this case, the first variable, which is the number of times that a patient was pregnant.
|
1 2 3 |
... # create box and whisker plot boxplot(x=0, data=dataset) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# box and whisker plot of a numerical variable from pandas import read_csv from seaborn import boxplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # create box and whisker plot boxplot(x=0, data=dataset) # show plot pyplot.show() |
Running the example first loads the diabetes dataset and creates a boxplot plot of the first input variable, showing the distribution of the number of times patients were pregnant.
We can see the median just above 2.5 times, some outliers up around 15 times (wow!).
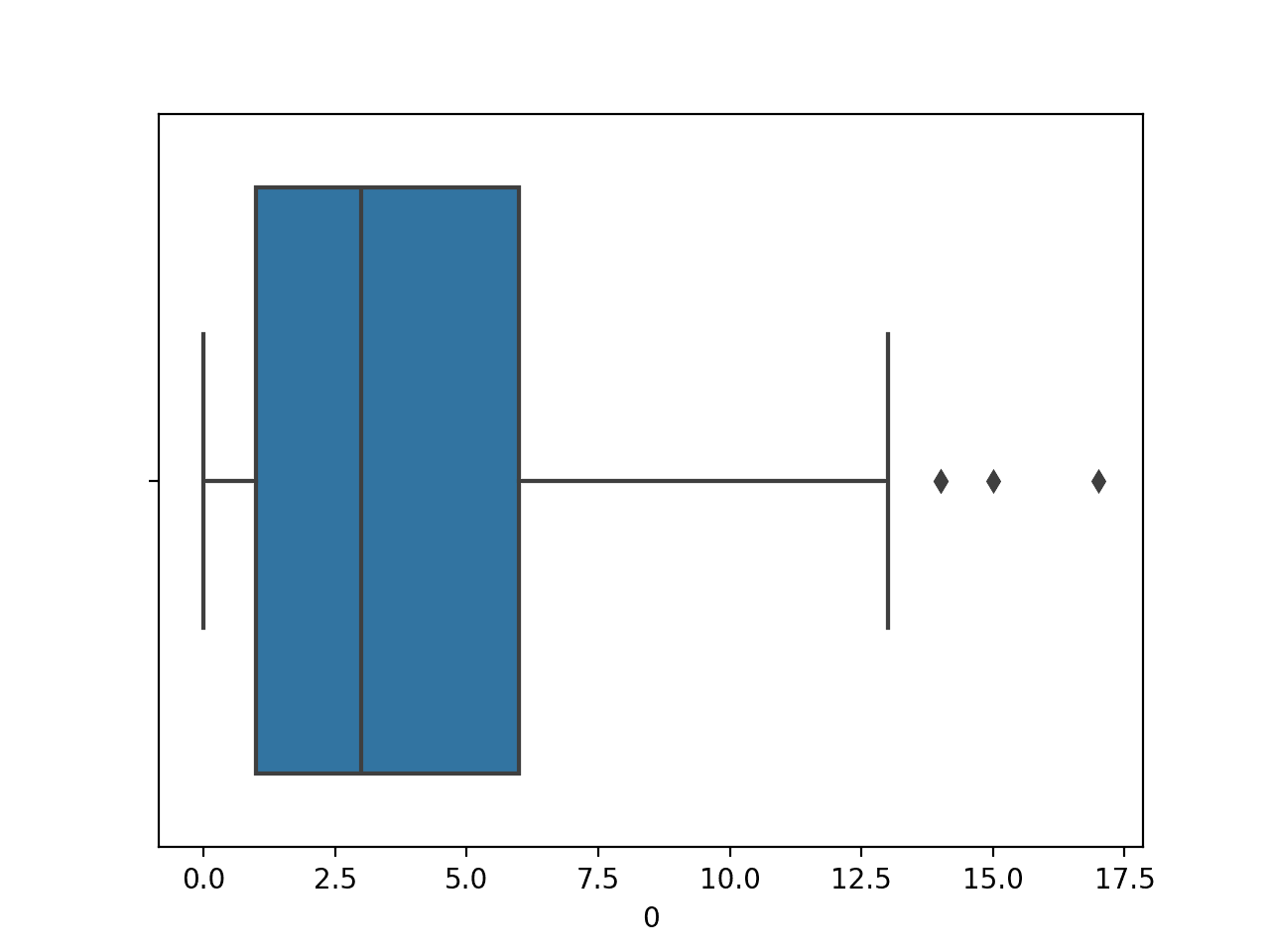
Box and Whisker Plot of Number of Times Pregnant Numerical Variable
We might also want to plot the distribution of the numerical variable for each value of a categorical variable, such as the first variable, against the class label.
