A foundation in statistics is required to be effective as a machine learning practitioner.
The book “All of Statistics” was written specifically to provide a foundation in probability and statistics for computer science undergraduates that may have an interest in data mining and machine learning. As such, it is often recommended as a book to machine learning practitioners interested in expanding their understanding of statistics.
In this post, you will discover the book “All of Statistics”, the topics it covers, and a reading list intended for machine learning practitioners.
After reading this post, you will know:
- Larry Wasserman wrote “All of Statistics” to quickly bring computer science students up to speed with probability and statistics.
- The book provides a broad coverage of the field of statistics with a focus on the mathematical presentation of the topics covered.
- The book covers much more than is required by machine learning practitioners, but a select reading of topics will be helpful for those that prefer a mathematical treatment.
Kick-start your project with my new book Statistics for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

All of Statistics for Machine Learning
Photo by Chris Sorge, some rights reserved.
All of Statistics
The book “All of Statistics: A Concise Course in Statistical Inference” was written by Larry Wasserman and released in 2004.

All of Statistics
Wasserman is a professor of statistics and data science at Carnegie Mellon University.
The book is ambitious.
It seeks to quickly bring computer science students up-to-speed with probability and statistics. As such, the topics covered by the book are very broad, perhaps broader than the average introductory textbooks.
Taken literally, the title “All of Statistics” is an exaggeration. But in spirit, the title is apt, as the book does cover a much broader range of topics than a typical introductory book on mathematical statistics. This book is for people who want to learn probability and statistics quickly.
— Page vii, All of Statistics: A Concise Course in Statistical Inference, 2004.
The book is not for the average practitioner; it is intended for computer science undergraduate students. It does assume some prior knowledge in calculus and linear algebra. If you don’t like equations or mathematical notation, this book is not for you.
Interestingly, Wasserman wrote the book in response to the rise of data mining and machine learning in computer science occurring outside of classical statistics. He asserts in the preface the importance of having a grounding in statistics in order to be effective in machine learning.
Using fancy tools like neural nets, boosting, and support vector machines without understanding basic statistics is like doing brain surgery before knowing how to use a band-aid.
— Pages vii-viii, All of Statistics: A Concise Course in Statistical Inference, 2004.
The material is presented in a very clear and concise manner. A systematic approach is taken with brief descriptions of a method, equations describing its implementation, and worked examples to motivate the use of the method with sample code in R.
In fact, the material is so compact that it often reads like a series of encyclopedia examples. This is great if you want to know how to implement a method, but very challenging if you are new to the methods and seeking intuitions.
Need help with Statistics for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Review of Contents
The choice of topics covered by the book is very broad, as mentioned in the previous section.
This is great on the one hand as the reader is given exposure to advanced subjects early on. The downside of this aggressive scope is that topics are touched on briefly with very little hand holding. You are left to re-read sections until you get it.
Let’s look at the topics covered by the book.
This is helpful to both get an idea of the presented scope of the field and the context for the topics that may interest you as a machine learning practitioner.
The book is divided into three parts; they are:
- I Probability
- II Statistical Inference
- III Statistical Models and Methods
The first part of the book focuses on probability theory and formal language for describing uncertainty. The second part is focused on statistical inference. The third part focuses on specific methods and problems raised in the second part.
The book does have a reference or encyclopedia feeling. As such, there are a lot of chapters, but each chapter is reasonably standalone. The book is divided into 24 chapters; they are:
- Chapter 1: Probability
- Chapter 2: Random Variables
- Chapter 3: Expectation
- Chapter 4: Inequalities
