Captioning an image involves generating a human readable textual description given an image, such as a photograph.
It is an easy problem for a human, but very challenging for a machine as it involves both understanding the content of an image and how to translate this understanding into natural language.
Recently, deep learning methods have displaced classical methods and are achieving state-of-the-art results for the problem of automatically generating descriptions, called “captions,” for images.
In this post, you will discover how deep neural network models can be used to automatically generate descriptions for images, such as photographs.
After completing this post, you will know:
- About the challenge of generating textual descriptions for images and the need to combine breakthroughs from computer vision and natural language processing.
- About the elements that comprise a neural feature captioning model, namely the feature extractor and language model.
- How the elements of the model can be arranged into an Encoder-Decoder, possibly with the use of an attention mechanism.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Overview
This post is divided into 3 parts; they are:
- Describing an Image with Text
- Neural Captioning Model
- Encoder-Decoder Architecture
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Describing an Image with Text
Describing an image is the problem of generating a human-readable textual description of an image, such as a photograph of an object or scene.
The problem is sometimes called “automatic image annotation” or “image tagging.”
It is an easy problem for a human, but very challenging for a machine.
A quick glance at an image is sufficient for a human to point out and describe an immense amount of details about the visual scene. However, this remarkable ability has proven to be an elusive task for our visual recognition models
— Deep Visual-Semantic Alignments for Generating Image Descriptions, 2015.
A solution requires both that the content of the image be understood and translated to meaning in the terms of words, and that the words must string together to be comprehensible. It combines both computer vision and natural language processing and marks a true challenging problem in broader artificial intelligence.
Automatically describing the content of an image is a fundamental problem in artificial intelligence that connects computer vision and natural language processing.
— Show and Tell: A Neural Image Caption Generator, 2015.
Further, the problems can range in difficulty; let’s look at three different variations on the problem with examples.
1. Classify Image
Assign an image a class label from one of hundreds or thousands of known classes.

Example of classifying images into known classes
Taken From “Detecting avocados to zucchinis: what have we done, and where are we going?”, 2013.
2. Describe Image
Generate a textual description of the contents image.

Example of captions generated for photogaphs
Taken from “Long-term recurrent convolutional networks for visual recognition and description”, 2015.
3. Annotate Image
Generate textual descriptions for specific regions on the image.
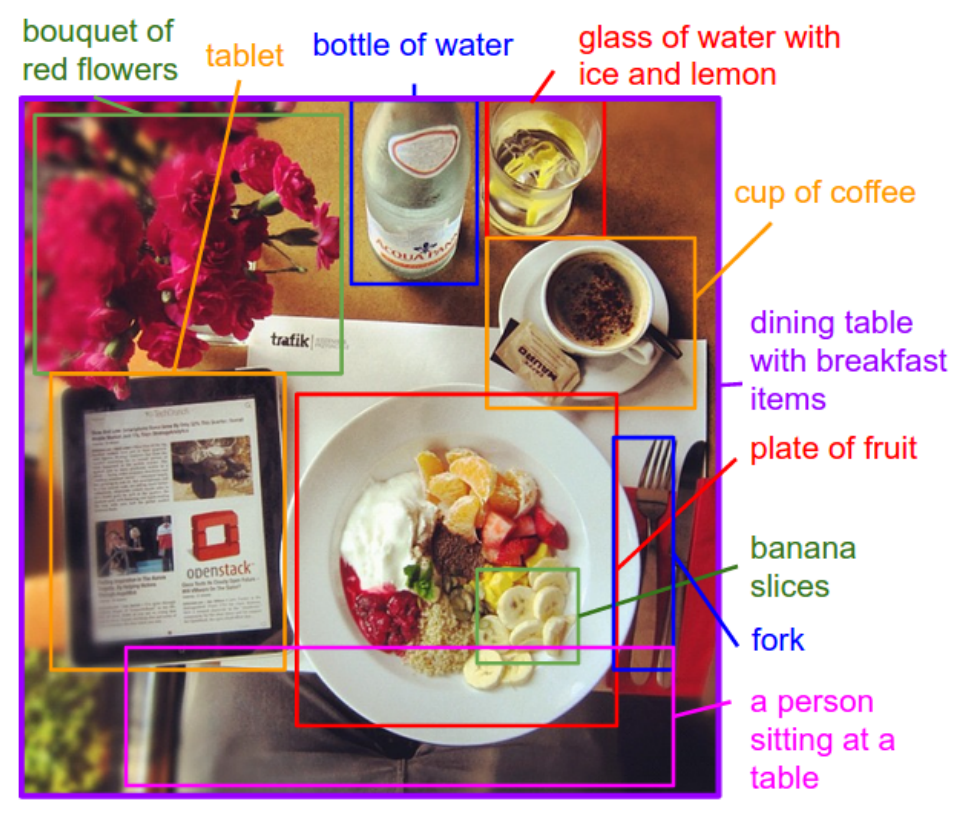
Example of annotation regions of an image with descriptions.