This can be achieved by calling the boxplot() function and passing the class variable as the x-axis and the numerical variable as the y-axis.
|
1 2 3 |
... # create box and whisker plot boxplot(x=8, y=0, data=dataset) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# box and whisker plot of a numerical variable vs class label from pandas import read_csv from seaborn import boxplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # create box and whisker plot boxplot(x=8, y=0, data=dataset) # show plot pyplot.show() |
Running the example first loads the diabetes dataset and creates a boxplot of the data, showing the distribution of the number of times pregnant as a numerical variable for the two-class labels.
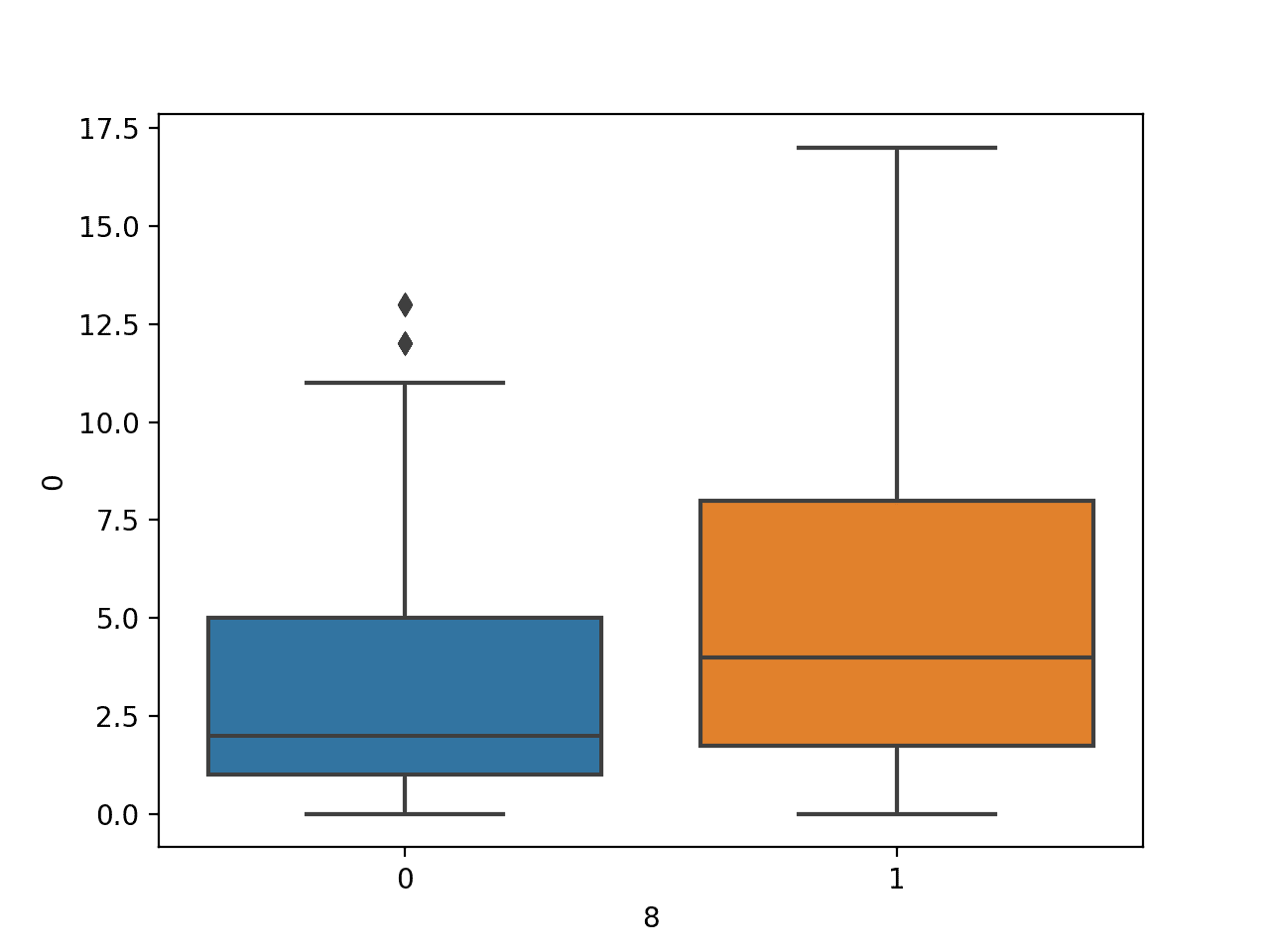
Box and Whisker Plot of Number of Times Pregnant Numerical Variable by Class Label
Scatter Plots
A scatter plot, or scatterplot, is generally used to summarize the relationship between two paired data samples.
