
What is Machine Learning? We can read authoritative definitions of machine learning, but really, machine learning is defined by the problem being solved. Therefore the best way to understand machine learning is to look at some example problems.
In this post we will first look at some well known and understood examples of machine learning problems in the real world. We will then look at a taxonomy (naming system) for standard machine learning problems and learn how to identify a problem as one of these standard cases. This is valuable, because knowing the type of problem we are facing allows us to think about the data we need and the types of algorithms to try.
10 Examples of Machine Learning Problems
Machine Learning problems are abound. They make up core or difficult parts of the software you use on the web or on your desktop everyday. Think of the “do you want to follow” suggestions on twitter and the speech understanding in Apple’s Siri.
Below are 10 examples of machine learning that really ground what machine learning is all about.
- Spam Detection: Given email in an inbox, identify those email messages that are spam and those that are not. Having a model of this problem would allow a program to leave non-spam emails in the inbox and move spam emails to a spam folder. We should all be familiar with this example.
- Credit Card Fraud Detection: Given credit card transactions for a customer in a month, identify those transactions that were made by the customer and those that were not. A program with a model of this decision could refund those transactions that were fraudulent.
- Digit Recognition: Given a zip codes hand written on envelops, identify the digit for each hand written character. A model of this problem would allow a computer program to read and understand handwritten zip codes and sort envelops by geographic region.
- Speech Understanding: Given an utterance from a user, identify the specific request made by the user. A model of this problem would allow a program to understand and make an attempt to fulfil that request. The iPhone with Siri has this capability.
- Face Detection: Given a digital photo album of many hundreds of digital photographs, identify those photos that include a given person. A model of this decision process would allow a program to organize photos by person. Some cameras and software like iPhoto has this capability.
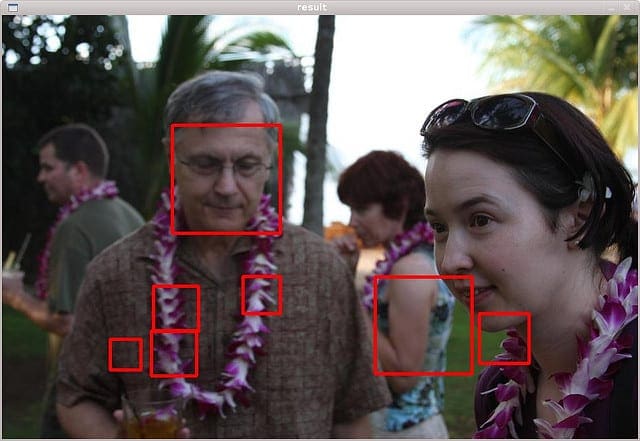
Example of Face Detection in a Photo.
Photo by mr. ‘sto Licensed under a Attribution-ShareAlike 2.0 Generic Creative Commons License.
- Product Recommendation: Given a purchase history for a customer and a large inventory of products, identify those products in which that customer will be interested and likely to purchase. A model of this decision process would allow a program to make recommendations to a customer and motivate product purchases. Amazon has this capability. Also think of Facebook, GooglePlus and LinkedIn that recommend users to connect with you after you sign-up.
- Medical Diagnosis: Given the symptoms exhibited in a patient and a database of anonymized patient records, predict whether the patient is likely to have an illness. A model of this decision problem could be used by a program to provide decision support to medical professionals.
- Stock Trading: Given the current and past price movements for a stock, determine whether the stock should be bought, held or sold. A model of this decision problem could provide decision support to financial analysts.
- Customer Segmentation: Given the pattern of behaviour by a user during a trial period and the past behaviours of all users, identify those users that will convert to the paid version of the product and those that will not. A model of this decision problem would allow a program to trigger customer interventions to persuade the customer to covert early or better engage in the trial.
- Shape Detection: Given a user hand drawing a shape on a touch screen and a database of known shapes, determine which shape the user was trying to draw. A model of this decision would allow a program to show the platonic version of that shape the user drew to make crisp diagrams. The Instaviz iPhone app does this.
These 10 examples give a good sense of what a machine learning problem looks like. There is a corpus of historic examples, there is a decision that needs to be modelled and a business or domain benefit to having that decision modelled and efficaciously made automatically.
Some of these problems are some of the hardest problems in Artificial Intelligence, such as Natural Language Processing and Machine Vision (doing things that humans do easily). Others are still difficult, but are classic examples of machine learning such as spam detection and credit card fraud detection.
Think about some of your interactions with online and offline software in the last week. I’m sure you could easily guess at another ten or twenty examples of machine learning you have directly or indirectly used.
