In this article, you will learn how to build a fully functional AI agent that runs entirely on your own machine using small language models, with no internet connection and no API costs required.
Topics we will cover include:
What AI agents and small language models are, and why running them locally is a practical and privacy-conscious choice.
How to set up Ollama and the required Python libraries to run a language model on your own hardware.
How to build a local AI agent step by step, adding tools and conversation memory to make it genuinely useful.
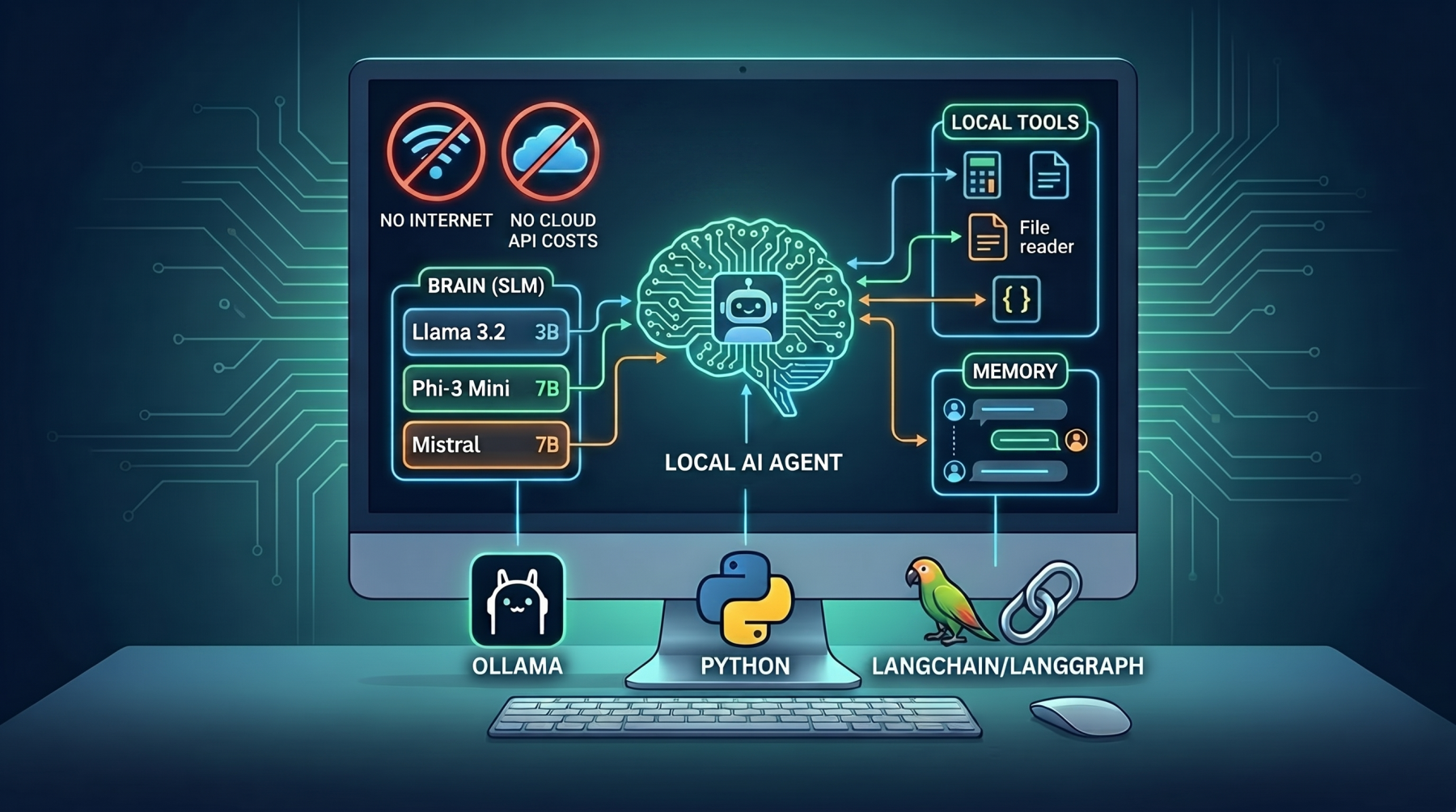
Building AI Agents with Local Small Language Models
Image by Editor
Introduction
The idea of building your own AI agent used to feel like something only big tech companies could pull off. You needed expensive cloud APIs, massive servers, and deep pockets. That picture has changed completely.
