In this article, you will learn the architectural differences between structured outputs and function calling in modern language model systems.
Topics we will cover include:
How structured outputs and function calling work under the hood.
When to use each approach in real-world machine learning systems.
The performance, cost, and reliability trade-offs between the two.
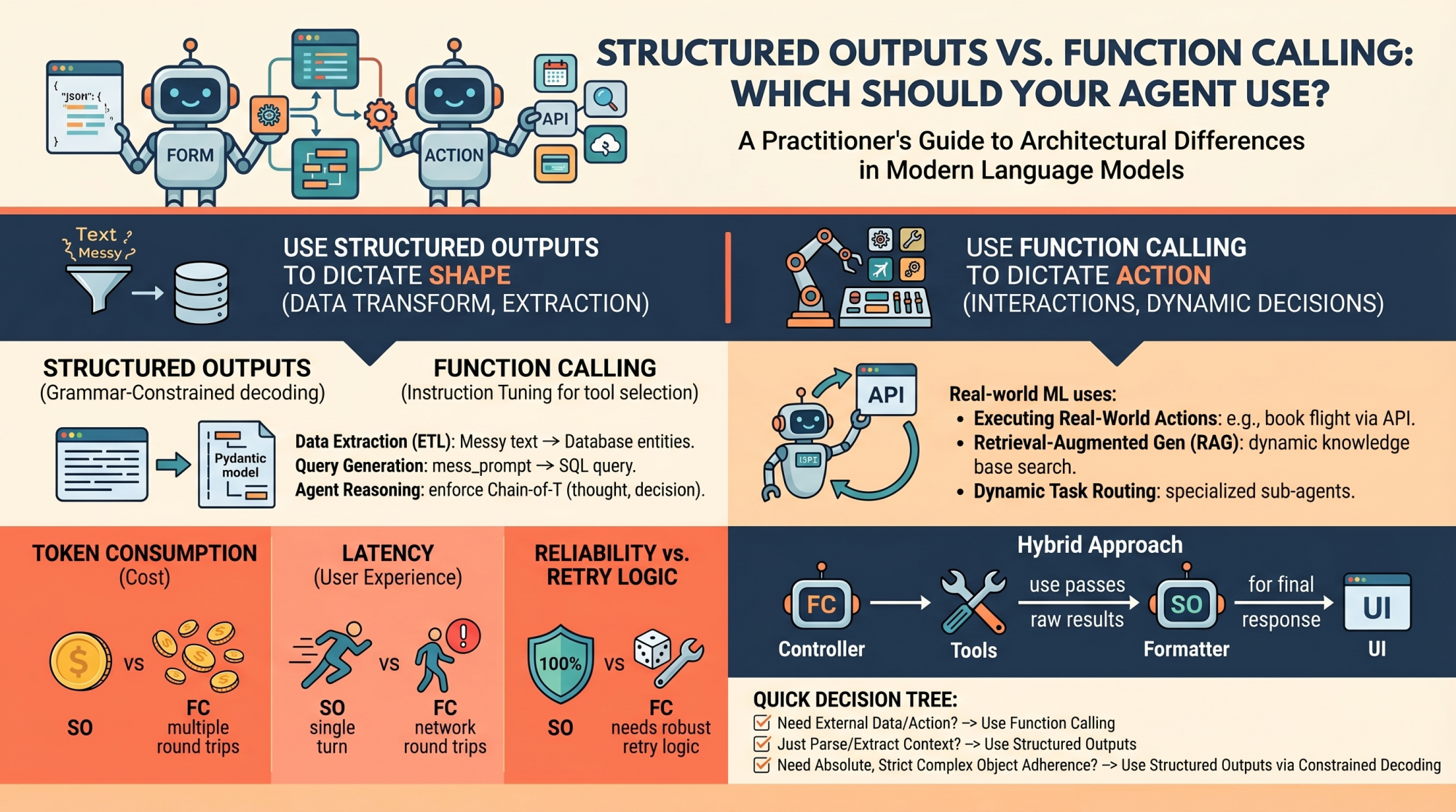
Structured Outputs vs. Function Calling: Which Should Your Agent Use?
