We write a program to solve a problem or make a tool that we can repeatedly solve a similar problem. For the latter, it is inevitable that we come back to revisit the program we wrote, or someone else is reusing the program we write. There is also a chance that we will encounter data that we didn’t foresee at the time we wrote our program. After all, we still want our program to work. There are some techniques and mentalities we can use in writing our program to make our code more robust.
After finishing this tutorial, you will learn
- How to prepare your code for the unexpected situation
- How to give an appropriate signal for situations that your code cannot handle
- What are the good practices to write a more robust program
Kick-start your project with my new book Python for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started!
Techniques to Write Better Python Code
Photo by Anna Shvets. Some rights reserved.
Overview
This tutorial is divided into three parts; they are:
- Sanitation and assertive programming
- Guard rails and offensive programming
- Good practices to avoid bugs
Sanitation and Assertive Programming
When we write a function in Python, we usually take in some argument and return some value. After all, this is what a function supposed to be. As Python is a duck-typing language, it is easy to see a function accepting numbers to be called with strings. For example:
|
1 2 3 4 |
def add(a, b): return a + b c = add("one", "two") |
This code works perfectly fine, as the + operator in Python strings means concatenation. Hence there is no syntax error; it’s just not what we intended to do with the function.
This should not be a big deal, but if the function is lengthy, we shouldn’t learn there is something wrong only at a later stage. For example, our program failed and terminated because of a mistake like this only after spending hours in training a machine learning model and wasting hours of our time waiting. It would be better if we could proactively verify what we assumed. It is also a good practice to help us communicate to other people who read our code what we expect in the code.
One common thing a fairly long code would do is to sanitize the input. For example, we may rewrite our function above as the following:
|
1 2 3 4 |
def add(a, b): if not isinstance(a, (int, float)) or not isinstance(b, (int, float)): raise ValueError("Input must be numbers") return a + b |
Or, better, convert the input into a floating point whenever it is possible:
|
1 2 3 4 5 6 7 |
def add(a, b): try: a = float(a) b = float(b) except ValueError: raise ValueError("Input must be numbers") return a + b |
The key here is to do some “sanitization” at the beginning of a function, so subsequently, we can assume the input is in a certain format. Not only do we have better confidence that our code works as expected, but it may also allow our main algorithm to be simpler because we ruled out some situations by sanitizing. To illustrate this idea, we can see how we can reimplement the built-in range() function:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def range(a, b=None, c=None): if c is None: c = 1 if b is None: b = a a = 0 values = [] n = a while n < b: values.append(n) n = n + c return values |
This is a simplified version of range() that we can get from Python’s built-in library. But with the two if statements at the beginning of the function, we know there are always values for variables a, b, and c. Then, the while loop can be written as such. Otherwise, we have to consider three different cases that we call range(), namely, range(10), range(2,10), and range(2,10,3), which will make our while loop more complicated and error-prone.
Another reason to sanitize the input is for canonicalization. This means we should make the input in a standardized format. For example, a URL should start with “http://,” and a file path should always be a full absolute path like /etc/passwd instead of something like /tmp/../etc/././passwd. Canonicalized input is easier to check for conformation (e.g., we know /etc/passwd contains sensitive system data, but we’re not so sure about /tmp/../etc/././passwd).
You may wonder if it is necessary to make our code lengthier by adding these sanitations. Certainly, that is a balance you need to decide on. Usually, we do not do this on every function to save our effort as well as not to compromise the computation efficiency. We do this only where it can go wrong, namely, on the interface functions that we expose as API for other users or on the main function where we take the input from a user’s command line.
However, we want to point out that the following is a wrong but common way to do sanitation:
|
1 2 3 4 |
def add(a, b): assert isinstance(a, (int, float)), "`a` must be a number" assert isinstance(b, (int, float)), "`b` must be a number" return a + b |
The assert statement in Python will raise the AssertError exception (with the optional message provided) if the first argument is not True. While there is not much practical difference between raising AssertError and raising ValueError on unexpected input, using assert is not recommended because we can “optimize out” our code by running with the -O option to the Python command, i.e.,
|
1 |
$ python -O script.py |
All assert in the code script.py will be ignored in this case. Therefore, if our intention is to stop the code from execution (including you want to catch the exception at a higher level), you should use if and explicitly raise an exception rather than use assert.