Today, developers &emdash; including those just starting out &emdash; can build fully functional AI agents that run entirely on their own computer, with no internet connection required (after initial setup and configuration) and no API bills to worry about. This is made possible by a new generation of small language models (SLMs): compact, efficient AI models that are powerful enough to reason, plan, and respond, yet light enough to run on a standard laptop or desktop.
In this article, you will learn how to build a local AI agent from scratch using the popular tools Ollama and LangChain/LangGraph. Whether you are a beginner who is just getting comfortable with Python or an intermediate developer exploring AI, this article is written for you.
What Are AI Agents?
An AI agent is a program that uses a language model to think, make decisions, and take actions in order to complete a goal. Unlike a regular chatbot that only responds to messages, an agent can:
Break down a task into smaller steps
Decide which tool or action to use next
Use the result of one step to inform the next
Keep going until the task is done
Think of it like the difference between a calculator and an assistant. A calculator waits for your input. An assistant thinks about your goal, figures out the steps, and works through them.
A basic agent has three parts:
Part
What It Does
Brain (LLM/SLM)
Understands input and decides what to do
Memory
Stores context from earlier in the conversation
Tools
External functions the agent can call (e.g. search, calculator, file reader)
What Are Small Language Models?
Small language models (SLMs) are AI models trained on large amounts of text data — similar to large models like GPT-4 — but designed to be much more lightweight.
Where GPT-4 might have hundreds of billions of parameters, an SLM like Phi-3, Mistral 7B, or Llama 3.2 (3B) has between 1 billion and 13 billion parameters. That makes them small enough to run on a regular computer with a modern CPU or a consumer-grade GPU.
If you are unsure which model to start with, go with Phi-3 Mini or Llama 3.2 (3B). They are well-documented, beginner-friendly, and perform well on local machines.
Why Run AI Agents Locally?
You might be wondering: why not just use the OpenAI API or Google Gemini?
Fair question. Here is why local SLMs are worth your attention:
No API costs. Cloud-based models charge per token or per request. If your agent runs thousands of queries, the cost adds up fast. Local models run for free after setup.
Full privacy. When you send data to a cloud API, it leaves your machine. For sensitive data like medical records, private business data, or personal documents, that is a real risk. Local models keep everything on your device.
Works offline. No internet? No problem. Your agent keeps running.
You are in control. You choose the model, the settings, and the behaviour. No rate limits, no usage policies getting in your way.
Great for learning. Running models locally forces you to understand how everything fits together, which makes you a better developer.
Tools You Will Use
Here is a quick overview of the three tools this guide uses:
Ollama
Ollama is a free, open-source tool that lets you download and run language models on your local machine with a single command. It handles all the complex setup behind the scenes so you can focus on building.
LangChain / LangGraph
LangChain is a popular framework for building applications powered by language models. LangGraph is an extension of LangChain that helps you build agent workflows, defining how your agent thinks and acts step by step using a graph-based structure.
Setting Up Your Environment
Before you write any agent code, you need to set up your tools.
Step 1: Install Ollama
Go to ollama.com and download the installer for your operating system (Windows, Mac, or Linux). Once installed, open your terminal and pull a model:
1
ollama pull phi3
This downloads the Phi-3 Mini model to your machine. To confirm it works, run:
1
ollama run phi3
You should see a prompt where you can chat with the model directly. Type /bye to exit.
Step 2: Install Python Libraries
Create a virtual environment and install the required packages:
1
python-mvenv agent-env
For Linux/Mac:
1
source agent-env/bin/activate
On Windows:
1
agent-env\Scripts\activate
Install the required libraries:
1
pip install langchain langchain-ollama langgraph
You need Python 3.9 or later. Check your version with:
1
python--version
Building Your First Local AI Agent
Now for the exciting part. Let us build a simple agent that can answer questions and use a basic tool — a calculator.