Image by Editor
Introduction
Language models (LMs), at their core, are text-in and text-out systems. For a human conversing with one via a chat interface, this is perfectly fine. But for machine learning practitioners building autonomous agents and reliable software pipelines, raw unstructured text is a nightmare to parse, route, and integrate into deterministic systems.
To build reliable agents, we need predictable, machine-readable outputs and the ability to interact seamlessly with external environments. In order to bridge this gap, modern LM API providers (like OpenAI, Anthropic, and Google Gemini) have introduced two primary mechanisms:
Structured Outputs: Forcing the model to reply by adhering exactly to a predefined schema (most commonly a JSON schema or a Python Pydantic model)
Function Calling (Tool Use): Equipping the model with a library of functional definitions that it can choose to invoke dynamically based on the context of the prompt
At first glance, these two capabilities look very similar. Both typically rely on passing JSON schemas to the API under the hood, and both result in the model outputting structured key-value pairs instead of conversational prose. However, they serve fundamentally different architectural purposes in agent design.
Conflating the two is a common pitfall. Choosing the wrong mechanism for a feature can lead to brittle architectures, excessive latency, and unnecessarily inflated API costs. Let’s unpack the architectural distinctions between these methods and provide a decision-making framework for when to use each.
Unpacking the Mechanics: How They Work Under the Hood
To understand when to use these features, it is necessary to understand how they differ at the mechanical and API levels.
Structured Outputs Mechanics
Historically, getting a model to output raw JSON relied on prompt engineering (“You are a helpful assistant that *only* speaks in JSON…”). This was error-prone, requiring extensive retry logic and validation.
Modern “structured outputs” fundamentally change this through grammar-constrained decoding. Libraries like Outlines, or native features like OpenAI’s Structured Outputs, mathematically restrict the token probabilities at generation time. If the chosen schema dictates that the next token must be a quotation mark or a specific boolean value, the probabilities of all non-compliant tokens are masked out (set to zero).
This is a single-turn generation strictly focused on form. The model is answering the prompt directly, but its vocabulary is confined to the exact structure you defined, with the aim of ensuring near 100% schema compliance.
Function Calling Mechanics
Function calling, on the other hand, relies heavily on instruction tuning. During training, the model is fine-tuned to recognize situations where it lacks the necessary information to complete a prompt, or when the prompt explicitly asks it to take an action.
When you provide a model with a list of tools, you are telling it, “If you need to, you can pause your text generation, select a tool from this list, and generate the necessary arguments to run it.”
This is an inherently multi-turn, interactive flow:
The model decides to call a tool and outputs the tool name and arguments.
The model pauses. It cannot execute the code itself.
Your application code executes the selected function locally using the generated arguments.
Your application returns the result of the function back to the model.
The model synthesizes this new information and continues generating its final response.
When to Choose Structured Outputs
Structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization.
Primary Use Case: The model has all the necessary information within the prompt and context window; it just needs to reshape it.
Examples for Practitioners:
Data Extraction (ETL): Processing raw, unstructured text like a customer support transcript and extracting entities &emdash; names, dates, complaint types, and sentiment scores &emdash; into a strict database schema.
Query Generation: Converting a messy natural language user prompt into a strict, validated SQL query or a GraphQL payload. If the schema is broken, the query fails, making 100% adherence critical.
Internal Agent Reasoning: Structuring an agent’s “thoughts” before it acts. You can enforce a Pydantic model that requires a thought_process field, an assumptions field, and finally a decision field. This forces a Chain-of-Thought process that is easily parsed by your backend logging systems.
