Deep learning is having a large impact on the field of natural language processing.
But, as a beginner, where do you start?
Both deep learning and natural language processing are huge fields. What are the salient aspects of each field to focus on and which areas of NLP is deep learning having the most impact?
In this post, you will discover a primer on deep learning for natural language processing.
After reading this post, you will know:
- The neural network architectures that are having the biggest impact on the field of natural language processing.
- A broad view of the natural language processing tasks that can be successfully addressed with deep learning.
- The importance of dense word representations and the methods that can be used to learn them.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Primer on Neural Network Models for Natural Language Processing
Photo by faungg’s photos, some rights reserved.
Overview
This post is divided into 12 sections that follow the structure of the paper; they are:
- About the Paper (Introduction)
- Neural Network Architectures
- Feature Representation
- Feed-Forward Neural Networks
- Word Embeddings
- Neural Network Training
- Cascading and Multi-Task Learning
- Structured Output Prediction
- Convolutional Layers
- Recurrent Neural Networks
- Concrete RNN Architectures
- Modeling Trees
I want to give you a flavor of the main sections and style of this paper as well as a high-level introduction to the topic.
If you want to go deeper, I highly recommend reading the paper in full, or the more recent book.
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
1. About the Paper
The title of the paper is: “A Primer on Neural Network Models for Natural Language Processing“.
It is available for free on ArXiv and was last dated 2015. It is a technical report or tutorial more than a paper and provides a comprehensive introduction to Deep Learning methods for Natural Language Processing (NLP), intended for researchers and students.
This tutorial surveys neural network models from the perspective of natural language processing research, in an attempt to bring natural-language researchers up to speed with the neural techniques.
The primer was written by Yoav Goldberg who is a researcher in the field of NLP and who has worked as a research scientist at Google Research. Yoav caused some controversy recently, but I wouldn’t hold that against him.
It is a technical report and is about 62 pages and has about 13 pages of references.
The paper is ideal for beginners for two reasons:
- It assumes little about the reader, other than you are interested in this topic and you know a little machine learning and/or natural language processing.
- It has great breadth, covering a wide range of deep learning methods and natural language problems.
In this tutorial I attempt to provide NLP practitioners (as well as newcomers) with the basic background, jargon, tools and methodology that will allow them to understand the principles behind the neural network models and apply them to their own work. … it is aimed at those readers who are interested in taking the existing, useful technology and applying it in useful and creative ways to their favourite NLP problems.
Often, key deep learning methods are re-cast using the terminology or nomenclature of linguistics or natural language processing, providing a useful bridge.
Finally, this 2015 primer has been turned into a book published in 2017, titled “Neural Network Methods for Natural Language Processing“.

Neural Network Methods for Natural Language Processing
If you like this primer and want to go deeper, I highly recommend Yoav’s book.
2. Neural Network Architectures
This short section provides an introduction to the different types of neural network architectures with cross-references into later sections.
Fully connected feed-forward neural networks are non-linear learners that can, for the most part, be used as a drop-in replacement wherever a linear learner is used.
A total of 4 types of neural network architectures are covered, highlighting examples of applications and references of each:
- Fully connected feed-forward neural networks, e.g. multilayer Perceptron networks.
- Networks with convolutional and pooling layers, e.g. convolutional neural networks.
- Recurrent Neural Networks, e.g. long short-term memory networks.
- Recursive Neural Networks.
This section provides a great source if you are only interested in applications for a specific network type and want to go straight to the source papers.
3. Feature Representation
This section focuses on the use of transitioning from sparse to dense representations that can, in turn, be trained along with the deep learning models.
Perhaps the biggest jump when moving from sparse-input linear models to neural-network based models is to stop representing each feature as a unique dimension (the so called one-hot representation) and representing them instead as dense vectors.
A general structure of NLP classification systems is presented, summarized as:
- Extract a set of core linguistic features.
- Retrieve the corresponding vector for each vector.
- Combine the feature vectors.
- Feed the combined vectors into a non-linear classifier.
The key to this formulation are the dense rather than sparse feature vectors and the use of core features rather than feature combinations.
Note that the feature extraction stage in the neural-network settings deals only with extraction of core features. This is in contrast to the traditional linear-model-based NLP systems in which the feature designer had to manually specify not only the core features of interests but also interactions between them
4. Feed-Forward Neural Networks
This section provides a crash course on feed-forward artificial neural networks.
