Vector space models are to consider the relationship between data that are represented by vectors. It is popular in information retrieval systems but also useful for other purposes. Generally, this allows us to compare the similarity of two vectors from a geometric perspective.
In this tutorial, we will see what is a vector space model and what it can do.
After completing this tutorial, you will know:
What is a vector space model and the properties of cosine similarity
How cosine similarity can help you compare two vectors
What is the difference between cosine similarity and L2 distance
Let’s get started.
A Gentle Introduction to Vector Space Models Photo by liamfletch, some rights reserved.
Tutorial overview
This tutorial is divided into 3 parts; they are:
Vector space and cosine formula
Using vector space model for similarity
Common use of vector space models and cosine distance
Vector space and cosine formula
A vector space is a mathematical term that defines some vector operations. In layman’s term, we can imagine it is a $n$-dimensional metric space where each point is represented by a $n$-dimensional vector. In this space, we can do any vector addition or scalar-vector multiplications.
It is useful to consider a vector space because it is useful to represent things as a vector. For example in machine learning, we usually have a data point with multiple features. Therefore, it is convenient for us to represent a data point as a vector.
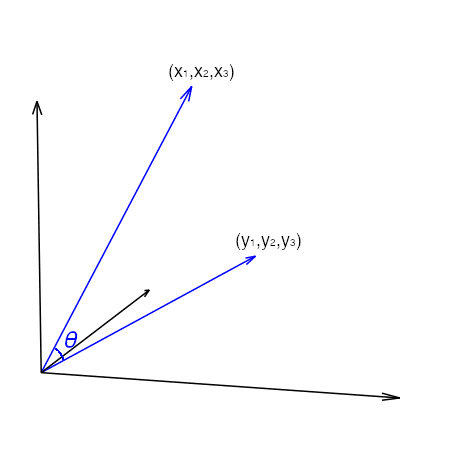
With a vector, we can compute its norm. The most common one is the L2-norm or the length of the vector. With two vectors in the same vector space, we can find their difference. Assume it is a 3-dimensional vector space, the two vectors are $(x_1, x_2, x_3)$ and $(y_1, y_2, y_3)$. Their difference is the vector $(y_1-x_1, y_2-x_2, y_3-x_3)$, and the L2-norm of the difference is the distance or more precisely the Euclidean distance between those two vectors:
$$
\sqrt{(y_1-x_1)^2+(y_2-x_2)^2+(y_3-x_3)^2}
$$
Besides distance, we can also consider the angle between two vectors. If we consider the vector $(x_1, x_2, x_3)$ as a line segment from the point $(0,0,0)$ to $(x_1,x_2,x_3)$ in the 3D coordinate system, then there is another line segment from $(0,0,0)$ to $(y_1,y_2, y_3)$. They make an angle at their intersection:
The angle between the two line segments can be found using the cosine formula:
where $a\cdot b$ is the vector dot-product and $\lVert a\rVert_2$ is the L2-norm of vector $a$. This formula arises from considering the dot-product as the projection of vector $a$ onto the direction as pointed by vector $b$. The nature of cosine tells that, as the angle $\theta$ increases from 0 to 90 degrees, cosine decreases from 1 to 0. Sometimes we would call $1-\cos\theta$ the cosine distance because it runs from 0 to 1 as the two vectors are moving further away from each other. This is an important property that we are going to exploit in the vector space model.
Using vector space model for similarity
Let’s look at an example of how the vector space model is useful.
World Bank collects various data about countries and regions in the world. While every country is different, we can try to compare countries under vector space model. For convenience, we will use the pandas_datareader module in Python to read data from World Bank. You may install pandas_datareader using pip or conda command:
1
pip install pandas_datareader
The data series collected by World Bank are named by an identifier. For example, “SP.URB.TOTL” is the total urban population of a country. Many of the series are yearly. When we download a series, we have to put in the start and end years. Usually the data are not updated on time. Hence it is best to look at the data a few years back rather than the most recent year to avoid missing data.
In below, we try to collect some economic data of every country in 2010:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from pandas_datareader import wb
import pandas aspd
pd.options.display.width=0
names=[
"NE.EXP.GNFS.CD",# Exports of goods and services (current US$)
"NE.IMP.GNFS.CD",# Imports of goods and services (current US$)
"NV.AGR.TOTL.CD",# Agriculture, forestry, and fishing, value added (current US$)
"NY.GDP.MKTP.CD",# GDP (current US$)
"NE.RSB.GNFS.CD",# External balance on goods and services (current US$)
In the above we obtained some economic metrics of each country in 2010. The function wb.download() will download the data from World Bank and return a pandas dataframe. Similarly wb.get_countries() will get the name of the countries and regions as identified by World Bank, which we will use this to filter out the non-countries aggregates such as “East Asia” and “World”. Pandas allows filtering rows by boolean indexing, which df["country"].isin(non_aggregates) gives a boolean vector of which row is in the list of non_aggregates and based on that, df[df["country"].isin(non_aggregates)] selects only those. For various reasons not all countries will have all data. Hence we use dropna() to remove those with missing data. In practice, we may want to apply some imputation techniques instead of merely removing them. But as an example, we proceed with the 174 remaining data points.
To better illustrate the idea rather than hiding the actual manipulation in pandas or numpy functions, we first extract the data for each country as a vector:
The Python dictionary we created has the name of each country as a key and the economic metrics as a numpy array. There are 5 metrics, hence each is a vector of 5 dimensions.