Types of Machine Learning Problems
Reading through the list of example machine learning problems above, I’m sure you can start to see similarities. This is a valuable skill, because being good at extracting the essence of a problem will allow you to think effectively about what data you need and what types of algorithms you should try.
There are common classes of problem in Machine Learning. The problem classes below are archetypes for most of the problems we refer to when we are doing Machine Learning.
- Classification: Data is labelled meaning it is assigned a class, for example spam/non-spam or fraud/non-fraud. The decision being modelled is to assign labels to new unlabelled pieces of data. This can be thought of as a discrimination problem, modelling the differences or similarities between groups.
- Regression: Data is labelled with a real value (think floating point) rather then a label. Examples that are easy to understand are time series data like the price of a stock over time, The decision being modelled is what value to predict for new unpredicted data.
- Clustering: Data is not labelled, but can be divided into groups based on similarity and other measures of natural structure in the data. An example from the above list would be organising pictures by faces without names, where the human user has to assign names to groups, like iPhoto on the Mac.
- Rule Extraction: Data is used as the basis for the extraction of propositional rules (antecedent/consequent aka if-then). Such rules may, but are typically not directed, meaning that the methods discover statistically supportable relationships between attributes in the data, not necessarily involving something that is being predicted. An example is the discovery of the relationship between the purchase of beer and diapers (this is data mining folk-law, true or not, it’s illustrative of the desire and opportunity).
When you think a problem is a machine learning problem (a decision problem that needs to be modelled from data), think next of what type of problem you could phrase it as easily or what type of outcome the client or requirement is asking for and work backwards.
Resources
There are few resources that provide lists of real-world machine learning problems. They may be out there, but I can’t find them. I still found some cool resources for you though:
- The Annual “Humies” Awards: These are a list of prizes awarded to results achieved by algorithms that are competitive with those results come up with by humans. It’s exciting because the algorithms are working only from data or cost functions and are able to be creative and inventive enough to infringe on patents. Amazing!
- The AI Effect: The notion where as soon as an Artificial Intelligence program achieves a good enough result it is no longer regarded as Artificial Intelligence, instead it is just technology and gets used in every day things. Applies just as equally to Machine Learning.
- AI-Complete: refers to very difficult problems in Artificial Intelligence that if solved would be an example of Strong AI (AI as envisioned in science fiction, true AI). The problems of Computer Vision and Natural Language Processing are both examples of AI-Complete problems and may also be considered domain-specific categories of machine learning problems.
- What are the Top 10 problems in Machine Learning for 2013? This Quora question has some excellent answers, and one that lists some broad categories of practical machine learning problems.
We have reviewed some common examples of real-world machine learning problems and a taxonomy of classes of machine learning problems. We now have some confidence to comment on whether a problem is a machine learning problem or not and to pick out the elements from a problem description and determine whether it is a classification, regression, clustering or rule extraction type of problem.
Do you know of some more real-world machine learning problems? Leave a comment and share your thoughts.



")


Why can’t Machine Learning predict Stock Prices yet?
Given the fact that historical information of Stock Price is available.
Is it merely becz Historical Info. by itself is not enough to predict a future price? Seems to be the case.
It’s a really hard problem. I’m afraid it’s that simple.
To do well, I understand you need a vast array of different methods working together.
1st even if people manage to predict stock prices – what happens? It’s simply another level of entropy where our bounded rationality gets better we might claim that we become more rational. In other words, if we have enough dimension to understanding the stock prices then we end up getting better at it as we have been with our weather prediction. Does it solve any problem of humanity at all?
The reason why machine learning cannot (and will likely never) be able to predict stock prices is because the past performance of a stock is not an indicator of its future performance. In other words, there is nothing to “learn”.
What we know:
Stocks go up because there are more buyers than sellers. Stocks go down because there are more sellers than buyers. THAT’S ABOUT IT.
Stock prices are driven by market factors which include how the organisation is doing…what plans it has for the furture growth etc apart from other factors. Any random incorrect news could jeopardize the stock price and shoot it down. There are apparently a host of factors that any machine learning algorithm should consider and find a solution for, to be able to do a regression on predicting stock prices. The dynamics are so huge that it may take a huger effort to come out with a relatively scalable solution.
In fact ML can successfully be applied to stock movements, and is by some hedge funds. However, because the market is a zero-sum game, success implicitly requires secrecy: if the successful ML approach was publicly disclosed, others would use it and the approach would no longer be successful. A corollary to this is that any successful approach cannot scale infinitely, so even though you may have a successful ML approach, the more you use it, the less return you will get on it. That is why hedge funds can’t just find a working ML approach and then grow to infinite size.