Paired data samples mean that two measures were recorded for a given observation, such as the weight and height of a person.
The x-axis represents observation values for the first sample, and the y-axis represents the observation values for the second sample. Each point on the plot represents a single observation.
A scatterplot can be created in Seaborn by calling the scatterplot() function and passing the two numerical variables.
We will demonstrate a scatterplot with two numerical variables from the diabetes classification dataset. We will plot the first versus the second variable, in this case, the first variable, which is the number of times that a patient was pregnant, and the second is the plasma glucose concentration after a two hour oral glucose tolerance test (more details of the variables here).
|
1 2 3 |
... # create scatter plot scatterplot(x=0, y=1, data=dataset) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# scatter plot of two numerical variables from pandas import read_csv from seaborn import scatterplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # create scatter plot scatterplot(x=0, y=1, data=dataset) # show plot pyplot.show() |
Running the example first loads the diabetes dataset and creates a scatter plot of the first two input variables.
We can see a somewhat uniform relationship between the two variables.
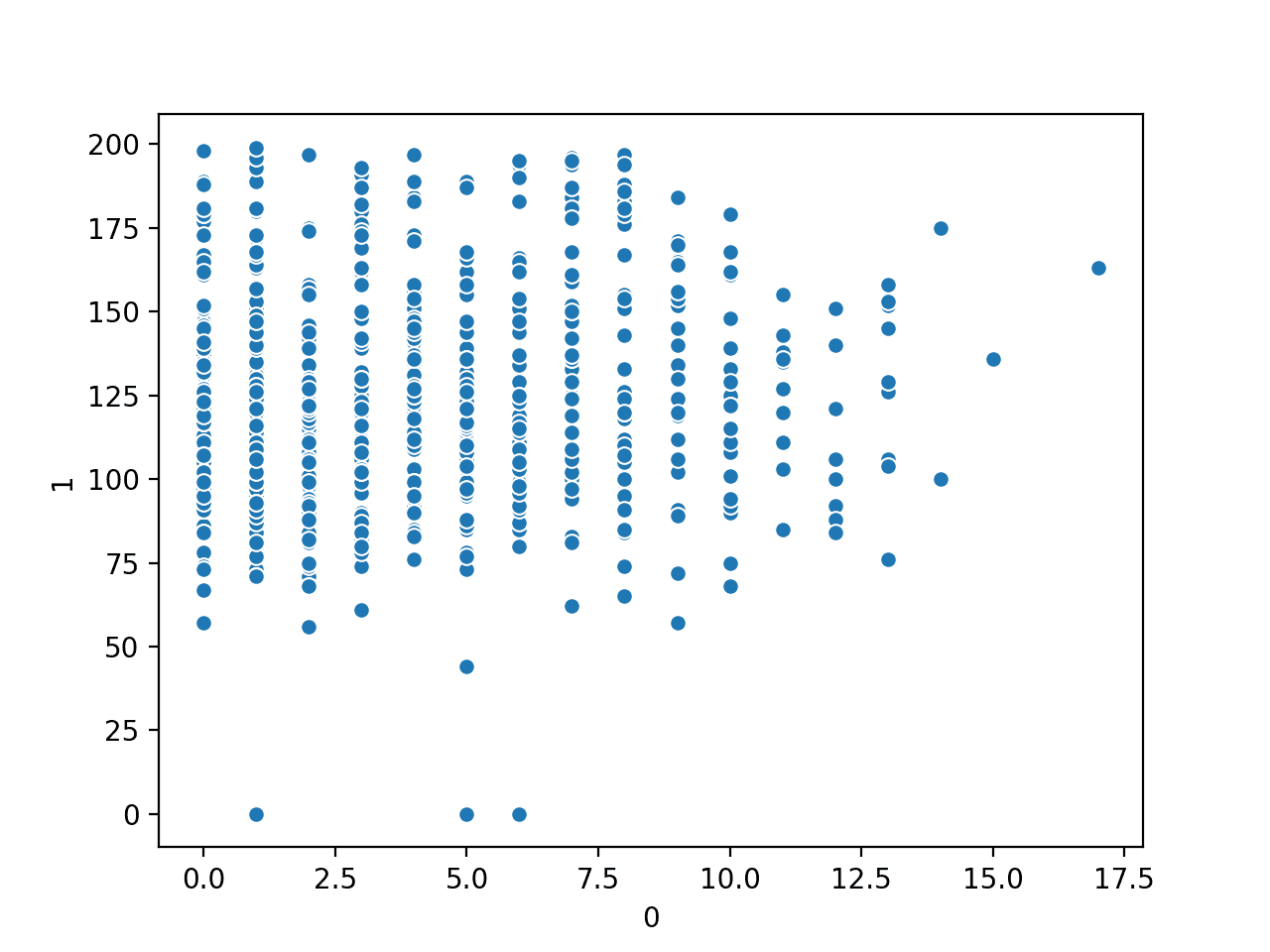
Scatter Plot of Number of Times Pregnant vs. Plasma Glucose Numerical Variables
We might also want to plot the relationship for the pair of numerical variables against the class label.
This can be achieved using the scatterplot() function and specifying the class variable (column index 8) via the “hue” argument, as follows:
