Keras is a Python deep learning library that provides easy and convenient access to the powerful numerical libraries like TensorFlow.
Large deep learning models require a lot of compute time to run. You can run them on your CPU but it can take hours or days to get a result. If you have access to a GPU on your desktop, you can drastically speed up the training time of your deep learning models.
In this post, you will discover how you can get access to GPUs to speed up the training of your deep learning models by using the Amazon Web Service (AWS) infrastructure. For a few dollars per hour and often a lot cheaper you can use this service from your workstation or laptop.
Kick-start your project with my new book Deep Learning With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Update Oct/2016: Updated examples for Keras 1.1.0.
Update Mar/2017: Updated to use new AMI, Keras 2.0.2 and TensorFlow 1.0.
Update Feb/2019: Updated to use the new “Deep Learning AMI” and “p3.2xlarge”.
Amazon Web Services Photo by Andrew Mager, some rights reserved
Tutorial Overview
The process is quite simple because most of the work has already been done for us.
Below is an overview of the process.
Setup Your AWS Account.
Launch Your AWS Instance.
Login and Run Your Code.
Close Your AWS Instance.
Note, it costs money to use a virtual server instance on Amazon. The cost is low for ad hoc model development (e.g. less than one US dollar per hour), which is why this is so attractive, but it is not free.
The server instance runs Linux. It is desirable although not required that you know how to navigate Linux or a unix-like environment. We’re just running our Python scripts, so no advanced skills are needed.
1. Setup Your AWS Account
You need an account on Amazon Web Services.
1. You can create an account by the Amazon Web Services portal and click “Sign in to the Console”. From there you can sign in using an existing Amazon account or create a new account.
AWS Sign-in Button
2. You will need to provide your details as well as a valid credit card that Amazon can charge. The process is a lot quicker if you are already an Amazon customer and have your credit card on file.
AWS Sign-In Form
Once you have an account you can log into the Amazon Web Services console.
You will see a range of different services that you can access.
2. Launch Your AWS Instance
Now that you have an AWS account, you want to launch an EC2 virtual server instance on which you can run Keras.
Launching an instance is as easy as selecting the image to load and starting the virtual server. Thankfully there is already an image available that has almost everything we need it is called the Deep Learning AMI (Amazon Linux) and was created and is maintained by Amazon. Let’s launch it as an instance.
1. Login to your AWS console if you have not already.
AWS Console
2. Click on EC2 for launching a new virtual server.
3. Select “US West Orgeon” from the drop-down in the top right hand corner. This is important otherwise you will not be able to find the image we plan to use.
4. Click the “Launch Instance” button.
5. Click “Community AMIs”. An AMI is an Amazon Machine Image. It is a frozen instance of a server that you can select and instantiate on a new virtual server.
Community AMIs
6. Enter “Deep Learning AMI” in the “Search community AMIs” search box and press enter.
Deep Learning AMI
7. Click “Select” to choose the AMI in the search result.
8. Now you need to select the hardware on which to run the image. Scroll down and select the “p3.2xlarge” hardware (I used to recommend g2 or g3 instances and p2 instances, but the p3 instances are newer and faster). This includes a Tesla V100 GPU that we can use to significantly increase the training speed of our models. It also includes 8 CPU Cores, 61GB of RAM and 16GB of GPU RAM. Note: using this instance will cost approximately $3USD/hour.
p3.2xlarge EC2 Instance
9. Click “Review and Launch” to finalize the configuration of your server instance.
10. Click the “Launch” button.
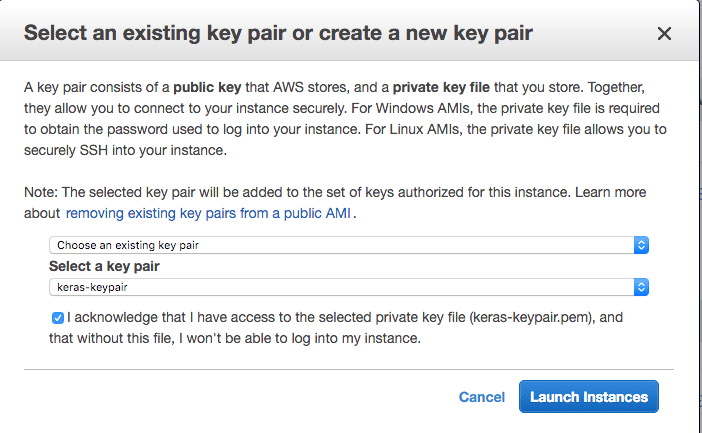
11. Select Your Key Pair.
If you have a key pair because you have used EC2 before, select “Choose an existing key pair” and choose your key pair from the list. Then check “I” acknowledge…”.
If you do not have a key pair, select the option “Create a new key pair” and enter a “Key pair name” such as keras-keypair. Click the “Download Key Pair” button.
Select Your Key Pair
12. Open a Terminal and change directory to where you downloaded your key pair.
13. If you have not already done so, restrict the access permissions on your key pair file. This is requred as part of the SSH access to your server. For example:
1
2
cd Downloads
chmod 600 keras-aws-keypair.pem
14. Click “Launch Instances”. If this is your first time using AWS, Amazon may have to validate your request and this could take up to 2 hours (often just a few minutes).