- Chapter 5: Convergence of Random Variables
- Chapter 6: Models, Statistical Inference and Learning
- Chapter 7: Estimating the CDF and Statistical Functions
- Chapter 8: The Bootstrap
- Chapter 9: Parametric Inference
- Chapter 10: Hypothesis Testing and p-values
- Chapter 11: Bayesian Inference
- Chapter 12: Statistical Decision Theory
- Chapter 13: Linear and Logistic Regression
- Chapter 14: Multivariate Models
- Chapter 15: Inference About Independence
- Chapter 16: Causal Inference
- Chapter 17: Directed Graphs and Conditional Independence
- Chapter 18: Undirected Graphs
- Chapter 19: Log-Linear Models
- Chapter 20: Nonparametric Curve Estimation
- Chapter 21: Smoothing Using Orthogonal Functions
- Chapter 22: Classification
- Chapter 23: Probability Redux: Stochastic Processes
Chapter 24: Simulation Methods
The preface for the book provides a useful glossary of terms mapping them from statistics to computer science. This “Statistics/Data Mining Dictionary” is reproduced below.
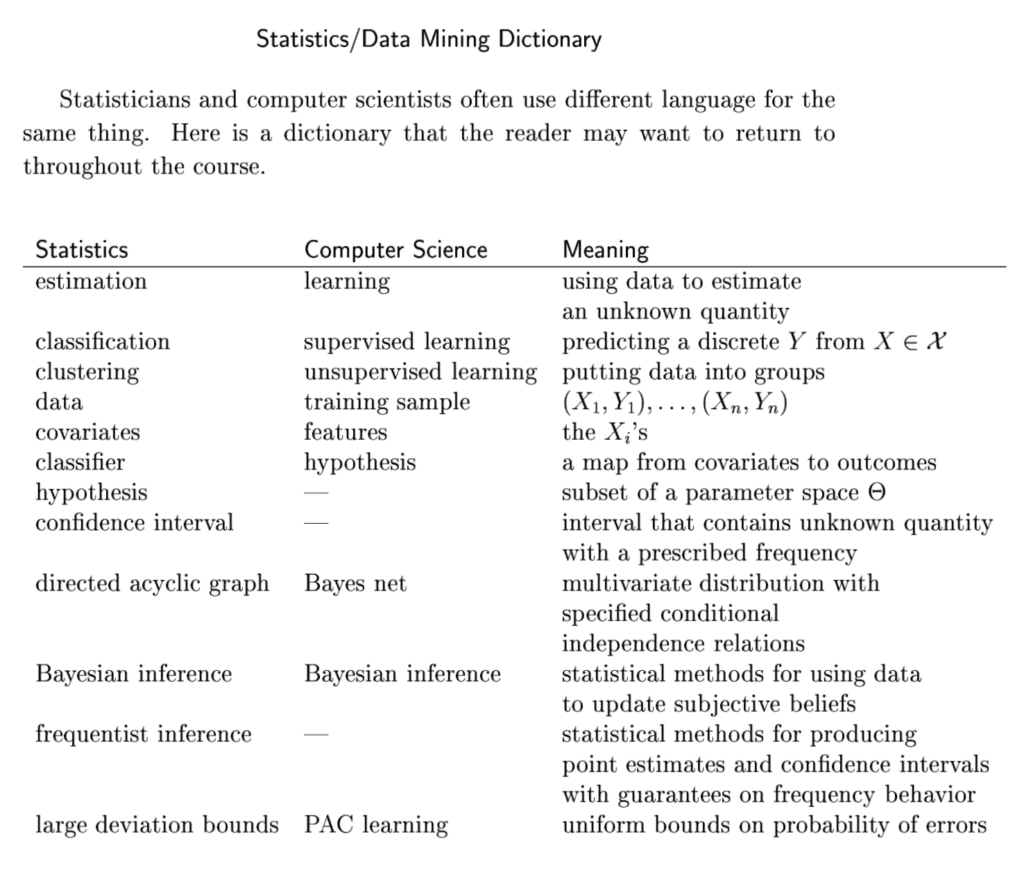
Statistics/Data Mining Dictionary
Taken from “All of Statistics“.
All of the R code and datasets used in the worked examples in the book are available from Wasserman’s homepage. This is very helpful as you can focus on experimenting with the examples rather than typing in the code and hoping that you got the syntax correct.
Reading List for Machine Learning
I would not recommend this book to developers who have not touched statistics before. It’s too challenging.
I would recommend this book to computer science students who are in math-learning-mode. I would also recommend it to machine learning practitioners with some previous background in statistics or a strong mathematical foundation.
If you are comfortable with mathematical notation and you know what you’re looking for, this book is an excellent reference. You can flip to the topic or the method and get a crisp presentation.
The problem is, for a machine learning practitioner, you do need to know about many of these topics, just not at the level of detail presented. Perhaps a shade lighter, at the intuition level. If you are up to it, it would be worth reading (or skimming) the following chapters in order to build a solid foundation in probability for statistics:
- Chapter 1: Probability
- Chapter 2: Random Variables
- Chapter 3: Expectation
- Chapter 5: Convergence of Random Variables
Again, these are important topics, but you require a concept-level understanding only.
For coverage of statistical hypothesis tests that you may use to interpret data and compare the skill of models, the following chapters are recommended reading:
- Chapter 6: Models, Statistical Inference and Learning
- Chapter 9: Parametric Inference
- Chapter 10: Hypothesis Testing and p-values
I would also recommend the chapter on the Bootstrap. It’s just a great method to have in your head, but with a focus for either better understanding bagging and random forest or as a procedure for estimating confidence intervals of model skill.
- Chapter 8: The Bootstrap
Finally, a statistical approach is used to present machine learning algorithms. I would recommend these chapters if you prefer a more mathematical treatment of regression and classification algorithms:
- Chapter 12: Statistical Decision Theory
- Chapter 13: Linear and Logistic Regression
- Chapter 22: Classification
I can read the mathematical presentation of statistics, but I prefer intuitions and working code. I am less likely to pick up this book from my bookcase, in favor of gentler treatments such as “Statistics in Plain English” or application focused treatments such as “Empirical Methods for Artificial Intelligence“.
Do you agree with this reading list?
Let me know in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- All of Statistics: A Concise Course in Statistical Inference, 2004.
- All of Statistics Errata
- Larry Wasserman Homepage
Summary
In this post, you discovered the book “All of Statistics” that provides a broad and concise introduction to statistics.
Specifically, you learned:
- Larry Wasserman wrote “All of Statistics” to quickly bring computer science students up to speed with probability and statistics.
- The book provides a broad coverage of the field of statistics with a focus on the mathematical presentation of the topics covered.
- The book covers much more than is required by machine learning practitioners, but a select reading of topics will be helpful for those that prefer a mathematical treatment.
Have you read this book?
What did you think of it? Let me know in the comments below.
Are you thinking of picking up a copy of this book?
Let me know in the comments.
Get a Handle on Statistics for Machine Learning!