|
1 2 3 |
... # create scatter plot scatterplot(x=0, y=1, hue=8, data=dataset) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# scatter plot of two numerical variables vs class label from pandas import read_csv from seaborn import scatterplot from matplotlib import pyplot # load the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # create scatter plot scatterplot(x=0, y=1, hue=8, data=dataset) # show plot pyplot.show() |
Running the example first loads the diabetes dataset and creates a scatter plot of the first two variables vs. class label.
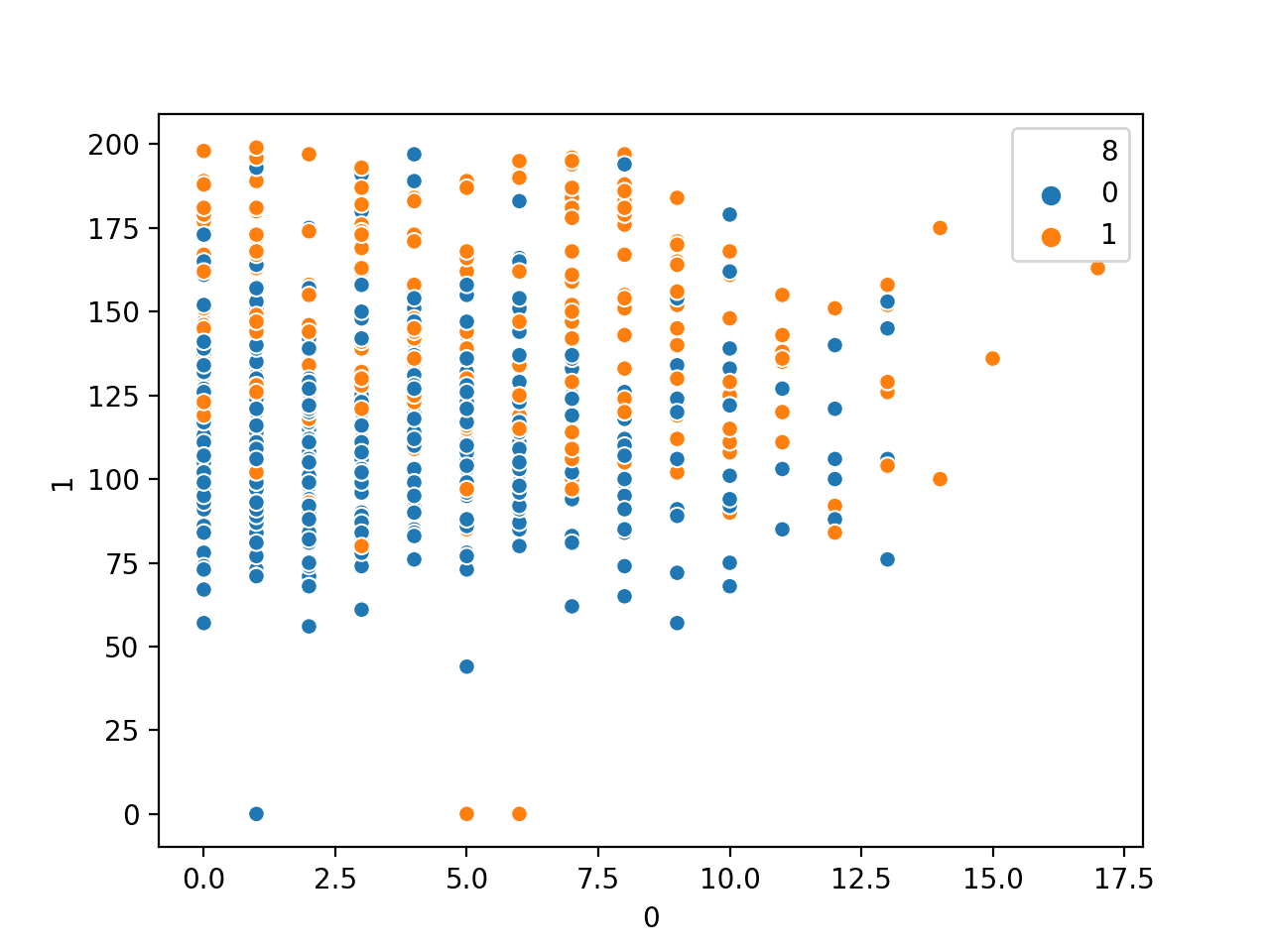
Scatter Plot of Number of Times Pregnant vs. Plasma Glucose Numerical Variables by Class Label
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
APIs
Summary
In this tutorial, you discovered a gentle introduction to Seaborn data visualization for machine learning.
Specifically, you learned:
- How to summarize the distribution of variables using bar charts, histograms, and box and whisker plots.
- How to summarize relationships using line plots and scatter plots.
- How to compare the distribution and relationships of variables for different class values on the same plot.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Discover Fast Machine Learning in Python!

Develop Your Own Models in Minutes
...with just a few lines of scikit-learn code
Learn how in my new Ebook:
Machine Learning Mastery With Python
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, modeling, tuning, and much more...
Finally Bring Machine Learning To
Your Own Projects
Skip the Academics. Just Results.

")




Valuable information and code about data visualization in Machine learning
