I’m a developer. I have read a book or some posts on machine learning. I have watched some of the Coursera machine learning course. I still don’t know how to get started…
Does this sound familiar?
Frustrated with machine learning books and courses? How do you get started in machine learning? Photo by Peter Alfred Hess, some rights reserved
The most common question I’m asked by developers on my newsletter is:
How do I get started in machine learning?
I honestly cannot remember how many times I have answered it.
In this post, I lay out all of my very best thinking on this topic.
You will discover why the traditional approach to teaching machine learning does not work for you.
You will discover how to flip the entire model on its head.
And you will discover my simple but very effective antidote that you can use to get started.
Let’s get into it…
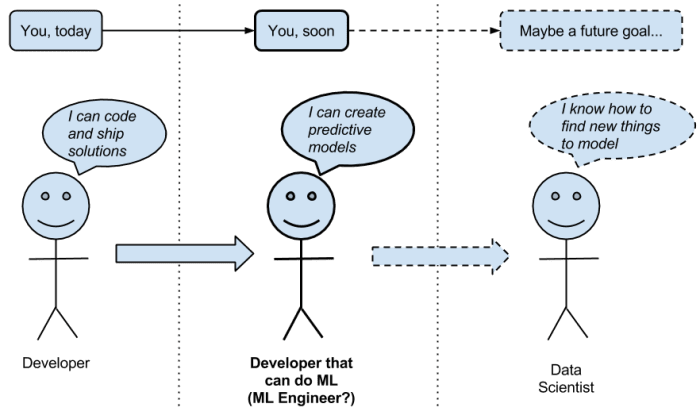
A Developer Interested in Machine Learning
You are a developer and you’re interested in getting into machine learning. And why not? It’s a hot topic at the moment, and it’s a fascinating and fast growing field.
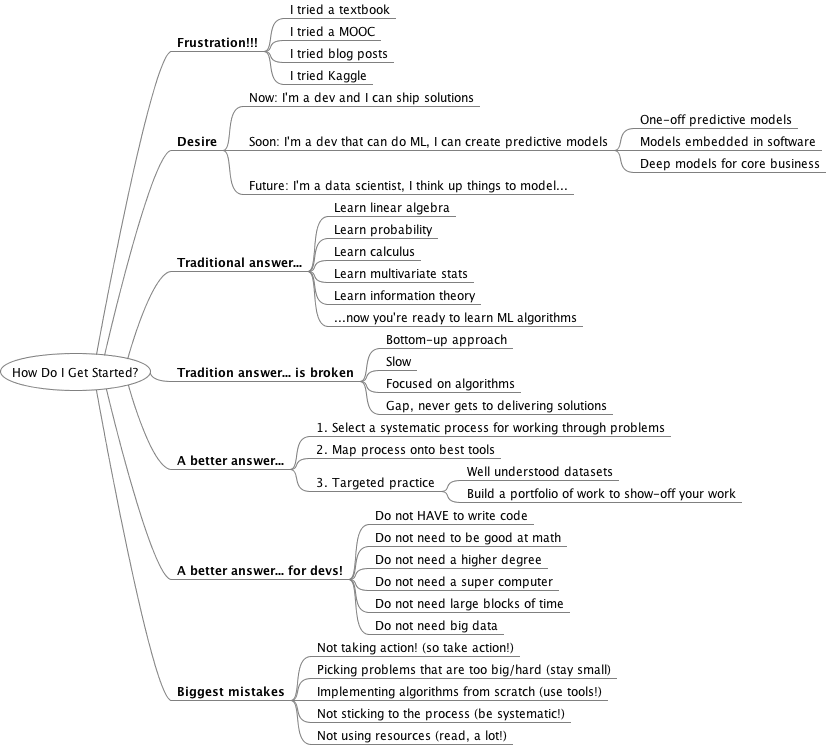
You read some blog posts. You tried to go deeper but the books are dreadful. Math focused. Theory focused. Algorithm focused.
Sound familiar? Have you tried books, MOOCs, blog posts and still not know how to get started in machine learning?
You try some video courses. You sign-up and make an honest attempt at the oft-cited Coursera Stanford Machine Learning MOOC. It’s not much better than the books and detailed blog posts. You can’t see what all the fuss is about, why it is recommended to beginners.
You may have even attempted some small data sets, perhaps an entry level Kaggle competition.
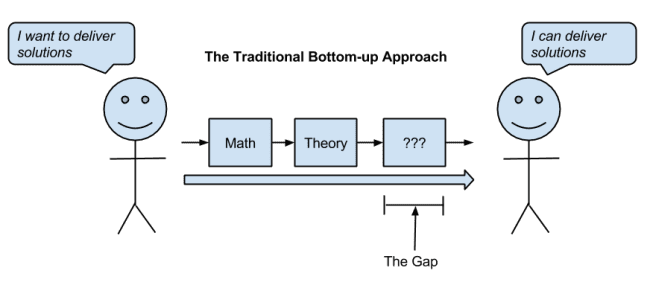
The problem is you can’t connect the theory, algorithms and math from the books and courses to the problem. There’s a huge gap. A gulf. How ARE you supposed to get started in machine learning?
Machine Learning Engineer
When you think forward into the future, once you have captured this elusive understanding of machine learning, what does your job look like? How are you using your newfound machine learning skills in your day-to-day?
I think I can see it. You’re a machine learning engineer. You’re a developer that knows how to “do” machine learning.
Do you want to transition from developer to a developer that can do machine learning?
Scenario 1: The one-off model
Your boss walks over and says:
Hey, you know machine learning, right? Can you use the customer data from last year to predict which current customers in our sales pipeline are likely to convert? I want to use it in a presentation to the board next week…
I call this the one-off model.
The problem is well defined by your boss. She gives you the data, which is small enough to look at and understand in MS Excel if you had to. She wants accurate and reliable predictions.
You can deliver. And more importantly, you can explain all the relevant caveats on the results.
Scenario 2: The embedded model
You and your team are collecting requirements from stakeholders on a software project. There is a requirement for the user to be able to freehand draw shapes in the software, and for the software to figure out which shape it is and turn it into a crisp unambiguous version and label it appropriately.
You quickly see that the best (and only viable?) way to solve this problem is to devise and train a predictive model and embed it in your software product.
I call this the embedded model. There are variations (such as whether the model is static or updated, and whether it is local or called remotely via an API), but that’s just detail.
What’s key in this scenario is that you have the experience to notice a problem that is best solved with a predictive model and the skills to devise, train and deploy it.
Scenario 3: The deep model
You have started a new job and the system you are working on is made up of at least one predictive model. Maintenance and the addition of features to this system require an understanding of the model, its inputs and its outputs. The accuracy of the model is a feature of the software product and part of your job will be to improve it.
For example, as a part of regular pre-release system testing, you must demonstrate that the accuracy of the model (when validated on historical data) has the same or better skill than the previous version.
I call this the deep model. You will be expected to build a deep understanding of one specific predictive model and use your experience and skill to improve and verify its accuracy as part of your routine duties.
The Developer That “Does” Machine Learning
These scenarios give you a glimpse at what it’s like to be a developer that knows how to do machine learning. They’re realistic because they are all variations on scenarios I’ve been in or tasks that I have had to complete.
All three of these scenarios make one thing very clear. Although machine learning is a fascinating area, to a developer machine learning algorithms are just another bag of tricks, like multi-threading or 3d graphics programming. Nevertheless, they are a powerful group of methods that are absolutely required for a specific class of problem.
Traditional Answer To: “how do I get started?“
So how do you get started in machine learning?
If you crack a book on machine learning seeking an answer to this question, you’ll get a shock. They start with definitions and move on to mathematical descriptions of concepts and algorithms of ever increasing complexity.
The traditional answer to the question “how do I get started in machine learning” is bottom-up.
Definitions and mathematical descriptions are clear, succinct and often unambiguous. The thing is, they are dry, boring and require the requisite mathematical background to parse and interpret.
There is a reason why machine learning is often taught as a graduate level subject at university. It’s because this “first principles” way of teaching the subject requires years of prerequisites to understand.
For example, it is advisable that you have a good footing in:
Statistics
Probability
Linear Algebra
Multivariate Statistics
Calculus
This gets worse if you stray slightly into some of the more exotic and interesting algorithms.
This bottom-up and algorithm fixated approach to machine learning is pervasive.
Online courses, MOOCs and YouTube videos mimic the university approach to teaching machine learning. Again, this is great if you have the background or you’ve already put in your half-to-full-decade of studies to earn those higher degrees. It does not help your average developer.
If you skulk off to a question and answer forum like Quora, StackExchange or Reddit and meekly ask how to get started, you’re slapped with the same response. Often this response comes from fellow developers who are just as lost. It’s one big echo chamber of the same bad advice.
It’s no wonder that honest and hard working developers seeking to do the right thing think they have to go back to school and get a Masters or Ph.D. before they feel qualified to “do” machine learning.
The Traditional Approach is DEAD WRONG!
Think about this bottom-up approach to teaching machine learning for a second. It’s rigorous and systematic and sounds like the right idea on the surface. How could it be wrong?
Bottom-Up Programming (or, how to kill off budding programmers)
Imagine you’re a young developer. You’ve picked up some of this and that language and you’re starting to learn how to create standalone software.
You tell friends and family that you want to get into a career where you get to program every day. They tell you that you need to do a degree in computer science before you can get a job as a programmer.
You sign-up and start a computer science degree. Semester after semester you are exposed to more and more esoteric algebra, calculus and discrete math. You use antiquated programming languages. Your passion for programming and building software wavers.
The traditional approach to getting started in machine learning has a gap on the path to practitioner.
Perhaps you somehow make it to the other side. Looking back, you realize you were not taught one thing about modern software development practices, languages, tooling, or anything that you can use in your pursuit of creating and delivering software.
See the parallels to the teaching of machine learning?
Thankfully, programming has been around long enough, is popular enough and is important enough to the economy that we have found other ways to give budding young (or old) programmers the skills they need to actually do the thing they want to do – e.g. create software.
It does not make sense to load up a budding programmer’s head with theory on computability or computational complexity, or even deep details of algorithms and data structures. Some of this useful material (the latter on algorithmic complexity and data structures) can come later. Perhaps with focused material – but importantly in the context of an engineer that is already programming and delivering software, not in isolation.