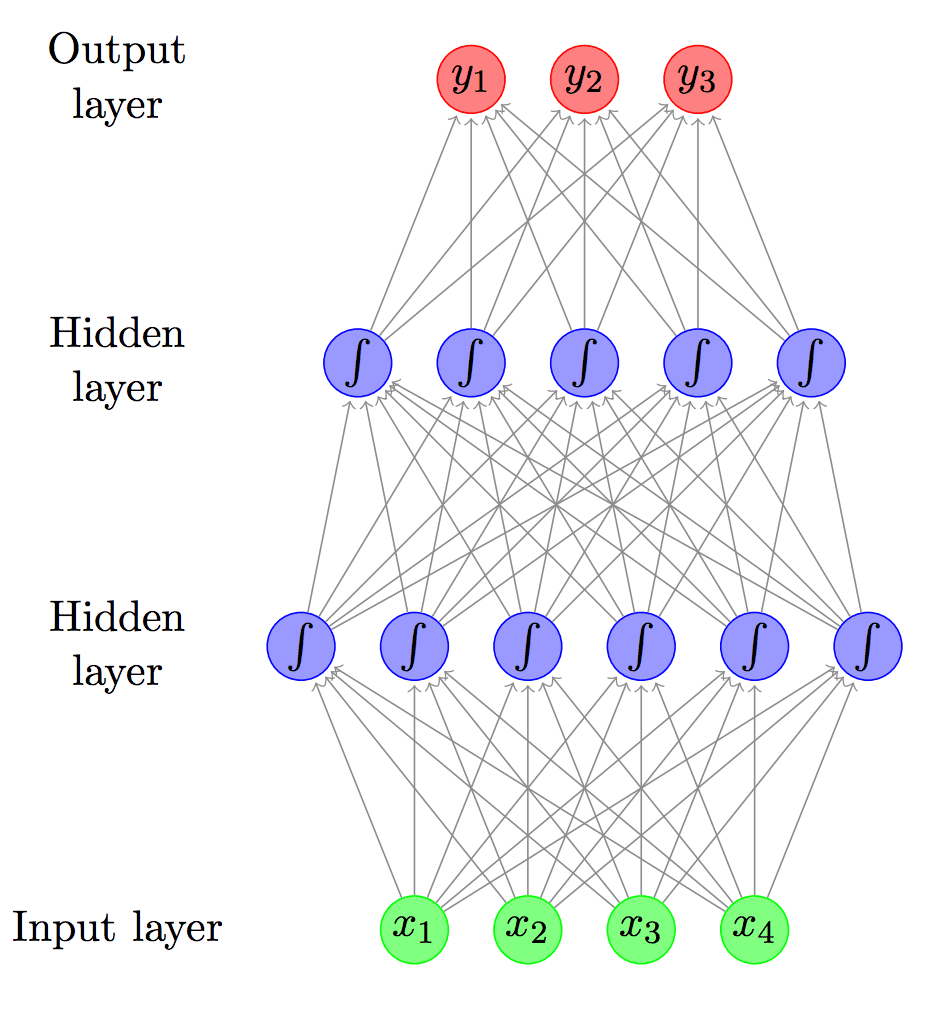
Feed-forward neural network with two hidden layers, taken from “A Primer on Neural Network Models for Natural Language Processing.”
Networks are presented both using a brain-inspired metaphor and using mathematical notation. Common neural network topics are covered such as:
- Representation Power (e.g. universal approximation).
- Common Non-linearities (e.g. transfer functions).
- Output Transformations (e.g. softmax).
- Word Embeddings (e.g. built-in learned dense representation).
- Loss Functions (e.g. hinge and log loss).
5. Word Embeddings
The topic of word embedding representations is key to the neural network approach in natural language processing. This section expands upon the topic and enumerates the key methods.
A main component of the neural-network approach is the use of embeddings — representing each feature as a vector in a low dimensional space
The following word embedding topics are reviewed:
- Random Initialization (e.g. starting with uniformed random vectors).
- Supervised Task-specific Pre-training (e.g. transfer learning).
- Unsupervised Pre-training (e.g. statistical methods like word2vec and GloVe).
- Training Objectives (e.g. the influence of the objective on the resulting vectors).
- The Choice of Contexts (e.g. influence of the words around each word).
Neural word embeddings originated from the world of language modeling, in which a network is trained to predict the next word based on a sequence of preceding words
6. Neural Network Training
This longer section focuses on how neural networks are trained, written for those new to the neural network paradigm.
