Computer Vision, often abbreviated as CV, is defined as a field of study that seeks to develop techniques to help computers “see” and understand the content of digital images such as photographs and videos.
The problem of computer vision appears simple because it is trivially solved by people, even very young children. Nevertheless, it largely remains an unsolved problem based both on the limited understanding of biological vision and because of the complexity of vision perception in a dynamic and nearly infinitely varying physical world.
In this post, you will discover a gentle introduction to the field of computer vision.
After reading this post, you will know:
- The goal of the field of computer vision and its distinctness from image processing.
- What makes the problem of computer vision challenging.
- Typical problems or tasks pursued in computer vision.
Kick-start your project with my new book Deep Learning for Computer Vision, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

A Gentle Introduction to Computer Vision
Photo by Axel Kristinsson, some rights reserved.
Overview
This tutorial is divided into four parts; they are:
- Desire for Computers to See
- What Is Computer Vision
- Challenge of Computer Vision
- Tasks in Computer Vision
Desire for Computers to See
We are awash in images.
Smartphones have cameras, and taking a photo or video and sharing it has never been easier, resulting in the incredible growth of modern social networks like Instagram.
YouTube might be the second largest search engine and hundreds of hours of video are uploaded every minute and billions of videos are watched every day.
The internet is comprised of text and images. It is relatively straightforward to index and search text, but in order to index and search images, algorithms need to know what the images contain. For the longest time, the content of images and video has remained opaque, best described using the meta descriptions provided by the person that uploaded them.
To get the most out of image data, we need computers to “see” an image and understand the content.
This is a trivial problem for a human, even young children.
- A person can describe the content of a photograph they have seen once.
- A person can summarize a video that they have only seen once.
- A person can recognize a face that they have only seen once before.
We require at least the same capabilities from computers in order to unlock our images and videos.
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
What Is Computer Vision?
Computer vision is a field of study focused on the problem of helping computers to see.
At an abstract level, the goal of computer vision problems is to use the observed image data to infer something about the world.
— Page 83, Computer Vision: Models, Learning, and Inference, 2012.
It is a multidisciplinary field that could broadly be called a subfield of artificial intelligence and machine learning, which may involve the use of specialized methods and make use of general learning algorithms.
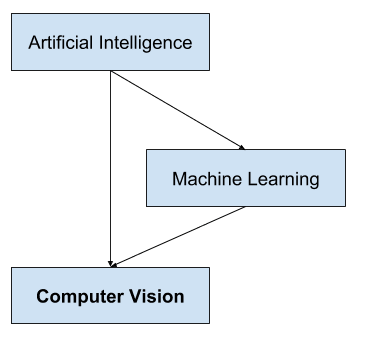
Overview of the Relationship of Artificial Intelligence and Computer Vision
As a multidisciplinary area of study, it can look messy, with techniques borrowed and reused from a range of disparate engineering and computer science fields.
One particular problem in vision may be easily addressed with a hand-crafted statistical method, whereas another may require a large and complex ensemble of generalized machine learning algorithms.
Computer vision as a field is an intellectual frontier. Like any frontier, it is exciting and disorganized, and there is often no reliable authority to appeal to. Many useful ideas have no theoretical grounding, and some theories are useless in practice; developed areas are widely scattered, and often one looks completely inaccessible from the other.
— Page xvii, Computer Vision: A Modern Approach, 2002.
The goal of computer vision is to understand the content of digital images. Typically, this involves developing methods that attempt to reproduce the capability of human vision.
Understanding the content of digital images may involve extracting a description from the image, which may be an object, a text description, a three-dimensional model, and so on.
Computer vision is the automated extraction of information from images. Information can mean anything from 3D models, camera position, object detection and recognition to grouping and searching image content.
— Page ix, Programming Computer Vision with Python, 2012.
Computer Vision and Image Processing
Computer vision is distinct from image processing.
Image processing is the process of creating a new image from an existing image, typically simplifying or enhancing the content in some way. It is a type of digital signal processing and is not concerned with understanding the content of an image.
A given computer vision system may require image processing to be applied to raw input, e.g. pre-processing images.
Examples of image processing include:
- Normalizing photometric properties of the image, such as brightness or color.
- Cropping the bounds of the image, such as centering an object in a photograph.
- Removing digital noise from an image, such as digital artifacts from low light levels.
