In this article, you will learn how AI agent memory works across working memory, external memory, and scalable memory architectures for building agents that improve over time.
Topics we will cover include:
- The memory problem in stateless large language model-based agents.
- How in-context, episodic, semantic, and procedural memory support agent behavior.
- How retrieval, memory writing, decay handling, and multi-agent consistency make memory work at scale.
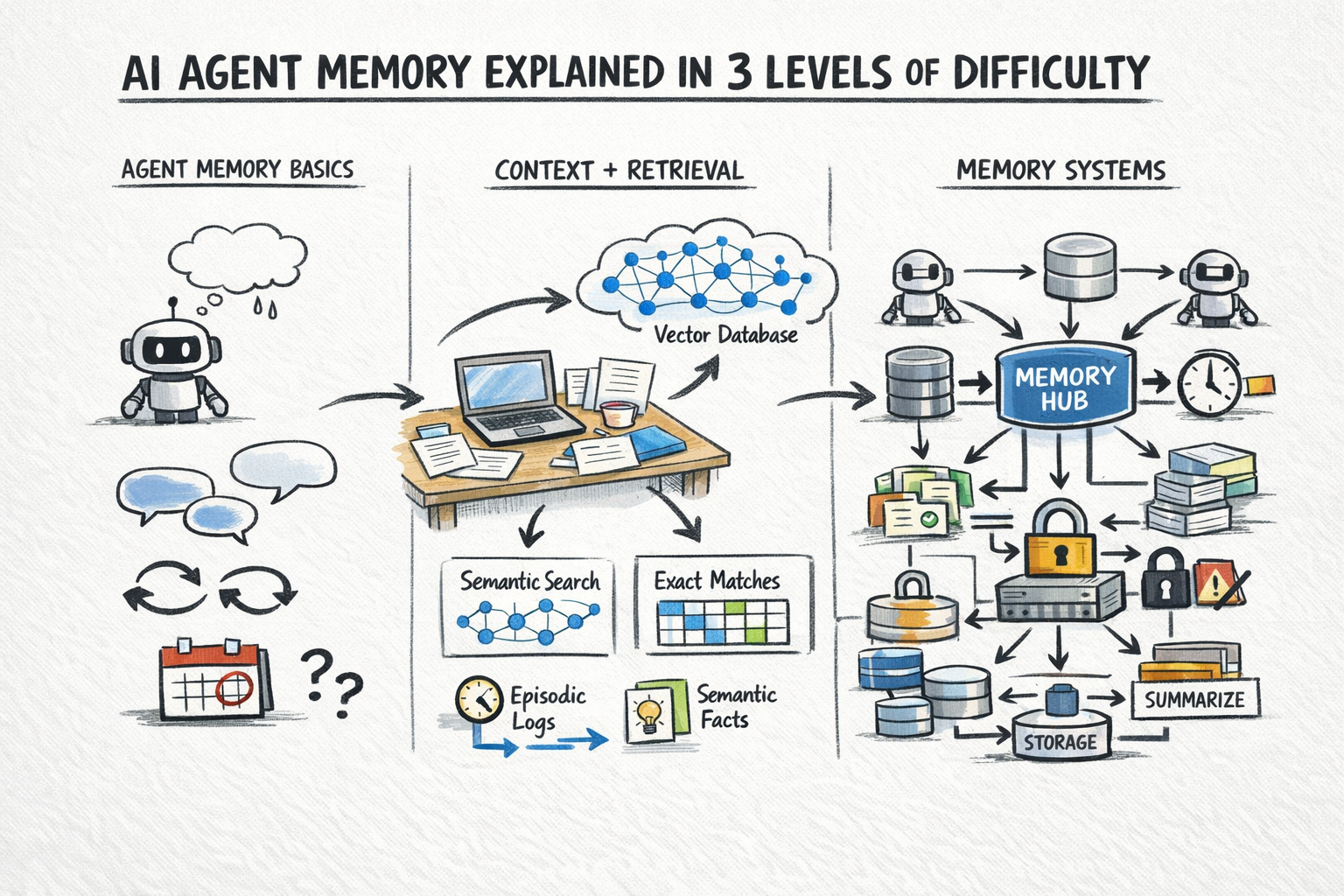
AI Agent Memory Explained in 3 Levels of Difficulty
Image by Author
Introduction
A stateless AI agent has no memory of previous calls. Every request starts from scratch. This works fine for isolated tasks, but it becomes a problem when an agent needs to track decisions, remember user preferences, or pick up where it left off.
