I found that the best way to discover and get a handle on the basic concepts in machine learning is to review the introduction chapters to machine learning textbooks and to watch the videos from the first model in online courses.
Domingos has a free course on machine learning online at courser titled appropriately “Machine Learning“. The videos for each module can be previewed on Coursera any time.
In this post you will discover the basic concepts of machine learning summarized from Week One of Domingos’ Machine Learning course.
Basic Concepts in Machine Learning Photo by Travis Wise, some rights reserved.
Machine Learning
The first half of the lecture is on the general topic of machine learning.
What is Machine Learning?
Why do we need to care about machine learning?
A breakthrough in machine learning would be worth ten Microsofts.
Machine Learning is getting computers to program themselves. If programming is automation, then machine learning is automating the process of automation.
Writing software is the bottleneck, we don’t have enough good developers. Let the data do the work instead of people. Machine learning is the way to make programming scalable.
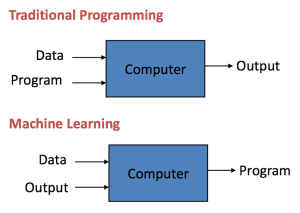
Traditional Programming: Data and program is run on the computer to produce the output.
Machine Learning: Data and output is run on the computer to create a program. This program can be used in traditional programming.
Machine learning is like farming or gardening. Seeds is the algorithms, nutrients is the data, the gardner is you and plants is the programs.
Traditional Programming vs Machine Learning
Applications of Machine Learning
Sample applications of machine learning:
Web search: ranking page based on what you are most likely to click on.
Computational biology: rational design drugs in the computer based on past experiments.
Finance: decide who to send what credit card offers to. Evaluation of risk on credit offers. How to decide where to invest money.
E-commerce: Predicting customer churn. Whether or not a transaction is fraudulent.
Space exploration: space probes and radio astronomy.
Robotics: how to handle uncertainty in new environments. Autonomous. Self-driving car.
Information extraction: Ask questions over databases across the web.
Social networks: Data on relationships and preferences. Machine learning to extract value from data.
Debugging: Use in computer science problems like debugging. Labor intensive process. Could suggest where the bug could be.
What is your domain of interest and how could you use machine learning in that domain?
Key Elements of Machine Learning
There are tens of thousands of machine learning algorithms and hundreds of new algorithms are developed every year.
Every machine learning algorithm has three components:
Representation: how to represent knowledge. Examples include decision trees, sets of rules, instances, graphical models, neural networks, support vector machines, model ensembles and others.
Evaluation: the way to evaluate candidate programs (hypotheses). Examples include accuracy, prediction and recall, squared error, likelihood, posterior probability, cost, margin, entropy k-L divergence and others.
Optimization: the way candidate programs are generated known as the search process. For example combinatorial optimization, convex optimization, constrained optimization.
All machine learning algorithms are combinations of these three components. A framework for understanding all algorithms.
Types of Learning
There are four types of machine learning:
Supervised learning: (also called inductive learning) Training data includes desired outputs. This is spam this is not, learning is supervised.
Unsupervised learning: Training data does not include desired outputs. Example is clustering. It is hard to tell what is good learning and what is not.
Semi-supervised learning: Training data includes a few desired outputs.
Reinforcement learning: Rewards from a sequence of actions. AI types like it, it is the most ambitious type of learning.
Supervised learning is the most mature, the most studied and the type of learning used by most machine learning algorithms. Learning with supervision is much easier than learning without supervision.
Inductive Learning is where we are given examples of a function in the form of data (x) and the output of the function (f(x)). The goal of inductive learning is to learn the function for new data (x).
Classification: when the function being learned is discrete.
Regression: when the function being learned is continuous.
Probability Estimation: when the output of the function is a probability.
Machine Learning in Practice
Machine learning algorithms are only a very small part of using machine learning in practice as a data analyst or data scientist. In practice, the process often looks like:
Start Loop
Understand the domain, prior knowledge and goals. Talk to domain experts. Often the goals are very unclear. You often have more things to try then you can possibly implement.
Data integration, selection, cleaning and pre-processing. This is often the most time consuming part. It is important to have high quality data. The more data you have, the more it sucks because the data is dirty. Garbage in, garbage out.
Learning models. The fun part. This part is very mature. The tools are general.
Interpreting results. Sometimes it does not matter how the model works as long it delivers results. Other domains require that the model is understandable. You will be challenged by human experts.
Consolidating and deploying discovered knowledge. The majority of projects that are successful in the lab are not used in practice. It is very hard to get something used.