What this helps us is that, we can use the vector representation of each country to see how similar it is to another. Let’s try both the L2-norm of the difference (the Euclidean distance) and the cosine distance. We pick one country, such as Australia, and compare it to all other countries on the list based on the selected economic metrics.
In the for-loop above, we set vecA as the vector of the target country (i.e., Australia) and vecB as that of the other country. Then we compute the L2-norm of their difference as the Euclidean distance between the two vectors. We also compute the cosine similarity using the formula and minus it from 1 to get the cosine distance. With more than a hundred countries, we can see which one has the shortest Euclidean distance to Australia:
By sorting the result, we can see that Mexico is the closest to Australia under Euclidean distance. However, with cosine distance, it is Colombia the closest to Australia.
1
2
...
df_distance.sort_values(by="cos").head()
1
2
3
4
5
6
euclid cos
Australia 0.000000e+00 -2.220446e-16
Colombia 8.981118e+11 1.720644e-03
Cuba 1.126039e+12 2.483993e-03
Italy 1.088369e+12 2.677707e-03
Argentina 7.572323e+11 2.930187e-03
To understand why the two distances give different result, we can observe how the three countries’ metric compare to each other:
From this table, we see that the metrics of Australia and Mexico are very close to each other in magnitude. However, if you compare the ratio of each metric within the same country, it is Colombia that match Australia better. In fact from the cosine formula, we can see that
which means the cosine of the angle between the two vector is the dot-product of the corresponding vectors after they were normalized to length of 1. Hence cosine distance is virtually applying a scaler to the data before computing the distance.
Putting these altogether, the following is the complete code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
from pandas_datareader import wb
import numpy asnp
import pandas aspd
pd.options.display.width=0
# Download data from World Bank
names=[
"NE.EXP.GNFS.CD",# Exports of goods and services (current US$)
"NE.IMP.GNFS.CD",# Imports of goods and services (current US$)
"NV.AGR.TOTL.CD",# Agriculture, forestry, and fishing, value added (current US$)
"NY.GDP.MKTP.CD",# GDP (current US$)
"NE.RSB.GNFS.CD",# External balance on goods and services (current US$)
Common use of vector space models and cosine distance
Vector space models are common in information retrieval systems. We can present documents (e.g., a paragraph, a long passage, a book, or even a sentence) as vectors. This vector can be as simple as counting of the words that the document contains (i.e., a bag-of-word model) or a complicated embedding vector (e.g., Doc2Vec). Then a query to find the most relevant document can be answered by ranking all documents by the cosine distance. Cosine distance should be used because we do not want to favor longer or shorter documents, but to focus on what it contains. Hence we leverage the normalization comes with it to consider how relevant are the documents to the query rather than how many times the words on the query are mentioned in a document.
If we consider each word in a document as a feature and compute the cosine distance, it is the “hard” distance because we do not care about words with similar meanings (e.g. “document” and “passage” have similar meanings but not “distance”). Embedding vectors such as word2vec would allow us to consider the ontology. Computing the cosine distance with the meaning of words considered is the “soft cosine distance“. Libraries such as gensim provides a way to do this.
Another use case of the cosine distance and vector space model is in computer vision. Imagine the task of recognizing hand gesture, we can make certain parts of the hand (e.g. five fingers) the key points. Then with the (x,y) coordinates of the key points lay out as a vector, we can compare with our existing database to see which cosine distance is the closest and determine which hand gesture it is. We need cosine distance because everyone’s hand has a different size. We do not want that to affect our decision on what gesture it is showing.
As you may imagine, there are much more examples you can use this technique.
Further reading
This section provides more resources on the topic if you are looking to go deeper.
I ran part of the text you labeled “layman’s terms” through the Flesch-Kincaid Readability Test, and the score came back: 0. That’s expert level. Not for laymen.
Aim for a score of 70-80 for the average adult to find it readable. Even 50-60 would be difficult for undergraduates.
I like and applaud the intent, but the implementation needs work.
As a scientific technical writer, my aim was always to write at a level appropriate for my audience (dictated by whoever commissioned me), so every piece was assessed and adjusted accordingly. I strongly recommend rewriting this piece if you want to appeal to laymen.
I have some doubts about the nomenclature.. If we are learning with ML the vectors its called Vector Embedding, otherwise (doing it with more traditional approaches, more broad vectorization) we dont consider them as embeddings?








Thank you, very clear intro and nice examples.
I ran part of the text you labeled “layman’s terms” through the Flesch-Kincaid Readability Test, and the score came back: 0. That’s expert level. Not for laymen.
Aim for a score of 70-80 for the average adult to find it readable. Even 50-60 would be difficult for undergraduates.
I like and applaud the intent, but the implementation needs work.
As a scientific technical writer, my aim was always to write at a level appropriate for my audience (dictated by whoever commissioned me), so every piece was assessed and adjusted accordingly. I strongly recommend rewriting this piece if you want to appeal to laymen.
Just a thought.
Hello Jason!
I have some doubts about the nomenclature.. If we are learning with ML the vectors its called Vector Embedding, otherwise (doing it with more traditional approaches, more broad vectorization) we dont consider them as embeddings?
Thank you,
Imola
Hi Imola…The terminology can be confusing! The following resource may be of interest to you:
https://www.analyticsvidhya.com/blog/2021/06/part-5-step-by-step-guide-to-master-nlp-text-vectorization-approaches/
Thank you for this! I find this fascinating!
Hi Mani…You are very welcome! Thank you for your feedback!