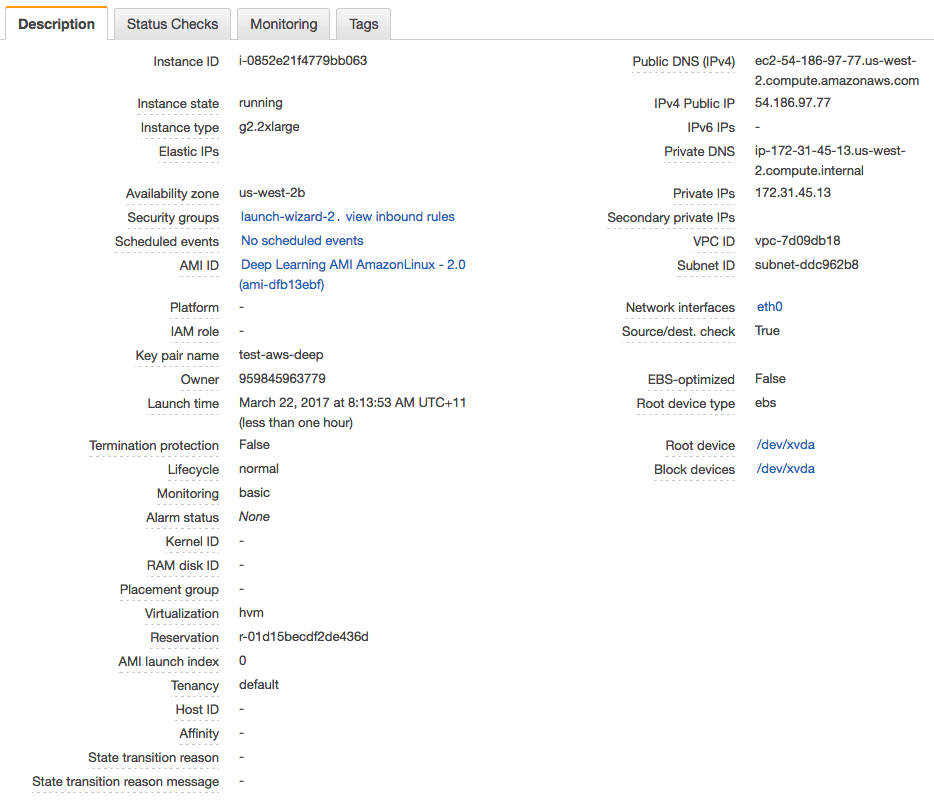
15. Click “View Instances” to review the status of your instance.
Deep Learning AMI Status
Your server is now running and ready for you to log in.
3. Login, Configure and Run
Now that you have launched your server instance, it is time to log in and start using it.
1. Click “View Instances” in your Amazon EC2 console if you have not already.
2. Copy “Public IP” (down the bottom of the screen in Description) to clipboard. In this example my IP address is 54.186.97.77. Do not use this IP address, your IP address will be different.
3. Open a Terminal and change directory to where you downloaded your key pair. Login to your server using SSH, for example:
When you are finished with your work you must close your instance.
Remember you are charged by the amount of time that you use the instance. It is cheap, but you do not want to leave an instance on if you are not using it.
1. Log out of your instance at the terminal, for example you can type:
1
exit
2. Log in to your AWS account with your web browser.
3. Click EC2.
4. Click “Instances” from the left-hand side menu.
Review Your List of Running Instances
5. Select your running instance from the list (it may already be selected if you only have one running instance).
Select Your Running AWS Instance
6. Click the “Actions” button and select “Instance State” and choose “Terminate”. Confirm that you want to terminate your running instance.
It may take a number of seconds for the instance to close and to be removed from your list of instances.
Need help with Deep Learning in Python?
Take my free 2-week email course and discover MLPs, CNNs and LSTMs (with code).
Click to sign-up now and also get a free PDF Ebook version of the course.
Tips and Tricks for Using Keras on AWS
Below are some tips and tricks for getting the most out of using Keras on AWS instances.
Design a suite of experiments to run beforehand. Experiments can take a long time to run and you are paying for the time you use. Make time to design a batch of experiments to run on AWS. Put each in a separate file and call them in turn from another script. This will allow you to answer multiple questions from one long run, perhaps overnight.
Run scripts as a background process. This will allow you to close your terminal and turn off your computer while your experiment is running.
You can then check the status and results in your script.log file later. Learn more about nohup.
Always close your instance at the end of your experiments. You do not want to be surprised with a very large AWS bill.
Try spot instances for a cheaper but less reliable option. Amazon sell unused time on their hardware at a much cheaper price, but at the cost of potentially having your instance closed at any second. If you are learning or your experiments are not critical, this might be an ideal option for you. You can access spot instances from the “Spot Instance” option on the left hand side menu in your EC2 web console.
For more help on command line recopies to use on AWS, see the post:
In this post, you discovered how you can develop and evaluate your large deep learning models in Keras using GPUs on the Amazon Web Service. You learned:
Amazon Web Services with their Elastic Compute Cloud offers an affordable way to run large deep learning models on GPU hardware.
How to set-up and launch an EC2 server for deep learning experiments.
How to update the Keras version on the server and confirm that the system is working correctly.
How to run Keras experiments on AWS instances in batch as background tasks.
Do you have any questions about running your models on AWS or about this post? Ask your questions in the comments and I will do my best to answer.
Do you guys have any tutorials on deploying the model as service? I am trying to allow a user to be able to upload an image and for me to classify it with a custom classifier.
I saw your book and I don’t think this was touched upon. I think having that would be a great capstone project to the book.
I don’t have any information at the moment on deploying a model as a service.
Generally, you could use a MLaaS like Google Prediction, Amazon, Azure on BigML.
I have setup models as a service in operations, but it has always been a custom job. E.g. custom delivery of inputs and custom handling of outputs of the model.
1. Is this limited to the specific examples or can I train anything on aws?
2. How can I upload / download data to / from the server?
3. Are you aware of windows based server configuration with caffe and python availiable?
Hi! Thanks for a great tutorial! Currently I’m training VGG16 and it trains pretty faster in compare to my CPU – 870s vs 70s per epoch 🙂
BTW what if not just terminate but also create a backup image and start from it each time?