Neural network training is done by trying to minimize a loss function over a training set, using a gradient-based method.
The section focuses on stochastic gradient descent (and friends like mini-batch) as well as important topics during training like regularization.
Interesting, the computational graph perspective of neural networks is presented, providing a primer for symbolic numerical libraries like Theano and TensorFlow that are popular foundations for implementing deep learning models.
Once the graph is built, it is straightforward to run either a forward computation (compute the result of the computation) or a backward computation (computing the gradients)
7. Cascading and Multi-Task Learning
This section builds upon the previous section by summarizing work for cascading NLP models and models for learning across multiple language tasks.
Model cascading: Exploits the computational graph definition of neural network models to leverage intermediate representations (encoding) to develop more sophisticated models.
For example, we may have a feed-forward network for predicting the part of speech of a word based on its neighbouring words and/or the characters that compose it.
Multi-task learning: Where there are related natural language prediction tasks that do not feed into one another, but information can be shared across tasks.
Information for predicting chunk boundaries, named-entity boundaries and the next word in the sentence all rely on some shared underlying syntactic-semantic representation
Both of these advanced concepts are described in the context of neural networks that permit both the connectivity between models or information both during training (backpropagation of errors) and making predictions.
8. Structured Output Prediction
This section is concerned with examples of natural language tasks where deep learning methods are used to make structured predictions such as sequences, trees and graphs.
Canonical examples are sequence tagging (e.g. part-of-speech tagging) sequence segmentation (chunking, NER), and syntactic parsing.
This section covers both greedy and search-based structured prediction, with focus on the latter.
The common approach to predicting natural language structures is search based.
9. Convolutional Layers
This section providers a crash course on Convolutional Neural Networks (CNNs) and their impact on natural language.
Notably, CNNs have proven very effective for classification NLP tasks like sentiment analysis, e.g. learning to look for specific subsequences or structures in text in order to make predictions.
A convolutional neural network is designed to identify indicative local predictors in a large structure, and combine them to produce a fixed size vector representation of the structure, capturing these local aspects that are most informative for the prediction task at hand.
10. Recurrent Neural Networks
As with the previous section, this section focuses on the use of a specific type of network and its role and application in NLP. In this case, Recurrent Neural Networks (RNNs) for modeling sequences.
Recurrent neural networks (RNNs) allow representing arbitrarily sized structured inputs in a fixed-size vector, while paying attention to the structured properties of the input.
Given the popularity of RNNs and specifically the Long Short-Term Memory (LSTM) in NLP, this larger section works through a variety of recurrent topics and models, including:
- The RNN Abstraction (e.g. recurrent connections in the network graph).
- RNN Training (e.g. backpropagation through time).
- Multi-layer (stacked) RNNs (e.g. the “deep” part of deep learning).
- BI-RNN (e.g. providing sequences forwards and backwards as input).
- RNNs for Representing Stacks
Time is spent on the RNN model architectures or architectural elements, specifically:
- Acceptor: the loss calculated on output after complete input sequence.
- Encoder: the final vector is used as an encoding of the input sequence.
- Transducer: one output is created for each observation in the input sequence.
- Encoder-Decoder: the input sequence is encoded to a fixed-length vector before being decoded to an output sequence.
11. Concrete RNN Architectures
This section builds on the previous by presenting specific RNN algorithms.
Specifically covered are:
- Simple RNN (SRNN).
- Long Short-Term Memory (LSTM).
- Gated Recurrent Unit (GRU).
12. Modeling Trees
This final section focuses on a more complex type of network called the Recursive Neural Network for learning model trees.
The trees can be syntactic trees, discourse trees, or even trees representing the sentiment expressed by various parts of a sentence. We may want to predict values based on specific tree nodes, predict values based on the root nodes, or assign a quality score to a complete tree or part of a tree.
As recurrent neural networks maintain state about the input sequences, recursive neural networks maintain state about nodes in the trees.