Thanks!
Hi, Jason,
First of all, this comment isn’t about this letter. I have enjoyed your texts so much and I have almost finished three of them. I am currently reading and studying “Deep Learning for Natural Language in Python.” I love your explanations and I love the fact that your algorithms always work. I received my M.Sc. in Analytics last year, and your texts are the reason I was so successful in completing my degree. Since graduating, I have continued to read your texts as a way of staying sharp. Thank you.
I am a PhD in math, and an M.Sc.in analytics professor, at Clark Atlanta University here in Atlanta, Georgia, USA. I have been a math professor for many years. However, I will not have completed my M.Sc in Analytics degree without your books. Which brings me to my point. My department chair asked me to teach linear algebra this fall. I love linear algebra, but it has been years since I last taught the course. I suggested I teach linear algebra for machine learning; and, my department chair is excited about the idea. Hence, I will be using your book, entitled “Basics of Linear Algebra for Machine Learning…” to 15 to 20 of our math majors for the first time. of course, I will have to supplement the text with concepts of transformations and diagonalization, but the course should go well. (And yes, I do have Jim Hefferon’s text as well.)
My question: what is the best way to order your texts via our book store? Our students have something equivalent to book vouchers. so, if there is a way to order your texts through our book store, our students will be able to access them more conveniently. Looking forward to your answer.
Charles Pierre
Thanks! Well done on your degree!
