
By Travis Addair & Geoffrey Angus
If you’d like to learn more about how to efficiently and cost-effectively fine-tune and serve open-source LLMs with LoRAX, join our November 7th webinar.
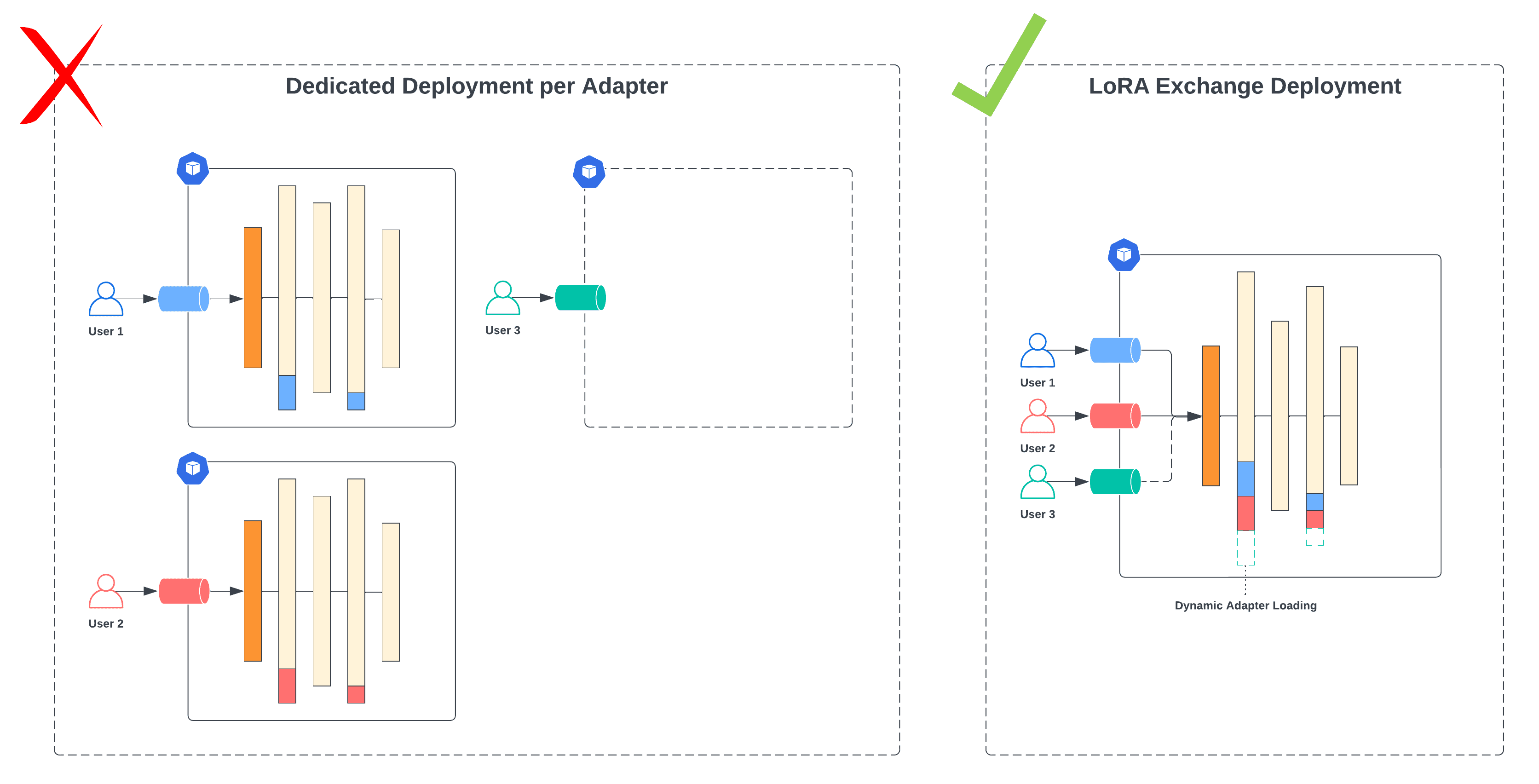
Developers are realizing that smaller, specialized language models such as LLaMA-2-7b outperform larger general-purpose models like GPT-4 when fine-tuned with proprietary data to perform a single task. However, you likely don’t have a single generative AI task, you have many, and serving each fine-tuned model with its own dedicated GPU resources can quickly add up to $10k+ per month in cloud costs.