Challenge of Computer Vision
Helping computers to see turns out to be very hard.
The goal of computer vision is to extract useful information from images. This has proved a surprisingly challenging task; it has occupied thousands of intelligent and creative minds over the last four decades, and despite this we are still far from being able to build a general-purpose “seeing machine.”
— Page 16, Computer Vision: Models, Learning, and Inference, 2012.
Computer vision seems easy, perhaps because it is so effortless for humans.
Initially, it was believed to be a trivially simple problem that could be solved by a student connecting a camera to a computer. After decades of research, “computer vision” remains unsolved, at least in terms of meeting the capabilities of human vision.
Making a computer see was something that leading experts in the field of Artificial Intelligence thought to be at the level of difficulty of a summer student’s project back in the sixties. Forty years later the task is still unsolved and seems formidable.
— Page xi, Multiple View Geometry in Computer Vision, 2004.
One reason is that we don’t have a strong grasp of how human vision works.
Studying biological vision requires an understanding of the perception organs like the eyes, as well as the interpretation of the perception within the brain. Much progress has been made, both in charting the process and in terms of discovering the tricks and shortcuts used by the system, although like any study that involves the brain, there is a long way to go.
Perceptual psychologists have spent decades trying to understand how the visual system works and, even though they can devise optical illusions to tease apart some of its principles, a complete solution to this puzzle remains elusive
— Page 3, Computer Vision: Algorithms and Applications, 2010.
Another reason why it is such a challenging problem is because of the complexity inherent in the visual world.
A given object may be seen from any orientation, in any lighting conditions, with any type of occlusion from other objects, and so on. A true vision system must be able to “see” in any of an infinite number of scenes and still extract something meaningful.
Computers work well for tightly constrained problems, not open unbounded problems like visual perception.
Tasks in Computer Vision
Nevertheless, there has been progress in the field, especially in recent years with commodity systems for optical character recognition and face detection in cameras and smartphones.
Computer vision is at an extraordinary point in its development. The subject itself has been around since the 1960s, but only recently has it been possible to build useful computer systems using ideas from computer vision.
— Page xviii, Computer Vision: A Modern Approach, 2002.
The 2010 textbook on computer vision titled “Computer Vision: Algorithms and Applications” provides a list of some high-level problems where we have seen success with computer vision.
- Optical character recognition (OCR)
- Machine inspection
- Retail (e.g. automated checkouts)
- 3D model building (photogrammetry)
- Medical imaging
- Automotive safety
- Match move (e.g. merging CGI with live actors in movies)
- Motion capture (mocap)
- Surveillance
- Fingerprint recognition and biometrics
It is a broad area of study with many specialized tasks and techniques, as well as specializations to target application domains.
Computer vision has a wide variety of applications, both old (e.g., mobile robot navigation, industrial inspection, and military intelligence) and new (e.g., human computer interaction, image retrieval in digital libraries, medical image analysis, and the realistic rendering of synthetic scenes in computer graphics).
— Page xvii, Computer Vision: A Modern Approach, 2002.
It may be helpful to zoom in on some of the more simpler computer vision tasks that you are likely to encounter or be interested in solving given the vast number of publicly available digital photographs and videos available.
Many popular computer vision applications involve trying to recognize things in photographs; for example:
- Object Classification: What broad category of object is in this photograph?
- Object Identification: Which type of a given object is in this photograph?
- Object Verification: Is the object in the photograph?
- Object Detection: Where are the objects in the photograph?
- Object Landmark Detection: What are the key points for the object in the photograph?
- Object Segmentation: What pixels belong to the object in the image?
- Object Recognition: What objects are in this photograph and where are they?
Other common examples are related to information retrieval; for example: finding images like an image or images that contain an object.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Computer Vision: Models, Learning, and Inference, 2012.
- Programming Computer Vision with Python, 2012.
- Multiple View Geometry in Computer Vision, 2004.
- Computer Vision: Algorithms and Applications, 2010.
- Computer Vision: A Modern Approach, 2002.
Articles
Summary
In this post, you discovered a gentle introduction to the field of computer vision.
Specifically, you learned:
- The goal of the field of computer vision and its distinctness from image processing.
- What makes the problem of computer vision challenging.
- Typical problems or tasks pursued in computer vision.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning Models for Vision Today!