Great question Charles. I often either offer a discount code to all students in the class or the university purchases a multi-seat license and shares the books with the students. I do both all of the time.
Contact me and let me know the approach you prefer and we can set it up:
https://machinelearningmastery.com/contact/
Dear Dr Jason,
Thank you for the tutorial on seaborn promised a few weeks ago.
Two points
(1) I wish to report an error when plotting your scatterplot of X[0] vs X[1] by class label y.
Whether I ran the example through the DOS console or the IDE IDLE, I still got the following error:
Versions:
(2) Since seaborn is used in conjunction with pyplot, one can add for example, xlabel, ylabel and title.
Summary:
(1) there appears to be a problem in plotting a scatterplot by class label
(2) since seaborn works with pyplot, we can add labels using pyplot.
Thank you,
Anthony of Sydney
Are you saying the example of the scatter plot by class label in the tutorial didn’t work for you?
Did you use the same dataset in the tutorial?
Dear Dr Jason,
To answer the question of did I “…use the same dataset in the tutorial?…”
Yes.
Method of storage of the code:
* Went to the exercise on this page.
* Above the lines, there is a facility on your code example that lets you copy the text.
* There is an instruction to press ctrl+C to copy.
* Pressed ctrl+C
* In a text editor Notepad++ not the MS Notepad, pressed ctrl+V
* save as test.py
Whether I ran within the DOS command line test.py
Result: got those errors pasted in the above text.
Recall the following:
Again, the error is produced when the attempting to display the graphic.
Again, no other error on other exercises on this page.
Maybe it’s a bug in seaborn? Perhaps need to resort to matplotlib only.
Thank you
Anthony of Sydney
I cannot explain the fault you are seeing, sorry.
I can confirm your library versions look correct.
Perhaps seaborn requires additional configuration on windows – I don’t have access to a windows machine.
Dear Dr Jason,
Thank you for your kind reply.
While the seaborn implementation of scatterplot not working is not an ‘earth-shattering’ outcome, I still achieved the same “the old fashioned way”.
Conclusion: ‘old-fashioned’ plot achieved the same outcome as ‘buggy’ seaborn with a few lines extra.
Thank you,
Anthony of Sydney
Nice workaround!
Dear Dr Jason,
Recall from above replies of the errors produced by
I have been experimenting again with seaborn, and another get around is instead of a scatterplot, to use a pointplot with a join=False
I tried with different datasets, and have been getting mixed results, mostly errors.
After searching, there is a reported reason that seaborn’s scatterplot has a bug for matplotlib 3.3,1, reference https://github.com/mwaskom/seaborn/issues/2194
As at 21-08-2020 there is a bug with seaborn’s scatterplot not working properly with matplotlib.
Thank you,
Anthony of Sydney
Thanks for sharing.
Dear Dr Jason,
To add to the methods of displaying of the pima indians diabetes in this tutorial, here is an example of a pairwise scatterplot of the ‘pima-indians-diabetes.csv’ data that I want to share.
The above is all pairwise combinations of numerical data, classed by diabetic status of pima indians diabetes data.
We only show all pairwise relations between features, X without any duplication – that is if we pair a and b, we don’t pair b and a.
In addition we don’t have anything in the diagonals such as kde.
Thank you,
Anthony of Sydney
Dear Dr Jason,
Forgot to mention
Apologies,
Anthony of Sydney
Nice work.
Dear Dr Jason,
There is another open-source graphics package called plotly, https://plotly.com/python/is-plotly-free/ which has an MIT licence.
It requires one to install the packages:
Here is a scatter plot with lower corner and no diagonals like the pima indians diabetes.
When fig.show() is invoked, the graphic is displayed on a default internet browser window with an ip address of 127.0.0.1
You will see a scatter matrix in the same way as seaborn and matplotlib’s scatter matrix.
This is a scatter matrix with no diagonal such as kde and lower corner only.
Thank you,
Anthony of Sydney
Thanks for sharing.
Does one has to learn Matplotlib and Seaborn for machine learning? I was looking at the google machine learning crash course and they haven’t touched on Matplotlib and Seaborn.
https://developers.google.com/machine-learning/crash-course/prereqs-and-prework
It’s very helpful for looking at your data.