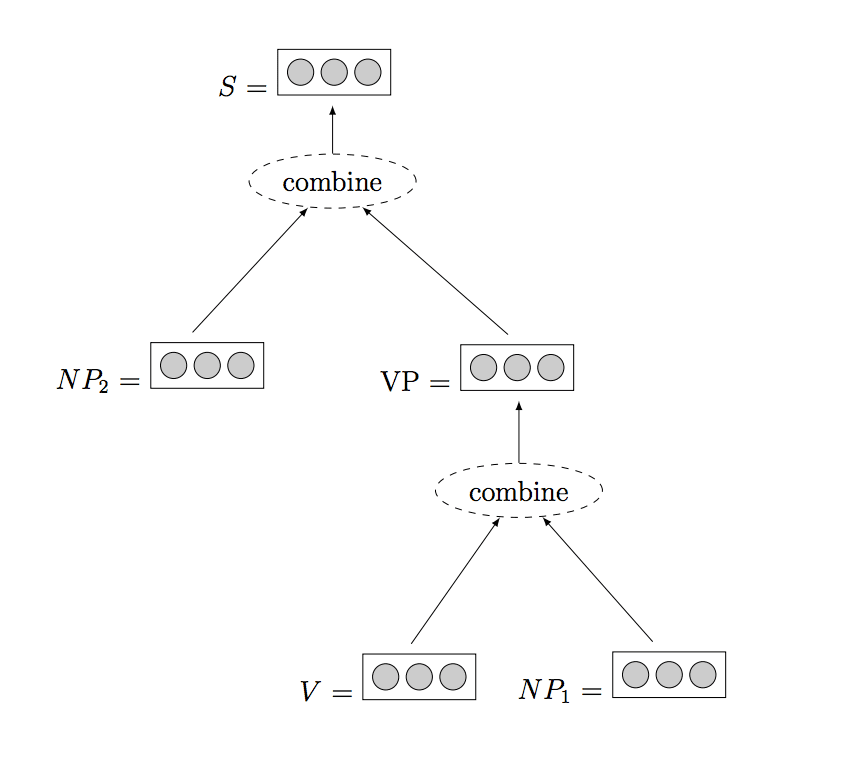
Example of a Recursive Neural Network, taken from “A Primer on Neural Network Models for Natural Language Processing.”
Further Reading
This section provides more resources on the topic if you are looking go deeper.
- A Primer on Neural Network Models for Natural Language Processing, 2015
- Neural Network Methods for Natural Language Processing, 2017
- Yoav Goldberg Homepage
- Yoav Goldberg on Medium
Summary
In this post, you discovered a primer on deep learning for natural language processing.
Specifically, you learned:
- The neural network architectures that are having the biggest impact on the field of natural language processing.
- A broad view of the natural language processing tasks that are can be successfully addressed with deep learning.
- The importance of dense word representations and the methods that can be used to learn them.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Text Data Today!

Develop Your Own Text models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Natural Language Processing
It provides self-study tutorials on topics like:
Bag-of-Words, Word Embedding, Language Models, Caption Generation, Text Translation and much more...
Finally Bring Deep Learning to your Natural Language Processing Projects
Skip the Academics. Just Results.






Hi Jason,
Thanks a lot for this useful article about NLP.
You’re welcome Simone.
Great article… again 🙂
Thanks a lot!
You’re welcome Jan.
Hi Jason,
Nice article. You may find this article useful as well – “Recent Trends in Deep Learning Based
Natural Language Processing” -> https://arxiv.org/pdf/1708.02709.pdf . Please have a look. Thanks.
Regards,
Soujanya
Thanks for the link.
Thanks for this Nice NLP post
You’re welcome.
Nice article Jason, thank you.
Thanks Victor.
Looking forward to see something like ‘nlp_with_python’ bundle from Jason in the near future.
It is coming isaac, it will cover word2vec, caption generation, sentiment analysis, translation and so much more. I’m about 70% done.
Good to hear your coming with NLP Jason, looking forward to it
Thanks Ravi.
A very informative article Jason.
I am currently reading/working-through your book: “Discover LSTMs With Python”. It has been very useful.
Looking forward to your future book(s)/bundle.
Thanks Ade!
Good job Jason!
Do you know if, inside the book, there is something about aspect based sentiment analysis?
What would you recommend for this topic?
Thank you!
Sorry, I’ve not heard of “aspect-based sentiment analysis”. I’m not sure if it is in the book.
I tried to read it once, it seemed too technical and filled with mathematical notation and jargon. Do you really think it is accessible and that a programmer or a practical ML practitioner could benefit from reading this?
It is a good start until something else comes along.
I am working on a book to bridge the gap.
Awesome. I would love to see a book for people allergic to highly abstract mathematical notation.
Thanks Tim.