The Python ecosystem is growing and may become the dominant platform for applied machine learning.
The primary rationale for adopting Python for time series forecasting is because it is a general-purpose programming language that you can use both for R&D and in production.
In this post, you will discover the Python ecosystem for time series forecasting.
After reading this post, you will know:
- The three standard Python libraries that are critical for time series forecasting.
- How to install and setup the Python and SciPy environment for development.
- How to confirm your environment is working correctly and ready for time series forecasting.
Kick-start your project with my new book Time Series Forecasting With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Python Environment for Time Series Forecasting
Photo by Joao Trindade, some rights reserved.
Why Python?
Python is a general-purpose interpreted programming language (unlike R or Matlab).
It is easy to learn and use primarily because the language focuses on readability.
It is a popular language in general, consistently appearing in the top 10 programming languages in surveys on StackOverflow (for example, the 2015 survey results).
Python is a dynamic language and very suited to interactive development and quick prototyping with the power to support the development of large applications.
Python is also widely used for machine learning and data science because of the excellent library support. It has quickly become one of the dominant platforms for machine learning and data science practitioners and is in greater demand than even the R platform by employers (see the graph below).
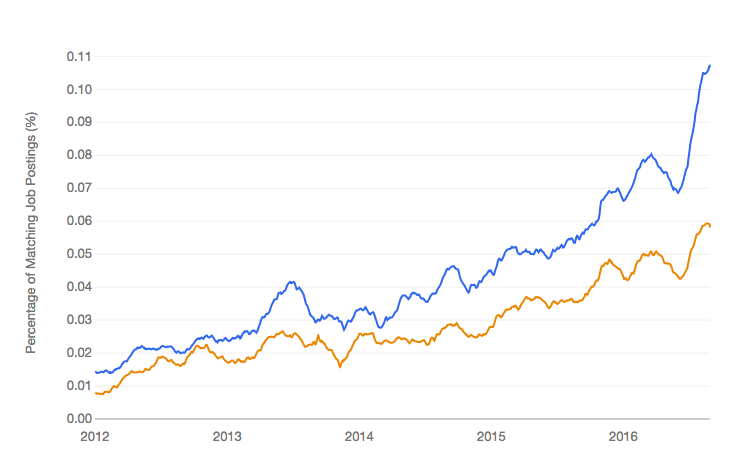
Python Machine Learning Jobs vs R Machine Learning Jobs
This is a simple and very important consideration.
It means that you can perform your research and development (figuring out what models to use) in the same programming language that you use in operations, greatly simplifying the transition from development to operations.
Stop learning Time Series Forecasting the slow way!
Take my free 7-day email course and discover how to get started (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Python Libraries for Time Series
SciPy is an ecosystem of Python libraries for mathematics, science, and engineering. It is an add-on to Python that you will need for time series forecasting.
Two SciPy libraries provide a foundation for most others; they are NumPy for providing efficient array operations and Matplotlib for plotting data.There are three higher-level SciPy libraries that provide the key features for time series forecasting in Python.
They are pandas, statsmodels, and scikit-learn for data handling, time series modeling, and machine learning respectively.
Let’s take a closer look at each in turn.
Library: pandas
The pandas library provides high-performance tools for loading and handling data in Python.
It is built upon and requires the SciPy ecosystem and uses primarily NumPy arrays under the covers but provides convenient and easy to use data structures like DataFrame and Series for representing data.
Pandas provides a special focus on support for time series data.
Key features relevant for time series forecasting in pandas include:
- The Series object for representing a univariate time series.
- Explicit handling of date-time indexes in data and date-time ranges.
- Transforms such as shifting, lagging, and filling.
- Resampling methods such as up-sampling, down-sampling, and aggregation.
Library: statsmodels
The statsmodels library provides tools for statistical modeling.
It is built upon and requires the SciPy ecosystem and supports data in the form of NumPy arrays and Pandas Series objects.
It provides a suite of statistical test and modeling methods, as well as tools dedicated to time series analysis that can also be used for forecasting.
Key features of statsmodels relevant to time series forecasting include:
- Statistical tests for stationarity such as the Augmented Dickey-Fuller unit root test.
- Time series analysis plots such as autocorrelation function (ACF) and partial autocorrelation function (PACF).
- Linear time series models such as autoregression (AR), moving average (MA), autoregressive moving average (ARMA), and autoregressive integrated moving average (ARIMA).
Library: scikit-learn
The scikit-learn library is how you can develop and practice machine learning in Python.
It is built upon and requires the SciPy ecosystem. The name “sckit” suggests that it is a SciPy plug-in or toolkit. You can review a full list of available SciKits.
The focus of the library is machine learning algorithms for classification, regression, clustering, and more. It also provides tools for related tasks such as evaluating models, tuning parameters, and pre-processing data.
Key features relevant for time series forecasting in scikit-learn include:
- The suite of data preparation tools, such as scaling and imputing data.
- The suite of machine learning algorithms that could be used to model data and make predictions.
- The resampling methods for estimating the performance of a model on unseen data, specifically the TimeSeriesSplit.