Steve Jobs dies, Apple shares fall…
Malaysia Airlines plane crashes, MA shares fall…
MA plane shot down, MA shares fall…
Horse DNA in Tesco food, shares fall…
Manufacturer factory in Bangladesh falls down, American brand shares fall..
Unless I’m missing something, I struggle to see how a machine will be able to forecast any of these events by looking purely at prior share prices?
Of course it’s not possible to predict those events by looking at prior share prices. I don’t think anybody is under the illusion that it is possible to perfectly model all price movements. The goal is just to get it right as often as you can. These are models, after all — that means they’re not perfect.
With that said, it actually is possible to take these events into account in an ML model (though, as you point out, not using prior share prices alone). You can’t predict them, but you can try to *react* to them faster than the market does. Many hedge funds use things like news feeds, press releases and Twitter as sources of data, applying natural language processing techniques like sentiment analysis to look for signals that could presage movements in the stock market.
What James just quoted are rare events and predicting them is mostly impossible within any window of predictive accuracy (earthquake prediction is another example of the same).Having said that, the catastrophic events with the share market can be very difficult to model or predict as they are rare and random (but not very frequent).This is not the same with events that are in my opinion “constructive”, i.e. Apple has posted for the longest decades y.o.y profits and introduced the right products at the right time (ipod, iphone, ipad etc.) and anyone with few tools of machine learning in his box would be able to track and add these to his/her model (as rightly said by some i.e. nlp, text feed mining, sentiment mining, social media analytics, sales/customers/competitor data modeling etc.) and place their bets on the Apple share price accordingly.
Uncertainties makes it difficult to learn. I can imagine that when all the possible combinations of uncertainties which affect stock prices are input to ML to learn, then only Ml would be able to predict. However, this seems practically difficult.
We can also predict those events by feeding in the historical events of disaster and how the markets reacted to those disasters in the past, we can list down the historical disasters and the volatility in the market as reaction to those events
We know that rumours can drive stock prices.
We use machine learning to predict sentiment of social media posts (rumours) about listed companies. We have found that the net sentiment score is a predictor under certain circumstances.
Because stocks are manipulated, the past data are irrelevant.
A belated reply to qnaguru —
Here is a link to a video presentation that discusses trading system development using machine learning:
https://www.youtube.com/watch?v=v729evhMpYk&feature=youtu.be
Best,
Howard
Thank you for the video link Mr. Bandy. It helped.
stock prices are affected by confounding variables that affects ML algorithm performance. Oil prices can be affected by wars, political stupidity, and other factors not very available to an algorithm, so forecasting a trend becomes very difficult.
Something called arbitraged out the signal. If a hedge fund is able to find a signal that helps predict stock price, soon peers starts replicating the strategy and the predictive power decreases. And if your signal is so secretive and not replicated by anyone, than u gaurd it with your life by not taking outside money to invest and thus not able to reveal the core of your strategy. There r multiple research papers that document how the predictive power of a signal reduces as more and more firms replicate the strategy. And to begin with, financial data has aot of noise, thats surely doesnt help.
Does not sounds like a game I want to play.
Machine learning problem shouls able to surely wats the hypothesis set, the feature under train and testing and whats the learning strategy, then only a problem can percept in the view of solving as machine learing problem.
Answering the question ”qnaguru” posted I would like to suggest you read ‘Predictive Analytics – The Power to Predict Who Will Click, Buy, Lie or Die’ which presents the brilliance of Machine Learning in the current marketing scenarion. Its also mentioned in the ‘Machine Learning Foundations’ by Jason.
Great info. Lucky me I discovered your website by accident
(stumbleupon). I have book marked it for later!
We are trying to apply machine learning to
– Identifying new drivers to monitor safety at a work place in the oil and gas industry.
safety analytics- anyone has any input on what techniques were used on massive amounts of structured and unstructured data that we have with us and we are currently trying to look at how we can identify new drivers to monitor incidents that lead to fatality and that way allow for business to build in monitoring capabilities around it.
-HR: identify who is most “like me”. to automize the recruitment process as much as possible so HR can be more efficient at finding the right candidate and we can eliminate the more manual aspects to this.
any insights or ideas or papers that anyone can share?
what techniques were applied?
how you worked on the data set?
how was the data presented?
all suggestions welcome.
Thanks,
Suchitra.
Thanks for this post! o/
Thanks for this information,its a good learning ground…
HI Jasin, great post! One question: could you do a multithreading sample for face detection? Thanks!
Thanks for the suggestion.
I look for predictive analysis need to identify faults in machinery making data mining sensor reading can you help me?
I am working on exactly this problem using vibration monitoring systems. Please email me and we can discuss and try to help one another solve this problem. Leo@machinesaver.net
Excellent post! Thank you, Jason.
