The No Free Lunch Theorem is often thrown around in the field of optimization and machine learning, often with little understanding of what it means or implies.
The theorem states that all optimization algorithms perform equally well when their performance is averaged across all possible problems.
It implies that there is no single best optimization algorithm. Because of the close relationship between optimization, search, and machine learning, it also implies that there is no single best machine learning algorithm for predictive modeling problems such as classification and regression.
In this tutorial, you will discover the no free lunch theorem for optimization and search.
After completing this tutorial, you will know:
The no free lunch theorem suggests the performance of all optimization algorithms are identical, under some specific constraints.
There is provably no single best optimization algorithm or machine learning algorithm.
The practical implications of the theorem may be limited given we are interested in a small subset of all possible objective functions.
Kick-start your project with my new book Optimization for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
No Free Lunch Theorem for Machine Learning Photo by Francisco Anzola, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
What Is the No Free Lunch Theorem?
Implications for Optimization
Implications for Machine Learning
What Is the No Free Lunch Theorem?
The No Free Lunch Theorem, often abbreviated as NFL or NFLT, is a theoretical finding that suggests all optimization algorithms perform equally well when their performance is averaged over all possible objective functions.
The NFL stated that within certain constraints, over the space of all possible problems, every optimization technique will perform as well as every other one on average (including Random Search)
The theorem applies to optimization generally and to search problems, as optimization can be described or framed as a search problem.
The implication is that the performance of your favorite algorithm is identical to a completely naive algorithm, such as random search.
Roughly speaking we show that for both static and time dependent optimization problems the average performance of any pair of algorithms across all possible problems is exactly identical.
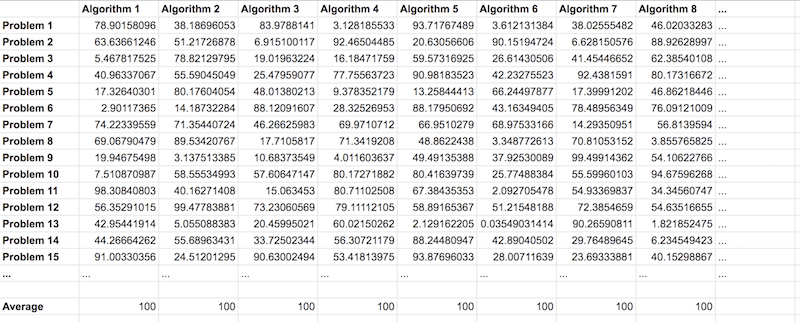
An easy way to think about this finding is to consider a large table like you might have in excel.
Across the top of the table, each column represents a different optimization algorithm. Down the side of the table, each row represents a different objective function. Each cell of the table is the performance of the algorithm on the objective function, using whatever performance measure you like, as long as it is consistent across the whole table.
Depiction on the No Free Lunch Theorem as a Table of Algorithms and Problems
You can imagine that this table will be infinitely large. Nevertheless, in this table, we can calculate the average performance of any algorithm from all the values in its column and it will be identical to the average performance of any other algorithm column.
If one algorithm performs better than another algorithm on one class of problems, then it will perform worse on another class of problems
Now that we are familiar with the no free lunch theorem in general, let’s look at the specific implications for optimization.
Want to Get Started With Optimization Algorithms?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Implications for Optimization
So-called black-box optimization algorithms are general optimization algorithms that can be applied to many different optimization problems and assume very little about the objective function.
Examples of black-box algorithms include the genetic algorithm, simulated annealing, and particle swarm optimization.
The no free lunch theorem was proposed in an environment of the late 1990s where claims of one black-box optimization algorithm being better than another optimization algorithm were being made routinely. The theorem pushes back on this, indicating that there is no best optimization algorithm, that it is provably impossible.
The theorem does state that no optimization algorithm is any better than any other optimization algorithm, on average.
… known as the “no free lunch” theorem, sets a limit on how good a learner can be. The limit is pretty low: no learner can be better than random guessing!