Python Ecosystem Installation
This section will provide you general advice for setting up your Python environment for time series forecasting.
We will cover:
- Automatic installation with Anaconda.
- Manual installation with your platform’s package management.
- Confirmation of the installed environment.
If you already have a functioning Python environment, skip to the confirmation step to check if your software libraries are up-to-date.
Let’s dive in.
1. Automatic Installation
If you are not confident at installing software on your machine or you’re on Microsoft Windows, there is an easy option for you.
There is a distribution called Anaconda Python that you can download and install for free.
It supports the three main platforms of Microsoft Windows, Mac OS X, and Linux.
It includes Python, SciPy, and scikit-learn: everything you need to learn, practice, and use time series forecasting with the Python Environment.
You can get started with Anaconda Python here:
2. Manual Installation
There are multiple ways to install the Python ecosystem specific to your platform.
In this section, we cover how to install the Python ecosystem for time series forecasting.
How To Install Python
The first step is to install Python. I prefer to use and recommend Python 2.7 or Python 3.5.
Installation of Python will be specific to your platform. For instructions see:
On Mac OS X with macports, I would type:
|
1 2 3 |
sudo port install python35 sudo port select --set python python35 sudo port select --set python3 python35 |
How To Install SciPy
There are many ways to install SciPy.
For example, two popular ways are to use package management on your platform (e.g. dnf on RedHat or macports on OS X) or use a Python package management tool, like pip.
The SciPy documentation is excellent and covers how-to instructions for many different platforms on the page Installing the SciPy Stack.
When installing SciPy, ensure that you install the following packages as a minimum:
- scipy
- numpy
- matplotlib
- pandas
- statsmodels
On Mac OS X with macports, I would type:
|
1 2 |
sudo port install py35-numpy py35-scipy py35-matplotlib py35-pandas py35-statsmodels py35-pip sudo port select --set pip pip35 |
On Fedora Linux with dnf, I would type:
|
1 |
sudo dnf install python3-numpy python3-scipy python3-pandas python3-matplotlib python3-statsmodels |
How To Install scikit-learn
The scikit-learn library must be installed separately.
I would suggest that you use the same method to install scikit-learn as you used to install SciPy.
There are instructions for installing scikit-learn, but they are limited to using the Python pip package manager.
On Linux and Mac OS X, I installed scikit-learn by typing:
|
1 |
sudo pip install -U scikit-learn |
3. Confirm Your Environment
Once you have set-up your environment, you must confirm that it works as expected.
Let’s first check that Python was installed successfully. Open a command line and type:
|
1 |
python -V |
You should see a response like the following:
|
1 |
Python 2.7.12 |
or
|
1 |
Python 3.5.3 |
Now, confirm that the libraries were installed successfully.
Create a new file called versions.py and copy and paste the following code snippet into it and save the file as versions.py.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# scipy import scipy print('scipy: %s' % scipy.__version__) # numpy import numpy print('numpy: %s' % numpy.__version__) # matplotlib import matplotlib print('matplotlib: %s' % matplotlib.__version__) # pandas import pandas print('pandas: %s' % pandas.__version__) # statsmodels import statsmodels print('statsmodels: %s' % statsmodels.__version__) # scikit-learn import sklearn print('sklearn: %s' % sklearn.__version__) |
Run the file on the command line or in your favorite Python editor. For example, type:
|
1 |
python versions.py |
This will print the version of each key library you require.
For example, on my system at the time of writing, I got the following results:
|
1 2 3 4 5 6 |
scipy: 0.18.1 numpy: 1.11.3 matplotlib: 1.5.3 pandas: 0.19.1 statsmodels: 0.6.1 sklearn: 0.18.1 |
If you have an error, stop now and fix it. You may need to consult the documentation specific for your platform.
Summary
In this post, you discovered the Python ecosystem for time series forecasting.
You learned about:
- The pandas, statsmodels, and scikit-learn libraries that are the top time series forecasting with Python.
- How to automatically and manually setup a Python SciPy environment for development.
- How to confirm your environment is installed correctly and that you’re ready to started developing models.
You also learned how to install the Python ecosystem for machine learning on your workstation.
Do you have any questions about Python for time series forecasting, or this post? Ask your question in the comments and I will do my best to answer.
Want to Develop Time Series Forecasts with Python?

Develop Your Own Forecasts in Minutes
...with just a few lines of python codeDiscover how in my new Ebook:
Introduction to Time Series Forecasting With Python
It covers self-study tutorials and end-to-end projects on topics like: Loading data, visualization, modeling, algorithm tuning, and much more...
Finally Bring Time Series Forecasting to
Your Own Projects
Skip the Academics. Just Results.






Hi Jason,
I work on clustering time series, can you guide me to an example.
Do you have an idea about Dynamic Time Warping (DTW) for time series clustering or point me to an example..
Thank you.
Sorry, I don’t have a tutorial on DTW, thanks for the suggestion.
Hi Jason,
Can you please Make a tutorial for Sktime library and how it work for multi output regression
Thanks in advance.
Thanks for the suggestion.