By Rajan Mistry Sr. Applications Engineer with the Qualcomm Developer Network
Today, you can’t help but read the media headlines about AI and the growing sophistication of generative AI models like Stable Diffusion. A great example of a use case for generative AI on Windows is Microsoft 365 Copilot. This AI assistant can perform tasks such as analyzing your spreadsheets, generating content, and organizing your meetings.
And while such intelligence can feel like magic, its capabilities don’t happen magically. They’re built on a foundation of powerful ML models which have been rapidly evolving. The key enabler for these models is the rich model frameworks which allow ML developers to experiment and collaborate.
One of these emerging ML frameworks is ONNX Runtime (ONNX RT). The open-source framework’s underlying ONNX format enables ML developers to exchange models, while ONNX RT can execute them from a variety of languages (e.g., Python, C++, C#, etc.) and hardware platforms.
Our Qualcomm AI Stack now supports ONNX RT and allows for hardware-accelerated AI in Windows on Snapdragon apps. In case you haven’t heard, Windows on Snapdragon is the next generation Windows platform, built on years of evolution in mobile compute. Its key features include heterogeneous compute, up to all-day battery life, and the Qualcomm Hexagon NPU.
Let’s take a closer look at how you can use the Qualcomm AI Stack with ONNX RT for bare-metal, hardware-accelerated AI in your Windows on Snapdragon apps.
ONNX Runtime Support in the Qualcomm AI Stack
The Qualcomm AI Stack, shown in Figure 1 below, provides the tools and runtimes to take advantage of the NPU at the edge:
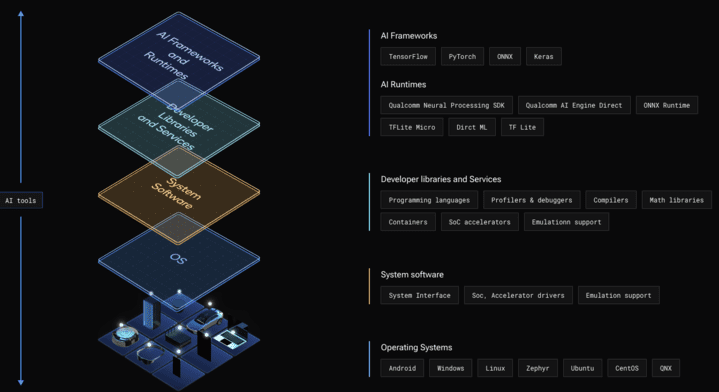
Figure 1 – The Qualcomm AI Stack provides hardware and software components for AI at the edge across all Snapdragon platforms.
At the highest level of the stack sits popular AI frameworks for generating models. These models can then be executed on various AI runtimes including ONNX RT. ONNX RT includes an Execution Provider that uses the Qualcomm AI Engine Direct SDK bare-metal inference on Snapdragon various cores including its Hexagon NPU. Figure 2 shows a more detailed view of the Qualcomm AI Stack components:
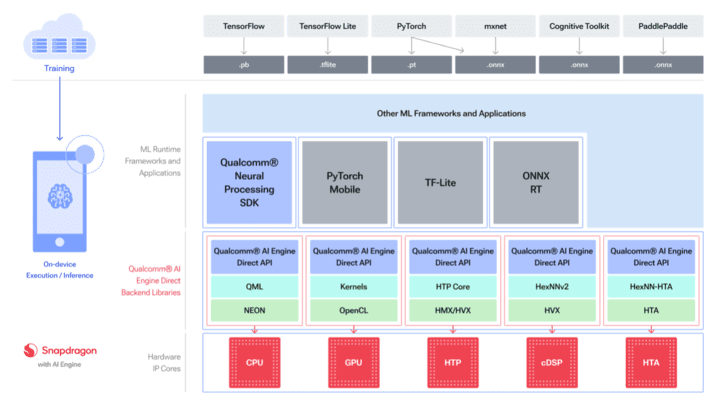
Figure 2 – Overview of the Qualcomm AI Stack including its runtime framework support and backend libraries.
Application-level Integration
At the application level, developers can compile their applications for ONNX runtime built with support for Qualcomm AI Engine Direct SDK. ONNX RT’s Execution Provider constructs a graph from an ONNX model for execution on a supported backend library.
Developers can use the ONNX runtime API’s that provides a consistent interface across all Execution Providers. It is also designed to support various programming languages like Python, C/C++/C#, Java, and Node.js.
We offer two options to generate context binaries. One way is to use the Qualcomm AI Engine Direct tool chain. Alternatively, developers can generate the binary using ONNX RT EP, which in turn uses the Qualcomm AI Engine Direct API’s. The context binary files help applications reduce the compile time for networks. These are created when the app runs for the first time. On subsequent runs, the model loads from the cached context binary file.
Getting Started
When you’re ready to get started, visit the Qualcomm AI Engine Direct SDK page where you can download the SDK and access the documentation.
Snapdragon and Qualcomm branded products are products of Qualcomm Technologies, Inc. and/or its subsidiaries.






No comments yet.