Thankfully we have focused software engineering degrees. We also have resources like codecademy where you learn to program by… yep, actually programming.
If a developer wants to “do” machine learning, should they really have to go and spend a bunch of years and tens or hundreds of thousands of dollars to get the requisite math and higher degrees?
The answer is of course not! There is a better way.
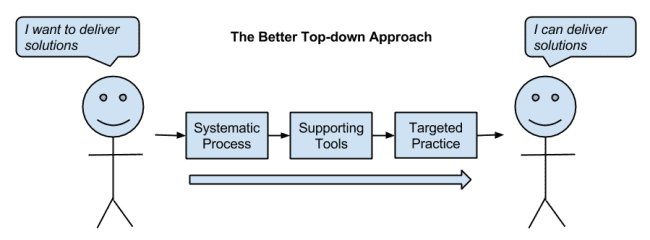
A Better Approach
As with computer science, you can’t just invert the model and teach the same material top-down.
The reason is, like a computer science course never making it to the subjects that cover the practical concerns of developing and delivering software, machine learning courses and books fall well short. They stop at algorithms.
You need a top-down approach to machine learning. An approach where you focus on the actual result you want: working real machine learning problems from end-to-end using modern and “best of breed” tools and platforms.
A better approach to learning machine learning that starts with working machine learning problems end-to-end.
Here’s what I think your yellow brick road looks like.
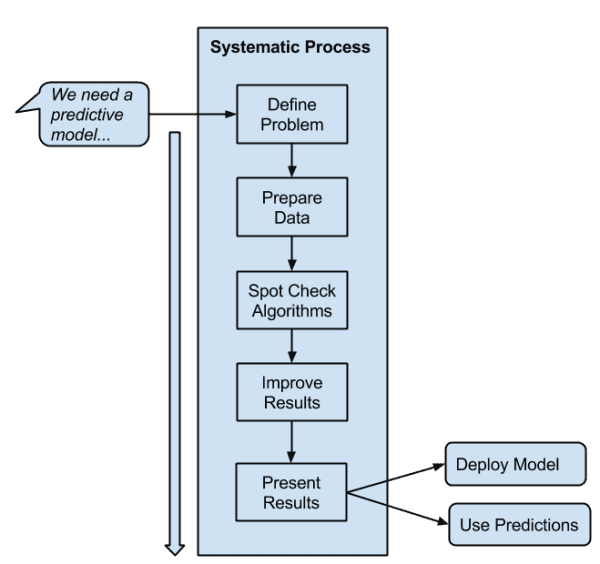
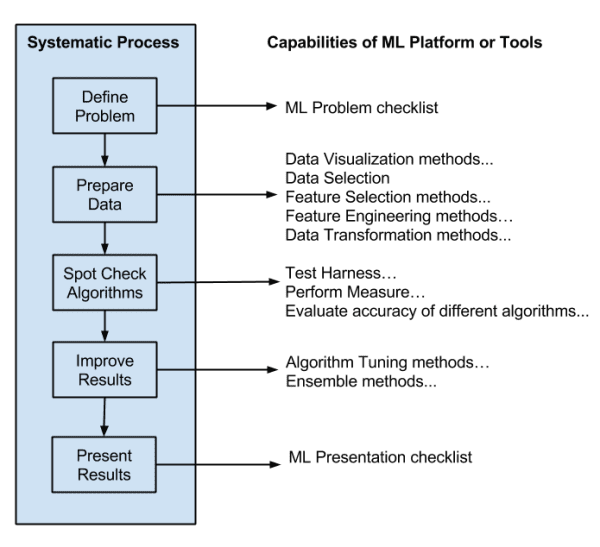
1. Repeatable Results with a Systematic Process
Once you know some tooling, it is relatively easy to blast a problem with a machine learning algorithm and call it “done“.
This could be dangerous.
How do you know you’re done? How do you know the results are any good? How do you know the results are reliable on the dataset?
You need to be systematic when working a machine learning problem. It’s a project, like a software project, and good processes can make achieving a high-quality result repeatable from project to project.
Contemplating such a process you can think of some clear requirements, such as:
A process that guides you from end-to-end, from problem specification to presentation or deployment of results. Like a software project, you can think you’re done, but you’re probably not. Having the end deliverable in mind from the beginning sets an unambiguous project stop condition and focuses effort.
A process that is step-by-step so that you always know what to do next. Not knowing what to do next is a project killer.
A process that guarantees “good” results, e.g. better than average or good enough for the needs of the project. It is very common for projects to need good results delivered reliably with known confidence levels, not necessarily the very best accuracy possible.
A process that is invariant to the specific tools, programming languages and algorithm fads. Tools come and go and the process must be adaptive. Given the algorithm obsession in the field, there are always new and powerful algorithms coming out of academia.
Select a systematic and repeatable process that you can use to deliver results consistently.
There are many great processes out there, including some older processes that you can adapt to your needs.
Pick or adapt a process that works best for you and meets the requirements above.
2. Mapping of “Best of Breed” Tools onto Your Process
Machine learning tools and libraries come and go, but at any single point in time you have to use something that best maps onto your chosen process of delivering results.
You don’t want to evaluate and select any old algorithm or library, you want the so-called “best of breed” that is going to give you fast, reliable and high-quality results and automate as much of your process that you can afford.
Again, you are going to have to make these selections yourself. If you ask anyone, you’re going to hear their biases, often the latest tool they’re using.
I have my own biases, and I like to use different tools and platforms for different types of work.
For example, in the scenarios listed above, I would advise the following best of breed tools:
One-off predictive model: The Weka platform, because I can load a CSV, design an experiment and get the best model in no time at all without a line of programming (see my mapping onto the process).
Embedded predictive model: Python with scikit-learn, because I can develop the model in the same language in which it is deployed. IPython is a great way to demonstrate your pipeline and results to the broader team. A MLaaS is also an option for bigger data.
Deep-dive model: R with the caret package, because I can quickly and automatically try a lot of state-of-the-art models and devise more and more elaborate feature selection, feature engineering and algorithm tuning experiments using the whole R platform.
In reality, these three tools bleed across the three scenarios depending on the specifics of a situation.
Map your preferred machine learning tools onto your chosen systematic process for working through problems.
Like development, you need to study your tools to get the most from them. You also need to keep your ear to the ground and jump to newer better tools if and when they are available, forever adapting them to your repeatable process.
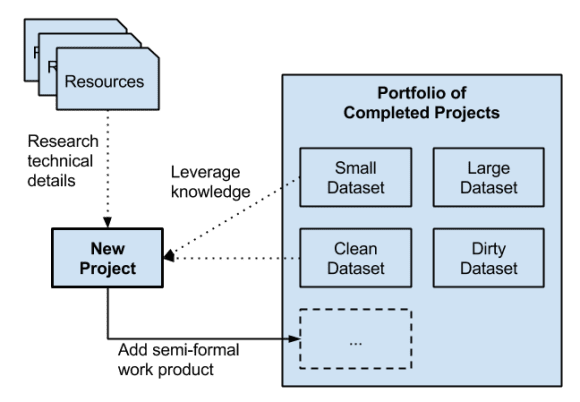
3. Targeted Practice with Semi-Formal Work Product
You get good at development by practicing – by developing lots of software. Use this familiar approach to get good at machine learning. The more of the process you practice in each project, the better (ideally, work problems end-to-end).
Carefully Select Your Practice Datasets
You want to pick datasets that are realistic rather than contrived. There are hundreds of free datasets out there of ever increasing complexity.
I would advise starting with small in-memory datasets from places like the UCI Machine Learning Repository. They are well known, relatively clean and a good place to start as you feel out your new process and tooling.
From there, I would recommend larger in-memory datasets, like those from some Kaggle and KDD cup competitions. They are little more dirty and require you to flex work on more and different skills.
Stick with tabular data, this is what I advise all of my students.
Working with image and text data are new and different fields in their own right (computer vision and natural language processing respectively) that require you to learn specialized methods and tooling to those fields. If these are types of problems you want or need to work then it might be best to start there, and there are great resources available.
Write-Up Your Results and Build A Public Portfolio of Work
Create and retain semi-formal outcomes (I refer to outcomes as “work product”) from each project. By this I mean, write up what you did and what you learned into some kind of standalone document so that you can refer back and leverage the results on future and following projects.
This is akin to keeping a directory for each programming project as a developer and reusing code and ideas from previous projects. It speeds up the journey a lot, and I strongly recommend it.
Keep any scripts, code and generated images, but it is also important to write up your findings. Think of it as akin to comments in your code. A standalone write-up could be a simple PPT or text file, or as elaborate as a presentation at a meet-up or video on YouTube.
Work through and complete discrete projects, write up results and build a portfolio of projects.
Save each project in a public version control repository (like GitHub) so that other beginners can learn from you and extend your work. Link to the projects from your blog, LinkedIn or wherever and use the public portfolio to demonstrate your growing skills and capabilities.
A portfolio of public GitHub repositories is fast becoming the resume in the hiring process at companies that actually care about skills and delivering results.
Yes, This Approach Is Tailored For Developers
What we have laid out above is an approach that you can use as a developer to learn, get started and make progress in machine learning.
It’s natural you may have some doubts about whether this approach is really suited to you. Let me address some of your concerns.
You do not need to write code
You may be a web developer or similar where you do not write a lot of code. You can use this approach to get started and apply machine learning. Tools like Weka make it easy to devise machine learning experiments and build models without any programming at all.
Writing code can unlock more and different tools and capabilities, but it is not required, and it does not need to come first.
You do not need to be good at mathematics
Just like development where you don’t need to know a thing about computability or Big O notation to write code and ship useful and reliable software, you can work through machine learning problems end-to-end without a background in statistics, probability and linear algebra.
It is important to note that we do not start with theory, but we do not ignore it. Dive in and pull out what you need on a method or algorithm, when you need it. In fact, you won’t be able to hold yourself back. The reason is, working machine learning problems is addictive and consuming. In the pursuit of getting better results and more accurate predictions, you will draw from any resources you can find, learning just enough to extract the nuggets of wisdom for you to apply on your problem.
If your goal is to master the theory, this approach is slower and less efficient. And this is why it so uncomfortable when seen through that lens. When viewed from the goal of being a developer that does machine learning, it makes a lot of sense.
