Principal component analysis (PCA) is an unsupervised machine learning technique. Perhaps the most popular use of principal component analysis is dimensionality reduction. Besides using PCA as a data preparation technique, we can also use it to help visualize data. A picture is worth a thousand words. With the data visualized, it is easier for us to get some insights and decide on the next step in our machine learning models.
In this tutorial, you will discover how to visualize data using PCA, as well as using visualization to help determining the parameter for dimensionality reduction.
After completing this tutorial, you will know:
How to use visualize a high dimensional data
What is explained variance in PCA
Visually observe the explained variance from the result of PCA of high dimensional data
Let’s get started.
Principal Component Analysis for Visualization Photo by Levan Gokadze, some rights reserved.
Tutorial Overview
This tutorial is divided into two parts; they are:
Scatter plot of high dimensional data
Visualizing the explained variance
Prerequisites
For this tutorial, we assume that you are already familiar with:
Visualization is a crucial step to get insights from data. We can learn from the visualization that whether a pattern can be observed and hence estimate which machine learning model is suitable.
It is easy to depict things in two dimension. Normally a scatter plot with x- and y-axis are in two dimensional. Depicting things in three dimensional is a bit challenging but not impossible. In matplotlib, for example, can plot in 3D. The only problem is on paper or on screen, we can only look at a 3D plot at one viewport or projection at a time. In matplotlib, this is controlled by the degree of elevation and azimuth. Depicting things in four or five dimensions is impossible because we live in a three-dimensional world and have no idea of how things in such a high dimension would look like.
This is where a dimensionality reduction technique such as PCA comes into play. We can reduce the dimension to two or three so we can visualize it. Let’s start with an example.
We start with the wine dataset, which is a classification dataset with 13 features (i.e., the dataset is 13 dimensional) and 3 classes. There are 178 samples:
1
2
3
4
5
from sklearn.datasets import load_wine
winedata=load_wine()
X,y=winedata['data'],winedata['target']
print(X.shape)
print(y.shape)
1
2
(178, 13)
(178,)
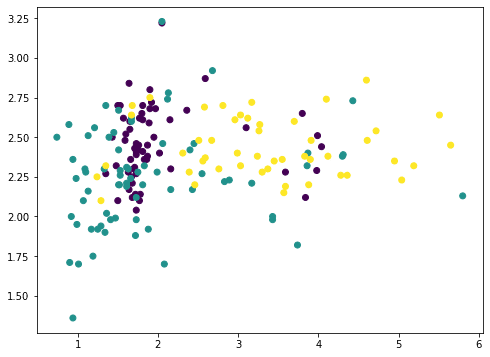
Among the 13 features, we can pick any two and plot with matplotlib (we color-coded the different classes using the c argument):
1
2
3
4
...
import matplotlib.pyplot asplt
plt.scatter(X[:,1],X[:,2],c=y)
plt.show()
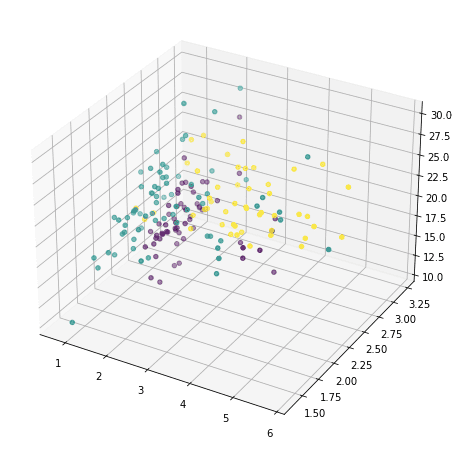
or we can also pick any three and show in 3D:
1
2
3
4
...
ax=fig.add_subplot(projection='3d')
ax.scatter(X[:,1],X[:,2],X[:,3],c=y)
plt.show()
But this doesn’t reveal much of how the data looks like, because majority of the features are not shown. We now resort to principal component analysis:
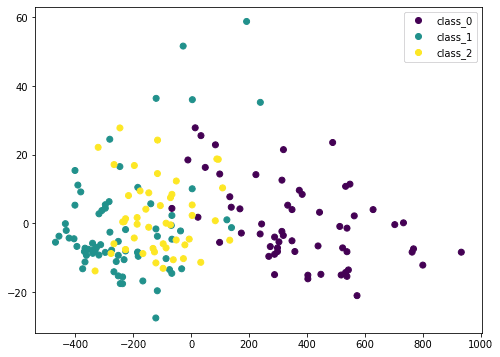
Here we transform the input data X by PCA into Xt. We consider only the first two columns, which contain the most information, and plot it in two dimensional. We can see that the purple class is quite distinctive, but there is still some overlap. If we scale the data before PCA, the result would be different:
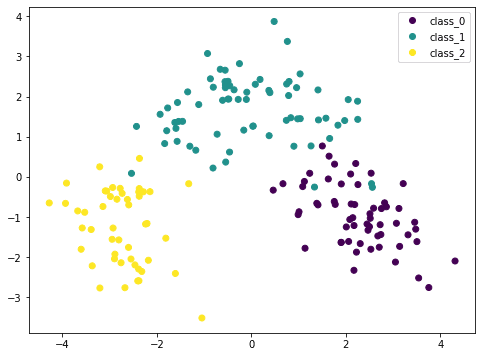
Because PCA is sensitive to the scale, if we normalized each feature by StandardScaler we can see a better result. Here the different classes are more distinctive. By looking at this plot, we are confident that a simple model such as SVM can classify this dataset in high accuracy.