End Loop
It is not a one-shot process, it is a cycle. You need to run the loop until you get a result that you can use in practice. Also, the data can change, requiring a new loop.
Inductive Learning
The second part of the lecture is on the topic of inductive learning. This is the general theory behind supervised learning.
What is Inductive Learning?
From the perspective of inductive learning, we are given input samples (x) and output samples (f(x)) and the problem is to estimate the function (f). Specifically, the problem is to generalize from the samples and the mapping to be useful to estimate the output for new samples in the future.
In practice it is almost always too hard to estimate the function, so we are looking for very good approximations of the function.
Some practical examples of induction are:
Credit risk assessment.
The x is the properties of the customer.
The f(x) is credit approved or not.
Disease diagnosis.
The x are the properties of the patient.
The f(x) is the disease they suffer from.
Face recognition.
The x are bitmaps of peoples faces.
The f(x) is to assign a name to the face.
Automatic steering.
The x are bitmap images from a camera in front of the car.
The f(x) is the degree the steering wheel should be turned.
When Should You Use Inductive Learning?
There are problems where inductive learning is not a good idea. It is important when to use and when not to use supervised machine learning.
4 problems where inductive learning might be a good idea:
Problems where there is no human expert. If people do not know the answer they cannot write a program to solve it. These are areas of true discovery.
Humans can perform the task but no one can describe how to do it. There are problems where humans can do things that computer cannot do or do well. Examples include riding a bike or driving a car.
Problems where the desired function changes frequently. Humans could describe it and they could write a program to do it, but the problem changes too often. It is not cost effective. Examples include the stock market.
Problems where each user needs a custom function. It is not cost effective to write a custom program for each user. Example is recommendations of movies or books on Netflix or Amazon.
The Essence of Inductive Learning
We can write a program that works perfectly for the data that we have. This function will be maximally overfit. But we have no idea how well it will work on new data, it will likely be very badly because we may never see the same examples again.
The data is not enough. You can predict anything you like. And this would be naive assume nothing about the problem.
In practice we are not naive. There is an underlying problem and we are interested in an accurate approximation of the function. There is a double exponential number of possible classifiers in the number of input states. Finding a good approximate for the function is very difficult.
There are classes of hypotheses that we can try. That is the form that the solution may take or the representation. We cannot know which is most suitable for our problem before hand. We have to use experimentation to discover what works on the problem.
Two perspectives on inductive learning:
Learning is the removal of uncertainty. Having data removes some uncertainty. Selecting a class of hypotheses we are removing more uncertainty.
Learning is guessing a good and small hypothesis class. It requires guessing. We don’t know the solution we must use a trial and error process. If you knew the domain with certainty, you don’t need learning. But we are not guessing in the dark.
You could be wrong.
Our prior knowledge could be wrong.
Our guess of the hypothesis class could be wrong.
In practice we start with a small hypothesis class and slowly grow the hypothesis class until we get a good result.
A Framework For Studying Inductive Learning
Terminology used in machine learning:
Training example: a sample from x including its output from the target function
Target function: the mapping function f from x to f(x)
Hypothesis: approximation of f, a candidate function.
Concept: A boolean target function, positive examples and negative examples for the 1/0 class values.
Classifier: Learning program outputs a classifier that can be used to classify.
Learner: Process that creates the classifier.
Hypothesis space: set of possible approximations of f that the algorithm can create.
Version space: subset of the hypothesis space that is consistent with the observed data.
Key issues in machine learning:
What are good hypothesis space?
What algorithms work with that space?
What can I do to optimize accuracy on unseen data?
How do we have confidence in the model?
Are there learning problems that are computationally intractable?
How can we formulate application problems as machine learning problems?
There are 3 concerns for a choosing a hypothesis space space:
Size: number of hypotheses to choose from
Randomness: stochastic or deterministic
Parameter: the number and type of parameters
There are 3 properties by which you could choose an algorithm:
Search procedure
Direct computation: No search, just calculate what is needed.
Local: Search though the hypothesis space to refine the hypothesis.
Constructive: Build the hypothesis piece by piece.
Timing
Eager: Learning performed up front. Most algorithms are eager.
Lazy: Learning performed at the time that it is needed
Online vs Batch
Online: Learning based on each pattern as it is observed.
Batch: Learning over groups of patterns. Most algorithms are batch.
Summary
In this post you discovered the basic concepts in machine learning.
In summary, these were:
What is machine learning?
Applications of Machine Learning
Key Elements of Machine Learning
Types of Learning
Machine Learning in Practice
What is Inductive Learning?
When Should You Use Inductive Learning?