You do not need a higher degree
There are no gatekeepers to this knowledge. It’s all available and you can study it yourself, today, now. You do not need to trade a lot of time and money for a degree before you can start working on machine learning problems.
If you heart is set on getting that higher degree, why not just start working on machine learning problems first and take a look at a degree in a few weeks or months after you have a small portfolio of completed projects built up. You will have a much clearer idea of the extent of the field and the parts you like.
I did go back and get those higher degrees. I love doing research, but I love working real problems and delivering results that clients actually care about a whole lot more. Also, I was working machine learning problems before I started the degree, I just didn’t realize I already had the resources and a path in front of me.
It’s one of the reasons I’m so passionate to convince developers like you that you have what you need to get started right now.
It is so very easy to come up with excuses to not get started in machine learning.
You do not need big data
Machine learning algorithms were developed and are best understood on small data. Data small enough for you to review in MS Excel, to load into memory and to work through on your desktop workstation.
Big data != machine learning. You can build predictive models using big data, but see this as a specialization of your skill set to a domain. I generally advise my students to start with small in memory datasets when starting in machine learning.
If big data machine learning is the area you want to work, then start there.
You do not need a desktop supercomputer
It is true that some of the state-of-the-art algorithms like deep learning require very powerful bazillion-core GPUs. They are powerful and exciting algorithms. They are also algorithms that work on smaller problems that you can compute with your desktop CPU.
You do not need to hold off getting started in machine learning until you have access to a big-fast computer.
Before you go off and buy a desktop supercomputer or rent very large EC2 instances, it might be worth spending some time learning how to get the most from these algorithms on smaller better-understood datasets.
You do not need a lot of time
We all have busy lives, but if you really want something you need to put in the time.
I’ve said it before, working machine learning problems is addictive. If you get caught up in machine learning competitions you will gladly sacrifice a month of evening television to squeeze a few more percent from your algorithm.
That being said, if you start small with a clear process and a best of breed tool, you can work a dataset from end-to-end in an hour or two, perhaps spread over one or two nights. A few of these and you have a beachhead on a portfolio of completed machine learning projects that you can begin to leverage on larger and more interesting problems.
Break it down into snack-size tasks on your Kanban board and make the time to get started.
Biggest Mistakes Developers Make and How To Avoid Them
I have been giving variations on this advice for close to two years now since I launched Machine Learning Mastery. Over that time I’ve seen five common pitfalls that I want you to avoid.
Not Taking Action: It’s all laid out and yet I see so many developers not take action. It is so much easier to watch TV or read news than to build a new and valuable skill in a fascinating field of study. You can lead a horse to water…
Picking Problems that are Too Big: I commonly see the first or second dataset a developer selects to work on being too difficult. It’s too large, too complex or too dirty and they’re not ready for the challenge. The awful thing is that the “failure” kills motivation and the developer flunks out of the process. Pick small problems that you can finish and write up in 60 minutes. Do that for a while before you take on something bigger.
Implementing Algorithms from Scratch: We have algorithm implementations. It’s done. At least done enough for you to do interesting things for the next few years. If your goal is to learn how to develop and deliver reliable and accurate predictive models, do not spend time implementing algorithms from scratch, use a library. On the other hand, if you want to focus on implementing algorithms, then clearly make this your objective and focus in on it.
Not Sticking to a Process: As with agile software development, if you deviate from the process, the wheels can come off your project pretty quickly and the result is often a big mess. Sticking to a process from start-to-finish that systematically works through a problem end-to-end is key. You can revisit “that interesting thing you found…” as a follow-up mini-project (an “ideas for follow-up work” section in your write-up), but finish the process and deliver.
Not Using Resources: There are many great papers, books and blog posts on machine learning. You can leverage these resources to improve your process, usage of tools and accuracy of your results. Use third party resources to get more from your algorithm and your dataset. Get ideas for algorithms and framings of the problem. A nugget of wisdom can change the course of your project. Remember, if you adopt a top-down process, the theory has to come in at the back-end. Take the time to understand your final models.
Don’t let any of these happen to you!
Your Next Step
We have covered a lot of ground and I hope I am starting to convince you that you can get started and make progress in machine learning. That a future in which you are a developer that can do machine learning is very real and very obtainable.
What advice would you give to someone who’d like to implement some basic/intermediate algorithm (from equation to code) in Matlab for example? Which algorithm should I start with, considering I have a fair background in maths, not so great in statistics and at the beginning of ML.
Start simple, say linear regression (using gradient descent), kNN, naive bayes or Perceptron are great “first” algorithms to implement. Pick one.
Survey multiple sources, including papers, books, other peoples code, blog posts tutorials and so on. Use them all to help you get across the line. The goal is a working not a pure implementation. Make it work, then make it beautiful/elegant.
Sir I m new in programming world …I just had put my 1step in python….and I want t learn M.l for good job in future..what aspects I should keep in my mind
Hello Jason, Thanks for such a wonderful and elaborative ML learning plan. I was bit confused before I found this article, the way you explained really suit me. Thanks.
This is amazing; as a self-taught computer geek, I find the mathy parts always the most complicated – I always struggled with math in school, and it wasn’t until I started programming / analysis that I realised I could do it. I have tried the Coursera course, spent a ton of money on ebooks from Amazon, and always get lost in the math (usually around Chapter 2). The way you’ve presented it here makes perfect sense and is very much aligned to the way I think, so thank you! I’ve signed up for the email based course and very excited to read more of your blog!!
Have a great day!
Thanks, I think your experience is more common that most people think.
There are many ways to learn and get good at a subject like programming or machine learning, and the “traditional” is not always the best, most efficient, most fun or suited to everyone.
I really like you are emphasizing that one should not be scared away by the mathematics that are behind the machine learning algorithms. Scientists and other programmers did indeed already cover many details for us so that ML algorithms can be used as a toolbox. I believe the manner you describe is a more natural to discover ML: get your data, try-out some out-of-the-box ML algorithms like SVM or Random Forests by trial-and-error and expand your knowledge in those algorithms. Maybe you will end up writing your own implementation but it is not the place to start.
Data preparation and feature engineering are a critical part of ML, if you get those right, the ML algorithms provided by WEKA, Scikit-learn and other packages will suffice. (See also the paper of Domingos (https://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf) for this).
I think it’s a tragedy that so many developers give up on machine learning because of the math. It’s such a fascinating and fun field and developers have such an important contribution to make in freeing powerful methods from academic papers and archaic sample code.
Thanks Jason for this great blog.
I wanted to know if Preference Learning also follows the same pattern as Machine Learning. Because I understand Preference Learning is an extension of ML where the data is adjusted according to the user preferences.
Hi Sriram, I must admit that I don’t think I’ve done any work in preference learning, but I expect the method laid out in this post for studying machine learning would be applicable.
Hi Sriram, actually this practice-focused methodology applies to any engineer and even any knowledge learning (including like natural science where you need to practice solving problems, science of law where you need to practice debating, and many other areas) where experience is very demanding and invaluable. The best way for learning and teaching these highly experience-dependent areas is something like ‘practice — learning — practice’, where students first come with some existing projects with problems and solutions (practice) to get familiar with traditional methods in the area and perhaps also with their methodology. After practicing with some elementary experiences, they can go into the books and study the underlying theory, which serves to guide their future advanced practice and will enhance their toolbox of solving practical problems. Studying theory also further improves their understanding on the elementary experiences, and will help them acquire advanced experiences more quickly. Unfortunately, to my knowledge and experience, traditional teaching in university by professors often totally omitted the first important and necessary practice part, leaving only ‘learning — practice’, making the learning progress like a castle in the air, abstracting knowledges, making them completely separated from practice, and confusing students. Even worse, faculties in universtiy despise people teaching practice, because they are equipped with advanced tools (mathematics and science) and they believe these practice is very simple (although they scarcely ever practice because they are bosses). This totally wrong and harmful approach misleads generations of students. The most efficient and best way is, as already mentioned, ‘practice — learning — practice’. To my knowledge, this approach was first proposed by Chairman Mao Zedong in 1975 (during the Cultural Revolution), in a instruction called ‘7-21 instruction’.
Hi, Jason, this is singlehandedly the best advice ever. I’ve toyed with the idea of getting started with machine learning for a long time but after reading this, I’m on it.
Thank you
I too belong to the same pool where I was frustrated and decided to leave Machine Learning. Some how I started exploring H2O and the interest was flown back into me.
I discussed this with one of my friends and he suggested me to go through your article on Machine Learning. I’m fortunate that I landed here and got the real treasure. 🙂
I’m a confident man now and ready to take the ML challenge step-by-step process. 🙂
Thanks a lot for helping many people like me. And last but not least, thanks to my friend for redirecting my ML vehicle here.
I started to take the Coursera Stanford Machine Learning MOOC but I had some problems when I tried to submit/up load my responses to the exercises of the course because maybe the nature my internet connection here in Cuba. This “failure” almost killed my motivation, but now I’ll take your approach to pursuit my goal to become a machine learning practitioner. Thanks a lot for your advice.
Thanks for the wonderful effort of making ML more beginner friendly. I am a beginner and I have benefited from your work.
Here’s my personal approach:
Switching between reading and practicing works best for me. For example If I find 2 hours for dedicating to ML on a given day, I enjoy it most when I read for an hour and practice (relevant or irrelevant material) for an hour (in any order).This makes me feel that I am having fun as well as making some solid progress on the fundamentals.
Of course, the mix does not have to be exact 50-50, but whatever suits to the current point of expertise/enthusiasm. Over a longer period of time, I believe it covers more or less same ground as any other approach.
I chose scikit-learn and WEKA as practicing platforms, and I am reading Bishop’s PRML alongside.
Thanks Jason,
This blog helped me a lot on how to start. But i wanted to be research student. My approach should be different because my priority should be algorithms rather than the solution most of the time. Can you suggest me any approach for that.
If you are a research student, my advice would be to commit to the academic approach as taught in university. Read the textbooks, take the courses and learn machine learning from the bottom-up.
I just found your site and started here. Excellent advice. I have spent the better part of two years learning as much as I could in statistics, linear algebra, calculus, programming, databases and machine learning, mostly through Coursera. I did take Andrew Ng’s course fairly early on and did well, but still felt that I was a long way from the point where I could develop my own applications. I also came away with the impression that I had to fully understand all of the algorithms, essentially by programming them myself! Since then, I have started other machine learning courses that do use libraries (Dato). Now, I can see that you don’t have to reinvent the wheel to make progress. In a way, I thought this was “cheating”, and it did hold me back.