Putting these together, the following is the complete code to generate the visualizations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import matplotlib.pyplot asplt
# Load dataset
winedata=load_wine()
X,y=winedata['data'],winedata['target']
print("X shape:",X.shape)
print("y shape:",y.shape)
# Show any two features
plt.figure(figsize=(8,6))
plt.scatter(X[:,1],X[:,2],c=y)
plt.xlabel(winedata["feature_names"][1])
plt.ylabel(winedata["feature_names"][2])
plt.title("Two particular features of the wine dataset")
plt.show()
# Show any three features
fig=plt.figure(figsize=(10,8))
ax=fig.add_subplot(projection='3d')
ax.scatter(X[:,1],X[:,2],X[:,3],c=y)
ax.set_xlabel(winedata["feature_names"][1])
ax.set_ylabel(winedata["feature_names"][2])
ax.set_zlabel(winedata["feature_names"][3])
ax.set_title("Three particular features of the wine dataset")
plt.show()
# Show first two principal components without scaler
plt.title("First two principal components after scaling")
plt.show()
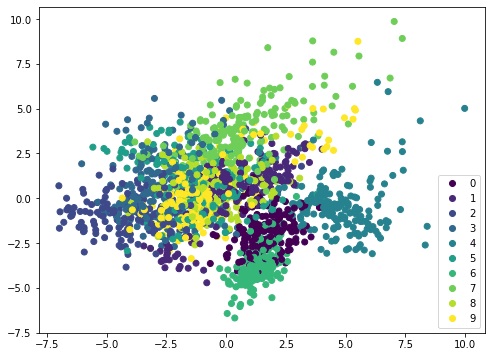
If we apply the same method on a different dataset, such as MINST handwritten digits, the scatterplot is not showing distinctive boundary and therefore it needs a more complicated model such as neural network to classify:
PCA in essence is to rearrange the features by their linear combinations. Hence it is called a feature extraction technique. One characteristic of PCA is that the first principal component holds the most information about the dataset. The second principal component is more informative than the third, and so on.
To illustrate this idea, we can remove the principal components from the original dataset in steps and see how the dataset looks like. Let’s consider a dataset with fewer features, and show two features in a plot:
1
2
3
4
5
6
from sklearn.datasets import load_iris
irisdata=load_iris()
X,y=irisdata['data'],irisdata['target']
plt.figure(figsize=(8,6))
plt.scatter(X[:,0],X[:,1],c=y)
plt.show()
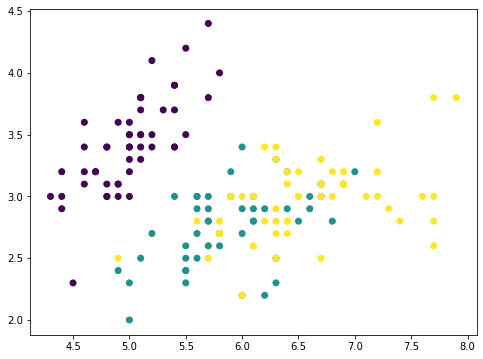
This is the iris dataset which has only four features. The features are in comparable scales and hence we can skip the scaler. With a 4-features data, the PCA can produce at most 4 principal components:
1
2
3
...