The correct way of using assert is to help us debug while developing our code. For example,
|
1 2 3 4 5 6 7 |
def evenitems(arr): newarr = [] for i in range(len(arr)): if i % 2 == 0: newarr.append(arr[i]) assert len(newarr) * 2 >= len(arr) return newarr |
While we develop this function, we are not sure our algorithm is correct. There are many things to check, but here we want to be sure that if we extracted every even-indexed item from the input, it should be at least half the length of the input array. When we try to optimize the algorithm or polish the code, this condition must not be invalidated. We keep the assert statement at strategic locations to make sure we didn’t break our code after modifications. You may consider this as a different way of unit testing. But usually, we call it unit testing when we check our functions’ input and output conformant to what we expect. Using assert this way is to check the steps inside a function.
If we write a complex algorithm, it is helpful to add assert to check for loop invariants, namely, the conditions that a loop should uphold. Consider the following code of binary search in a sorted array:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def binary_search(array, target): """Binary search on array for target Args: array: sorted array target: the element to search for Returns: index n on the array such that array[n]==target if the target not found, return -1 """ s,e = 0, len(array) while s < e: m = (s+e)//2 if array[m] == target: return m elif array[m] > target: e = m elif array[m] < target: s = m+1 assert m != (s+e)//2, "we didn't move our midpoint" return -1 |
The last assert statement is to uphold our loop invariants. This is to make sure we didn’t make a mistake on the logic to update the start cursor s and end cursor e such that the midpoint m wouldn’t update in the next iteration. If we replaced s = m+1 with s = m in the last elif branch and used the function on certain targets that do not exist in the array, the assert statement will warn us about this bug. That’s why this technique can help us write better code.
Guard Rails and Offensive Programming
It is amazing to see Python comes with a NotImplementedError exception built-in. This is useful for what we call offensive programming.
While the input sanitation is to help align the input to a format that our code expects, sometimes it is not easy to sanitize everything or is inconvenient for our future development. One example is the following, in which we define a registering decorator and some functions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import math REGISTRY = {} def register(name): def _decorator(fn): REGISTRY[name] = fn return fn return _decorator @register("relu") def rectified(x): return x if x > 0 else 0 @register("sigmoid") def sigmoid(x): return 1/(1 + math.exp(-x)) def activate(x, funcname): if funcname not in REGISTRY: raise NotImplementedError(f"Function {funcname} is not implemented") else: func = REGISTRY[funcname] return func(x) print(activate(1.23, "relu")) print(activate(1.23, "sigmoid")) print(activate(1.23, "tanh")) |
We raised NotImplementedError with a custom error message in our function activate(). Running this code will print you the result for the first two calls but fail on the third one as we haven’t defined the tanh function yet:
|
1 2 3 4 5 6 7 8 |
1.23 0.7738185742694538 Traceback (most recent call last): File "/Users/MLM/offensive.py", line 28, in <module> print(activate(1.23, "tanh")) File "/Users/MLM/offensive.py", line 21, in activate raise NotImplementedError(f"Function {funcname} is not implemented") NotImplementedError: Function tanh is not implemented |
As you can imagine, we can raise NotImplementedError in places where the condition is not entirely invalid, but it’s just that we are not ready to handle those cases yet. This is useful when we gradually develop our program, which we implement one case at a time and address some corner cases later. Having these guard rails in place will guarantee our half-baked code is never used in the way it is not supposed to. It is also a good practice to make our code harder to be misused, i.e., not to let variables go out of our intended range without notice.
In fact, the exception handling system in Python is mature, and we should use it. When you never expect the input to be negative, raise a ValueError with an appropriate message. Similarly, when something unexpected happens, e.g., a temporary file you created disappeared at the midway point, raise a RuntimeError. Your code won’t work in these cases anyway, and raising an appropriate exception can help future reuse. From the performance perspective, you will also find that raising exceptions is faster than using if-statements to check. That’s why in Python, we prefer “it’s easier to ask for forgiveness than permission” (EAFP) over “look before you leap” (LBYL).
The principle here is that you should never let the anomaly proceed silently as your algorithm will not behave correctly and sometimes have dangerous effects (e.g., deleting wrong files or creating cybersecurity issues).
Want to Get Started With Python for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Good Practices to Avoid Bugs
It is impossible to say that a piece of code we wrote has no bugs. It is as good as we tested it, but we don’t know what we don’t know. There are always potential ways to break the code unexpectedly. However, there are some practices that can promote good code with fewer bugs.
First is the use of the functional paradigm. While we know Python has constructs that allow us to write an algorithm in functional syntax, the principle behind functional programming is to make no side effect on function calls. We never mutate something, and we don’t use variables declared outside of the function. The “no side effect” principle is powerful in avoiding a lot of bugs since we can never mistakenly change something.
When we write in Python, there are some common surprises that we find mutated a data structure unintentionally. Consider the following:
|
1 2 3 |
def func(a=[]): a.append(1) return a |
It is trivial to see what this function does. However, when we call this function without any argument, the default is used and returned us [1]. When we call it again, a different default is used and returned us [1,1]. It is because the list [] we created at the function declaration as the default value for argument a is an initiated object. When we append a value to it, this object is mutated. The next time we call the function will see the mutated object.