Anyway, thank you for this site. I hope to work my way through all of it and follow the many resource links that you have put together.
Thanks for outlining this approach. It makes me feel a lot better about approaching machine learning. I knew that it was possible to understand and use machine learning without all of the complexity of the math and algorithms. Having you confirm it really drives the point home. I’m excited to have come across your web site!
Hi Jason,
First of all, I want to thank you for such an amazing post. As you said, it is very disheartening for young, fledgling developers when they are berated on stackoverflow and quora for not knowing what to do. They are given a curt and dry reply- “Go study Algorithms/Data Structure/Stats/Probability/etc.” Not because they are lazy to read but because they just don’t know where to start. This behavior just breaks their heart and rips any aspiration. So thanks, for being so kind to us novices.
Now, I have a good theoretical understanding of Machine Learning thanks to a class I took- classification, clustering, types of errors, bagging, boosting, etc. I have tried many of these methods using Weka and feel comfortable with it. Now, I want to take the next step- somehow apply my programming skills to solve problems. What do you recommend my next steps be? I ask this, because I am somewhat in the middle and don’t know which direction to proceed. This seems worse to me than not knowing ML at all because I would’ve atleast started with an open mind.
Thanks
Respected sir
Thank you for this amazing post. This made me very clear how to proceed, what to do and what not. I have a small doubt about programming language used in machine learning. Some articles suggested using python while some books are using R language. Please guide me which language I should choose.
Hope to hear from you soon.
Thank You
Thanks Jason, some of my deepest concerns in studying ML are cleared. Im glad I found your blog atleast now as I started thinking that I cannot teach ML myself, though I have lot of interest in the subject.
Hey Jason, I am new to machine learning, I just read your article and feeling motivated.
I want to do a machine learning project on handwritten digit recognition. I have no idea how should I start with it.
Can you give me a brief guideline on how should I start and what are the things I will be needing to learn. I have already found a data set on machine learning repository.
Excellent article. The problem is when you are really tired of MOOCs, Big fat Statistics Books and Kaggle , KDD you stumble here. Irony is you do not search for a similar blog when you start ML.
I have a 9-6 job and a non programmer. I am keen to learn ML for two reasons.
1. Exited to learn new technology
2. Use it in my day to day job as I work with lot of data ( I am in Project Management in a Semiconductor Company here in Bangalore , India).
Its been a year, I have tried, R, Python, Octave, MATLAB, Codeacademy, Spark you name it. I know some stuff now, but my thinking was clouded.
Thanks Jason. You are my ML Guru now. Coming from an Indian who really means it when he says the word “Guru”.
I haven’t coded in … many … years but always love data analysis and stats. With machine learning/data science being a hot area and my son learning Python, I’ve been looking for ways to learn and I’m lucky enough to stumble across your post here. What a relief to find that there’s a quicker way to play with ML without having to understand all the esoteric concepts and theories!
Hi Jason,
What a brilliant approach you suggested to novice like me!
I started with Coursera Stanford Machine Learning MOOC.I am in my first week of that course(I also watched YouTube Video of lectures on Machine Learning from Stanford)
and already find it daunting to understand all equations and algorithms. I took a refresher book on Linear Algebra( I took that before many years and now I am lost) but it is taking lot of time to go through. I received your email in mean time with links to this blog and found right approach to ML.
I will follow your advise and take hart to plunge in learning ML right way.
You saved me lot of pain and time.
Very useful article. I already tried watching Andrew Ng’s video lecture. Then I came to know that I don’t know much statistics and Probability, Linear Algebra, …… etc. Then I started with Statistical Learning Course from stanford. But half way only … I was really confused with all these approach but now I found good way! Thanks for the article.
Great Post… I have B.Tech Degree, MBA (2 Years ) , 1 year Business Analytics Certification from IIM Calcutta (premier Institute in INDIA ) & 6 years over all experience ( Coding/IT Sales/Data Analyst) so far…
But i have been struggling to get into core M/C learning or Data science stream because everywhere they ask for hands on experience (R/python/ etc)…. As a reason i have been frustrated a lot and trying to layout a plan for myself so that I can focus on one thing and get expertise of the same so that i can leverage my degrees as well.
Any more guidance would really help…thanks 🙂
really liked your post..
I don’t think I’m anywhere near ready to start Machine Learning, as I don’t even know a language just yet, and have never developed anything in my life. I’ve just started learning Python at nights, but since I don’t work within IT (yet), it is slow progress.
Just after some advice, seeing as you’ve got a PhD in AI (philosophy). My goal is to work with intelligent agents and help shape the future of AI; I’m interested in deep learning, reinforcement learning and some NLP.
Since I don’t have a strong Computer Science background, would you recommend that I look at going to university, or do you think there is a better way to learn from the foundation upwards?
Hi Jason! I read your article “Machine Learning for Programmers: Leap from developer to machine learning practitioner”(the one talks about the traditional bottom-up approaching system.) I am very very grateful someone just shoot out things that I am so confused about !!!! I am watching the Stanford MOOC, I pushed myself so hard(to the huge gap) that I realized I lost some motivation(which I think is the most important) about even computer science. Then I found you and the article online this morning. Not exaggerating, you are my career saver. After 2 entry level computer science courses(they motivated me so much about being CS major) in college, I just felt wrong along going further about school which is too far away from the real life problem solving. Friends around me they admire school so much, they are so comfortable with the school system as long as they got good GPAs. I could go pages, just don’t want waste your time to help others. All I want to say is thank you. Finally, I got a pro confirmed my confusion. Thank you so much!!!
I am a embedded software engineer with experience in writing device drivers/firmware/Linux etc etc
Due to limited opportunities in embedded domain, I would like to move to ML/Deep learning.
How tough will it be for me to move? I have 14 years of embedded sw development experience.
Jason, this has been very helpful. I was in the dilemma whether PhD first or experience first. And when I concluded relevant industry experience really counts towards profile building for PhD, I found this master piece. I am a developer with database, data warehousing BI with c# programming experience. Thank you so much for sharing your thoughts, looking forward to see more of your work here.
Thanks a tonne for such rare and wonderful article.
I am a research student and I have opted for machine learning domain for my research work.
Can you please help me through some of my doubts regarding interface between weka and matlab that can be used in research work for machine learning. I am using classification technique in ML but somehow confused how to proceed and with what out of the two.
Great article! I work in algorithm development and have an academic background in intelligent systems but not all the necessary math so i can see the same frustrations you describe. I think the general information overload in the “data science” area (as well as many others like software development) adds to the problem and sometimes make it seem unsurmountable. I like your focus on the “machine learning engineer” type role too, and the approach of starting practical and learning the deeper layers as projects are undertaken. Do you have any advice for trying to encourage “old school” algorithm developers to move to machine learning approaches? I find this an issue in my current role, that they do not understand or “trust” the algorithms and therefore stick with old non scalable ways of making models.
I know this post is intended for developers but would you suggest this same process for non-developers?
Before realising I wanted to work as a data scientist, I’ve been learning HTML, CSS & Javascript. However the more digit I did Ito data science the more I found out how often Python/R languages are used.
Would you suggest I learn a language like Python first before I start taking the approach you suggest?
Yes, this approach works just as well for designers and other non-developers.
I would suggest starting with Weka, that way you can learn and get good at applied machine learning without programming. It is much harder to learn 2 things at once – programming and machine learning.
This post fits me perfectly. Wish I had seen it earlier.
I set myself up for “failure” by picking a complex and dirty problem as my very first ML project and on top of that, it’s my thesis topic. Great combo, eh?
It would be interesting to hear from someone that has followed through with this advice and has made the transition from some type of software development position to a machine learning software engineer.
Thanks for the nice article. I see a ray of hope again after going through the blog.
I’m now around 45+ years, worked mostly in traditional software companies and now at management position which i dont feel i can do justice with and I’m interested in ML( mainly in R&D) i was very good as a student in maths and engineering too( always stood among top 3 in universities, though 25 years back ). I’m ready to take a break of 6 months to dive into this but do you suggest at this age should i take this risk? can i focus again and play with maths after so long? Need your advice, please help if i should even think of this stream?
Yes. My advice would be to be laser focused on how to deliver results, not the theory. Of course, you can study whatever you want, but the shortest line between you now and being effective is learning how to deliver results – working through predictive modeling problems end to end.
You can get a long way in a few weeks of working every day, let alone a few months!
I am a sophomore year student at IIT Guwahati, India. I am a UI/UX design student. This article is quite insightful as to how one can learn and apply ML. But it is more inclined towards developers switching to ML. I have recently developed interest in ML and although being a design student, I have completed courses in Linear Algebra and calculus in my freshman year. I’m a bit confused as to what would be my career prospectives if I choose to pursue ML with a Bachelor of Design degree.
OMG, Jason you are a pro. I’ve already made a planning on how to learn by myself an entire BS CS curriculum before appling to a Ms in Computer Science and finally do ML. What you have just told me here is “You can do whatever you want, but you don’t have to wait to start doing ML”. This is amazing, this totally makes sense to me….
I’ll follow your advice, and start working as soon as posible, and then make sense of it on my way to ML engineering.
Again, Thank you so much Jason, keep doing what you are doing, dudes like you have a prime role in making ML change the world.
Hello sir, i have just completed my B.E in IT branch. i have recently developed interest in ML, but i don’t know how to begin. I have tried everything blogs, youtube videos but they all start with intermediate level. I have good knowledge of Python and i love solving calculus problems. could you suggest me where to begin?
I am a developer trying to learn ML and you laid out such a beautiful path. You mapped it out amazingly. Thanks in advance… developer –> ML engineer… eventually data scientist.
I will scavenge your site until I bleed it dry of knowledge… keep it coming.
I have a question about data transformation and feature engineering:
If I have a dataset containing 2 columns, one of them is data in Chinese characters and the other is numerical values. In this case, how can I do the data transformation and feature engineering?
suppose the prediction problem is that we want to find the potential users of new service in a bank.
the characters represent the summary of users’ credit summary and the numbers represents users’ deposit in that bank.