The Essence of Inductive Learning
A Framework For Studying Inductive Learning
These are the basic concepts that are covered in the introduction to most machine learning courses and in the opening chapters of any good textbook on the topic.
Although targeted at academics, as a practitioner, it is useful to have a firm footing in these concepts in order to better understand how machine learning algorithms behave in the general sense.
I am a newbie in this area.. I have total of 8 years experience in PL/SQL programming . What should be my first step to learn ML. I have basic knowledge in Python.
please guide , Thank you Sir.
This article is very useful, certainly. But as a newbie, I see that the final part, from framework for studying inductive learning is quite hard to understand because of too much new concepts. I know I have to learn more.
Many thanks, Jason.
Best wishes for you and your family.
Thanks for this AWESOME introduction to machine learning! I’ve always been interested in the subject but never gotten around to looking into it.
Now that I’ve graduate from university (masters in physics [lasers]) I’ve a bit more time on my hands as I start to look for a job. I’m increasingly excited at the possibility of going into this large and growing field.
As I am beginner so it makes me very confident,whatever I was expecting in machine learning it cover-up all those stuffs . Thank you very much and very helpful for beginner
Like others, I should also say that this is a very nice conceptual introduction. Could you possibly add or refer to a practical and simple example of a solved problem using ML? So far I couldn’t have found any useful source giving sufficient details of different steps for ML, in particular the mathematics behind it.
I was about to read it and go further. But I can’t leave your website before saying that you have a great ability to write about very complex things in an easy matter. It shows that you have very big knowlege and with your articles it is easy to understand a lot of things. Continue what you’re doing because you’re doing it good. You were very helpful to me, thanks.
Some remarks :
It could be interesting to add real life analogies / concrete examples to : terminology / the algorithm properties …
Typo at the end ? “patters” instead of “patterns” ?
Also some information in readers comments could be implemented in the article
what are the statistical approach we use in machine clearing while modeling….
I mean suppose we have an data set,should we have an hypothesis to start with …what are the steps,it would be very helpful ,if you could throw some light on it…
This is a very nice summary, Jason, thank you for sharing.
Some additional topics that seem worthy of mention here:
1. Generalization — the objective of a predictive model is to predict well on new data that the model has never seen, not to “fit” the data we already have.
2. Model validation – how to assess model performance; dividing data into training, validation, and test sets; cross-validation; avoiding data snooping, selection bias, survivorship bias, look-ahead bias, and more. In my experience, model validation is one of the most challenging aspects of ML (and to do it well may vastly increase the challenges in constructing and managing your datasets)
3. Bias / variance tradeoff — importance of balancing overfitting (high variance, complex models) and underfitting (high bias, simple models); the more complex the model, the more data that is required to avoid overfitting; deep learning models require vastly more labeled data than traditional (simpler) ML models
4. Curse of dimensionality — as you increase the number of predictors (independent variables), you need exponentially more data to avoid underfitting; dimensionality reduction techniques
5. Feature engineering — related to domain expertise and data preparation; with good domain experts, you can often construct features that perform vastly better than the raw data.
Ok, that’s more than enough. I started my reply intending to mention only generalization and validation … This is such a rich topic! Hope this helps. Thanks again for your great work.
Hi Jason. I enjoyed your article, thanks for writing. I also wrote an article on machine learning that is geared towards beginners at youcodetoo.com. Let me know what you think!
Machine learning is the coolest field to build a better career. I was looking for some point which help me to become a machine learning. After reading your blog every picture become clear in my mind. Now I can design my career path. Thank you for best career advice. Your blog have fabulous information.
Wow, this is my first reading on Machine Learning! And I am seriously delving into it. A great introduction of a subject. Will seek your guide as I walk in the new world. Thanks







It is indeed very good article. I am beginner to Machine learning and this article helped me give basic information. Thank You Jason.
I’m glad it was useful Deepak.
I am a newbie in this area.. I have total of 8 years experience in PL/SQL programming . What should be my first step to learn ML. I have basic knowledge in Python.
please guide , Thank you Sir.
rsgupta87@gmail.com
+91-9873982576
You can get started here:
https://machinelearningmastery.com/start-here/#getstarted
Hi Jason. I found this artie useful and worthy. But I don’t have basics of any language… i am a commerce student. Can i learn ML?
How do I start
learning ML and Please help me out in learning ML
Yes, you can, start here:
https://machinelearningmastery.com/start-here/#getstarted
Very nice introduction…
I’m glad you found it useful Lal.