In your agent.py file, paste this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
from langchain_ollama import OllamaLLM
from langchain.agents import AgentExecutor,create_react_agent
from langchain.tools import tool
from langchain import hub
# Step 1: Load the local model via Ollama
llm=OllamaLLM(model="phi3")
# Step 2: Define a simple tool -- a calculator
@tool
def calculator(expression:str)->str:
"""Evaluates a basic math expression. Input should be a valid Python math expression."""
"input":"What is 245 multiplied by 18, and then divided by 5?"
})
print("\n--- Agent Response ---")
print(response["output"])
Here is what is happening:
The OllamaLLM class connects to your locally running Phi-3 model.
The @tool decorator turns a regular Python function into a tool the agent can call.
The create_react_agent function uses the ReAct pattern — a method where the agent reasons about the problem and then acts using a tool, repeatedly, until it has an answer.
AgentExecutor manages the loop of reasoning, acting, and observing results.
Run the script:
1
python agent.py
You will see the agent’s thought process printed in the terminal before it produces the final answer.
Adding Memory and Tools to Your Agent
A real agent needs to remember what was said earlier in a conversation. Here is how to add conversation memory and a second tool — a simple knowledge base lookup.
In your agent_with_memory.py file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
from langchain_ollama import OllamaLLM
from langchain.agents import AgentExecutor,create_react_agent
from langchain.tools import tool
from langchain.memory import ConversationBufferMemory
from langchain import hub
llm=OllamaLLM(model="phi3")
# Tool 1: Calculator
@tool
def calculator(expression:str)->str:
"""Evaluates a basic math expression."""
try:
returnstr(eval(expression))
except Exception ase:
returnf"Error: {str(e)}"
# Tool 2: Simulated knowledge base lookup
@tool
def knowledge_base(query:str)->str:
"""Looks up information from a local knowledge base."""
kb={
"python":"Python is a beginner-friendly programming language widely used in AI and data science.",
"ai agent":"An AI agent is a program that uses a language model to reason and take actions.",
"ollama":"Ollama is a tool for running language models locally on your computer.",
print(agent_executor.invoke({"input":"What is an AI agent?"})["output"])
print(agent_executor.invoke({"input":"Now tell me what Ollama is."})["output"])
print(agent_executor.invoke({"input":"Calculate 50 multiplied by 12."})["output"])
Note:eval() is used here for instructional purposes, but should never be used on untrusted input in production code.
With ConversationBufferMemory, the agent remembers your previous messages in the same session. This makes it behave more like a real assistant rather than a stateless chatbot.
Limitations to Know
Running AI agents locally with SLMs is powerful, but it is important to be honest about the trade-offs:
Smaller models make more mistakes. SLMs are not as capable as GPT-4 or Claude. They can hallucinate — confidently give wrong answers — more often, especially on complex tasks.
Speed depends on your hardware. If you do not have a GPU, your model may run slowly. Expect 5–30 seconds per response depending on your machine.
Context length is limited. Most SLMs can only handle shorter conversations before they “forget” earlier messages. This is a known limitation of smaller models.
Complex reasoning is harder. Multi-step logic, advanced coding tasks, or nuanced instructions may not work as well as they would with a larger cloud model.
When to use local SLMs: For prototyping, learning, privacy-sensitive projects, offline use cases, and applications where the cost of cloud APIs is a concern.
When to use cloud models: For production applications that demand high accuracy, handle complex tasks, or serve many users simultaneously.
Conclusion
Building AI agents with local small language models is no longer a niche skill reserved for AI researchers. With tools like Ollama and LangChain/LangGraph, any developer with a working Python environment can have a local agent running in under an hour.
Here is what you covered in this article:
What AI agents are and how they work
What small language models are, and which ones are worth using
Why running AI locally gives you privacy, control, and zero API cost
How to set up Ollama and your Python environment
How to build a working agent with a calculator tool
How to add memory and multiple tools to make your agent smarter
The best way to learn this deeply is to build something. Start with the code examples in this guide, swap in a different model (I suggest you try Mistral 7B next), and keep adding tools until your agent can do something genuinely useful to you.
I find this article very encouraging. 20 years ago I was an active researcher using backprop neural nets for narrow AI applications. All of my work preceded LLM technology by a decade so I’ve been hesitant to undertake building an agentic development environment. Your article makes me think I can probably do this. I have a small budget ($10K) to buy hardware and I’m privacy paranoid so I’m only looking at LINUX-based open source tools and local, off line hosting of the LLM and agents.