Unless we explicitly want to do this (e.g., an in-place sort algorithm), we should not use the function arguments as variables but should use them as read-only. And in case it is appropriate, we should make a copy of it. For example,
|
1 2 3 4 5 6 7 8 9 10 |
LOGS = [] def log(action): LOGS.append(action) data = {"name": None} for n in ["Alice", "Bob", "Charlie"]: data["name"] = n ... # do something with `data` log(data) # keep a record of what we did |
This code intended to keep a log of what we did in the list LOGS, but it did not. While we work on the names “Alice,” “Bob,” and then “Charlie,” the three records in LOGS will all be “Charlie” because we keep the mutable dictionary object there. It should be corrected as follows:
|
1 2 3 4 5 |
import copy def log(action): copied_action = copy.deepcopy(action) LOGS.append(copied_action) |
Then we will see the three distinct names in the log. In summary, we should be careful if the argument to our function is a mutable object.
The other technique to avoid bugs is not to reinvent the wheel. In Python, we have a lot of nice containers and optimized operations. You should never try to create a stack data structure yourself since a list supports append() and pop(). Your implementation would not be any faster. Similarly, if you need a queue, we have deque in the collections module from the standard library. Python doesn’t come with a balanced search tree or linked list. But the dictionary is highly optimized, and we should consider using the dictionary whenever possible. The same attitude applies to functions too. We have a JSON library, and we shouldn’t write our own. If we need some numerical algorithms, check if you can get one from NumPy.
Another way to avoid bugs is to use better logic. An algorithm with a lot of loops and branches would be hard to follow and may even confuse ourselves. It would be easier to spot errors if we could make our code clearer. For example, making a function that checks if the upper triangular part of a matrix contains any negative would be like this:
|
1 2 3 4 5 6 7 8 9 10 |
def neg_in_upper_tri(matrix): n_rows = len(matrix) n_cols = len(matrix[0]) for i in range(n_rows): for j in range(n_cols): if i > j: continue # we are not in upper triangular if matrix[i][j] < 0: return True return False |
But we also use a Python generator to break this into two functions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def get_upper_tri(matrix): n_rows = len(matrix) n_cols = len(matrix[0]) for i in range(n_rows): for j in range(n_cols): if i > j: continue # we are not in upper triangular yield matrix[i][j] def neg_in_upper_tri(matrix): for element in get_upper_tri(matrix): if element[i][j] < 0: return True return False |
We wrote a few more lines of code, but we kept each function focused on one topic. If the function is more complicated, separating the nested loop into generators may help us make the code more maintainable.
Let’s consider another example: We want to write a function to check if an input string looks like a valid floating point or integer. We require the string to be “0.12” and not accept “.12“. We need integers to be like “12” but not “12.“. We also do not accept scientific notations like “1.2e-1” or thousand separators like “1,234.56“. To make things simpler, we also do not consider signs such as “+1.23” or “-1.23“.
We can write a function to scan the string from the first character to the last and remember what we saw so far. Then check whether what we saw matched our expectation. The code is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def isfloat(floatstring): if not isinstance(floatstring, str): raise ValueError("Expects a string input") seen_integer = False seen_dot = False seen_decimal = False for char in floatstring: if char.isdigit(): if not seen_integer: seen_integer = True elif seen_dot and not seen_decimal: seen_decimal = True elif char == ".": if not seen_integer: return False # e.g., ".3456" elif not seen_dot: seen_dot = True else: return False # e.g., "1..23" else: return False # e.g. "foo" if not seen_integer: return False # e.g., "" if seen_dot and not seen_decimal: return False # e.g., "2." return True print(isfloat("foo")) # False print(isfloat(".3456")) # False print(isfloat("1.23")) # True print(isfloat("1..23")) # False print(isfloat("2")) # True print(isfloat("2.")) # False print(isfloat("2,345.67")) # False |
The function isfloat() above is messy with a lot of nested branches inside the for-loop. Even after the for-loop, the logic is not entirely clear for how we determine the Boolean value. Indeed we can use a different way to write our code to make it less error-prone, such as using a state machine model:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
def isfloat(floatstring): if not isinstance(floatstring, str): raise ValueError("Expects a string input") # States: "start", "integer", "dot", "decimal" state = "start" for char in floatstring: if state == "start": if char.isdigit(): state = "integer" else: return False # bad transition, can't continue elif state == "integer": if char.isdigit(): pass # stay in the same state elif char == ".": state = "dot" else: return False # bad transition, can't continue elif state == "dot": if char.isdigit(): state = "decimal" else: return False # bad transition, can't continue elif state == "decimal": if not char.isdigit(): return False # bad transition, can't continue if state in ["integer", "decimal"]: return True else: return False print(isfloat("foo")) # False print(isfloat(".3456")) # False print(isfloat("1.23")) # True print(isfloat("1..23")) # False print(isfloat("2")) # True print(isfloat("2.")) # False print(isfloat("2,345.67")) # False |
Visually, we implement the diagram below into code. We maintain a state variable until we finish scanning the input string. The state will decide to accept a character in the input and move to another state or reject the character and terminate. This function returns True only if it stops at the acceptable states, namely, “integer” or “decimal.” This code is easier to understand and more structured.