The catch is that the application of algorithms does not assume anything about the problem. In fact, algorithms are applied to objective functions with no prior knowledge, even such as whether the objective function is minimizing or maximizing. And this is a hard constraint of the theorem.
We often have “some” knowledge about the objective function being optimized. In fact, if in practice we truly knew nothing about the objective function, we could not choose an optimization algorithm.
As elaborated by the no free lunch theorems of Wolpert and Macready, there is no reason to prefer one algorithm over another unless we make assumptions about the probability distribution over the space of possible objective functions.
The beginner practitioner in the field of optimization is counseled to learn and use as much about the problem as possible in the optimization algorithm.
The more we know and harness in the algorithms about the problem, the better tailored the technique is to the problem and the more likely the algorithm is expected to perform well on the problem. The no free lunch theorem supports this advice.
We don’t care about all possible worlds, only the one we live in. If we know something about the world and incorporate it into our learner, it now has an advantage over random guessing.
Additionally, the performance is averaged over all possible objective functions and all possible optimization algorithms. Whereas in practice, we are interested in a small subset of objective functions that may have a specific structure or form and algorithms tailored to those functions.
… we cannot emphasize enough that no claims whatsoever are being made in this paper concerning how well various search algorithms work in practice The focus of this paper is on what can be said a priori without any assumptions and from mathematical principles alone concerning the utility of a search algorithm.
These implications lead some practitioners to note the limited practical value of the theorem.
This is of considerable theoretical interest but, I think, of limited practical value, because the space of all possible problems likely includes many extremely unusual and pathological problems which are rarely if ever seen in practice.
Now that we have reviewed the implications of the no free lunch theorem for optimization, let’s review the implications for machine learning.
Implications for Machine Learning
Learning can be described or framed as an optimization problem, and most machine learning algorithms solve an optimization problem at their core.
The no free lunch theorem for optimization and search is applied to machine learning, specifically supervised learning, which underlies classification and regression predictive modeling tasks.
This means that all machine learning algorithms are equally effective across all possible prediction problems, e.g. random forest is as good as random predictions.
So all learning algorithms are the same in that: (1) by several definitions of “average”, all algorithms have the same average off-training-set misclassification risk, (2) therefore no learning algorithm can have lower risk than another one for all f …
This also has implications for the way in which algorithms are evaluated or chosen, such as choosing a learning algorithm via a k-fold cross-validation test harness or not.
… an algorithm that uses cross validation to choose amongst a prefixed set of learning algorithms does no better on average than one that does not.
It also has implications for common heuristics for what constitutes a “good” machine learning model, such as avoiding overfitting or choosing the simplest possible model that performs well.
Another set of examples is provided by all the heuristics that people have come up with for supervised learning avoid overfitting prefer simpler to more complex models etc. [no free lunch] says that all such heuristics fail as often as they succeed.
Given that there is no best single machine learning algorithm across all possible prediction problems, it motivates the need to continue to develop new learning algorithms and to better understand algorithms that have already been developed.
As a consequence of the no free lunch theorem, we need to develop many different types of models, to cover the wide variety of data that occurs in the real world. And for each model, there may be many different algorithms we can use to train the model, which make different speed-accuracy-complexity tradeoffs.
It also supports the argument of testing a suite of different machine learning algorithms for a given predictive modeling problem.
The “No Free Lunch” Theorem argues that, without having substantive information about the modeling problem, there is no single model that will always do better than any other model. Because of this, a strong case can be made to try a wide variety of techniques, then determine which model to focus on.
Nevertheless, as with optimization, the implications of the theorem are based on the choice of learning algorithms having zero knowledge of the problem that is being solved.
In practice, this is not the case, and a beginner machine learning practitioner is encouraged to review the available data in order to learn something about the problem that can be incorporated into the learning algorithm.
We may even want to take this one step further and say that learning is not possible without some prior knowledge and that data alone is not enough.