pca=PCA().fit(X)
print(pca.components_)
1
2
3
4
[[ 0.36138659 -0.08452251 0.85667061 0.3582892 ]
[ 0.65658877 0.73016143 -0.17337266 -0.07548102]
[-0.58202985 0.59791083 0.07623608 0.54583143]
[-0.31548719 0.3197231 0.47983899 -0.75365743]]
For example, the first row is the first principal axis on which the first principal component is created. For any data point $p$ with features $p=(a,b,c,d)$, since the principal axis is denoted by the vector $v=(0.36,-0.08,0.86,0.36)$, the first principal component of this data point has the value $0.36 \times a – 0.08 \times b + 0.86 \times c + 0.36\times d$ on the principal axis. Using vector dot product, this value can be denoted by
$$
p \cdot v
$$
Therefore, with the dataset $X$ as a 150 $\times$ 4 matrix (150 data points, each has 4 features), we can map each data point into to the value on this principal axis by matrix-vector multiplication:
$$
X \cdot v
$$
and the result is a vector of length 150. Now if we remove from each data point the corresponding value along the principal axis vector, that would be
$$
X – (X \cdot v) \cdot v^T
$$
where the transposed vector $v^T$ is a row and $X\cdot v$ is a column. The product $(X \cdot v) \cdot v^T$ follows matrix-matrix multiplication and the result is a $150\times 4$ matrix, same dimension as $X$.
If we plot the first two feature of $(X \cdot v) \cdot v^T$, it looks like this:
The numpy array Xmean is to shift the features of X to centered at zero. This is required for PCA. Then the array value is computed by matrix-vector multiplication.
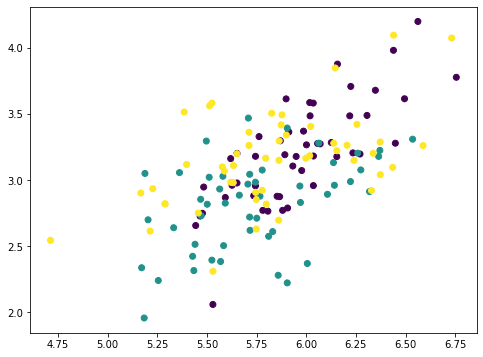
The array value is the magnitude of each data point mapped on the principal axis. So if we multiply this value to the principal axis vector we get back an array pc1. Removing this from the original dataset X, we get a new array Xremove. In the plot we observed that the points on the scatter plot crumbled together and the cluster of each class is less distinctive than before. This means we removed a lot of information by removing the first principal component. If we repeat the same process again, the points are further crumbled:
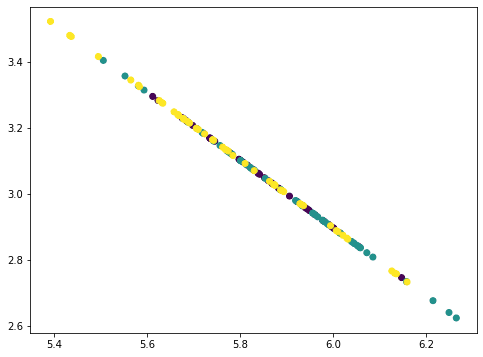
The points all fall on a straight line because we removed three principal components from the data where there are only four features. Hence our data matrix becomes rank 1. You can try repeat once more this process and the result would be all points collapse into a single point. The amount of information removed in each step as we removed the principal components can be found by the corresponding explained variance ratio from the PCA:
1
2
...
print(pca.explained_variance_ratio_)
1
[0.92461872 0.05306648 0.01710261 0.00521218]
Here we can see, the first component explained 92.5% variance and the second component explained 5.3% variance. If we removed the first two principal components, the remaining variance is only 2.2%, hence visually the plot after removing two components looks like a straight line. In fact, when we check with the plots above, not only we see the points are crumbled, but the range in the x- and y-axes are also smaller as we removed the components.
In terms of machine learning, we can consider using only one single feature for classification in this dataset, namely the first principal component. We should expect to achieve no less than 90% of the original accuracy as using the full set of features:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
...
from sklearn.model_selection import train_test_split
The other use of the explained variance is on compression. Given the explained variance of the first principal component is large, if we need to store the dataset, we can store only the the projected values on the first principal axis ($X\cdot v$), as well as the vector $v$ of the principal axis. Then we can approximately reproduce the original dataset by multiplying them:
$$
X \approx (X\cdot v) \cdot v^T
$$
In this way, we need storage for only one value per data point instead of four values for four features. The approximation is more accurate if we store the projected values on multiple principal axes and add up multiple principal components.
Putting these together, the following is the complete code to generate the visualizations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split


 from Scratch in Python")





Hi, I am getting this error while I’m trying to import my own dataset from this path rather than default dataset.
ImportError Traceback (most recent call last)
in
—-> 1 from sklearn.datasets import cleveland_data
2 winedata = cleveland_data()
3 X, y = winedata[‘data’], winedata[‘target’]
4 print(X.shape)
5 print(y.shape)
ImportError: cannot import name ‘cleveland_data’ from ‘sklearn.datasets’ (/opt/anaconda3/lib/python3.8/site-packages/sklearn/datasets/__init__.py)
That means you don’t have cleveland_data in scikit-learn. Indeed the latest documentation has no mention of such.
Thank you Adrian!