Damn! missed it. another reason to view regularly visit your blogs. I just spent the night understanding how to ensure cudnn and keras and all that stuff work properly on aws. I could have just seen this blog and used the AMI.
TFAMI contains Keras, TensorFlow and OpenAI Gym. It is one of the hardest combinations to install. So I decided to create an open-source AMI that is actively maintained. Feel free to recommend to beginners instead of the one that you are currently recommending.
Thanks for creating this. However, I tried your TFAMI.v2 (N. Virginia ami-a96634be) using a p2.xlarge AWS spot request and found that no GPU could be located on the machine (output below). Any ideas?
>>> import tensorflow as tf
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so.5 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally
>>> sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
E tensorflow/stream_executor/cuda/cuda_driver.cc:491] failed call to cuInit: CUDA_ERROR_NO_DEVICE
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:153] retrieving CUDA diagnostic information for host: ip-172-31-50-145
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:160] hostname: ip-172-31-50-145
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:185] libcuda reported version is: 367.57.0
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:356] driver version file contents: “””NVRM version: NVIDIA UNIX x86_64 Kernel Module 367.48 Sat Sep 3 18:21:08 PDT 2016
GCC version: gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.2)
“””
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:189] kernel reported version is: 367.48.0
E tensorflow/stream_executor/cuda/cuda_diagnostics.cc:296] kernel version 367.48.0 does not match DSO version 367.57.0 — cannot find working devices in this configuration
I tensorflow/core/common_runtime/gpu/gpu_init.cc:81] No GPU devices available on machine.
Thank you for a very clear tutorial, Jason. Got your books now too. It works for me with one exception – I cannot switch to g2.2xlarge, I can only select t2.micro as I chose to sign up for the 12 month free trial. I looked high and low but could not find a way to switch to faster hardware.
I don’t mind paying for the compute instance on the hourly rate, but I don’t want to be stuck in an expensive developer account with monthly subcription as I need AWS for a pet project of mine.
Is there a way about it? I looked into Reserved Instances but there again it seemed like I would be stuck with a service for 12 months minimum.
I believe you may need to contact AWS support and request access to the larger hardware. They may need to perform a quick check of your account then approve access. This is often a very fast process.
Hi,
I am running into several errors while running an Faster RCNN network on the ami-125b2c72. Which version of opencv do I install for this ami? Do I need to be changing/downgrading the versions of CUDA and cuDNN?
When we stop the instance all the data will be erased, it seems a little annoying to redownload the datasets and configure our codes. Should we use EBS storage service? or what is your suggestion? Thanks
Consider using storage like S3 for datasets. Take a look at the Amazon docs, but I think there is cost advantages in storing data in the amazon infrastructure.
Hi Jason, First of all Sorry for Off-topic discussion,
I would like to know, is it possible to run a Java Project developed on Eclipse Environment (lots of packages has imported while developing the project) on AWS Server to get the high computational speed? If yes, can you give some references for the above? I am new to Amazon AWS and I found the description is a bit complicated.
I like this tutorial from which any one can understand the steps very easily.
Unfortunately this one is also not available: “Latest update: our Amazon credits has expired ¯\_(ツ)_/¯ As such, we are unable to host these AMIs on all regions “. Will try to run Kaggle ML image seems to be working one.
thank you for your effort, but I still can not find it. Today, I’ve searched again section “Community AMI’s” in region N.Virginia for name TFAMI.v3 and for ami-name: ami-0e969619. Did the same for N.California, checked TFAMI.v3 and ami-08451468. No ami’s found.
I think, you were able to find it because you saved it into “My AMI’s” list.
I realize this article was originally written over a year ago, but since the p2.xlarge instances are now available and the g2.2xlarge ones are roughly 1/2 speed is there any reason to still use the latter?
And, from the FAQ on the AWS site:
P2 instances use NVIDIA Tesla K80 GPUs and are designed for general purpose GPU computing using the CUDA or OpenCL programming models. P2 instances provide customers with high bandwidth 20Gbps networking, powerful single and double precision floating-point capabilities, and error-correcting code (ECC) memory, making them ideal for deep learning, high performance databases, computational fluid dynamics, computational finance, seismic analysis, molecular modeling, genomics, rendering, and other server-side GPU compute workloads. With the latest driver release, P2 instances support CUDA 7.5 and OpenCL 1.2.
G2 instances use NVIDIA GRID GPUs and provide a cost-effective, high-performance platform for graphics applications using DirectX or OpenGL. NVIDIA GRID GPUs also support NVIDIA’s fast capture and encode APIs. Example applications include video creation services, 3D visualizations, streaming graphics-intensive applications, and other server-side graphics workloads. With the initial driver release, G2 instances support DirectX 9, 10, and 11, OpenGL 4.3, CUDA 5.5, OpenCL 1.1, and DirectCompute.
Hi,
What is the best( Right ) EC2 Instance Type to choose?
I mean instance type that fits my applications requirements for this course..?
should not be expensive nor cheap however has to be practical (speed and memory,..etc)
hi
I have tried many times to get through the instance (ami-dfb13ebf ) however when I reach the step 7 : (Step 7: Review Instance Launch)
Launch failed
I contacted AWS and i got this response :
(((Thank you for reaching out to us. The error message you are seeing is caused by not having access to the specific instance type. You do have a default on demand instance limit of twenty. We are happy to submit a limit increase request on your behalf, let us know what type of instance that you would like to request.
I hope this helps, let us know if you have any questions.