At Predibase, we’ve addressed the cost challenges with a solution we call LoRA Exchange (LoRAX), an innovative LLM serving system built for deploying numerous fine-tuned LLMs using a shared set of GPU resources. This approach enables users to pack over 100 task-specific models into a single GPU, significantly reducing the expenses associated with serving fine-tuned models by orders of magnitude over dedicated deployments.
The Hidden Cost of Serving Fine-tuned LLMs
The standard method for fine-tuning deep neural networks involves updating all the model parameters during the training process, which demands significant GPU memory and storage resources. To address this issue, techniques like Low Rank Adaptation (LoRA) have been introduced, which add a small number of parameters that are trained while keeping the original model parameters frozen. This approach achieves comparable performance to full fine-tuning with significantly less resource consumption.
Using existing LLM serving infrastructure, deploying multiple models fine-tuned with LoRA still requires separate dedicated resources for each model, leading to high operational costs. However, because each fine-tuned model is very small (about 1% the size of the original model), a solution built for serving fine-tuned LLMs like LoRAX can consolidate multiple of these small fine-tuned adapters into a single deployment by reusing common base model parameters, minimizing resource usage and operational complexity.
Introducing LoRA Exchange (LoRAX): Serve 100s of Fine-tuned LLMs for the Cost of Serving 1
LoRA Exchange (LoRAX) is a new approach to LLM serving infrastructure specifically designed for serving many fine-tuned models at once using a shared set of GPU resources. LoRAX introduces three key components that make this possible: Dynamic Adapter Loading, Tiered Weight Caching, and Continuous Multi-Adapter Batching.
Dynamic Adapter Loading
Unlike conventional serving infrastructure that preloads all model weights during initialization, LoRAX only loads the pretrained base LLM weights during initialization, and dynamically loads each set of fine-tuned LoRA adapters just-in-time at runtime.
To avoid blocking ongoing requests from other users, the LoRAX system maintains an individual request queue per fine-tuned adapter. While the new fine-tuned model’s adapter weights are being dynamically loaded in, all of its associated requests will wait in queue while other requests proceed as usual. In practice, we’ve observed the overhead of dynamically loading in a new adapter to be on the order of 200ms, much less than the typical text generation response time, making it possible to start interactively evaluating your fine-tuned models immediately after training completes. This small loading cost is further amortized away as subsequent tokens are generated and requests to the same model are submitted.
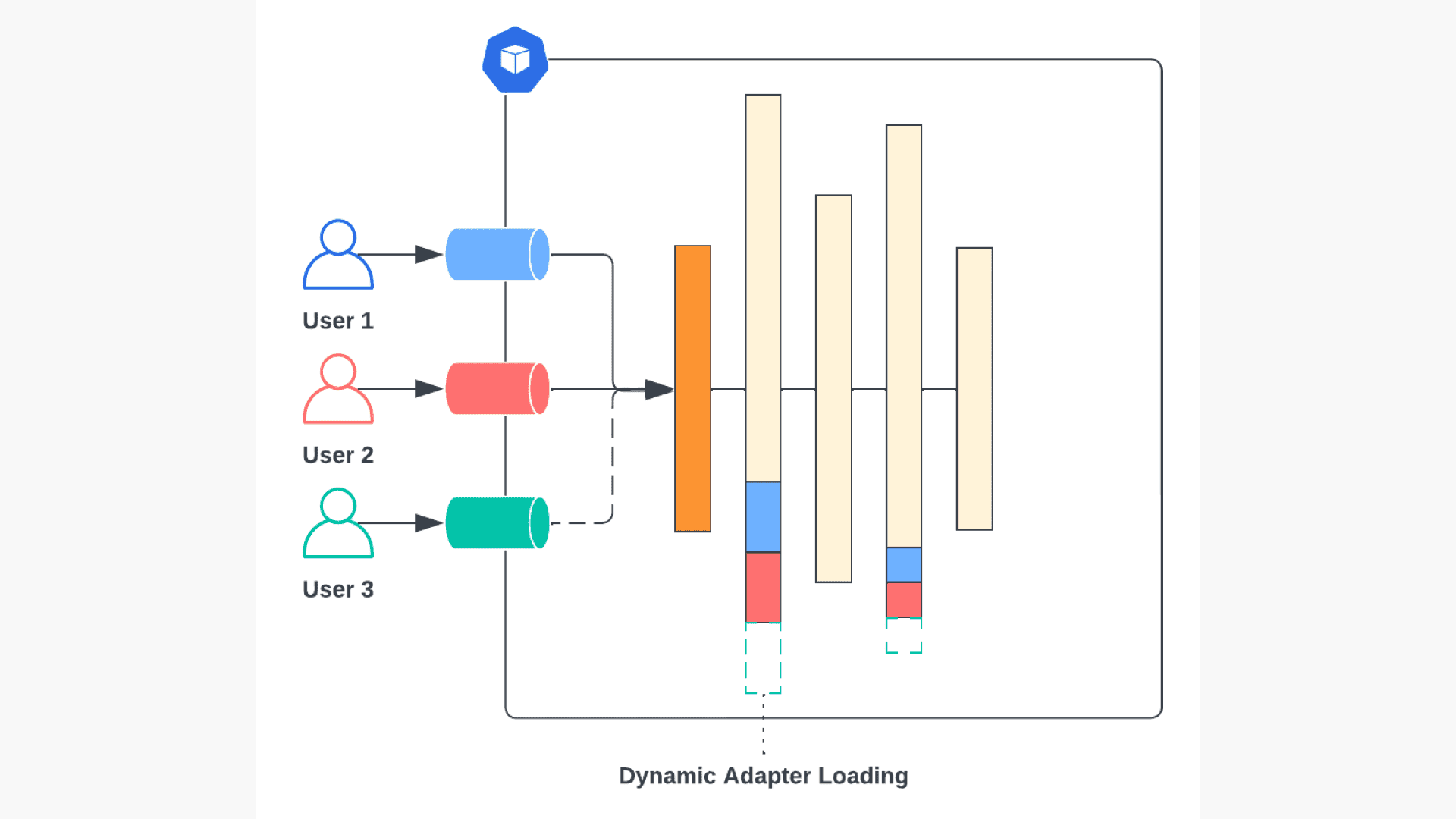
Overview of dynamic adapter loading with multiple concurrent fine-tuned model requests. User 3’s model (green) is loaded in the background while the other requests proceed as usual.
Tiered Weight Caching