Given my constraints, do you have any recommendations on hardware? I’ve read that a system with 128GB of unified memory running on one or more GPU(s) would allow me to run a larger model like DeepSeek but I’m still very much a novice and suffer from the “don’t know what I don’t know” problem! Any advice you have for me would be closely attended.
Thank you this insightful article!
Hello! I think this is a good beginner article but the langchain version should be mentioned here. It seems that you’re using an older version which has a lot of syntax differences.
Great article. I’m about to get on a plane and short in time- but I just wanted to take a quick minute to say thank you. I appreciate the information you shared and the way it was presented/shared.
I wanna push back a little on some of the feedback I’ve seen about smaller models. Yes, they can be like very noob interns, prone to both error and confusion. That is baked-in to the equation – no limits, no cost, no reliability. Balance your resources against your requirements; If you are working “on the cheap”, small models are The Way to Go — it is on you to accommodate the advantages or disadvantages of your tech stack.
Hi, I appreciate the article, but I ran into a few issues following it and had codex try to fix it. I had it write a summary of what it needed to fix, in a format suitable for this comment section:
[codex]
Use this between the tags:
The article appears to be written for an older LangChain API, but the install command pulls current LangChain.
The article says to install:
pip install langchain langchain-ollama langgraph
In this environment, that installed langchain 1.2.18. With that version, the article’s imports no longer resolve:
from langchain_ollama import OllamaLLM
from langchain.agents import AgentExecutor, create_react_agent
from langchain.tools import tool
from langchain import hub
The current-LangChain version needed these imports instead:
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
from langchain.tools import tool
Main changes required:
Replaced OllamaLLM with ChatOllama.
Replaced create_react_agent with create_agent.
Removed AgentExecutor.
Removed hub.pull(“hwchase17/react”).
Changed invocation from {“input”: “…”} to a messages list.
Changed response reading from response[“output”] to response[“messages”][-1].content.
Changed the Ollama model from phi3 to a tool-calling-capable model.
There was also a separate Ollama/model issue. The article uses phi3, but current LangChain’s create_agent uses tool calling, and Ollama returned:
registry.ollama.ai/library/phi3:latest does not support tools
Using qwen3:0.6b worked after running:
ollama pull qwen3:0.6b
The working current-LangChain script was:
import os
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
from langchain.tools import tool
@tool
def calculator(expression: str) -> str:
“””Evaluates a basic math expression. Input should be a valid Python math expression.”””
try:
result = eval(expression)
return str(result)
except Exception as e:
return f”Error: {str(e)}”
tools = [calculator]
agent = create_agent(model=llm, tools=tools)
response = agent.invoke({
“messages”: [
{
“role”: “user”,
“content”: “What is 245 multiplied by 18, and then divided by 5?”,
}
]
})
245 multiplied by 18, and then divided by 5 equals 882.
So the article likely needs either pinned older package versions, or an update for current LangChain’s create_agent API and a local Ollama model that supports tool calling.
thank you Ashour! I am still in the beginning phase of my AI/ML journey and it seems like every tutorial i find online are using older langchain versions and i keep seeing that arguments are deprecated. So then i find myself googling how to fix it. Do you have any recommendations on where i can look online for accurate and up to date tutorials for creating AI agents?






I find this article very encouraging. 20 years ago I was an active researcher using backprop neural nets for narrow AI applications. All of my work preceded LLM technology by a decade so I’ve been hesitant to undertake building an agentic development environment. Your article makes me think I can probably do this. I have a small budget ($10K) to buy hardware and I’m privacy paranoid so I’m only looking at LINUX-based open source tools and local, off line hosting of the LLM and agents.
Given my constraints, do you have any recommendations on hardware? I’ve read that a system with 128GB of unified memory running on one or more GPU(s) would allow me to run a larger model like DeepSeek but I’m still very much a novice and suffer from the “don’t know what I don’t know” problem! Any advice you have for me would be closely attended.
Thank you this insightful article!
Hi David…The following resources may be of interest: https://machinelearningmastery.com/?s=gpu
This is very insightful, thank you.