In the meantime, the practical consequence of the “no free lunch” theorem is that there’s no such thing as learning without knowledge. Data alone is not enough.
It provides self-study tutorials with full working code on: Gradient Descent, Genetic Algorithms, Hill Climbing, Curve Fitting, RMSProp, Adam,
and much more...
Bring Modern Optimization Algorithms to Your Machine Learning Projects
I am just a practitioner student and have a question.
What about the models based on gradient boosting, such as XGboost, LightGBM? They are frequently considered to perform better than many other optimization techniques. Usually, this seems to be true on a bunch of different problems (subset of functions). What could we infer from the theorem in this case?
What is the no-free lunch theorem? How does it apply in ICT with regards to Information Systems and businesses, and Information Security and businesses?
How does a no free lunch apply in information communication technology with regards to information system and business, and information security systems
Is it just my impression or some folks here are simply copying/pasting college homework questions as comments?!?!? Don’t cheat guys!!! Congrats, Jason, the post is a very good explanation!
Thanks for the article! I am obsessed with the generality of machine learning algorithms but something is a bit off about the idea.. and there it is the no free lunch theorem.
1. In the NFL, why the accuracy of results is ignored (only the efficiency is discussed)?
The average function call of the random search (for all possible problems) is equal to other approaches and the random search mathematically converges to accurate solution with the probability 1. But, the other approaches may fail to find proper solution (global optimum). Why this fact is always neglected?
If the accuracy is matter, is the proposed NFL proof correct?
2. We may consider gradient based optimization approaches (i.e. SQP) as block-box optimization algorithm (i.e. by estimating gradients using finite difference in analysis). Then, can we compare it with random Monte Carlo Sampling? are these two types of search methods are equal from NFL point of view? (I ask this just to be ensure about the perception of NFL).
Thanks for your time and sharing your research results.
1. Try to limit the cost of random search (e.g., stop at loop 1000), then that’s what you should compare. If you allow all algorithms to try for infinite amount of time (with random initial solution, for example), you will see it can equal to your description of random search too.
Thank you very much. But I believe that something is wrong here.
I think our information about the dimension of search problem (i.e. number of variables) affects the generality of NFL proof. For example, some algorithms are developed to solve high-dimensional problems (we can name them “problem dependent algorithms”).
Once we want to solve a high dimensional problem, knowing the size of the optimization problem (number of variables), we can use them in our analyses.
Therefore, if we only compare two algorithms (one is developed for small size problems, one developed for high dimensional problems), the overall perfjoamcne may not be same. It seems that there is always some free launches (since we always know the size of the problem).
The idea of understanding NFL is that there is always cost associated and no one is always better than another. If you have a specific problem or dataset, and I have a look up table to give you the answer right away. My cost is zero? Of course not, because I haven’t generalized to all problems. And I haven’t consider the cost of building the look up table.
Thank you for your response Adrian,
You are right and I’m agreeing with you.
According to my understanding, “NFL also says that for a black-box problem, no algorithm is better than others”. I say: “This is not true” (This is completely different with what you presented in the response).
We know that considering size of a black-box problem, algorithms that are consistent with the size of the problem are better than others (i.e. if the problem has 10000 design variables, algorithms that are designed to solve high-dimensional problems perfroms better than others and vice versa). I hope this is clarifying.
Anyway, thank you very much for your time and responses.
Hi Sampath…A larger network is not always the best option. If you should go with a larger network, keep in mind the following:
I recommend running large models or long-running experiments on a server.
I recommend only using your workstation for small experiments and for figuring out what large experiments to run. I talk more about this approach here:
Machine Learning Development Environment
I recommend using Amazon EC2 service as it provides access to Linux-based servers with lots of RAM, lots of CPU cores, and lots of GPU cores (for deep learning).
