Where can you get good datasets to practice machine learning?
Datasets that are real-world so that they are interesting and relevant, although small enough for you to review in Excel and work through on your desktop.
In this post you will discover a database of high-quality, real-world, and well understood machine learning datasets that you can use to practice applied machine learning.
This database is called the UCI machine learning repository and you can use it to structure a self-study program and build a solid foundation in machine learning.
Practice Practice Practice Photo by Phil Roeder, some rights reserved.
Why Do We Need Practice Datasets?
If you are interested in practicing applied machine learning, you need datasets on which to practice.
This problem can stop you dead.
Which dataset should you use?
Should you collect your own or use one off the shelf?
I teach that the best way to get started is to practice on datasets that have specific traits.
I recommend you select traits that you will encounter and need to address when you start working on problems of your own such as:
Different types of supervised learning such as classification and regression.
Different sized datasets from tens, hundreds, thousands and millions of instances.
Different numbers of attributes from less than ten, tens, hundreds and thousands of attributes
Different attribute types from real, integer, categorical, ordinal and mixtures
Different domains that force you to quickly understand and characterize a new problem in which you have no previous experience.
You can create a program of traits to study and learn about and the algorithm you need to address them, by designing a program of test problem datasets to work through.
Such a program has a number of practical requirements, for example:
Real-World: The datasets should be drawn from the real world (rather than being contrived). This will keep them interesting and introduce the challenges that come with real data.
Small: The datasets need to be small so that you can inspect and understand them and that you can run many models quickly to accelerate your learning cycle.
Well-Understood: There should be a clear idea of what the data contains, why it was collected, what the problem is that needs to be solved so that you can frame your investigation.
Baseline: It is also important to have an idea of what algorithms are known to perform well and the scores they achieved so that you have a useful point of comparison. This is important when you are getting started and learning because you need quick feedback as to how well you are performing (close to state-of-the-art or something is broken).
Plentiful: You need many datasets to choose from, both to satisfy the traits you would like to investigate and (if possible) your natural curiosity and interests.
For beginners, you can get everything you need and more in terms of datasets to practice on from the UCI Machine Learning Repository.
For more than 25 years it has been the go-to place for machine learning researchers and machine learning practitioners that need a dataset.
UCI Machine Learning Repository
Each dataset gets its own webpage that lists all the details known about it including any relevant publications that investigate it. The datasets themselves can be downloaded as ASCII files, often the useful CSV format.
For example, here is the webpage for the Abalone Data Set that requires the prediction of the age of abalone from their physical measurements.
Benefits of the Repository
Some beneficial features of the library include:
Almost all datasets are drawn from the domain (as opposed to being synthetic), meaning that they have real-world qualities.
Datasets cover a wide range of subject matter from biology to particle physics.
The details of datasets are summarized by aspects like attribute types, number of instances, number of attributes and year published that can be sorted and searched.
Datasets are well studied which means that they are well known in terms of interesting properties and expected “good” results. This can provide a useful baseline for comparison.
Most datasets are small (hundreds to thousands of instances) meaning that you can readily load them in a text editor or MS Excel and review them, you can also easily model them quickly on your workstation.
Browse the 300+ datasets using this handy table that supports sorting and searching.
Criticisms of the Repository
Some criticisms of the repository include:
The datasets are cleaned, meaning that the researchers that prepared them have often already performed some pre-processing in terms of the the selection of attributes and instances.
The datasets are small, this is not helpful if you are interested in investigating larger scale problems and techniques.
There are so many to choose from that you can be frozen by indecision and over-analysis. It can be hard to just pick a dataset and get started when you are unsure if it is a “good dataset” for what you’re investigating.
Datasets are limited to tabular data, primarily for classification (although clustering and regression datasets are listed). This is limiting for those interested in natural language, computer vision, recommender and other data.
Take a look at the repository homepage as it shows featured datasets, the newest datasets as well as which datasets are currently the most popular.
A Self-Study Program
So, how can you make the best use of the UCI machine learning repository?
I would advise you to think about the traits in problem datasets that you would like to learn about.
These may be traits that you would like to model (like regression), or algorithms that model these traits that you would like to get more skillful at using (like random forest for multi-class classification).
This is just a list of traits, can pick and choose your own traits to investigate.
I have listed one dataset for each trait, but you could pick 2-3 different datasets and complete a few small projects to improve your understanding and put in more practice.