Best regards,))))
PLease help me to start this course , I did not start yet
and how to get through from putty as I have windows on my computer
thank you so much for help
First of all – Thank you so much for your blog and work. I’m a student interested in machine learning and for many things my starting point is your blog.
I am experimenting with LSTMs and timeseries-forecasts in the course of my master thesis and I am experiencing that gpu-based computing for example with the g2.2xlarg instance in aws is much slower than computation on a much cheaper cpu-only machine (even core i5 of my notebook).
Have you made similar experience ? I already read some blog and developer posts that the tensorflow backend has a slow implementation for lstm and many others that ran into that problem. I get nearly the same results with Theano. I already know that the batch size has significant potential to improve gpu, but not quite sure whether the sequential type of problem is the reason why gpu can’t outperform cpu.
Would be really cool to hear your opinion and experience.
Yes, I see this often and only with LSTM models. I am fitting caption generation models now (large language model component) and I may as well run on my local i7 rather than the GPUs on AWS.
Glad to hear it is a common problem. I do not dwell though, got work to do and I’ll run my code wherever, I just need the result.
Asp per your blog I have take an aws account and rented an instance g2.2xlarge one.When I am running this code – 9.3 Grid Search Deep Learning Model Parameters ( This is from your book I have bought your book as well.) It is taking forever I have waited for 30 min. Should it take that much time in aws. I am new to aws so not sure which stage it is stuck in.
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import GridSearchCV
import numpy
# Function to create model, required for KerasClassifier
def create_model(optimizer=’rmsprop’, init=’glorot_uniform’):
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer=init, activation=’relu’))
model.add(Dense(8, kernel_initializer=init, activation=’relu’))
model.add(Dense(1, kernel_initializer=init, activation=’sigmoid’))
# Compile model
model.compile(loss=’binary_crossentropy’, optimizer=optimizer, metrics=[‘accuracy’])
return model
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt(“/home/ec2-user/pima-indians-diabetes.csv”, delimiter=”,”)
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = KerasClassifier(build_fn=create_model, verbose=0)
# grid search epochs, batch size and optimizer
optimizers = [‘rmsprop’, ‘adam’]
inits = [‘glorot_uniform’, ‘normal’, ‘uniform’]
epochs = [50, 100, 150]
batches = [5, 10, 20]
param_grid = dict(optimizer=optimizers, epochs=epochs, batch_size=batches, init=inits)
print param_grid
grid = GridSearchCV(estimator=model, param_grid=param_grid)
grid_result = grid.fit(X, Y)
# summarize results
print(“Best: %f using %s” % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_[‘mean_test_score’]
stds = grid_result.cv_results_[‘std_test_score’]
params = grid_result.cv_results_[‘params’]
for mean, stdev, param in zip(means, stds, params):
print(“%f (%f) with: %r” % (mean, stdev, param))
Hi Jason, I tried couple of small codes like cv and few small code. they worked fine. This one is taking time. I tried tweaking it but still taking lot of time. I am planning to run few codes on larger dataset . Will let you know about my findings.
I’m on g2.2xlarge right now with image: Deep Learning AMI Amazon Linux – 3.3_Oct2017 (ami-78994d02).
Is there some way I can ensure that GPUs are being used? When I run “pip list”, “tensorflow (1.3.0)” is listed, not tensorflow-gpu.
I’m also confused because I ran your pima indian code under #6 on https://machinelearningmastery.com/tutorial-first-neural-network-python-keras/, on the same Deep Learning AMI, and the code completed in about 15 seconds on a t2.large, but 45 seconds on p2.xlarge! These timing values were after I had run each one a few times.
Why would it be running significantly slower on the GPU instance?
For small problems, the GPU may result in worse performance given the overhead. A large image classification problem like MNIST or CFIAR would be a good test.
I’m having trouble implementing the tutorial. I’ve tried to used a different training text, but it’s quite a bit shorter than Alice in Wonderland, and all my model produces is the letter ‘a’ repeated 1000 times. Is this due to the training data not being extensive enough? Are there any rules of thumb about how much data is needed…?
I’m training a convnet sample from the book “Deep Learning with Python.”
On my laptop, an underpowered ThinkPad T540, training takes about 55 seconds per epoch.
I ran the same code on an AWS Ubuntu GPU compute p2.xlarge instance and it still took 42 seconds per epoch.
I must be missing something. Is there something I might be doing wrong for it to be so slow on AWS.
Thanks,
Tim
Thanks for the response Jason.
I was hoping that it would have been something obvious.
Do you know of a way to check that Keras and the TensorFlow backend are using the GPU?
Hello, I built a machine learning model in AWS (Type: Binary classification) and then evaluate it. And now I want to run this model 100 times to see the completion time and the cost of every run. Is there any methods to do that?
Update/FYI: AWS may have some new rules regarding launching g2.2xlarge and/or p2.xlarge instances (the GPU instances). I was not able to create an instance of either and had to contact amazon to “request limit increase” to increase my current limit of 0 instances on the above 2 types to 1. I’ve just submitted the request, will update this comment when the result of the review comes in.
However, while waiting for to get access to the gpu instances. I have walked through Jasons tutorial on the “free” instance. I’d suggest you go ahead and do this as there are a few steps to it. One issue I ran in to was, when I created my working instance, I attempted to use keys that were created while attempting to create another instance. This prevented me from ssh’ing into my new instance. For us new guys, you might want to create a new key with a new instance just to keep it simple in the beginning.
This is excellent. Thanks for the post.
I would like to know one more thing, how could I set up 2 AWS instances for distributed computing. As of now I have one AWS GPU instance on which I am training my DL models. I want to create one more and train the model in parallel so that training would be much faster. Is there a way I can do this?