The challenge is that memory in AI agents is a collection of different mechanisms that serve different purposes. These mechanisms also operate at different timescales — some are scoped to a single conversation, while others persist indefinitely. How you combine them determines whether your agent stays useful across sessions.
This article explains AI agent memory at three levels: what memory means for an agent and why it is hard, how the main memory types work in practice, and finally, the architectural patterns and retrieval strategies that make persistent, reliable memory work at scale.
Level 1: Understanding The Memory Problem In AI Agents
A large language model has no persistent state. Every call to the API is stateless: the model receives a block of text, or context window, processes it, returns a response, and retains nothing. There is no internal store being updated between calls.
This is fine for answering a one-off question. It is a fundamental problem for anything agent-like: a system that takes multi-step actions, learns from feedback, or coordinates work across many sessions.
The following four questions make the memory problem concrete:
- What happened before? An agent that books calendar events needs to know what is already scheduled. If it does not remember, it double-books.
- What does this user want? A writing assistant that does not remember your preferred tone and style resets to generic behavior every session.
- What has the agent already tried? A research agent that does not remember failed search queries will repeat the same dead ends.
- What facts has the agent accumulated? An agent that discovers mid-task that a file is missing needs to record that and factor it into future steps.
The memory problem is the problem of giving an inherently stateless system the ability to behave as if it has persistent, queryable knowledge about the past.
Level 2: The Types Of Agent Memory
In-Context Memory Or Working Memory
The simplest form: everything in the context window right now. The conversation history, tool call results, system prompt, relevant documents — all of it gets passed to the model as text on every call.
This is exact and immediate. The model can reason over anything in context with high fidelity. There is no retrieval step, no approximation, and no chance of pulling the wrong record. The constraint is context window size. Current models support 128K to 1M tokens, but costs and latency scale with length, so you cannot simply dump everything in and call it done.