So, how to do transform the characters into numerical values in order to do feature engineering ?
Maybe there are systematic things you can pull out.
Maybe turning all the text into numbers is the way (e.g. bag of words or word embedding methods). I would recommend testing lots of different approaches and see what works best for the problem.
Hey, Jason, you see I am currently pursuing my bachelors in computer science and I want to do Django web development first and then move on to machine learning so what path will fit me right?
Hey, I want to classify a word document contents using naive bayes algorithm in python. So, any one can give me some help or example so that i can implement the same in my problem.
Thank you to all in advance.
Thanks a ton Jason Brownlee . Before reading this blog I was almost certain to quit ML due to lack of mathematical core concepts. Although this blog is written so well based on some real life facts. This indeed is a great help for ppl like me trying to make transition to ML from software
For these many years , I was searching for a efficient source to learn Machine learning !Today I am lucky to visit this site ;
Very interesting articles ; Feeling Blessed () ;
Thankyou ! Sir
Thank you for the great article and site! Super cool that your doing this.
I’ve been a top down programmer for most of my career. I needed to accomplish as task, I then developed/found the skills/tools, techniques to accomplish that specific task. For a number of the projects I actually didn’t understand a lot of the underlying concepts or math until after it was implemented, sometimes even after a number of years… But I was able to use those tools and concepts to successfully deliver. Of course of over time I’ve developed a pretty broad skill set I still don’t have some of the basic knowledge a fully educated software engineer has.
So I commend your approach, it is the exact approach took in the past and am now taking with machine learning.
Now that found your site I plan on going through a lot of it. To start though I do have one task that I do need to accomplish with ML – Predict a timeseries. Then improve that prediction over time as more data is acquired.
Would you have any additional suggestions for me in this case?
Hi Jason
I gone through article. I still have confusion . I used Weka by not focusing on algorithm like linear regression and gradient descent . But at the end I found lost myself again asking the same question is really a software developer can become machine learning developer.
I did not able to make the decision whether to under weka dataset i had to learn basis algorithms.
Sorry this might be a dumb question but i found myself lost.
Hi Jason,
This is a good article and I would like to use some of my spare time to try the whole flow. Just want to ask this question:
I am a professional developer for some years with good coding skills(my Python skill is okay or average) and very poor math skills, I can spend about 3 hours (at most) per day to learn about ML every day, 5 days a week, how long do you think I can finish the all 12 books and be ready to work on real ML projects in reality?
I know this might sounds like a dumb question, but I really need your opinion before I can dive in this domain and seriously do something.
Some people start adding values in a few weeks, other take years. It come down to how much you focus on the process of working through problems systematically and delivering a usable result.
Damn, I wish I read this before I started. As a dev I have no idea had how to approach it. I feel like I’ve read quite a lot and progressed very little in comparison, feeling pretty stupid and very frustrated with trying to understand all the math and theory going on. I feel like this is the key info what I was missing, just knowing how to approach this whole thing in the situation from a developer’s point of view. I think this article is a game changer and big eyeopener for me. Thanks you very much for this!! This is a must read for every developer trying to get into ML.
Me too, I wish I found this before I started an year back. lost in learning mushrooming tools, especially Programming in python, instead of focusing on core ML. Thank god I found this.
I like your approach top-down (instead of bottom-up) method as immersive way to start delivering specific solutions in Machine Learning, through a big spectrum of particulars and full solutions, even if the pillars as developer (math -calculus, linear algebra, statistics-, programming language, API knowledge, etc) are not the best, because of our current university degree or study background lack .
I think it is easier start “mutating” small part of the final code provide by you in every post instead of starting from scratch (bottom-up) every time.
That reminds me a process as imitating biology; I can construct a new life entity starting from unicellular, combining into multicellulars, later on producing organs differentiations, etc. that is the “hard way” of standard university education or just simply change some “genes” or “mutating” in a similars animals to obtain some skillful new life differentiation just from the beginning out of the blue. Even if the new life cab be reproducible you can create new lifes in a sustainable way.
I estimate this the way you start and the final reason of your posts success.
In addition to that, and you do not mention, you can always going back and study deeper into the pillars of statics, algebra, calculus, etc to strengthen your basic knowledge …any time you are interested to know the roots of something you just have done, but do not know the fundamentals.
Hello,
Thanks for this post, it was very motivating, I have a question, what difference does a linear regression algorithm from the perspective of machine learning and a linear regression algorithm from the perspective of statistics? My question is oriented to, why is it called machine learning? What is the change, if I solve a problem with statistics or if I address them with ML? What is the difference? Thanks again for your help.
I have spent hours reading about getting started with ML. As a developer, this is really the best synopsis of what it is all about. Lots of people can be good at statistical analysis, but few can eloquently articulate what it takes to succeed here. Thanks for putting this together!
Great article. Thanks for nice contribution.
I am planning to start my research in finance using (ML,AI,DL techiniques) from scratch. but totally upset where to start. My background is master in computer science.
Sir!
Would you suggest me something in this regard .
Dear Jason
I really thank you and appreciate your help to beginners learn deep learning. I myself was disappointed after getting overwhelmed by too many resources on deep learning until I found your helpful website. As you mentioned, having PhD does not guarantee to understand scientific tips especially on deep learning.
I’m system engineer and a 10 years experienced software developer. I’m beginning in AI field, so this post is a good aproach. I took some AI courses, but it’s still difficult to me to realize when I can use AI to solve problems.
Thus, my question is, do you have any post with advices aimed to recognize opportunities to use AI?
Hi,
I wonder if you cover any of those Maths related things you talk about here, or if you could point me towards such resources. I would ike to understand all the basic Maths related stuff attached to ML.
I’m new to the world of stochastic matrix modelling and agent based modelling/individual based modelling, where there is a lot of uncertainty around the model parameters (educated guess work from experts in the applied domain!), around modelling methods, and of arising from the noise generated by the random sampling from the parameter windows and other stochasticity introduced within the model. I’m currently wading through the huge field of sensitivity analysis and have been looking at using regression/classification emulators applied to the relationship between a the parameter space and some model response (like, say binomial extinction). I’m guessing you have already published a lot on this topic, and your general ethos seems to be “traditional is not always best”.
If you have any time, it’d be great if you would please be able to point me to any of your blogs or books or web posts on this area.
I love your post, one thing I disagree with is “develop the algorithms from scratch”, I feel that learning how to develop from scratch makes you understand what each library is doing so when you use libraries, you have a more deep understanding of what to apply.
You are totally right Jason, starting from scratch can be overwhelming for beginners.
Anyways keep doing your blog posts, I love them, you are just awesome man 🙂
Thanks for great post !
I’m a web developer but I haven’t a high school diploma yet, this was stoping me to continue,
I tried to ask in some ml forum “where to start”, the answer was the same (linear algebra, probability,etc.).
This post is helpful to me cause I’m don’t have any intermediate math knowledge!
I appreciate your blog, thanks alot.
The top down approach to learning you described really resonates with me. As a developer who got started at a bootcamp, I can attest to the fact that its best to learn programming by building things that get you excited about the field. Of course its important to circle back later and fill out some of the theory you are missing, but even this is easier when you can conceptualize why it is important. As a person who went back to school to get a masters, I can also attest to the fact that school focuses much more on ground up theory. This is obviously a must if you want to be the person designing the next ML algorithms, but for a practitioner in a professional setting, I would agree its best to start doing and learn while you go.
The greatest advice I have ever read on starting code in Machine Learning. I found the reason why I am so bored with coding because of the pitfall of traditional learning system. I understand the limit is me myself and my mindset. Now I’m working on my mindset first and begin the learning process from ‘Top to Down’.
Change your thinking and change your life is real motto!






")




Hi, great practical article!
What advice would you give to someone who’d like to implement some basic/intermediate algorithm (from equation to code) in Matlab for example? Which algorithm should I start with, considering I have a fair background in maths, not so great in statistics and at the beginning of ML.
Thanks!
Great question.
Start simple, say linear regression (using gradient descent), kNN, naive bayes or Perceptron are great “first” algorithms to implement. Pick one.
Survey multiple sources, including papers, books, other peoples code, blog posts tutorials and so on. Use them all to help you get across the line. The goal is a working not a pure implementation. Make it work, then make it beautiful/elegant.
Some blog posts that might help:
* How to Implement a Machine Learning Algorithm
* How to Research a Machine Learning Algorithm
* Tutorial To Implement k-Nearest Neighbors in Python From Scratch
Sir I m new in programming world …I just had put my 1step in python….and I want t learn M.l for good job in future..what aspects I should keep in my mind
My best advice is here:
https://machinelearningmastery.com/start-here/#getstarted
Hello Jason, Thanks for such a wonderful and elaborative ML learning plan. I was bit confused before I found this article, the way you explained really suit me. Thanks.
Thanks, I’m glad to hear it helped.
This is amazing; as a self-taught computer geek, I find the mathy parts always the most complicated – I always struggled with math in school, and it wasn’t until I started programming / analysis that I realised I could do it. I have tried the Coursera course, spent a ton of money on ebooks from Amazon, and always get lost in the math (usually around Chapter 2). The way you’ve presented it here makes perfect sense and is very much aligned to the way I think, so thank you! I’ve signed up for the email based course and very excited to read more of your blog!!
Have a great day!
Thanks, I think your experience is more common that most people think.
There are many ways to learn and get good at a subject like programming or machine learning, and the “traditional” is not always the best, most efficient, most fun or suited to everyone.
Hi Daras would like to connect to u @parth_iconoclas
Thanks for the insight. This exactly how I’ve felt while trying to learn ML.Much appreciated.
Thanks, you’re very welcome.
Keep up the good work man. 🙂
I will Alex, thanks.
I really like you are emphasizing that one should not be scared away by the mathematics that are behind the machine learning algorithms. Scientists and other programmers did indeed already cover many details for us so that ML algorithms can be used as a toolbox. I believe the manner you describe is a more natural to discover ML: get your data, try-out some out-of-the-box ML algorithms like SVM or Random Forests by trial-and-error and expand your knowledge in those algorithms. Maybe you will end up writing your own implementation but it is not the place to start.
Data preparation and feature engineering are a critical part of ML, if you get those right, the ML algorithms provided by WEKA, Scikit-learn and other packages will suffice. (See also the paper of Domingos (https://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf) for this).