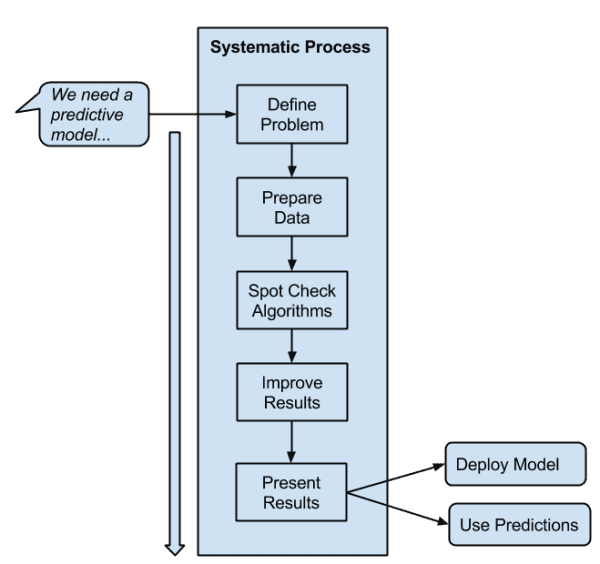
For each problem, I would advise that you work it systematically from end-to-end, for example, go through the following steps in the applied machine learning process:
Define the problem
Prepare data
Evaluate algorithms
Improve results
Write-up results
Select a systematic and repeatable process that you can use to deliver results consistently.
It allows you to build up a portfolio of projects that you refer back to as a reference on future projects and get a jump-start, as well as use as a public resume or your growing skills and capabilities in applied machine learning.
I don’t know a machine learning tool.
Pick a tool or platform (like Weka, R or scikit-learn) and use this process to learn a tool. Cover off both practicing machine learning and getting good at your tool at the same time.
I don’t know how to program (or code very well). Use Weka. It has a graphical user interface and no programming is required. I would recommend this to beginners regardless of whether they can program or not because the process of working machine learning problems maps so well onto the platform.
I don’t have the time.
With a strong systematic process and a good tool that covers the whole process, I think that you could work through a problem in one-or-two hours. This means you could complete one project in an evening or over two evenings.
You choose the level of detail to investigate and it is a good idea to keep it light and simple when just starting out.
I don’t have a background in the domain I’m modeling.
The dataset pages provide some background on the dataset. Often you can dive deeper by looking at publications or the information files accompanying the main dataset.
I have little to no experience working through machine learning problems.
Now is your time to start. Pick a systematic process, pick a simple dataset and a tool like Weka and work through your first problem. Place that first stone in your machine learning foundation.
I have no experience at data analysis.
No experience in data analysis is required. The datasets are simple, easy to understand and well explained. You simply need to read up on them using the data sets home page and by looking at the data files themselves.
Action Step
Select a dataset and get started.
If you are serious about your self-study, consider designing a modest list of traits and corresponding datasets to investigate.
You will learn a lot and build a valuable foundation for diving into more complex and interesting problems.
Did you find this post useful? Leave a comment and let me know.
Hi Jason,
Thank you for this great post. I just began my study of data analysis and was totally confused when to began doing projects. This post is truly enlightening.
You mention something that is confusing… “For example, here is the webpage for the Abalone Data Set that requires the prediction of the age of abalone from their physical measurements.”
Why do you use the word “requires”? The webpage requires… Or the dataset requires? No. Confuses.
Wouldn’t this make more sense…”The dataset provides content to the learning machine to predict the age of an Abalone from physical measurements.”
I have a question for example dataset wine quality:
how should I look at data?
I’ve opened the data and I can see that density and resuidal sugar are higly corelated. But what now? I should try to draw a plot for each feature? (e.g plot(x1,quality) plot(x2,quality) and so on?
Could you give some advice what steps should be taken?
Hey Jason, this is really nicely broken down into steps. I always felt that I get too involved into the problems that I miss the big picture but I think keeping a process and working through it is a good way to approach learning. And I am definitely looking forward to practising like you suggest. Thanks!
How do you handle the datasets not seeming to have any benchmarks for what a poor, fair, or good accuracy is for prediction? If I pick some binary classification dataset to practice on and get say, an ROC = 0.6, how am I to know if that’s a fantastic result or there’s still a lot of improving I could do with respect to how others have done?