NonMaximum Supression is an approach to avoid double detections on the same object.
But if they are from different classes (on similar object) you get to instances on this object, independent from the NMS-Treshold.
My question is now:
how can i customize your code to say that it is just one object and he should take the more confidence class for this object.
So one object in reality should just be one object in detection.
Hey Jason, I’m getting an error from AWS about failure to launch – ” You have requested more vCPU capacity than your current vCPU limit of 0 allows for the instance bucket that the specified instance type belongs to.”. Do you know any workarounds?
I’ve been working with AWS to fix the issue but have had no success. They increased my vCPU limit to 10 and I still get the same error message. Also, when I try to restrict the access permissions on the key pair file I downloaded (named keras-keypair) by running the code you gave above (“chmod 600 keras-aws-keypair.pem”), I get an error message saying “no such file or directory”. I double checked and the file is in the appropriate directory. But when I try to run “chmod 600 keras-keypair.pem” I don’t get an error message. Could this be the source of the problem?
Hey how do you use any local editor and run notebooks off the cloud? I donot have a great laptop for machine learning and would like to run notebooks off the cloud
Have you ever tried using your laptop’s GPU. I recently installed tensorflow gpu in my laptop with a different environment. and, in another env i installed only tensorflow. the mnist example when run with and without gpu have the same time when trained.
Do you have any idea why was the performance not sped up with using GPU?
Hi tanuja…Thank you for your question! In order to obtain a performance increase with a GPU it is necessary to target functionality specifically designed to take advantage of the GPU architecture. The following resources may help in understanding how to train Keras models for the Amazon Web Services environment.












Hi Jason,
Do you guys have any tutorials on deploying the model as service? I am trying to allow a user to be able to upload an image and for me to classify it with a custom classifier.
I saw your book and I don’t think this was touched upon. I think having that would be a great capstone project to the book.
I don’t have any information at the moment on deploying a model as a service.
Generally, you could use a MLaaS like Google Prediction, Amazon, Azure on BigML.
I have setup models as a service in operations, but it has always been a custom job. E.g. custom delivery of inputs and custom handling of outputs of the model.
So, this is the error I get when theano is called.
CNMeM is enabled with initial size: 95.0% of memory, cuDNN Version is too old. Update to v5, was 3007.
How do I solve this ?
You can ignore this error. It will not affect the examples.
Thanks for the great tutorial.
1. Is this limited to the specific examples or can I train anything on aws?
2. How can I upload / download data to / from the server?
3. Are you aware of windows based server configuration with caffe and python availiable?
Yes, you can use this AWS to train any models you like, within reason.
You can copy your data/code to your AWS instance using secure copy from the command line as follows:
scp -r -i /path/to/keys yourdir ip.address:/path/
Sorry, I don’t know about windows or windows servers.
Thanks for a helpful start-up…looking forward to putting this to work on real examples.
Also, the root partition only has about 4GB of free space, but /mnt should have around 60GB. Probably best to put bigger data files there.
Thanks for the tip Fred.
Hi! Thanks for a great tutorial! Currently I’m training VGG16 and it trains pretty faster in compare to my CPU – 870s vs 70s per epoch 🙂
BTW what if not just terminate but also create a backup image and start from it each time?
Glad to hear it Alexander.
It can be a good idea to create a checkpoint and restart training from the checkpoint in case there is a problem. You can learn about checkpointing models in Keras here:
https://machinelearningmastery.com/check-point-deep-learning-models-keras/
how to deploy a deeplearning cluster with aws.
Great question Linghai. I don’t know off the top of my head.
Let me know how you go.
Damn! missed it. another reason to view regularly visit your blogs. I just spent the night understanding how to ensure cudnn and keras and all that stuff work properly on aws. I could have just seen this blog and used the AMI.
I’m glad you found the post Anurag.
Hi,
I linked an open-source AWS AMI to your awesome guide so beginners can install. Do let me know if it’s cool.
https://github.com/ritchieng/tensorflow-aws-ami
TFAMI contains Keras, TensorFlow and OpenAI Gym. It is one of the hardest combinations to install. So I decided to create an open-source AMI that is actively maintained. Feel free to recommend to beginners instead of the one that you are currently recommending.
TFAMI is available in ALL regions.
Cheers,
Ritchie
Hi Ritchie,
Great work. I’ll try out your AMI when I get time – looks really useful.
Thanks for sharing.
Hi Ritchie,
Thanks for creating this. However, I tried your TFAMI.v2 (N. Virginia ami-a96634be) using a p2.xlarge AWS spot request and found that no GPU could be located on the machine (output below). Any ideas?
>>> import tensorflow as tf
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so.5 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally
>>> sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
E tensorflow/stream_executor/cuda/cuda_driver.cc:491] failed call to cuInit: CUDA_ERROR_NO_DEVICE
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:153] retrieving CUDA diagnostic information for host: ip-172-31-50-145
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:160] hostname: ip-172-31-50-145
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:185] libcuda reported version is: 367.57.0
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:356] driver version file contents: “””NVRM version: NVIDIA UNIX x86_64 Kernel Module 367.48 Sat Sep 3 18:21:08 PDT 2016
GCC version: gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.2)
“””
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:189] kernel reported version is: 367.48.0
E tensorflow/stream_executor/cuda/cuda_diagnostics.cc:296] kernel version 367.48.0 does not match DSO version 367.57.0 — cannot find working devices in this configuration
I tensorflow/core/common_runtime/gpu/gpu_init.cc:81] No GPU devices available on machine.
if want train a deep learning model on dataset available on my laptop using AWS AMI , do i have to upload data to AWS s3?
No, you can upload to your EC2 server.