Taken from “Deep Visual-Semantic Alignments for Generating Image Descriptions”, 2015.
The general problem can also be extended to describe images over time in video.
In this post, we will focus our attention on describing images, which we will describe as ‘image captioning.’
Neural Captioning Model
Neural network models have come to dominate the field of automatic caption generation; this is primarily because the methods are demonstrating state-of-the-art results.
The two dominant methods prior to end-to-end neural network models for generating image captions were template-based methods and nearest-neighbor-based methods and modifying existing captions.
Prior to the use of neural networks for generating captions, two main approaches were dominant. The first involved generating caption templates which were filled in based on the results of object detections and attribute discovery. The second approach was based on first retrieving similar captioned images from a large database then modifying these retrieved captions to fit the query. […] Both of these approaches have since fallen out of favour to the now dominant neural network methods.
— Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2015.
Neural network models for captioning involve two main elements:
- Feature Extraction.
- Language Model.
Feature Extraction Model
The feature extraction model is a neural network that given an image is able to extract the salient features, often in the form of a fixed-length vector.
The extracted features are an internal representation of the image, not something directly intelligible.
A deep convolutional neural network, or CNN, is used as the feature extraction submodel. This network can be trained directly on the images in the image captioning dataset.
Alternately, a pre-trained model, such as a state-of-the-art model used for image classification, can be used, or some hybrid where a pre-trained model is used and fine tuned on the problem.
It is popular to use top performing models in the ImageNet dataset developed for the ILSVRC challenge, such as the Oxford Vision Geometry Group model, called VGG for short.
[…] we explored several techniques to deal with overfitting. The most obvious way to not overfit is to initialize the weights of the CNN component of our system to a pretrained model (e.g., on ImageNet)
— Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2015.
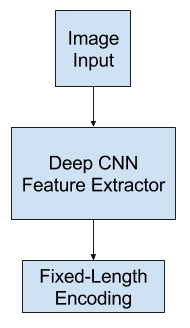
Feature Extractor
Language Model
Generally, a language model predicts the probability of the next word in the sequence given the words already present in the sequence.
For image captioning, the language model is a neural network that given the extracted features from the network is capable of predicting the sequence of words in the description and build up the description conditional on the words that have already been generated.
It is popular to use a recurrent neural network, such as a Long Short-Term Memory network, or LSTM, as the language model. Each output time step generates a new word in the sequence.
Each word that is generated is then encoded using a word embedding (such as word2vec) and passed as input to the decoder for generating the subsequent word.
An improvement to the model involves gathering the probability distribution of words across the vocabulary for the output sequence and searching it to generate multiple possible descriptions. These descriptions can be scored and ranked by likelihood. It is common to use a Beam Search for this search.
The language model can be trained standalone using pre-computed features extracted from the image dataset; it can be trained jointly with the feature extraction network, or some combination.
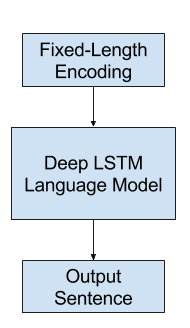
Language Model
Encoder-Decoder Architecture
A popular way to structure the sub-models is to use an Encoder-Decoder architecture where both models are trained jointly.
[the model] is based on a convolution neural network that encodes an image into a compact representation, followed by a recurrent neural network that generates a corresponding sentence. The model is trained to maximize the likelihood of the sentence given the image.
— Show and Tell: A Neural Image Caption Generator, 2015.
This is an architecture developed for machine translation where an input sequence, say in French, is encoded as a fixed-length vector by an encoder network. A separate decoder network then reads the encoding and generates an output sequence in the new language, say English.
A benefit of this approach in addition to the impressive skill of the approach is that a single end-to-end model can be trained on the problem.
When adapted for image captioning, the encoder network is a deep convolutional neural network, and the decoder network is a stack of LSTM layers.