The answer is to use ZeroR or similar to baseline the problem and determine the point from which all other results can be compared. After you run through a suite of good standard algorithms you will get a feel for what result is “easy” to achieve, providing a new baseline from which to improve.
From there, interpretation of results is problem specific.
Hello Jason,
Thanks for your post, it is very helpful. But I have one question, which is how to validate your results or your implemented algorithms? How to compare our results with a better one?
You can evaluate the performance of your models by estimating their performance on unseen data. You can do this with resampling methods like k-fold cross validation.
You can then compare the skill of multiple algorithms on the problem.
You can compare to previously published results by re-creating their test setup.
Thank you for this refreshing article, Jason! Although your explanations are simple, they are deep and very well thought at the same time. I am learning a lot from your writings.
Once again, thank you for sharing your wisdom and knowledge with us.
Thanks for excellent stuff on ML.
I really get my ideas clear just by yoir posts.
I got my current assignmen to compair at least four pricelists and to suggest the final prices list for our company.please suggest the suitable algorithm for the same.
I wish i could be in regular touch with you bacause i want to be a REAL good Data Scientist and you REALLY know the path which can lead one there.
This website is the best source for learning machine learning.
Hello sir,
Thank you for such a nice information, it is very simple to understand. As a student of M Sc (Statistics), i m looking for project in data mining, can you suggest something?
Thanks for your articles. I have recently started reading your page and articles. I am a practicing analyst who enjoys to play around data, what I lack is systematic approach to implementation of algorithms, I know them theoretically but don’t have the confidence on implementing them. I have also joined mailing subscription from your website and also reading your number of articles to start working with a plan. I generally get lost and overwhelmed in my learning process and hence leave it between. Would request you to help me on how can I keep my learning process productive.
Thank you for your posts which are so helpful to me.
Regarding the datsets from UCI repository, I’m wondering how I get csv format. Because I found that the files there are with extension .data, not .csv.
Wish I have this in my early time when I was starting with Data Science. Practice is the key for sure reading soo many books will give you knowledge about the process but in one or two directions. Its practice which gives you the exposure for real life scenarios.
Thank you for your help,
as it may be a reason to give hope to non-specialists like me to start again after many failed attempts. i am grateful for all helpful like you
Thanks for your great work. It has improved my ML knowledge and increased my interest. I was wondering if there are other ML repository you know of, specially, the ones that have raw datasets- just for the sake of working on my data cleaning/pre-processing skills?
You made me feel that coding is not big deal as everybody exaggerates it. I have started using R programming only because of you. Thanks for the confidence.
Sir, your work is greatly appreciated, kindly clear me at a point i want to detect a plant/fruit diseases system, will it be better for me to use the existing datasets or to prepare my own. thanks and regards




")




dear Jason,
You are the best teacher.because you make simple things.
Thanks hossein!
Awesome post for any newbies in Data Science, really appreciate the work.
Thanks!
Thank you so much Sir Jason.I am surely looking forward to pracitsing like you suggest
You’re welcome.
Hi Jason,
Thank you for this great post. I just began my study of data analysis and was totally confused when to began doing projects. This post is truly enlightening.
You mention something that is confusing… “For example, here is the webpage for the Abalone Data Set that requires the prediction of the age of abalone from their physical measurements.”
Why do you use the word “requires”? The webpage requires… Or the dataset requires? No. Confuses.
Wouldn’t this make more sense…”The dataset provides content to the learning machine to predict the age of an Abalone from physical measurements.”
I can say it is a one stop solution for Machine Learning Problem.
Thank you very much Jason ,You make my life easy….. 🙂
You’re very welcome.
Hi, could you recommend me one or a few data sets on computer system resources usage just for the purpose of machine learning ?
Thanks in advance.
Hi Jason,
I have a question for example dataset wine quality:
how should I look at data?
I’ve opened the data and I can see that density and resuidal sugar are higly corelated. But what now? I should try to draw a plot for each feature? (e.g plot(x1,quality) plot(x2,quality) and so on?
Could you give some advice what steps should be taken?
Regards,
Adam
Hi Adam, take a look at this process for working through an applied machine learning problem:
https://machinelearningmastery.com/process-for-working-through-machine-learning-problems/
Exactly what I was searching for, thank you so much!
You’re welcome Elton.
As a naive programmer, recently graduate from Clg, your posts is what I looking for.