Hi Jason,
Any chance you can show us how to deploy this on a small cluster (say two GPU machines for now). Would really really appreciate that.
Also just bought your book on DL and ML (via company). Is there extra material in the books?
Thanks,
Sachin
Hi Sachin,
I don’t have an example of deploying a model to a cluster, sorry.
Thank you for a very clear tutorial, Jason. Got your books now too. It works for me with one exception – I cannot switch to g2.2xlarge, I can only select t2.micro as I chose to sign up for the 12 month free trial. I looked high and low but could not find a way to switch to faster hardware.
I don’t mind paying for the compute instance on the hourly rate, but I don’t want to be stuck in an expensive developer account with monthly subcription as I need AWS for a pet project of mine.
Is there a way about it? I looked into Reserved Instances but there again it seemed like I would be stuck with a service for 12 months minimum.
Thank you.
Katya, I don’t know if this apply to you, but I had to specifically request a limit increase to get access to the GPU instances. See http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-resource-limits.html
Apart from that I pay per hour without any subscription.
Hope it helps.
Nice one, thanks for the pointer Hugues.
Hi Katya,
I believe you may need to contact AWS support and request access to the larger hardware. They may need to perform a quick check of your account then approve access. This is often a very fast process.
Let me know how you go.
Hi Jason:
Thank you for posting this! I was wondering if jupyter notebook is preinstalled in this AMI or I have to do it myself? Thanks!
I don’t know Jenny, I do not use notebooks myself, just command line.
Hi,
I am running into several errors while running an Faster RCNN network on the ami-125b2c72. Which version of opencv do I install for this ami? Do I need to be changing/downgrading the versions of CUDA and cuDNN?
Hi Supriya, I did not install or upgrade anything other than is stated in the tutorial above. No opencv, and I did not touch cuda or cudnn.
When we stop the instance all the data will be erased, it seems a little annoying to redownload the datasets and configure our codes. Should we use EBS storage service? or what is your suggestion? Thanks
Correct.
Consider using storage like S3 for datasets. Take a look at the Amazon docs, but I think there is cost advantages in storing data in the amazon infrastructure.
Hi Jason, First of all Sorry for Off-topic discussion,
I would like to know, is it possible to run a Java Project developed on Eclipse Environment (lots of packages has imported while developing the project) on AWS Server to get the high computational speed? If yes, can you give some references for the above? I am new to Amazon AWS and I found the description is a bit complicated.
I like this tutorial from which any one can understand the steps very easily.
Regards
Yes I don’t see why not. I don’t have a tutorial or resources, sorry.
Hi Jason,
unfortunately ami-125b2c72 is not available anymore at least at us-east-1. Can you recommend the other one having Keras + GPU?
Best,
Nick
Sorry to hear that, I’ll look into a next best step.
Until then, I think this one is good:
https://github.com/ritchieng/tensorflow-aws-ami
Unfortunately this one is also not available: “Latest update: our Amazon credits has expired ¯\_(ツ)_/¯ As such, we are unable to host these AMIs on all regions “. Will try to run Kaggle ML image seems to be working one.
Hi Nick, the AMI is still available, I have just used it myself.
Hi Jason,
thank you for your effort, but I still can not find it. Today, I’ve searched again section “Community AMI’s” in region N.Virginia for name TFAMI.v3 and for ami-name: ami-0e969619. Did the same for N.California, checked TFAMI.v3 and ami-08451468. No ami’s found.
I think, you were able to find it because you saved it into “My AMI’s” list.
I agree Nick, it too is now gone.
I will find a solid replacement (or make one) and update the tutorial soon.
UPDATE: I have updated the tutorial to use a new better AMI.
Hi, did you decide not to update the AMI to keras v 2.0.2? Looks like the AMI has v 1.2.2
Note the section in the tutorial where I show how to update the version of Keras.
Thanks. And great tutorial by the way; it’s been a huge help. Thanks for sharing.
Thanks CK, I’m glad to hear that.
I realize this article was originally written over a year ago, but since the p2.xlarge instances are now available and the g2.2xlarge ones are roughly 1/2 speed is there any reason to still use the latter?
For a performance comparison see:
http://blog.bitfusion.io/2016/11/03/quick-comparison-of-tensorflow-gpu-performance-on-aws-p2-and-g2-instances
And, from the FAQ on the AWS site:
P2 instances use NVIDIA Tesla K80 GPUs and are designed for general purpose GPU computing using the CUDA or OpenCL programming models. P2 instances provide customers with high bandwidth 20Gbps networking, powerful single and double precision floating-point capabilities, and error-correcting code (ECC) memory, making them ideal for deep learning, high performance databases, computational fluid dynamics, computational finance, seismic analysis, molecular modeling, genomics, rendering, and other server-side GPU compute workloads. With the latest driver release, P2 instances support CUDA 7.5 and OpenCL 1.2.
G2 instances use NVIDIA GRID GPUs and provide a cost-effective, high-performance platform for graphics applications using DirectX or OpenGL. NVIDIA GRID GPUs also support NVIDIA’s fast capture and encode APIs. Example applications include video creation services, 3D visualizations, streaming graphics-intensive applications, and other server-side graphics workloads. With the initial driver release, G2 instances support DirectX 9, 10, and 11, OpenGL 4.3, CUDA 5.5, OpenCL 1.1, and DirectCompute.
Excellent, thanks for the note James!
Jason, your tutorials are some of the best out there. Thank you for creating these resources.
Any thoughts on AWS vs. Google Cloud ML?
Thanks Kim. No, I have not used Google but I have used AWS for years and trust it.
Hi,
What is the best( Right ) EC2 Instance Type to choose?