Good to start
@Jason I found a typo ‘martin’ which should be margin I think…
Great, thanks Lal. Fixed.
This article is very useful, certainly. But as a newbie, I see that the final part, from framework for studying inductive learning is quite hard to understand because of too much new concepts. I know I have to learn more.
Many thanks, Jason.
Best wishes for you and your family.
Thanks for the feedback Namnnb.
@Jason Very useful article. thank you.
I’m glad to hear that soufiane.
Which topics were most interesting?
Thnx Jason Brownlee Nice and Interesting Article …..Very help full.
I’m glad to hear that Anees.
Thanks for this AWESOME introduction to machine learning! I’ve always been interested in the subject but never gotten around to looking into it.
Now that I’ve graduate from university (masters in physics [lasers]) I’ve a bit more time on my hands as I start to look for a job. I’m increasingly excited at the possibility of going into this large and growing field.
Thank you again!
Thanks Jerry, it’s great to have you here.
As I am beginner so it makes me very confident,whatever I was expecting in machine learning it cover-up all those stuffs . Thank you very much and very helpful for beginner
I’m glad to hear it Abhishek.
what’s the difference between inductive learning algorithm and analogy learning algorithm?
I’ve not heard of the analogy learning algorithm, sorry.
Very nice explanation. Can you help me to understand Artificial Intelligence and the difference between ML and AI.
Regards,
Irfan
Hi Irfan,
ML is a subfield of AI concerned with making inferences from data. AI is concerned with all aspects of intelligence.
The most useful part of ML I would recommend focusing on is predictive modeling.
Thanks, MR Jason, such a wonderful knowledge about machine learning. It is very usedful for beginners.
Thanks!
Good Article Indeed, thanks for making me familiar with those new terms., Looking forward for more info.
You’re welcome Sagar.
Hi Jason,
Like others, I should also say that this is a very nice conceptual introduction. Could you possibly add or refer to a practical and simple example of a solved problem using ML? So far I couldn’t have found any useful source giving sufficient details of different steps for ML, in particular the mathematics behind it.
Thanks Majid,
Here are the steps for working through a problem:
https://machinelearningmastery.com/start-here/#process
Here are some interesting problems solved with ML:
https://machinelearningmastery.com/inspirational-applications-deep-learning/
Very nice article, i get relevant basic concepts about ML.
Thanks, I’m glad to hear that Addisie.
Great article for a beginner like me. I got to learn basic terminology and concepts in ML.
I’m glad to hear that Saksham.
Thanks Dr. Jason.
Your articles are very practical and comprehensive. In a way I am indebted.
Regards Raghav
Thanks.
Great Work
Thanks Vijay.
so what do you suggest to go from here to get my feet a bit more wet?
Weka:
https://machinelearningmastery.com/start-here/#weka
Dear Jason, thanks for the high-level overview. It helped me a lot!
You’re welcome, I’m happy to hear that.
Can you explain more regarding selecting an algorithm based on search procedure.
What do you mean exactly?
very nice article. Thanks Jason!!
Thanks meghana, I’m glad it helped.
Thanks Jason, is online simply where batch-size = 1?
Yes Jann.
Very informative article. Thank you Jason..
Thanks Ramesh.
Nice Article Jason.If you have a series of this, please let us know. We will follow this
Not at this stage, perhaps in the future.
I was about to read it and go further. But I can’t leave your website before saying that you have a great ability to write about very complex things in an easy matter. It shows that you have very big knowlege and with your articles it is easy to understand a lot of things. Continue what you’re doing because you’re doing it good. You were very helpful to me, thanks.
Thanks Kamila!
Hi Jason,
Thanks for this wonderful start. May i know the pre-requistes for ML? Do we have need any programming experience?
Not at all. Start here:
https://machinelearningmastery.com/start-here/#getstarted
Hi Jason,
Any tips on formulating a good hypothesis with the data owner?
Mostly, it’s a case of “I want to know ‘this’ – here’s my data”.
What do you mean exactly?
Can you discriminate following terminologies ?
-Deep learning
-Machine learning
-Neural Network
-Artificial Intelligence
How they differ with each other ?
ML is a subfield of AI.
DL and NN are the same thing and are a subfield of ML.
Useful stuff (Y)
Thanks.
here’s a typo Jason
“There are problems where inductive learning is not a hood idea”
Should be “good” instead of “hood”.
Cheers
Thanks Doug, fixed.
I am a newbie. Nice introduction. Thank you.
Thanks, I’m glad it helped.
New to this. Nice introduction. Thank you!
Thanks!
thank you sir
Helped me for preparing my exams for AI
I searched the web for inductive learning, got here with the aid of QUORA
Thanks again!!