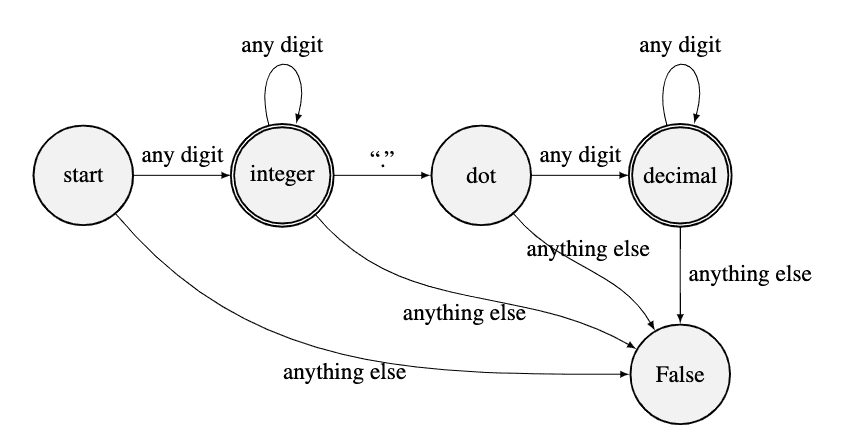
In fact, the better approach is to use a regular expression to match the input string, namely,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import re def isfloat(floatstring): if not isinstance(floatstring, str): raise ValueError("Expects a string input") m = re.match(r"\d+(\.\d+)?$", floatstring) return m is not None print(isfloat("foo")) # False print(isfloat(".3456")) # False print(isfloat("1.23")) # True print(isfloat("1..23")) # False print(isfloat("2")) # True print(isfloat("2.")) # False print(isfloat("2,345.67")) # False |
However, a regular expression matcher is also running a state machine under the hood.
There is way more to explore on this topic. For example, how we can better segregate responsibilities of functions and objects to make our code more maintainable and easier to understand. Sometimes, using a different data structure can let us write simpler code, which helps make our code more robust. It is not a science, but almost always, bugs can be avoided if the code is simpler.
Finally, consider adopting a coding style for your project. Having a consistent way to write code is the first step in offloading some of your mental burdens later when you read what you have written. This also makes you spot mistakes easier.
Further reading
This section provides more resources on the topic if you are looking to go deeper.
Articles
Books
- Building Secure Software by John Viega and Gary R. McGraw
- Building Secure and Reliable Systems by Heather Adkins et al
- The Hitchhiker’s Guide to Python by Kenneth Reitz and Tanya Schlusser
- The Practice of Programming by Brian Kernighan and Rob Pike
- Refactoring, 2nd Edition, by Martin Fowler
Summary
In this tutorial, you have seen the high-level techniques to make your code better. It can be better prepared for a different situation, so it works more rigidly. It can also be easier to read, maintain, and extend, so it is fit for reuse in the future. Some techniques mentioned here are generic to other programming languages as well.
Specifically, you learned:
- Why we would like to sanitize our input, and how it can help make our program simpler
- The correct way of using
assertas a tool to help development - How to use Python exceptions appropriately to give signals in unexpected situations
- The pitfall in Python programming in handling mutable objects
Get a Handle on Python for Machine Learning!

Be More Confident to Code in Python
...from learning the practical Python tricks
Discover how in my new Ebook:
Python for Machine Learning
It provides self-study tutorials with hundreds of working code to equip you with skills including:
debugging, profiling, duck typing, decorators, deployment,
and much more...






How to convert our machine learning code to simple software consist of file, edit and exit thank you very much.
If you want to build a UI to interact with your model in production, there are several python GUI frameworks available like pyGUI
Great tutorial, thank you!
In function
def neg_in_upper_tri(matrix):
for element in get_upper_tri(matrix):
if element[i][j] < 0:
return True
return False
it should just be element (instead of element[i][j]), right?
Hi Eric…You are very welcome! Did you receive an error with the provided code? Please share your findings.