[in machine translation] An “encoder” RNN reads the source sentence and transforms it into a rich fixed-length vector representation, which in turn in used as the initial hidden state of a “decoder” RNN that generates the target sentence. Here, we propose to follow this elegant recipe, replacing the encoder RNN by a deep convolution neural network (CNN).
— Show and Tell: A Neural Image Caption Generator, 2015.
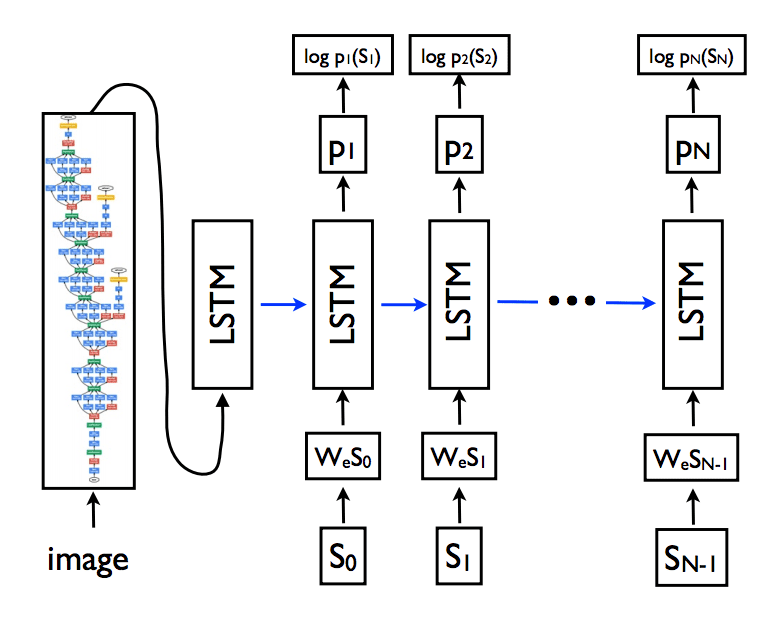
Example of the CNN and LSTM Architecture.
Taken from “Show and Tell: A Neural Image Caption Generator”, 2015.
Captioning Model with Attention
A limitation of the Encoder-Decoder architecture is that a single fixed-length representation is used to hold the extracted features.
This was addressed in machine translation through the development of attention across a richer encoding, allowing the decoder to learn where to place attention as each word in the translation is generated.
The approach of attention has also been used to improve the performance of the Encoder-Decoder architecture for image captioning by allowing the decoder to learn where to put attention in the image when generating each word in the description.
Encouraged by recent advances in caption generation and inspired by recent success in employing attention in machine translation and object recognition we investigate models that can attend to salient part of an image while generating its caption.
— Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2015.
A benefit of this approach is that it is possible to visualize exactly where attention is placed while generating each word in a description.
We also show through visualization how the model is able to automatically learn to fix its gaze on salient objects while generating the corresponding words in the output sequence.
— Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2015.
This is easiest to understand with an example; see below.

Example of image captioning with attention
Taken from “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”, 2015.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Papers
- Show and Tell: A Neural Image Caption Generator, 2015.
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2015.
- Long-term recurrent convolutional networks for visual recognition and description, 2015.
- Deep Visual-Semantic Alignments for Generating Image Descriptions, 2015.
Articles
- Automatic image annotation on Wikipedia
- Show and Tell: image captioning open sourced in TensorFlow, 2016.
- Presentation: Automated Image Captioning with ConvNets and Recurrent Nets, Andrej Karpathy and Fei-Fei Li (slides).
Projects
- Project: Deep Visual-Semantic Alignments for Generating Image Descriptions, 2015.
- NeuralTalk2: Efficient Image Captioning code in Torch, runs on GPU, Andrej Karpathy.
Summary
In this post, you discovered how deep neural network models can be used to automatically generate descriptions for images, such as photographs.
Specifically, you learned:
- About the challenge of generating textual descriptions for images and the need to combine breakthroughs from computer vision and natural language processing.
- About the elements that comprise a neural feature captioning model, namely the feature extractor and language model.
- How the elements of the model can be arranged into an Encoder-Decoder, possibly with the use of an attention mechanism.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Text Data Today!

Develop Your Own Text models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Natural Language Processing
It provides self-study tutorials on topics like:
Bag-of-Words, Word Embedding, Language Models, Caption Generation, Text Translation and much more...
Finally Bring Deep Learning to your Natural Language Processing Projects
Skip the Academics. Just Results.






This is awesome.