Develop Your Own Vision Models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Computer Vision
It provides self-study tutorials on topics like:
classification, object detection (yolo and rcnn), face recognition (vggface and facenet), data preparation and much more...
Finally Bring Deep Learning to your Vision Projects
Skip the Academics. Just Results.






Good work.
Thanks.
Great Job Sir,
I have 2 Questions .
1.Could you enlist some modern and professional tools (industrial point of view) for CV,
e.g Python with Matlav or Anaconda.
What will you recommend ?
2. Name and minimum number of Tools at least one should must get command over them to be a professional from student level .
(maybe you can merge both questions)
Python platform, deep learning libraries like OpenCV and Keras:
https://machinelearningmastery.com/start-here/#dlfcv
hi sir,
it is all good that you are blogging here for me and thanks for all. but i have a question if you would answer that is in deep learning for image classification what are the best feature extractors better than CNN and the best classifiers after extracting the features to fed in to?
thanks
A high-performing pre-trained model fit on a subset of the imagenet dataset can be used as a very effective feature extraction model.
Examples include VGG, Inception and Resnet.
The features can be fed into a neural net or another algorithm, such as an SVM.
Great work.
When do we expect the book to be published? .
Thanks.
Very soon I hope.
Good article, nice balance. Not too technical and not too fluffy!
Well done!
Thanks Richard!
Great work , u r great teacher.
i m confusing computer vision and image processing as u mention above, detection of object computer vison from existing image, and create new image from existing is image procssing, so after u example the computer vision is OCR, ANPR(automatc number plate detection) is also get info from existing image , but we use image prosecng in this
plz u could explain if u understand my question?
(sorry for my english , its not my native)
Yes, often a computer vision project will include aspects of image processing.
Good article, nice work.
Thanks, I’m glad it helped.
Finally! Thank you for your clear explanations…they will also help me when explaining to others.
Thanks, I’m glad they helped!
you so gucci fam lit dude
Thanks.
Nice post good information provided for Machine Learning
Thanks!
Can anyone tell me about its data?
Which data?
HI,
What about 3D modelling? Or perhaps building a 3D model using stereo cameras or photogrammetry? would that be considered at computer vision as well?
Yes.
read this to understand a course my granddaughter is taking. It was clear and helpful – I do have a math background.
Thanks Joanne, I’m happy it helped!
Hello, Prof
thanks for for this great article could you help me how to recognize sign languages
Perhaps this process will help:
https://machinelearningmastery.com/start-here/#process
Hello Jason,
Is there any of your articles posted on “machine learning for medical imaging”?
Thanks
Not at this stage.
You can find computer vision tutorials here:
https://machinelearningmastery.com/start-here/#dlfcv
sir I have a question
Are feature selection and extraction methods in machine vision applicable to all images? Or will the algorithm change be depending on the image?
Feature selection and extraction is learned by the CNN model and performed on all images automatically by the model.
Well explained article but I have question is moral of cv Is that it can help to knew properties of image and objects in image but can’t extract real means of image??
Am I right??
No, we solve specific engineering problems using the tools of computer vision.
Amazing article.
Thanks!
Hi Jason,
Thank you so much for your nice article. I have a basic question. Could you please help me to understand the following question?
Could we say an image a natural image collected from internet sources flickers, google , and many other source.
Looking forward to your kind response.
Many Thanks!
Sorry, I don’t understand. Perhaps you could rephrase your question or elaborate.
Hi Jason,
Thank you so much for your quick feedback!
I have dataset “MIT-Indoor-67” which contains images collected from internet source such as flicker, google, and labelMe. Could I call the images of this dataset “natural images” in the context of deep learning / image preprocessing? I am confused about natural images vs real images concepts in context of deep learning.
Many Thanks!
Sorry, I have not heard these terms before, I don’t know the differnce.
Its not true that CV is a subfield of AI. CV and AI are distinct fields and have, in its core, nothing to do with each other. Beside object detection, recoginition and so on, CV also deals with camera calibration, computational imaging, stereoscopic depth estimation and much more. But its true that a lot of classical CV algorithms have been superseded by ML algorithms.
Thank you for the feedback Martin! You may find the following of interest:
https://machinelearningmastery.com/how-to-get-started-with-deep-learning-for-computer-vision-7-day-mini-course/