Thank.
Glad to hear it!
Hey Jason, this is really nicely broken down into steps. I always felt that I get too involved into the problems that I miss the big picture but I think keeping a process and working through it is a good way to approach learning. And I am definitely looking forward to practising like you suggest. Thanks!
I’m glad it was useful to you Sonal.
What a find! This is awesome beyond words, Jason; thank you!!!
You’re welcome kay.
Hey Jason,
Got a nice link flow is nice in simple words and detailed explanation.
Thanks
I’m glad it’s useful Kartik.
Hi Jason!
How do you handle the datasets not seeming to have any benchmarks for what a poor, fair, or good accuracy is for prediction? If I pick some binary classification dataset to practice on and get say, an ROC = 0.6, how am I to know if that’s a fantastic result or there’s still a lot of improving I could do with respect to how others have done?
Thanks
Great question!
The answer is to use ZeroR or similar to baseline the problem and determine the point from which all other results can be compared. After you run through a suite of good standard algorithms you will get a feel for what result is “easy” to achieve, providing a new baseline from which to improve.
From there, interpretation of results is problem specific.
This post is really good for beginners sir,thank you
I’m glad to hear it almas.
Hello Jason,
Thanks for your post, it is very helpful. But I have one question, which is how to validate your results or your implemented algorithms? How to compare our results with a better one?
Thanks.
Hi LinboLee, good questions.
You can evaluate the performance of your models by estimating their performance on unseen data. You can do this with resampling methods like k-fold cross validation.
You can then compare the skill of multiple algorithms on the problem.
You can compare to previously published results by re-creating their test setup.
I think I get the point for how to learn machine learning. Thank you.
I’m glad to hear that.
Thanks for such a freat article, You are working great,
Sir!
Thanks Priyank.
Thank you so much Dr Jason Brownlee
I’m glad it helped.
Very good article, as always you can articulate the theoretical and practical issues in predictive modeling.
I also recommend kaggle data sets. They are also free, have big and small data sets.
Great suggestion.
Thank you for this refreshing article, Jason! Although your explanations are simple, they are deep and very well thought at the same time. I am learning a lot from your writings.
Once again, thank you for sharing your wisdom and knowledge with us.
Thanks Francisco, kind of you to say. Hang in there!
How are you you can add this mine of good and open data sets http://www.andbrain.com/
Thanks for sharing.
You are awesome Jason. I have been looking for such a map for a long time! Thank you so much.
I’m glad it helped.
that is a valuable word you are really motivating me to work hard to know everything about Machine Learning.
I’m really glad to hear that!
Thanks a lot Jason for providing invaluable information about Machine Learning.
I’m glad it helped.
awesome sir ,really a good one.Thank you
I’m glad it helped.
Just want to say many thanks to you, Jason
Your articles really very helpful!
Thanks Vova, I really appreciate your support.
I love how you break down the types of machine learning problems. This is a great resource!
Thanks Shane.
Hi Jason
Thanks for excellent stuff on ML.
I really get my ideas clear just by yoir posts.
I got my current assignmen to compair at least four pricelists and to suggest the final prices list for our company.please suggest the suitable algorithm for the same.
See this post:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
Hi Jason,
Thanks for a great post.
Could you also advice on how to scrap data from UC Irvine database using R. It would be great to see a tutorial on that.
No need to scrape the dataset, you can download them directly as CSV files.
How can i prepare my own dataset? Can you suggest me the path?
Here Raw data may be either images or integer array or character array or strings.
I recommend this process:
https://machinelearningmastery.com/start-here/#process
Thank you for your support.
You’re welcome.
Hi Jason,
I want to prepare a white paper submission on Responsible AI or Ethical AI.Can you suggest any usecase or problem statement for it
No, sorry it is not my area of expertise.
I wish i could be in regular touch with you bacause i want to be a REAL good Data Scientist and you REALLY know the path which can lead one there.
This website is the best source for learning machine learning.
You are in touch with me, ask questions any time via comments or via the contact form.
My best advice is here:
https://machinelearningmastery.com/start-here/
The prima dataset is not avalilable now.
You can get it here:
https://github.com/jbrownlee/Datasets
hello sir
can you please guide me the data set for urban water supply
It is the default value. You can learn more about how to configure the model here:
https://radimrehurek.com/gensim/models/keyedvectors.html
how to download a dataset from UCI? just the usual way in Python and R ? is there a download link on the site ?