You are very welcome, Toluwalase! We wish you the best on your machine learning journey!
Excellent article and code snippets. This would give an idea to many how AI agents work or can be domesticated for a particular work.
Thank you M S Prascad for your feedback and support!
Hello! I think this is a good beginner article but the langchain version should be mentioned here. It seems that you’re using an older version which has a lot of syntax differences.
Thank you for your feedback and suggestions NeMo!
Yes there is problem. “from langchain import hub” does not work. I tried all fixes suggested by AI but still did not work. Any suggestion?
Great article. I’m about to get on a plane and short in time- but I just wanted to take a quick minute to say thank you. I appreciate the information you shared and the way it was presented/shared.
Thank you, Nathan! We great appreciate your support and feedback! Keep us posted on your progress!
Yes there is problem. “from langchain import hub” does not work. I tried all fixes suggested by AI but still did not work. Any suggestion?
Those models are so tiny as to be nearly useless. Get some hardware that can run Gemma 4 31b
can you share the requirement.txt file to pin the python module versions
I wanna push back a little on some of the feedback I’ve seen about smaller models. Yes, they can be like very noob interns, prone to both error and confusion. That is baked-in to the equation – no limits, no cost, no reliability. Balance your resources against your requirements; If you are working “on the cheap”, small models are The Way to Go — it is on you to accommodate the advantages or disadvantages of your tech stack.
I enjoyed the article man way to go.
Thank you Unhacker for your feedback and support!
“from langchain import hub” – does not work. Tried all fixes suggested by AI but still did not work. Any suggestion?
Hi, I appreciate the article, but I ran into a few issues following it and had codex try to fix it. I had it write a summary of what it needed to fix, in a format suitable for this comment section:
[codex]
Use this between the tags:
The article appears to be written for an older LangChain API, but the install command pulls current LangChain.
The article says to install:
pip install langchain langchain-ollama langgraph
In this environment, that installed langchain 1.2.18. With that version, the article’s imports no longer resolve:
from langchain_ollama import OllamaLLM
from langchain.agents import AgentExecutor, create_react_agent
from langchain.tools import tool
from langchain import hub
The current-LangChain version needed these imports instead:
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
from langchain.tools import tool
Main changes required:
Replaced OllamaLLM with ChatOllama.
Replaced create_react_agent with create_agent.
Removed AgentExecutor.
Removed hub.pull(“hwchase17/react”).
Changed invocation from {“input”: “…”} to a messages list.
Changed response reading from response[“output”] to response[“messages”][-1].content.
Changed the Ollama model from phi3 to a tool-calling-capable model.
There was also a separate Ollama/model issue. The article uses phi3, but current LangChain’s create_agent uses tool calling, and Ollama returned:
registry.ollama.ai/library/phi3:latest does not support tools
Using qwen3:0.6b worked after running:
ollama pull qwen3:0.6b
The working current-LangChain script was:
import os
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
from langchain.tools import tool
model_name = os.environ.get(“OLLAMA_MODEL”, “qwen3:0.6b”)
llm = ChatOllama(model=model_name)
@tool
def calculator(expression: str) -> str:
“””Evaluates a basic math expression. Input should be a valid Python math expression.”””
try:
result = eval(expression)
return str(result)
except Exception as e:
return f”Error: {str(e)}”
tools = [calculator]
agent = create_agent(model=llm, tools=tools)
response = agent.invoke({
“messages”: [
{
“role”: “user”,
“content”: “What is 245 multiplied by 18, and then divided by 5?”,
}
]
})
print(“\n— Agent Response —“)
print(response[“messages”][-1].content)
That produced:
245 multiplied by 18, and then divided by 5 equals 882.
So the article likely needs either pinned older package versions, or an update for current LangChain’s create_agent API and a local Ollama model that supports tool calling.
[/codex]
Thank you Ashour for your contribution to our discussion!
thank you Ashour! I am still in the beginning phase of my AI/ML journey and it seems like every tutorial i find online are using older langchain versions and i keep seeing that arguments are deprecated. So then i find myself googling how to fix it. Do you have any recommendations on where i can look online for accurate and up to date tutorials for creating AI agents?