You’re welcome Jim.
I am not sure where things like learning to drive, or learning knowledge of a domain (eg math learning systems) fall into your 4 way classification?
I think they are more general systems problems, the finer grained elements of which may use machine learning.
There’s nice picture which explains the principle of machine learning – https://www.cleveroad.com/images/article-previews/computer-science-fields.png
One of the reasons of the renewed chatbots popularity is a sweeping development of Machine Learning technology. But what is it? Isn’t it an artificial intelligence that makes chatbots communicate with people? Truly said, no. Developers are still far away from creating a real artificial intelligence. However, they have already achieved the significant results in one of its subfields – in machine learning.
Machine learning is focused on the development of the programs that can learn from patterns and previous experiences.
Machine learning algorithms are used in chatbots development, so they could learn from conversations with users to optimize their next interactions.
For me, I see chatbots as more AI than machine learning.
My focus with machine learning is on predictive modeling. Making models that can do classification and regression and varients of those problems.
Hello Jason Brownlee Please help me where i can get cancer cell for data analytics data sets
Consider searching kaggle and the uci machine learning repository.
Hi Jason, what would be a good open source machine learning platform to solve a predictive or recommendation system solution where based on past data of user preferences, product liking, category preferences, market conditions, latest customer trends and maybe even sales data, we want to build a system to recommend products and categories to the customer.
Good question, I have not gone deep into recommender systems (other than coding my own from scratch). I don’t know what the best platform might be – perhaps sklearn in Python would be a good starting point.
Just a comment regarding stock market price prediction. Machine Learning can obviously help with making stock market predictions, but it will never be a certainty. I invest in shares myself and have manually analysed trends to find stocks that follow a particular pattern. These stocks make a better investment because gains are better able to be predicted. I think it’d be a good use of ML to find these kinds of stocks first, rather than attempting to make predictions on any particular stock.
Thanks Tim. It’s totally not my area.
Liked the article a lot. can u please describe more about credit card fraud .
latest techniques ,solutions ,issues .
Thanks
Thanks.
Sorry, I don’t have examples of credit card fraud at the moment.
I am work on hand gesture recognition. where dataset comprised of video sequence for each gesture can I chose limited number of frames from each video and the use RNN for classify this gestures. or RNN can classify video that have (35-100) frames
Great question.
Consider a CNN front end. Consider exploring different frame rates and compare model skill.
Pls. can you explain in more detial
Sorry, I do not have examples of working with video, I hope to have some soon.
For the guys above asking if ML could be applied to stock exchange, it is being done in fact: https://en.wikipedia.org/wiki/High-frequency_trading This kind of algorythmic trading it´s starting to be more known.
Excellent post-Jason.
Kind Regards
Amitava
Thanks Amitava.
Thanks for enlightening me! 🙂
I’m glad it helped.
This is a very good post. It defines some of the areas where machine learning truly shines, such as recommendations and spam detection. I’ll also add self-driving cars! With the huge increase in popularity of deep learning, many advancements in the field have been made thanks to the goal of teaching a deep neural network how to drive a car. In fact, MIT offers a specific class on Deep Learning for Self-Driving cars: https://selfdrivingcars.mit.edu/
Again, nice article Jason! Congratulations!
Thanks.
On “Product Recommendation” you wrote Facebook twice: “Also think of Facebook, GooglePlus and Facebook that recommend users to connect with you after you sign-up.”
Thanks, fixed.
Jason,
I am trying to apply ML to a problem in product testing. Large number of tests are run producing failures. I want to group failures into clusters based on similarity.
Though I am still working with different feature selection, how does one validate the results. Is it a manual review and acceptance by users OR is there any automated way? If some grouping (clusters) are not right, how does one locate the problem? In this problem, there is no labeled data, hence manual review and acceptance seems to be only way.
Any inputs will help
Sorry, I don’t have material on clustering, mainly because I don’t.
Validating clusters is a huge problem. It feels like voodoo to me (not science), hence I stay away.
Thanks for your quick response. let me find other options
Nice post.After reading I am able to understand and classify real world problems towards MI
Thanks for the post.
Thanks, I’m happy that it helped.
I have started reading about Machine Learning a few days ago, and it has risen my interest in ML field. After reading about use cases and the challenges that may occur, I can now understand the whole topic.
Thanks for such an informative one.
Keep Posting
Cheers!
I’m glad it helped.
suggest to me with a mini project idea(ML).
See this:
https://machinelearningmastery.com/faq/single-faq/what-machine-learning-project-should-i-work-on
Such a useful article with great content
Thanks!
cool stuff you have and you keep overhaul every one of us
Thanks!
Excellent article. Thank you, Jason!
You’re welcome.