Thanks!
Excited with development of deep learning and New opportunities and ideas evolving around it. With basic understanding of ML and sklearn tools. What is best way to start exploring deep learning ?
Get started right here:
https://machinelearningmastery.com/start-here/#deeplearning
Lovely stuff Jason. Although there’s just overwhelming knowledge on this stuff especially for a PhD student. I think this will help us learn faster
Thanks, hang in there!
Hi Jason: Is there a basic running code for this task: 3. Annotate Image that I could get my hands on
Yes, I have a complete example in my book:
https://machinelearningmastery.com/deep-learning-for-nlp/
Excellent material,very useful.Thanks Jason.
I’m glad it helped.
Hi Jason, Is there an example for implementation of attention mechanism that was explained above? (show, attend, tell).
Thanks in advance,
Harathi
Good question, I list some places to search here:
https://machinelearningmastery.com/faq/single-faq/where-can-i-get-code-on-__
Thanks Jason,
I will take a look at them
Hi Jason. How far away are we from generating textual renders of video?
Textual rendering of layered frames and their temporal context/relationships to one another would seem to be exponentially more difficult, but wow – what a breakthrough that would be. One can imagine how machine descriptions could revolutionize a whole series of industries (journalism, intelligence, policy, screenwriting, etc).
Good question, a matter of a few years would be my guess. We have this for small cases now.
http://www.cs.utexas.edu/users/ml/papers/venugopalan.naacl15.pdf
Perfect. Thanks for the link.
Again Nice post Jason. I read your post with interest.Jason can i get this specific code of the post without buying this whole book? or do you have some book that have the implementation code of “image annotation” specifically.If you you have then i am ready to buy the whole book.because i am interested in the mentioned material only.again thank for sharing such a helping material.
Perhaps this post will help:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Hi Jason,
I have been informed that deep learning algorithms need much training data. What makes and which part of the algorithms need so much data?
Yes, deep learning algorithms can make use of more data if available and performance can continue to improve.
HI Jason! Are you going to implement this in keras as well? Or have you already done this? It will be a good read too!
Yes, right here:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Hi Jason,
I’ve been wondering that how can the model be trained if we use the different input images that should output the same image captioning, say “a boy jumps into the pool.”. Doesn’t it rather confuse the model? I mean, the model should output different captions corresponding to different input images, right? In other words, do we have to show the model various versions of captions for “a boy jumps into the pool.” images for the label of different input images, to make the model to be trained better?
Thank you in advance!
Kyu
Excellent question!
It may. Or it may act like a data augmentation technique and regularize the learning algorithm (my guess).
Sounds like an interesting question to explore!
can this be used to generate descriptions for charts /tables?
Wow, cool idea.
Perhaps.
Maybe try it. The hard part is getting a good dataset to train the model.
Hope this does not sound too crazy.
I want a human to look at images and generate the captions and speak the captions to the machine, and then have the machine view the images PLUS “read” my captions and learn how to categorize my captions, and THEN make learn how to make predictions about what I am looking at.
I can see relationships in Data/Images that it are difficult to encode.
So, it is much easier for me to merely dictate what I see, instead of forcing me to encode it.
Allow me to simply dictate the labels, and then let the machine learn from my labels…without me having to encode and load the code into a spreadsheet or database.
Not sure if I am explaining this correctly, but I could show you an example.
I am actually thinking of using images of a DataTable…and I describe what I see in the DataTable Image.
So, for example, I could look at Image of Graph showing IQ results for Students. And I describe what I see in the Graph, and I tell the machine which students Graduated, and which ones did not.
And machine learns to predict who graduates by ME dictating to Alexa what features I can see in the Graph of their IQ score results in different IQ tasks.
Does that make any sense?
Perhaps try building your idea and see?
I’m sorry to have been unclear: I am asking if it is possible and feasible to do such a thing. I have no means of knowing if it can be built, or how. I thought you would be able to point me in the right direction if it was.
I answered the best that I can, e.g. the only effective way to answer questions like this is to explore a prototype model.
hi jason , please i need the programme of Automatically Generate Textual Descriptions for Photographs with Deep Learning
Hi Houssem…Please provide a specific question regarding the given tutorial and the code listings provided to get you started so that I may better assist you.
Hi Jason, Is there possibility automatic describe all content of image (Full scene) in Text Its automated complete image to text generation. If there any books or writing from you…
Hi Sri…the following is a great starting point:
https://www.tensorflow.org/text/tutorials/text_generation