You can learn how to setup an EC2 instance for machine learning in these posts:
How To Develop and Evaluate Large Deep Learning Models with Keras on Amazon Web Services
How to Train XGBoost Models in the Cloud with Amazon Web Services
You can learn useful commands when working on the server instance in this post:
10 Command Line Recipes for Deep Learning on Amazon Web Services
“We may even want to take this one step further and say that learning is not possible without some prior knowledge and that data alone is not enough.”
Could I change “knowledge” for “assumption”?
These things lead me to ontologic questions. We do not know the world; we just shift assumptions (paradigms) on it, based on our learnings from precedent assumptions.
I guess, those that trained a machine on Othello (the board game) with just coordinates of succesive moves in complete games (a lot of them) did not cheated by researching the most suitable model for learning that (I mean, programming Othello or its board in some way into the model architecture) and just picked a “reasonable” or “feasible” one (the same for the efficiency of the training method). (I’m referring to those that found kind of a board structure inside the weights of the model, once trained). (Sorry for the fuzziness of my language; I read about that in a popular science article; I’m a complete newbie on the tield, and I couldn’t even locate the research article to improve this description).
Thanks for the article to the author and to the publishers. I find amazing to access these contents, and to have the opportunity to leave this comment here, not to say the possibility of receiving an answer…
Thank you Juan for your post! Although we do not cover reinforcement learning in our content, you may wish to investigate the state of the art in this field. Very interesting work that touches on many of the ideas you presented in your post.
(Have I got to reply my own comment?) I’ve just find out what I read about the LLM’s world-model constructions in the paradigm of the Othello boardgame:l. The research article sketched there is
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
Kenneth Li, Aspen K. Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, Martin Wattenberg








Excellent article! Thank you, Jason.
I am just a practitioner student and have a question.
What about the models based on gradient boosting, such as XGboost, LightGBM? They are frequently considered to perform better than many other optimization techniques. Usually, this seems to be true on a bunch of different problems (subset of functions). What could we infer from the theorem in this case?
Thanks!
It suggests that may well on many examples in the small subset of all problems we are interested in solving.
NFLT is way more general.
What is the no-free lunch theorem? How does it apply in ICT with regards to Information Systems and businesses, and Information Security and businesses?
See the above tutorial on exactly this topic.
where exactly
The tutorial is on the topic of the no free lunch theorem.
How does a no free lunch apply in information communication technology with regards to information system and business, and information security systems
Is it just my impression or some folks here are simply copying/pasting college homework questions as comments?!?!? Don’t cheat guys!!! Congrats, Jason, the post is a very good explanation!
They are!
Thanks for the article! I am obsessed with the generality of machine learning algorithms but something is a bit off about the idea.. and there it is the no free lunch theorem.
You’re welcome.
thank you
Thank you for the helpful article, Jason.
I have two questions:
1. In the NFL, why the accuracy of results is ignored (only the efficiency is discussed)?
The average function call of the random search (for all possible problems) is equal to other approaches and the random search mathematically converges to accurate solution with the probability 1. But, the other approaches may fail to find proper solution (global optimum). Why this fact is always neglected?
If the accuracy is matter, is the proposed NFL proof correct?
2. We may consider gradient based optimization approaches (i.e. SQP) as block-box optimization algorithm (i.e. by estimating gradients using finite difference in analysis). Then, can we compare it with random Monte Carlo Sampling? are these two types of search methods are equal from NFL point of view? (I ask this just to be ensure about the perception of NFL).
Thanks for your time and sharing your research results.
1. Try to limit the cost of random search (e.g., stop at loop 1000), then that’s what you should compare. If you allow all algorithms to try for infinite amount of time (with random initial solution, for example), you will see it can equal to your description of random search too.
2. Yes.
Thank you very much. But I believe that something is wrong here.
I think our information about the dimension of search problem (i.e. number of variables) affects the generality of NFL proof. For example, some algorithms are developed to solve high-dimensional problems (we can name them “problem dependent algorithms”).