In practice, in-context memory works best for the active state of a task: the current conversation, recent tool outputs, and documents directly relevant to the immediate step.
External Memory
For information too large, too old, or too dynamic to keep in context at all times, agents query an external store and pull in what is relevant when needed. This is retrieval-augmented generation (RAG) applied to agent memory.
Two retrieval patterns serve different needs:
Semantic search over a vector database finds records similar in meaning to the current query.
Exact lookup against a relational or key-value store retrieves structured facts by attribute — user preferences, task state, prior decisions, and entity records.
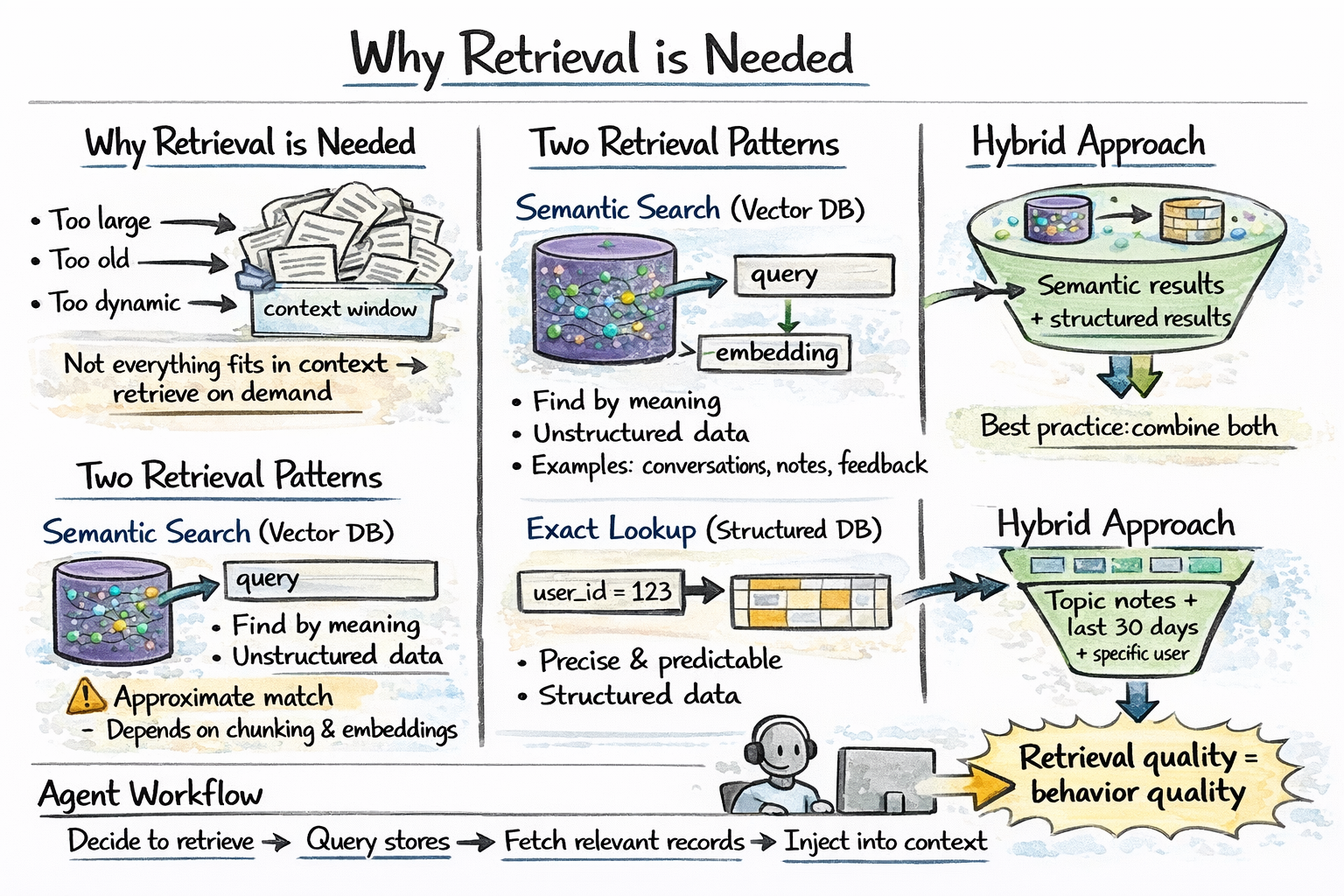
Agent memory retrieval step
In practice, the most robust agent memory systems use both in combination: run a vector search and a structured query as needed, then merge the results.
Level 3 focuses on making memory systems work in real-world production. It goes beyond basic memory types and tackles practical challenges: how to structure memory more granularly, what information to store and when, how to reliably retrieve the right data at scale, and how to handle issues like stale data or multiple agents writing to the same system.
In short, it’s about the architecture and strategies that ensure memory actually improves an agent’s performance.
Level 3: AI Agent Memory Architecture At Scale
What Needs To Be Stored
Not all information deserves the same treatment, and it’s worth being precise about what you’re actually storing. Agent memory naturally falls into a few categories:
Episodic memory captures what happened: specific events, tool calls, and their outcomes.
Semantic memory captures what is true: facts and preferences extracted from experience.
Procedural memory captures how to do things. It encodes learned action patterns, successful strategies, and known failure modes.
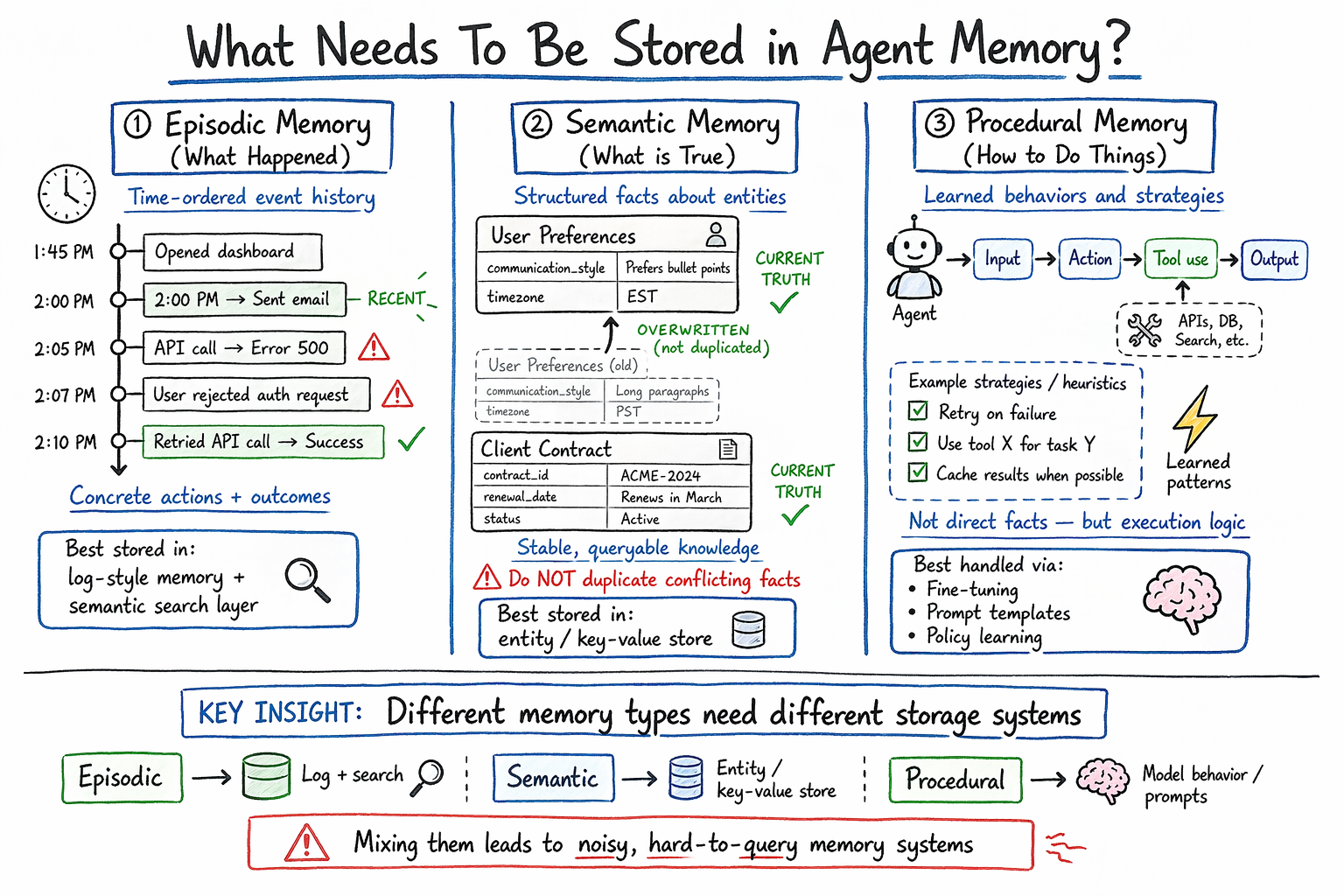
An overview of AI agent memory types
Writing To Memory: When And What To Store
An agent that writes every token of every interaction to memory produces noise at scale. Memory has to be selective. The following are two common patterns:
End-of-session summarization: After each session, the agent or a dedicated summarization step extracts salient facts, decisions, and outcomes and writes them as compact memory records.
Event-triggered writes: Certain events explicitly trigger memory writes — user corrections, explicit preference statements, task completions, and error conditions.
What not to store: raw transcripts at scale, intermediate reasoning traces that do not affect future behavior, or redundant duplicates of existing records.
Retrieving From Memory: Getting The Right Context
Here is an overview of the three main retrieval strategies:
Vector similarity search queries the memory store with an embedding of the current context and returns the top-K most semantically similar records. This is fast, approximate, and works well for unstructured memory. It also requires an embedding model and a vector index like HNSW or IVF-based. Quality depends on chunking strategy and embedding model.
Structured query retrieves facts by attribute — user ID, time range, entity name. Precise when you know what you’re looking for. This doesn’t handle semantic drift. Works with SQL or key-value lookups.
Hybrid retrieval combines both: run a vector search and a structured query in parallel and merge the results. Useful when memories have both semantic content and structured metadata, like finding memories about billing issues from the last 30 days for this user.
Memory Decay And Versioning
Memories become stale. A user’s job title changes. A previously correct API endpoint gets deprecated. An agent that surfaces outdated memories causes errors downstream. You need some ways to handle it, and here are the most relevant:
Temporal decay: Weight recent memories more heavily than old ones.
Versioned entity records: Maintain a versioned entity store so updates overwrite prior values with timestamps.
Multi-Agent Memory
When multiple agents share memory — a coordinator and several subagents working in parallel — consistency becomes the hard problem. Here are common approaches:
- Central memory: Use locking or optimistic concurrency to control writes
- Namespaces: Each agent writes to its own memory space
- Append-only logs: Store all changes and resolve conflicts at read time
There’s no single best solution; it depends on how agents run and share state. Read Why Multi-Agent Systems Need Memory Engineering to learn more.