As more fine-tuned models are loaded into a single LLM deployment, the memory overhead increases. To avoid encountering an out of memory error (OOM), the LoRAX system implements a tiered weight caching strategy that offloads adapter weights from GPU → CPU → disk to trade off between adapter exchange latency and memory overhead.
LoRAX’s caching strategy aims to strike a balance between keeping as many adapters on the GPU as possible, while leaving enough room for handling long sequences and large request batches. When an adapter does need to be evicted from the GPU, we transition it to CPU (host memory) using a least-recently used (LRU) policy. This policy also extends down to lower layers of the cache, so that we evict weights from CPU and (if necessary) delete them from local ephemeral disk as new adapter weights are loaded in. In the worst case, weights can be redownloaded from object storage.
Putting all of this together allows you to pack upwards of 100 models into a single deployment without the need to scale up to additional replicas barring high request volume.
Continuous Multi-Adapter Batching
Continuous batching is a crucial technique for high-throughput text generation, allowing multiple requests to be grouped together during each token generation step. However, when utilizing LoRA weights for different fine-tuned models, a challenge arises in managing requests efficiently. How do you batch together requests from different adapters together at once? What if there are hundreds of concurrent adapter requests, more than you could reasonably fit in GPU memory at a time?
LoRAX addresses these issues by implementing a fair scheduling policy that optimizes aggregate throughput while ensuring timely response for each specific adapter. This involves marking a limited number of adapters as “active” at any given time, continuously batching requests for these active adapters, and periodically switching to the next set of adapters in a round-robin manner. Multiple adapters can fit into a single batch by applying a simple masking scheme to the outputs of each adapter layer. The scheduling system enables prioritization of either throughput or latency based on the configurable time intervals for adapter switching.
The Future is Fine-Tuned
Smaller and more specialized LLMs are the most cost-effective and performant way to put generative AI into production. But today’s LLM serving infrastructure wasn’t built for serving a variety of specialized models. Achieving this vision of a more fine-tuned future means rethinking the serving stack to be fine-tuning first.
Get Started for Free with Predibase
Predibase is the first platform designed to help developers put open-source LLMs into production on scalable, serverless and cost-effective managed infra–all within your cloud. Built on top of the open source Ludwig framework developed at Uber, Predibase makes it easy to efficiently fine-tune and serve LLMs on even the cheapest most readily available commodity hardware.
- See for yourself by starting a 14-day free trial of Predibase where you’ll be able to fine-tune and query LLaMA-2-7b using LoRAX.
- Join our upcoming webinar to see LoRAX in action and get access to our free colab notebook.


")



No comments yet.