Once we want to solve a high dimensional problem, knowing the size of the optimization problem (number of variables), we can use them in our analyses.
Therefore, if we only compare two algorithms (one is developed for small size problems, one developed for high dimensional problems), the overall perfjoamcne may not be same. It seems that there is always some free launches (since we always know the size of the problem).
Is my conclusion wrong?
The idea of understanding NFL is that there is always cost associated and no one is always better than another. If you have a specific problem or dataset, and I have a look up table to give you the answer right away. My cost is zero? Of course not, because I haven’t generalized to all problems. And I haven’t consider the cost of building the look up table.
Thank you for your response Adrian,
You are right and I’m agreeing with you.
According to my understanding, “NFL also says that for a black-box problem, no algorithm is better than others”. I say: “This is not true” (This is completely different with what you presented in the response).
We know that considering size of a black-box problem, algorithms that are consistent with the size of the problem are better than others (i.e. if the problem has 10000 design variables, algorithms that are designed to solve high-dimensional problems perfroms better than others and vice versa). I hope this is clarifying.
Anyway, thank you very much for your time and responses.
what about a huge neural network?
Hi Sampath…A larger network is not always the best option. If you should go with a larger network, keep in mind the following:
I recommend running large models or long-running experiments on a server.
I recommend only using your workstation for small experiments and for figuring out what large experiments to run. I talk more about this approach here:
Machine Learning Development Environment
I recommend using Amazon EC2 service as it provides access to Linux-based servers with lots of RAM, lots of CPU cores, and lots of GPU cores (for deep learning).
You can learn how to setup an EC2 instance for machine learning in these posts:
How To Develop and Evaluate Large Deep Learning Models with Keras on Amazon Web Services
How to Train XGBoost Models in the Cloud with Amazon Web Services
You can learn useful commands when working on the server instance in this post:
10 Command Line Recipes for Deep Learning on Amazon Web Services
“We may even want to take this one step further and say that learning is not possible without some prior knowledge and that data alone is not enough.”
Could I change “knowledge” for “assumption”?
These things lead me to ontologic questions. We do not know the world; we just shift assumptions (paradigms) on it, based on our learnings from precedent assumptions.
I guess, those that trained a machine on Othello (the board game) with just coordinates of succesive moves in complete games (a lot of them) did not cheated by researching the most suitable model for learning that (I mean, programming Othello or its board in some way into the model architecture) and just picked a “reasonable” or “feasible” one (the same for the efficiency of the training method). (I’m referring to those that found kind of a board structure inside the weights of the model, once trained). (Sorry for the fuzziness of my language; I read about that in a popular science article; I’m a complete newbie on the tield, and I couldn’t even locate the research article to improve this description).
Thanks for the article to the author and to the publishers. I find amazing to access these contents, and to have the opportunity to leave this comment here, not to say the possibility of receiving an answer…
Thank you Juan for your post! Although we do not cover reinforcement learning in our content, you may wish to investigate the state of the art in this field. Very interesting work that touches on many of the ideas you presented in your post.
https://www.youtube.com/watch?v=SupFHGbytvA&list=PL_iWQOsE6TfVYGEGiAOMaOzzv41Jfm_Ps
(Have I got to reply my own comment?) I’ve just find out what I read about the LLM’s world-model constructions in the paradigm of the Othello boardgame:l. The research article sketched there is
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
Kenneth Li, Aspen K. Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, Martin Wattenberg
the one in the following link:
https://arxiv.org/abs/2210.13382?utm_campaign=The%20Batch&utm_source=hs_email&utm_medium=email&_hsenc=p2ANqtz-8Nb-a1BUHkAvW21WlcuyZuAvv0TS4IQoGggo5bTi1WwYUuEFH4RunaPClPpQPx7iBhn-BH
I read about it at the beginning of https://www.deeplearning.ai/the-batch/issue-209
Thanks for letting me clarify it.
Thank you Juan for providing this update for everyone!