Develop a working understanding of statistics
...by writing lines of code in python
Discover how in my new Ebook:
Statistical Methods for Machine Learning
It provides self-study tutorials on topics like:
Hypothesis Tests, Correlation, Nonparametric Stats, Resampling, and much more...
Discover how to Transform Data into Knowledge
Skip the Academics. Just Results.


")



Hey! great article!
The post is informative and the topic is discussed is really good keep on sharing new things.
Thanks.
Hi Jason
Your articles are very useful. Would please post an article about Quasi Experiment.
Thanks for the suggestion.
Nice job Jason,
Using stat and probability is eventual core for data application, machine learning and AI. And this in line for such paving requirement.
Thanks.
Nice review, Jason.
As someone who came to the area later in life (read: as an applied package monkey) I find this book refreshing, enjoyable, rigorous and best of all, easy to go over. It’s all out there in it’s most distilled form. No fluff.
It really does what if promises, of introducing so many different concepts in a way that engages the reader without throwing them off.
I also very much enjoy working through Casella and Berger, but that book is a much longer term effort.
The point regarding intuitions is also well made, in that one can pick up a book like ESL or Murphy for the reasoning behind the methods. But for some reason I just couldn’t relate to ESL the first time round (that has changed now) because it felt strange to look at mathematical objects like expectations without having played with them properly.
Thanks for sharing.
Agreed. A foundation in stats, probability and linalg is required before reading ESL, Murphy or most ML textbooks!
Hey, I want to consult, if I bought all your e-books, then if I am not satisfied, can I get a full refund ($337), how can I contact you? I don’t seem to see your email.
Yes. You can use the “contact” page:
https://machinelearningmastery.com/contact/
I am a graduate student in Master of Data Science (studying Actuarial Science in my undergraduate study). I am currently reading this book and just discovered this article. I would say this book is fantastic for one with some foundation in statistics. It brings you to revisit some fundamental topics in greater depth. Even though the topics it covers are mostly taught in my introductory statistics class, I learned a bunch of new insights from this book. In addition, its supplementary exercises are definitely a top-up. They are stimulating!
P.S. To document my study of this book, I made a repo in Github. Check it out: https://github.com/riven314/All_of_Statistics_Exercises
Well done!