Thanks Andreas.
I think it’s a tragedy that so many developers give up on machine learning because of the math. It’s such a fascinating and fun field and developers have such an important contribution to make in freeing powerful methods from academic papers and archaic sample code.
That’s a great paper. It’s on my list of the best resources to get started in machine learning
For those interested in more on those important topics, see:
* How to Prepare Data For Machine Learning
* Discover Feature Engineering, How to Engineer Features and How to Get Good at It
* An Introduction to Feature Selection
Thanks Jason for this great blog.
I wanted to know if Preference Learning also follows the same pattern as Machine Learning. Because I understand Preference Learning is an extension of ML where the data is adjusted according to the user preferences.
Hi Sriram, I must admit that I don’t think I’ve done any work in preference learning, but I expect the method laid out in this post for studying machine learning would be applicable.
Check back in and let me know how you go.
Hi Sriram, actually this practice-focused methodology applies to any engineer and even any knowledge learning (including like natural science where you need to practice solving problems, science of law where you need to practice debating, and many other areas) where experience is very demanding and invaluable. The best way for learning and teaching these highly experience-dependent areas is something like ‘practice — learning — practice’, where students first come with some existing projects with problems and solutions (practice) to get familiar with traditional methods in the area and perhaps also with their methodology. After practicing with some elementary experiences, they can go into the books and study the underlying theory, which serves to guide their future advanced practice and will enhance their toolbox of solving practical problems. Studying theory also further improves their understanding on the elementary experiences, and will help them acquire advanced experiences more quickly. Unfortunately, to my knowledge and experience, traditional teaching in university by professors often totally omitted the first important and necessary practice part, leaving only ‘learning — practice’, making the learning progress like a castle in the air, abstracting knowledges, making them completely separated from practice, and confusing students. Even worse, faculties in universtiy despise people teaching practice, because they are equipped with advanced tools (mathematics and science) and they believe these practice is very simple (although they scarcely ever practice because they are bosses). This totally wrong and harmful approach misleads generations of students. The most efficient and best way is, as already mentioned, ‘practice — learning — practice’. To my knowledge, this approach was first proposed by Chairman Mao Zedong in 1975 (during the Cultural Revolution), in a instruction called ‘7-21 instruction’.
Thanks jason for a nice post
You’re welcome Aman.
Hi,
Dr Jason it is really enlightening one. I think I better get started to use them for my work in hydrology.
Keep up.
Thanks Surajit.
Hi, Jason, this is singlehandedly the best advice ever. I’ve toyed with the idea of getting started with machine learning for a long time but after reading this, I’m on it.
Thank you
Excellent. Start slow and steady and email me if you have any questions. I’m eager to hear how you go.
Nice post, as always! Glad to see your blog is active again. Really appreciate your insights.
Thanks Brian!
Beautiful! Thanks for really bringing it, in this one, Jason!
You’re welcome Jonny, thanks for the kind words!
Hi Jason,
Would it be possible to open a *.data file instead of a *.arff in WEKA?
Kind Regards,
Cornelius
I too belong to the same pool where I was frustrated and decided to leave Machine Learning. Some how I started exploring H2O and the interest was flown back into me.
I discussed this with one of my friends and he suggested me to go through your article on Machine Learning. I’m fortunate that I landed here and got the real treasure. 🙂
I’m a confident man now and ready to take the ML challenge step-by-step process. 🙂
Thanks a lot for helping many people like me. And last but not least, thanks to my friend for redirecting my ML vehicle here.
That’s great, thanks Ravindra.
Thank you for sharing this information.
I started to take the Coursera Stanford Machine Learning MOOC but I had some problems when I tried to submit/up load my responses to the exercises of the course because maybe the nature my internet connection here in Cuba. This “failure” almost killed my motivation, but now I’ll take your approach to pursuit my goal to become a machine learning practitioner. Thanks a lot for your advice.
Hi Jason,
Thanks for the wonderful effort of making ML more beginner friendly. I am a beginner and I have benefited from your work.
Here’s my personal approach:
Switching between reading and practicing works best for me. For example If I find 2 hours for dedicating to ML on a given day, I enjoy it most when I read for an hour and practice (relevant or irrelevant material) for an hour (in any order).This makes me feel that I am having fun as well as making some solid progress on the fundamentals.
Of course, the mix does not have to be exact 50-50, but whatever suits to the current point of expertise/enthusiasm. Over a longer period of time, I believe it covers more or less same ground as any other approach.
I chose scikit-learn and WEKA as practicing platforms, and I am reading Bishop’s PRML alongside.
Thanks again.
I’m with you on that, ‘The Top-down approach’
Thanks Jason,
This blog helped me a lot on how to start. But i wanted to be research student. My approach should be different because my priority should be algorithms rather than the solution most of the time. Can you suggest me any approach for that.
If you are a research student, my advice would be to commit to the academic approach as taught in university. Read the textbooks, take the courses and learn machine learning from the bottom-up.
Hi Jason…
I just found your site and started here. Excellent advice. I have spent the better part of two years learning as much as I could in statistics, linear algebra, calculus, programming, databases and machine learning, mostly through Coursera. I did take Andrew Ng’s course fairly early on and did well, but still felt that I was a long way from the point where I could develop my own applications. I also came away with the impression that I had to fully understand all of the algorithms, essentially by programming them myself! Since then, I have started other machine learning courses that do use libraries (Dato). Now, I can see that you don’t have to reinvent the wheel to make progress. In a way, I thought this was “cheating”, and it did hold me back.
Anyway, thank you for this site. I hope to work my way through all of it and follow the many resource links that you have put together.
Paul
Thanks for sharing Paul I’m happy the post made an impact on you.
Thanks for sharing Paul. This gives jump start; however can you list out level of complexity in ML in “Your next step section”?
Thanks for sharing Jason.
You’re very welcome Jay!
Hi Jason,
Thanks for outlining this approach. It makes me feel a lot better about approaching machine learning. I knew that it was possible to understand and use machine learning without all of the complexity of the math and algorithms. Having you confirm it really drives the point home. I’m excited to have come across your web site!
Thanks for the kind words Mehul. I hope that I can help you on your machine learning journey.
Hi Jason,
First of all, I want to thank you for such an amazing post. As you said, it is very disheartening for young, fledgling developers when they are berated on stackoverflow and quora for not knowing what to do. They are given a curt and dry reply- “Go study Algorithms/Data Structure/Stats/Probability/etc.” Not because they are lazy to read but because they just don’t know where to start. This behavior just breaks their heart and rips any aspiration. So thanks, for being so kind to us novices.
Now, I have a good theoretical understanding of Machine Learning thanks to a class I took- classification, clustering, types of errors, bagging, boosting, etc. I have tried many of these methods using Weka and feel comfortable with it. Now, I want to take the next step- somehow apply my programming skills to solve problems. What do you recommend my next steps be? I ask this, because I am somewhat in the middle and don’t know which direction to proceed. This seems worse to me than not knowing ML at all because I would’ve atleast started with an open mind.
Thanks
Respected sir
Thank you for this amazing post. This made me very clear how to proceed, what to do and what not. I have a small doubt about programming language used in machine learning. Some articles suggested using python while some books are using R language. Please guide me which language I should choose.
Hope to hear from you soon.
Thank You
Thanks Jason, some of my deepest concerns in studying ML are cleared. Im glad I found your blog atleast now as I started thinking that I cannot teach ML myself, though I have lot of interest in the subject.
thanks Jason , i come from china . your advice is awesome. i feel been suddenly enlightened.
best wishes
Hey Jason, I am new to machine learning, I just read your article and feeling motivated.
I want to do a machine learning project on handwritten digit recognition. I have no idea how should I start with it.
Can you give me a brief guideline on how should I start and what are the things I will be needing to learn. I have already found a data set on machine learning repository.
Any help will be appreciated, thanks in advance.
Excellent Blog!!
Excellent article. The problem is when you are really tired of MOOCs, Big fat Statistics Books and Kaggle , KDD you stumble here. Irony is you do not search for a similar blog when you start ML.
I have a 9-6 job and a non programmer. I am keen to learn ML for two reasons.
1. Exited to learn new technology
2. Use it in my day to day job as I work with lot of data ( I am in Project Management in a Semiconductor Company here in Bangalore , India).
Its been a year, I have tried, R, Python, Octave, MATLAB, Codeacademy, Spark you name it. I know some stuff now, but my thinking was clouded.
Thanks Jason. You are my ML Guru now. Coming from an Indian who really means it when he says the word “Guru”.
I haven’t coded in … many … years but always love data analysis and stats. With machine learning/data science being a hot area and my son learning Python, I’ve been looking for ways to learn and I’m lucky enough to stumble across your post here. What a relief to find that there’s a quicker way to play with ML without having to understand all the esoteric concepts and theories!
Thank you.
Hi Jason,
What a brilliant approach you suggested to novice like me!
I started with Coursera Stanford Machine Learning MOOC.I am in my first week of that course(I also watched YouTube Video of lectures on Machine Learning from Stanford)
and already find it daunting to understand all equations and algorithms. I took a refresher book on Linear Algebra( I took that before many years and now I am lost) but it is taking lot of time to go through. I received your email in mean time with links to this blog and found right approach to ML.
I will follow your advise and take hart to plunge in learning ML right way.
You saved me lot of pain and time.
Thanks a lot.
You’re very welcome Bharat.
Very useful article. I already tried watching Andrew Ng’s video lecture. Then I came to know that I don’t know much statistics and Probability, Linear Algebra, …… etc. Then I started with Statistical Learning Course from stanford. But half way only … I was really confused with all these approach but now I found good way! Thanks for the article.
Hey Jason,
Great Post… I have B.Tech Degree, MBA (2 Years ) , 1 year Business Analytics Certification from IIM Calcutta (premier Institute in INDIA ) & 6 years over all experience ( Coding/IT Sales/Data Analyst) so far…
But i have been struggling to get into core M/C learning or Data science stream because everywhere they ask for hands on experience (R/python/ etc)…. As a reason i have been frustrated a lot and trying to layout a plan for myself so that I can focus on one thing and get expertise of the same so that i can leverage my degrees as well.
Any more guidance would really help…thanks 🙂
really liked your post..