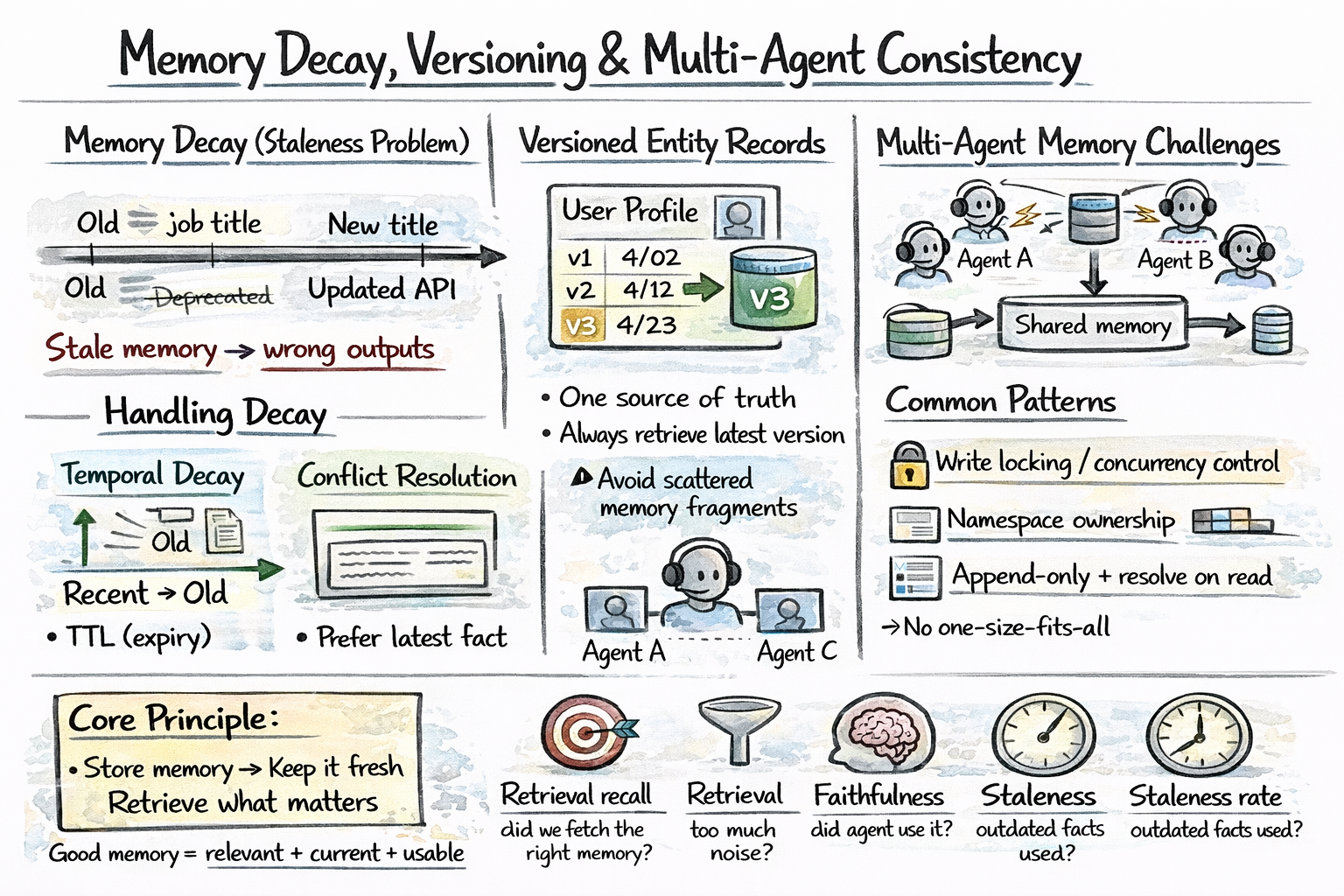
Memory decay, versioning, and multi-agent consistency
Evaluation
Memory systems often fail silently. The agent retrieves something wrong, reasons from it, and produces a plausible-sounding wrong answer. Here are some metrics worth tracking:
- Retrieval recall measures whether the system surfaces relevant memory when it exists.
- Retrieval precision measures whether it also pulls in noise.
- Faithfulness measures whether the agent uses retrieved memory in its reasoning.
- Staleness rate measures how often the agent surfaces an outdated fact.
Effective memory management, in essence, is all about storing information while keeping it relevant and retrievable.
Wrapping Up
Agent memory functions like a stack. In-context memory maintains current working state, while external retrieval brings in relevant history and facts. The engineering challenge lies in determining what to record, when to trigger retrieval, and how to maintain a clean, useful memory as it grows.
Here are a few resources for further learning:
- Building Memory-Aware Agents
- Making Sense of Memory in AI Agents
- 7 Steps to Mastering Memory in Agentic AI Systems
Happy learning and building!






No comments yet.