The Verdict: Use structured outputs when the “action” is simply formatting. Because there is no mid-generation interaction with external systems, this approach ensures high reliability, lower latency, and zero schema-parsing errors.
When to Choose Function Calling
Function calling is the engine of agentic autonomy. If structured outputs dictate the shape of the data, function calling dictates the control flow of the application.
Primary Use Case: External interactions, dynamic decision-making, and cases where the model needs to fetch information it doesn’t currently possess.
Examples for Practitioners:
Executing Real-World Actions: Triggering external APIs based on conversational intent. If a user says, “Book my usual flight to New York,” the model uses function calling to trigger the book_flight(destination="JFK") tool.
Retrieval-Augmented Generation (RAG): Instead of a naive RAG pipeline that always searches a vector database, an agent can use a search_knowledge_base tool. The model dynamically decides what search terms to use based on the context, or decides not to search at all if it already knows the answer.
Dynamic Task Routing: For complex systems, a router model might use function calling to select the best specialized sub-agent (e.g., calling delegate_to_billing_agent versus delegate_to_tech_support) to handle a specific query.
The Verdict: Choose function calling when the model must interact with the outside world, fetch hidden data, or conditionally execute software logic mid-thought.
Performance, Latency, and Cost Implications
When deploying agents to production, the architectural choice between these two methods directly impacts your unit economics and user experience.
Token Consumption: Function calling often requires multiple round trips. You send the system prompt, the model sends tool arguments, you send back the tool results, and the model finally sends the answer. Each step appends to the context window, accumulating input and output token usage. Structured outputs are typically resolved in a single, more cost-effective turn.
Latency Overhead: The round trips inherent to function calling introduce significant network and processing latency. Your application has to wait for the model, execute local code, and wait for the model again. If your primary goal is just getting data into a specific format, structured outputs will be vastly faster.
Reliability vs. Retry Logic: Strict structured outputs (via constrained decoding) offer near 100% schema fidelity. You can trust the output shape without complex parsing blocks. Function calling, however, is statistically unpredictable. The model might hallucinate an argument, pick the wrong tool, or get stuck in a diagnostic loop. Production-grade function calling requires robust retry logic, fallback mechanisms, and careful error handling.
Hybrid Approaches and Best Practices
In advanced agent architectures, the line between these two mechanisms often blurs, leading to hybrid approaches.
The Overlap:
It is worth noting that modern function calling actually relies on structured outputs under the hood to ensure the generated arguments match your function signatures. Conversely, you can design an agent that only uses structured outputs to return a JSON object describing an action that your deterministic system should execute after the generation is complete &emdash; effectively faking tool use without the multi-turn latency.
Architectural Advice:
The “Controller” Pattern: Use function calling for the orchestrator or “brain” agent. Let it freely call tools to gather context, query databases, and execute APIs until it is satisfied it has accumulated the necessary state.
The “Formatter” Pattern: Once the action is complete, pass the raw results through a final, cheaper model utilizing only structured outputs. This guarantees the final response perfectly matches your UI components or downstream REST API expectations.
Wrapping Up
LM engineering is rapidly transitioning from crafting conversational chatbots to building reliable, programmatic, autonomous agents. Understanding how to constrain and direct your models is the key to that transition.
TL;DR
Use structured outputs to dictate the shape of the data
Use function calling to dictate actions and interactions
The Practitioner’s Decision Tree
When building a new feature, run through this quick 3-step checklist:
Do I need external data mid-thought or need to execute an action? ⭢ Use function calling
Am I just parsing, extracting, or translating unstructured context into structured data? ⭢ Use structured outputs
Do I need absolute, strict adherence to a complex nested object? ⭢ Use structured outputs via constrained decoding
Final Thought
The most effective AI engineers treat function calling as a powerful but unpredictable capability, one that should be used sparingly and surrounded by robust error handling. Conversely, structured outputs should be treated as the reliable, foundational glue that holds modern AI data pipelines together.






No comments yet.