Regards,
Pramod
Hey Jason, great article.
I don’t think I’m anywhere near ready to start Machine Learning, as I don’t even know a language just yet, and have never developed anything in my life. I’ve just started learning Python at nights, but since I don’t work within IT (yet), it is slow progress.
Just after some advice, seeing as you’ve got a PhD in AI (philosophy). My goal is to work with intelligent agents and help shape the future of AI; I’m interested in deep learning, reinforcement learning and some NLP.
Since I don’t have a strong Computer Science background, would you recommend that I look at going to university, or do you think there is a better way to learn from the foundation upwards?
Consider starting with Weka, no programming required:
https://machinelearningmastery.com/tour-weka-machine-learning-workbench/
I think you can learn the practical steps of applied machine learning without going to university.
Hi Jason! I read your article “Machine Learning for Programmers: Leap from developer to machine learning practitioner”(the one talks about the traditional bottom-up approaching system.) I am very very grateful someone just shoot out things that I am so confused about !!!! I am watching the Stanford MOOC, I pushed myself so hard(to the huge gap) that I realized I lost some motivation(which I think is the most important) about even computer science. Then I found you and the article online this morning. Not exaggerating, you are my career saver. After 2 entry level computer science courses(they motivated me so much about being CS major) in college, I just felt wrong along going further about school which is too far away from the real life problem solving. Friends around me they admire school so much, they are so comfortable with the school system as long as they got good GPAs. I could go pages, just don’t want waste your time to help others. All I want to say is thank you. Finally, I got a pro confirmed my confusion. Thank you so much!!!
Thanks for the kind words Mike, I think your comment is inspiring.
Hang in there, Machine Learning is so much fun when you focus on the applied side!
Hi Jason,
Thanks for your handwork, excellent !
I am a embedded software engineer with experience in writing device drivers/firmware/Linux etc etc
Due to limited opportunities in embedded domain, I would like to move to ML/Deep learning.
How tough will it be for me to move? I have 14 years of embedded sw development experience.
appreciate your input !
Jason, this has been very helpful. I was in the dilemma whether PhD first or experience first. And when I concluded relevant industry experience really counts towards profile building for PhD, I found this master piece. I am a developer with database, data warehousing BI with c# programming experience. Thank you so much for sharing your thoughts, looking forward to see more of your work here.
I’m so glad it helped kartik, thanks for the comment.
Hello Sir Jason
Thanks a tonne for such rare and wonderful article.
I am a research student and I have opted for machine learning domain for my research work.
Can you please help me through some of my doubts regarding interface between weka and matlab that can be used in research work for machine learning. I am using classification technique in ML but somehow confused how to proceed and with what out of the two.
Kindly advise.
Hi Astha. Sorry I am not familiar with the Weka to Matlab interface. I cannot give you good advice.
Nice article
Thanks John.
Great read! I referenced this article on a talk I gave this week: https://medium.com/@gabrielcs/machine-learning-for-hackers-b60bfb9bbade
Thanks Gabriel
Great article! I work in algorithm development and have an academic background in intelligent systems but not all the necessary math so i can see the same frustrations you describe. I think the general information overload in the “data science” area (as well as many others like software development) adds to the problem and sometimes make it seem unsurmountable. I like your focus on the “machine learning engineer” type role too, and the approach of starting practical and learning the deeper layers as projects are undertaken. Do you have any advice for trying to encourage “old school” algorithm developers to move to machine learning approaches? I find this an issue in my current role, that they do not understand or “trust” the algorithms and therefore stick with old non scalable ways of making models.
Great article Jason. Very well thought and resonates immediately
Thanks Anant.
Hello Jason,
I know this post is intended for developers but would you suggest this same process for non-developers?
Before realising I wanted to work as a data scientist, I’ve been learning HTML, CSS & Javascript. However the more digit I did Ito data science the more I found out how often Python/R languages are used.
Would you suggest I learn a language like Python first before I start taking the approach you suggest?
Yes, this approach works just as well for designers and other non-developers.
I would suggest starting with Weka, that way you can learn and get good at applied machine learning without programming. It is much harder to learn 2 things at once – programming and machine learning.
More on Weka here:
https://machinelearningmastery.com/start-here/#weka
This post fits me perfectly. Wish I had seen it earlier.
I set myself up for “failure” by picking a complex and dirty problem as my very first ML project and on top of that, it’s my thesis topic. Great combo, eh?
I’m glad you found the post useful Ivan, and well done on spotting the hard way compared to the easy way.
I’m here to help if you have questions.
Hello jason
i dont have any programing knowledge,i want to know about machine learning.
please help me how to learn machine learning??/
Hi kiran kumar,
My best advice for non-programmers is to start with Weka:
https://machinelearningmastery.com/start-here/#weka
Thanks for the post, very intriguing.
It would be interesting to hear from someone that has followed through with this advice and has made the transition from some type of software development position to a machine learning software engineer.
I do get a lot of success stories by email. Some do let me interview them, for example:
https://machinelearningmastery.com/philosophy-graduate-to-machine-learning-practitioner/
https://machinelearningmastery.com/how-to-go-from-working-in-a-bank-to-hired-as-senior-data-scientist-at-target/
https://machinelearningmastery.com/how-a-beginner-used-small-projects-to-get-started-in-machine-learning-and-compete-on-kaggle/
I hope that helps as a start.
Hi Jason,
Thanks for the nice article. I see a ray of hope again after going through the blog.
I’m now around 45+ years, worked mostly in traditional software companies and now at management position which i dont feel i can do justice with and I’m interested in ML( mainly in R&D) i was very good as a student in maths and engineering too( always stood among top 3 in universities, though 25 years back ). I’m ready to take a break of 6 months to dive into this but do you suggest at this age should i take this risk? can i focus again and play with maths after so long? Need your advice, please help if i should even think of this stream?
Hi Sunil,
Yes. My advice would be to be laser focused on how to deliver results, not the theory. Of course, you can study whatever you want, but the shortest line between you now and being effective is learning how to deliver results – working through predictive modeling problems end to end.
You can get a long way in a few weeks of working every day, let alone a few months!
Start here:
https://machinelearningmastery.com/start-here/#getstarted
I hope that helps.
Thanks Jason, i’m hopeful it will be useful. I will connect back after few weeks.
Hi Jason,
I am a sophomore year student at IIT Guwahati, India. I am a UI/UX design student. This article is quite insightful as to how one can learn and apply ML. But it is more inclined towards developers switching to ML. I have recently developed interest in ML and although being a design student, I have completed courses in Linear Algebra and calculus in my freshman year. I’m a bit confused as to what would be my career prospectives if I choose to pursue ML with a Bachelor of Design degree.
Hi Ashutosh,
If you can learn how to provide value to a business with machine learning then you will have a “career”.
Don’t over think it.
OMG, Jason you are a pro. I’ve already made a planning on how to learn by myself an entire BS CS curriculum before appling to a Ms in Computer Science and finally do ML. What you have just told me here is “You can do whatever you want, but you don’t have to wait to start doing ML”. This is amazing, this totally makes sense to me….
I’ll follow your advice, and start working as soon as posible, and then make sense of it on my way to ML engineering.
Again, Thank you so much Jason, keep doing what you are doing, dudes like you have a prime role in making ML change the world.
I’m glad to hear that Daniel.
Stick with it. It’s worth it!
Can you send me your cs curriculum?
Great article Jason. Now I think even a novice developer like me can also learn ML. Thank you for the enlightenment.
Thanks Nikitha, I’m glad to hear it!
Very inspiring post and you hit every point that I am struggling with. Great stuff! ML here I come!
I’m glad it helped Fille. Hang in there!
so moocs’s are good or not
Up to you.
Hello sir, i have just completed my B.E in IT branch. i have recently developed interest in ML, but i don’t know how to begin. I have tried everything blogs, youtube videos but they all start with intermediate level. I have good knowledge of Python and i love solving calculus problems. could you suggest me where to begin?
I outline the getting started process here:
https://machinelearningmastery.com/start-here/#getstarted
The bunch of articles and exercises were really helpful with me to work in ML. Thank You so Much!
Thanks Nirodha, I’m really glad to hear that.
Hi Jason,
I am a developer trying to learn ML and you laid out such a beautiful path. You mapped it out amazingly. Thanks in advance… developer –> ML engineer… eventually data scientist.
I will scavenge your site until I bleed it dry of knowledge… keep it coming.
Thanks Todd. Let me know how you go!
Hi Jason,
I have a question about data transformation and feature engineering:
If I have a dataset containing 2 columns, one of them is data in Chinese characters and the other is numerical values. In this case, how can I do the data transformation and feature engineering?
Sincerely,
Steven
It depends on your prediction problem and what the characters and numbers represent.
hi Jason,
suppose the prediction problem is that we want to find the potential users of new service in a bank.
the characters represent the summary of users’ credit summary and the numbers represents users’ deposit in that bank.
So, how to do transform the characters into numerical values in order to do feature engineering ?
This sounds like feature engineering.
Maybe there are systematic things you can pull out.
Maybe turning all the text into numbers is the way (e.g. bag of words or word embedding methods). I would recommend testing lots of different approaches and see what works best for the problem.
More on feature engineering here:
https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
Hey, Jason, you see I am currently pursuing my bachelors in computer science and I want to do Django web development first and then move on to machine learning so what path will fit me right?
I don’t know, pick a path that best suits you.
Hey, I want to classify a word document contents using naive bayes algorithm in python. So, any one can give me some help or example so that i can implement the same in my problem.
Thank you to all in advance.
I will have a ton of NLP examples on the blog soon.
Thanks a ton Jason Brownlee . Before reading this blog I was almost certain to quit ML due to lack of mathematical core concepts. Although this blog is written so well based on some real life facts. This indeed is a great help for ppl like me trying to make transition to ML from software
Thanks, I’m glad to hear that. Hang in there!
Thanks, Jason ! A good and convincing article, which made me clear.
I’m glad to hear that.
For these many years , I was searching for a efficient source to learn Machine learning !Today I am lucky to visit this site ;
Very interesting articles ; Feeling Blessed () ;
Thankyou ! Sir
Thanks
Thank you for the great article and site! Super cool that your doing this.