I mean instance type that fits my applications requirements for this course..?
should not be expensive nor cheap however has to be practical (speed and memory,..etc)
Depends on your problem. I do fine with g2 and p2 instances.
hi
I have tried many times to get through the instance (ami-dfb13ebf ) however when I reach the step 7 : (Step 7: Review Instance Launch)
Launch failed
I contacted AWS and i got this response :
(((Thank you for reaching out to us. The error message you are seeing is caused by not having access to the specific instance type. You do have a default on demand instance limit of twenty. We are happy to submit a limit increase request on your behalf, let us know what type of instance that you would like to request.
I hope this helps, let us know if you have any questions.
Best regards,))))
PLease help me to start this course , I did not start yet
and how to get through from putty as I have windows on my computer
thank you so much for help
Saeed
I would recommend contacting AWS support and asking for a change to your account so that you can access the instance.
Hello Jason!
First of all – Thank you so much for your blog and work. I’m a student interested in machine learning and for many things my starting point is your blog.
I am experimenting with LSTMs and timeseries-forecasts in the course of my master thesis and I am experiencing that gpu-based computing for example with the g2.2xlarg instance in aws is much slower than computation on a much cheaper cpu-only machine (even core i5 of my notebook).
Have you made similar experience ? I already read some blog and developer posts that the tensorflow backend has a slow implementation for lstm and many others that ran into that problem. I get nearly the same results with Theano. I already know that the batch size has significant potential to improve gpu, but not quite sure whether the sequential type of problem is the reason why gpu can’t outperform cpu.
Would be really cool to hear your opinion and experience.
For example:
https://news.ycombinator.com/item?id=14538086 or https://groups.google.com/forum/#!topic/neon-users/3BDEEO6v_24
or
https://groups.google.com/forum/#!topic/neon-users/3BDEEO6v_24
Kind regards,
Constantin
Hi Constantin,
Yes, I see this often and only with LSTM models. I am fitting caption generation models now (large language model component) and I may as well run on my local i7 rather than the GPUs on AWS.
Glad to hear it is a common problem. I do not dwell though, got work to do and I’ll run my code wherever, I just need the result.
Hi Jason ,
Asp per your blog I have take an aws account and rented an instance g2.2xlarge one.When I am running this code – 9.3 Grid Search Deep Learning Model Parameters ( This is from your book I have bought your book as well.) It is taking forever I have waited for 30 min. Should it take that much time in aws. I am new to aws so not sure which stage it is stuck in.
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import GridSearchCV
import numpy
# Function to create model, required for KerasClassifier
def create_model(optimizer=’rmsprop’, init=’glorot_uniform’):
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer=init, activation=’relu’))
model.add(Dense(8, kernel_initializer=init, activation=’relu’))
model.add(Dense(1, kernel_initializer=init, activation=’sigmoid’))
# Compile model
model.compile(loss=’binary_crossentropy’, optimizer=optimizer, metrics=[‘accuracy’])
return model
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt(“/home/ec2-user/pima-indians-diabetes.csv”, delimiter=”,”)
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = KerasClassifier(build_fn=create_model, verbose=0)
# grid search epochs, batch size and optimizer
optimizers = [‘rmsprop’, ‘adam’]
inits = [‘glorot_uniform’, ‘normal’, ‘uniform’]
epochs = [50, 100, 150]
batches = [5, 10, 20]
param_grid = dict(optimizer=optimizers, epochs=epochs, batch_size=batches, init=inits)
print param_grid
grid = GridSearchCV(estimator=model, param_grid=param_grid)
grid_result = grid.fit(X, Y)
# summarize results
print(“Best: %f using %s” % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_[‘mean_test_score’]
stds = grid_result.cv_results_[‘std_test_score’]
params = grid_result.cv_results_[‘params’]
for mean, stdev, param in zip(means, stds, params):
print(“%f (%f) with: %r” % (mean, stdev, param))
It should not take too long.
Running multi-threaded may cause problems for AWS with GPUs.
Try another simpler example to ensure the AWS instance is working correctly.
Try simplifying the grid search to 1 value for each parameter and see if that finishes in a reasonable time. Then scale up from there.
Let me know how you go.
Just to tell you Keras is using tensor flow as a backend. I hope it should not make a difference in performance ?
I use the TF backend primarily these days.
Hi Jason, I tried couple of small codes like cv and few small code. they worked fine. This one is taking time. I tried tweaking it but still taking lot of time. I am planning to run few codes on larger dataset . Will let you know about my findings.
Sure.
This article is awesome, like all of yours I’ve read. Thank you so much.
Would love a tutorial on how to get CNTK up and running under Keras in AWS, given the hype about its LSTM speed compared to TensorFlow and Theano.
I’m getting errors attempting to install CNTK using microsoft’s docs.
Thanks for the suggestion Stuart.
after running:
> python -c “import keras; print keras.__version__”
I get:
> Using TensorFlow backend.
> 2.0.8
I’m on g2.2xlarge right now with image: Deep Learning AMI Amazon Linux – 3.3_Oct2017 (ami-78994d02).
Is there some way I can ensure that GPUs are being used? When I run “pip list”, “tensorflow (1.3.0)” is listed, not tensorflow-gpu.
I’m also confused because I ran your pima indian code under #6 on https://machinelearningmastery.com/tutorial-first-neural-network-python-keras/, on the same Deep Learning AMI, and the code completed in about 15 seconds on a t2.large, but 45 seconds on p2.xlarge! These timing values were after I had run each one a few times.
Why would it be running significantly slower on the GPU instance?
Yes, I have a command you can use on this post to check if the GPU is being used and how heavily:
https://machinelearningmastery.com/command-line-recipes-deep-learning-amazon-web-services/
For small problems, the GPU may result in worse performance given the overhead. A large image classification problem like MNIST or CFIAR would be a good test.