They have a download link and you can use a web browser.
Thank you so much for the article
I’m happy it helped.
Good post. I am in applied machine learning application. There is need to evaluate algorithms on good datasets.
Thanks.
thank you Jason. you have no idea of how helpful this is to me now. God bless
I’m glad it helps!
Hello sir,
Thank you for such a nice information, it is very simple to understand. As a student of M Sc (Statistics), i m looking for project in data mining, can you suggest something?
Thanks, perhaps experiment with some of these dataset.
Hi Jason,
Thanks for your articles. I have recently started reading your page and articles. I am a practicing analyst who enjoys to play around data, what I lack is systematic approach to implementation of algorithms, I know them theoretically but don’t have the confidence on implementing them. I have also joined mailing subscription from your website and also reading your number of articles to start working with a plan. I generally get lost and overwhelmed in my learning process and hence leave it between. Would request you to help me on how can I keep my learning process productive.
Try working through this tutorial:
https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
You are the best as usual professor jason
Thanks. I’m glad it helped.
where i can get plant disease dataset for machine learning, can anyone please suggest me..
This might help:
https://machinelearningmastery.com/faq/single-faq/where-can-i-get-a-dataset-on-___
how to read the uci data sets in excel?could anyone help!
See this tutorial:
https://machinelearningmastery.com/load-machine-learning-data-python/
after hovering around so many sites,i came here,the best i have ever visted for ML introductions…thanks so much Jason
Thanks!
Hi Jason Sir,
How do I get the csv file from the UCI repository…………i am getting a txt file that is getting opened by Notepad
PLz help fast
A CSV file is a text file.
Also, you can get the files here:
https://github.com/jbrownlee/Datasets
Hi, Jason.
Thank you for your posts which are so helpful to me.
Regarding the datsets from UCI repository, I’m wondering how I get csv format. Because I found that the files there are with extension .data, not .csv.
You might need to convert some to CSV format. Some might have .data extension and already have a CSV format.
Thanks Jason, it is a wonderful tutorial for me to start learning machine learning. It gives me confidence to continue the study.
Thanks, I’m happy to hear that.
Wish I have this in my early time when I was starting with Data Science. Practice is the key for sure reading soo many books will give you knowledge about the process but in one or two directions. Its practice which gives you the exposure for real life scenarios.
Thanks!
I agree.
Wonderfully explained…
Thanks Jason!!
Knowledge grows by sharing and you are already great in doing that.
Thanks!
This is the only site I often come back, and I think it simply shows how valuable the information you share is!
Thank you so much for spending time and putting lots of effort in doing this.
Thanks, you are very kind!
Awesome insights.
Now i have experiment with weka 😉
You’re welcome.
Thank you for your help,
as it may be a reason to give hope to non-specialists like me to start again after many failed attempts. i am grateful for all helpful like you
You’re welcome!
@Jason ,
Thanks for your great work. It has improved my ML knowledge and increased my interest. I was wondering if there are other ML repository you know of, specially, the ones that have raw datasets- just for the sake of working on my data cleaning/pre-processing skills?
Thanks!
Yes, see this:
https://machinelearningmastery.com/faq/single-faq/where-can-i-get-a-dataset-on-___
And this:
https://github.com/jbrownlee/Datasets
You made me feel that coding is not big deal as everybody exaggerates it. I have started using R programming only because of you. Thanks for the confidence.
Well done on your progress!
Yes, it’s not a big deal – just another tool for us to use to get a job done, like writing.
Much obliged to you for your posts which are so useful to me.
Concerning datsets from UCI vault, I’m considering how I get csv design. Since I found that the records there are with expansion .data, not .csv.
You can change the .data to .csv.
Also, Python does not care about the extension, only the content.
Thanks for the list of models with their classifications, makes it easier to start.
You’re welcome.
Thank you so much for the great sharing!
You’re welcome.
Sir, your work is greatly appreciated, kindly clear me at a point i want to detect a plant/fruit diseases system, will it be better for me to use the existing datasets or to prepare my own. thanks and regards
Hi Niaz…Existing datasets may be tremendous help along with transfer learning.
https://machinelearningmastery.com/how-to-improve-performance-with-transfer-learning-for-deep-learning-neural-networks/
Thanks and regards
You are very welcome K.Soumaia!