I’ve been a top down programmer for most of my career. I needed to accomplish as task, I then developed/found the skills/tools, techniques to accomplish that specific task. For a number of the projects I actually didn’t understand a lot of the underlying concepts or math until after it was implemented, sometimes even after a number of years… But I was able to use those tools and concepts to successfully deliver. Of course of over time I’ve developed a pretty broad skill set I still don’t have some of the basic knowledge a fully educated software engineer has.
So I commend your approach, it is the exact approach took in the past and am now taking with machine learning.
Now that found your site I plan on going through a lot of it. To start though I do have one task that I do need to accomplish with ML – Predict a timeseries. Then improve that prediction over time as more data is acquired.
Would you have any additional suggestions for me in this case?
Thanks Keith.
My best advice is to focus on the process of working through problems end to end, everything else makes sense (or can be ignored) through this lens.
Hi! Jason
Your advice/methodology gives me strength,power and confidence to see ML as simple as possible.
The Gradient steps will help me understand the problems with minimum errors and soon i will find a clear path to ML.
Thank You
Thanks.
Hi Jason
I gone through article. I still have confusion . I used Weka by not focusing on algorithm like linear regression and gradient descent . But at the end I found lost myself again asking the same question is really a software developer can become machine learning developer.
I did not able to make the decision whether to under weka dataset i had to learn basis algorithms.
Sorry this might be a dumb question but i found myself lost.
Why, what was the problem exactly? Perhaps I have some suggestions.
weka does not gives me steps to code the same algorithm which is classified by the tools. How to convert this knowledge into python programming .
Weka teaches you the process with a point-and-click interface.
In Python you can code the process together yourself.
Again a great article. Thanks
Glad it helped.
Very Good Artical
Thanks.
Hi Jason,
This is a good article and I would like to use some of my spare time to try the whole flow. Just want to ask this question:
I am a professional developer for some years with good coding skills(my Python skill is okay or average) and very poor math skills, I can spend about 3 hours (at most) per day to learn about ML every day, 5 days a week, how long do you think I can finish the all 12 books and be ready to work on real ML projects in reality?
I know this might sounds like a dumb question, but I really need your opinion before I can dive in this domain and seriously do something.
Thanks
Some people start adding values in a few weeks, other take years. It come down to how much you focus on the process of working through problems systematically and delivering a usable result.
It seems my last comment was gone?
I moderate comments in batch once or twice per day, more here:
https://machinelearningmastery.com/faq/single-faq/where-is-my-blog-comment
Damn, I wish I read this before I started. As a dev I have no idea had how to approach it. I feel like I’ve read quite a lot and progressed very little in comparison, feeling pretty stupid and very frustrated with trying to understand all the math and theory going on. I feel like this is the key info what I was missing, just knowing how to approach this whole thing in the situation from a developer’s point of view. I think this article is a game changer and big eyeopener for me. Thanks you very much for this!! This is a must read for every developer trying to get into ML.
Thanks, I’m really happy that it helps!
Me too, I wish I found this before I started an year back. lost in learning mushrooming tools, especially Programming in python, instead of focusing on core ML. Thank god I found this.
Thanks, I’m so happy it helps!
I like your approach top-down (instead of bottom-up) method as immersive way to start delivering specific solutions in Machine Learning, through a big spectrum of particulars and full solutions, even if the pillars as developer (math -calculus, linear algebra, statistics-, programming language, API knowledge, etc) are not the best, because of our current university degree or study background lack .
I think it is easier start “mutating” small part of the final code provide by you in every post instead of starting from scratch (bottom-up) every time.
That reminds me a process as imitating biology; I can construct a new life entity starting from unicellular, combining into multicellulars, later on producing organs differentiations, etc. that is the “hard way” of standard university education or just simply change some “genes” or “mutating” in a similars animals to obtain some skillful new life differentiation just from the beginning out of the blue. Even if the new life cab be reproducible you can create new lifes in a sustainable way.
I estimate this the way you start and the final reason of your posts success.
In addition to that, and you do not mention, you can always going back and study deeper into the pillars of statics, algebra, calculus, etc to strengthen your basic knowledge …any time you are interested to know the roots of something you just have done, but do not know the fundamentals.
Thanks Jason for your invaluable job !
Thanks, great metaphor!
Indeed, you can always circle back and go deeper, but only in service of getting better results (e.g. directed and with a context).
bro… where ever you are… u r awesome dude….
I’m right here 🙂
Thanks!
What a convincing (most positive) post! You just nailed it.
Thanks!
Hello,
Thanks for this post, it was very motivating, I have a question, what difference does a linear regression algorithm from the perspective of machine learning and a linear regression algorithm from the perspective of statistics? My question is oriented to, why is it called machine learning? What is the change, if I solve a problem with statistics or if I address them with ML? What is the difference? Thanks again for your help.
Same method, just more data and automation. Linear regression was devised to be calculated by hand.
Jason, thanks for this insightful and great contribution
Thanks, I’m glad you found it useful.
Jason,
Thanks for the detailed post. I have got confidence to move further
You’re welcome, I’m happy to hear that.
Thanks for the amazing blog! Its really helpful.
You’re welcome.
Great post. Thanks for sharing such an informative post.
Thanks, I’m glad it helped.
Thanks for the amazing blog.Its really helpful for me.
Thanks, I’m happy it helps!
Excellent post
Thanks!
I have spent hours reading about getting started with ML. As a developer, this is really the best synopsis of what it is all about. Lots of people can be good at statistical analysis, but few can eloquently articulate what it takes to succeed here. Thanks for putting this together!
Thanks Randeep!
I am Bheemanna I am learning Artificial Intelligence then I don’t know Artificial Intelligence what will you do sir
I teach predictive modeling, a subfield of machine learning, which is a subfield of AI.
You can get started here:
https://machinelearningmastery.com/start-here/#getstarted
I am beginner.
But I have a little mathematics theory.
I afraid that can i learn ML.
What do you think about this.
No problem at all, see this:
https://machinelearningmastery.com/youre-wrong-machine-learning-not-hard/
I love your post. Your post will greatly benefit me.Will post better later. Thanks
Thanks!
I wish I read this two months ago. Great article!
Thanks!
Great article. Thanks for nice contribution.
I am planning to start my research in finance using (ML,AI,DL techiniques) from scratch. but totally upset where to start. My background is master in computer science.
Sir!
Would you suggest me something in this regard .
Start here:
https://machinelearningmastery.com/start-here/#getstarted
A Great pathway is drawn here , thumbs up and Thank you !
Thanks!
Dear Jason
I really thank you and appreciate your help to beginners learn deep learning. I myself was disappointed after getting overwhelmed by too many resources on deep learning until I found your helpful website. As you mentioned, having PhD does not guarantee to understand scientific tips especially on deep learning.
Thanks, I’m happy it helps!
Great post, many thank you!
I’m system engineer and a 10 years experienced software developer. I’m beginning in AI field, so this post is a good aproach. I took some AI courses, but it’s still difficult to me to realize when I can use AI to solve problems.
Thus, my question is, do you have any post with advices aimed to recognize opportunities to use AI?
No, I focused on machine learning.
Hi,
I wonder if you cover any of those Maths related things you talk about here, or if you could point me towards such resources. I would ike to understand all the basic Maths related stuff attached to ML.
Thanks
Right here:
https://machinelearningmastery.com/faq/single-faq/what-mathematical-background-do-i-need-for-machine-learning
I very happy to meet your write up. It really save my day. Thanks
You’re welcome.
Hi Jason,
This is a cool post, thank you!
I’m new to the world of stochastic matrix modelling and agent based modelling/individual based modelling, where there is a lot of uncertainty around the model parameters (educated guess work from experts in the applied domain!), around modelling methods, and of arising from the noise generated by the random sampling from the parameter windows and other stochasticity introduced within the model. I’m currently wading through the huge field of sensitivity analysis and have been looking at using regression/classification emulators applied to the relationship between a the parameter space and some model response (like, say binomial extinction). I’m guessing you have already published a lot on this topic, and your general ethos seems to be “traditional is not always best”.
If you have any time, it’d be great if you would please be able to point me to any of your blogs or books or web posts on this area.
Thank you. 🙂
b
Sorry Bree, I don’t have tutorials on “agent based modeling” or “stochastic matrix modelling”.
I love your post, one thing I disagree with is “develop the algorithms from scratch”, I feel that learning how to develop from scratch makes you understand what each library is doing so when you use libraries, you have a more deep understanding of what to apply.
I agree it helps a lot. You just don’t need to do it as a first step, or at all if you’re not so inclined.
I see many beginners start by coding everything from scratch which can be hard/overwhelming.
Also, any implementation you do will be slower and have more bugs compared to an open-source library.
You are totally right Jason, starting from scratch can be overwhelming for beginners.
Anyways keep doing your blog posts, I love them, you are just awesome man 🙂
Thanks!
Thank you for this post, Jason, and for sharing your knowledge! It was just in time, as I was feeling a bit overwhelmed and ready to give up.
Hang in there!
Thanks for great post !
I’m a web developer but I haven’t a high school diploma yet, this was stoping me to continue,
I tried to ask in some ml forum “where to start”, the answer was the same (linear algebra, probability,etc.).
This post is helpful to me cause I’m don’t have any intermediate math knowledge!
I appreciate your blog, thanks alot.
Jehsh Philemon Mulwahali
Glad you liked it! There are different approach to ML. You don’t always need to dive into the theory side.
Stage PFE / ALGHORITME Machine Learning avec python
The top down approach to learning you described really resonates with me. As a developer who got started at a bootcamp, I can attest to the fact that its best to learn programming by building things that get you excited about the field. Of course its important to circle back later and fill out some of the theory you are missing, but even this is easier when you can conceptualize why it is important. As a person who went back to school to get a masters, I can also attest to the fact that school focuses much more on ground up theory. This is obviously a must if you want to be the person designing the next ML algorithms, but for a practitioner in a professional setting, I would agree its best to start doing and learn while you go.
Thank you for your feedback and support Daniel! We wish you the best on your machine learning journey!
The greatest advice I have ever read on starting code in Machine Learning. I found the reason why I am so bored with coding because of the pitfall of traditional learning system. I understand the limit is me myself and my mindset. Now I’m working on my mindset first and begin the learning process from ‘Top to Down’.
Change your thinking and change your life is real motto!
Thank you for your feedback Zabulon! We apprecciate it!