Hi,
I’m having trouble implementing the tutorial. I’ve tried to used a different training text, but it’s quite a bit shorter than Alice in Wonderland, and all my model produces is the letter ‘a’ repeated 1000 times. Is this due to the training data not being extensive enough? Are there any rules of thumb about how much data is needed…?
Perhaps try training the model for longer?
Hi Jason,
I followed your instructions (chose the same cluster, downloaded same packages, etc).
I can download scikit-learn fine, but when I enter python and try and import sklearn, it tells me:
“ImportError: No module named sklearn”
I’ve tried many different ways of downloading scikit-learn, but nothing is working. Any tips on how to troubleshoot?
Thanks
Hi,
I was running
python [scriptname.py, but it works fine when I dopython3 [scriptname.py].False alarm!
Glad to hear it.
Sounds like sklearn is not being installed correctly.
Thanks for the great tutorial.
I’m training a convnet sample from the book “Deep Learning with Python.”
On my laptop, an underpowered ThinkPad T540, training takes about 55 seconds per epoch.
I ran the same code on an AWS Ubuntu GPU compute p2.xlarge instance and it still took 42 seconds per epoch.
I must be missing something. Is there something I might be doing wrong for it to be so slow on AWS.
Thanks,
Tim
Perhaps memory or HDD speed?
Perhaps the batch size or other config?
Thanks for the response Jason.
I was hoping that it would have been something obvious.
Do you know of a way to check that Keras and the TensorFlow backend are using the GPU?
When you start running your model, often tensorflow will print debug information about what GPU is being used.
You can also use nvidia tools to see GPU utilization, I give some command line things to type here:
https://machinelearningmastery.com/command-line-recipes-deep-learning-amazon-web-services/
Hello, I built a machine learning model in AWS (Type: Binary classification) and then evaluate it. And now I want to run this model 100 times to see the completion time and the cost of every run. Is there any methods to do that?
Sure, but you will have to write the code.
Awesome post.
Thanks, I’m glad it helped.
Update/FYI: AWS may have some new rules regarding launching g2.2xlarge and/or p2.xlarge instances (the GPU instances). I was not able to create an instance of either and had to contact amazon to “request limit increase” to increase my current limit of 0 instances on the above 2 types to 1. I’ve just submitted the request, will update this comment when the result of the review comes in.
However, while waiting for to get access to the gpu instances. I have walked through Jasons tutorial on the “free” instance. I’d suggest you go ahead and do this as there are a few steps to it. One issue I ran in to was, when I created my working instance, I attempted to use keys that were created while attempting to create another instance. This prevented me from ssh’ing into my new instance. For us new guys, you might want to create a new key with a new instance just to keep it simple in the beginning.
Wonderful tips, thanks for sharing Eric!
This is excellent. Thanks for the post.
I would like to know one more thing, how could I set up 2 AWS instances for distributed computing. As of now I have one AWS GPU instance on which I am training my DL models. I want to create one more and train the model in parallel so that training would be much faster. Is there a way I can do this?
Thank you,
KK
Sorry, I don’t have an example of distributed computing on AWS.
Thanks for the response Sir. 🙂
Then I use google colab GPU, it is only 3 times faster than CPU. shouldn’t the speed up be almost 10 times?
Depends on the hardware, the dataset, and on the type of model.
Hey Jason,
NonMaximum Supression is an approach to avoid double detections on the same object.
But if they are from different classes (on similar object) you get to instances on this object, independent from the NMS-Treshold.
My question is now:
how can i customize your code to say that it is just one object and he should take the more confidence class for this object.
So one object in reality should just be one object in detection.
Thank for your help.
Your project is nice.
I believe most models like yolo and rcnn implement NMS directly on the output. No need to dive into it.
So I have to put NMS on the output and do it for intersecting rectangles of different classes?
Yes.
Hey Jason, I’m getting an error from AWS about failure to launch – ” You have requested more vCPU capacity than your current vCPU limit of 0 allows for the instance bucket that the specified instance type belongs to.”. Do you know any workarounds?
Thanks!
Perhaps contact AWS support directly, they are very responsive.
I’ve been working with AWS to fix the issue but have had no success. They increased my vCPU limit to 10 and I still get the same error message. Also, when I try to restrict the access permissions on the key pair file I downloaded (named keras-keypair) by running the code you gave above (“chmod 600 keras-aws-keypair.pem”), I get an error message saying “no such file or directory”. I double checked and the file is in the appropriate directory. But when I try to run “chmod 600 keras-keypair.pem” I don’t get an error message. Could this be the source of the problem?
Thanks
Sorry to hear that you are still having trouble.
You must change the permission of the file from the command line when the file is in the same location as when you are typing the command.
If not, you must specify the full path to the file.
Hey how do you use any local editor and run notebooks off the cloud? I donot have a great laptop for machine learning and would like to run notebooks off the cloud
Sorry, I don’t use notebooks and don’t recommend using them:
https://machinelearningmastery.com/faq/single-faq/why-dont-use-or-recommend-notebooks
Hi Jason,
Have you ever tried using your laptop’s GPU. I recently installed tensorflow gpu in my laptop with a different environment. and, in another env i installed only tensorflow. the mnist example when run with and without gpu have the same time when trained.
Do you have any idea why was the performance not sped up with using GPU?
thank you always.
Hi tanuja…Thank you for your question! In order to obtain a performance increase with a GPU it is necessary to target functionality specifically designed to take advantage of the GPU architecture. The following resources may help in understanding how to train Keras models for the Amazon Web Services environment.
https://machinelearningmastery.com/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/