I’m glad it helped.
hai
well written introduction
clear cut Definitions
all the information are at to the point .
very useful
thank you so much
awaiting for exploring more from you materials
Glad it helped.
The fact that the article still resonates with the audience after 2 years speaks on its own. Thank you!
Thanks.
Hi Jason,
It was a nice and informative article. Could you please explain how version space learning works?
Thanks and Regards,
Ankur Gupta
Thanks for the suggestion.
A good place to start is here:
https://en.wikipedia.org/wiki/Version_space_learning
Thank so much for great introduction!
I’m happy that it helped.
It is very clear and helpful..
Thanks.
yes its really awesome
It’s a great tutorial on ML…
Thanks.
very useful article .I am beginner in Machine Learning.can you send me other article.
Thanks.
You can access all of the articles on the blog.
Thank you for the article.
Some remarks :
It could be interesting to add real life analogies / concrete examples to : terminology / the algorithm properties …
Typo at the end ? “patters” instead of “patterns” ?
Also some information in readers comments could be implemented in the article
Great suggestions, thanks.
Fixed the typo.
great article…
what are the statistical approach we use in machine clearing while modeling….
I mean suppose we have an data set,should we have an hypothesis to start with …what are the steps,it would be very helpful ,if you could throw some light on it…
No, instead we prototype and empirically discover what algorithm works best for a given dataset.
You can learn more here:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
This is a very nice summary, Jason, thank you for sharing.
Some additional topics that seem worthy of mention here:
1. Generalization — the objective of a predictive model is to predict well on new data that the model has never seen, not to “fit” the data we already have.
2. Model validation – how to assess model performance; dividing data into training, validation, and test sets; cross-validation; avoiding data snooping, selection bias, survivorship bias, look-ahead bias, and more. In my experience, model validation is one of the most challenging aspects of ML (and to do it well may vastly increase the challenges in constructing and managing your datasets)
3. Bias / variance tradeoff — importance of balancing overfitting (high variance, complex models) and underfitting (high bias, simple models); the more complex the model, the more data that is required to avoid overfitting; deep learning models require vastly more labeled data than traditional (simpler) ML models
4. Curse of dimensionality — as you increase the number of predictors (independent variables), you need exponentially more data to avoid underfitting; dimensionality reduction techniques
5. Feature engineering — related to domain expertise and data preparation; with good domain experts, you can often construct features that perform vastly better than the raw data.
Ok, that’s more than enough. I started my reply intending to mention only generalization and validation … This is such a rich topic! Hope this helps. Thanks again for your great work.
Great topics, thanks!
Could you explain the types of error functions used in machine learning systems
Good question, see this post:
https://machinelearningmastery.com/loss-and-loss-functions-for-training-deep-learning-neural-networks/
Hi Jason, this article was very helpful to me but i am beginnner in this feild and i dont even know prgramming please help me out
You can get started in machine learning without programming using Weka:
https://machinelearningmastery.com/start-here/#weka
Thank you for the article. please can u send me some references about induction learning I needed so badly….
Start here:
https://en.wikipedia.org/wiki/Inductive_reasoning
Hi Jason. I enjoyed your article, thanks for writing. I also wrote an article on machine learning that is geared towards beginners at youcodetoo.com. Let me know what you think!
Thanks.
HI Jason.thanks for this article,and more clear about machine learning with example?
You’re welcome.
Very good overview for a beginner. Would you like to share some most commonly asked interview questions on ML? Thanks
Thanks for the suggestion.
Sorry, I don’t know about interview questions. I’m an expert in using applied ML to solve problems, not job interviews.
Very detailed and informative in a single page
Thanks!
There is a typo under “The Essence of Inductive Learning”. The first paragraph has “de” instead of “be”.
Thanks, fixed!
HI, Jason.thanks for this great article. do I need a strong statistical and algebra knowledge if I want to start learning ML?
Good question, no, see this:
https://machinelearningmastery.com/faq/single-faq/what-mathematical-background-do-i-need-for-machine-learning
Machine learning is the coolest field to build a better career. I was looking for some point which help me to become a machine learning. After reading your blog every picture become clear in my mind. Now I can design my career path. Thank you for best career advice. Your blog have fabulous information.
Wow, this is my first reading on Machine Learning! And I am seriously delving into it. A great introduction of a subject. Will seek your guide as I walk in the new world. Thanks
Hi Odipo…Thank you for your feedback and support! A great starting point for your machine learning journey can be found here:
https://machinelearningmastery.com/start-here/