The Transformer architecture, introduced in 2017, revolutionized sequence-to-sequence tasks like language translation by eliminating the need for recurrent neural networks. Instead, it relies on self-attention mechanisms to process input sequences. In this post, you’ll learn how to build a Transformer model from scratch. In particular, you will understand:
How self-attention processes input sequences
How transformer encoder and decoder work
How to implement a complete translation system with a transformer
Building a Transformer Model for Language Translation Photo by Sorasak. Some rights reserved.
Overview
This post is divided into six parts; they are:
Why Transformer is Better than Seq2Seq
Data Preparation and Tokenization
Design of a Transformer Model
Building the Transformer Model
Causal Mask and Padding Mask
Training and Evaluation
Why Transformer is Better than Seq2Seq
Traditional seq2seq models with recurrent neural networks have two main limitations:
Sequential processing prevents parallelization
Limited ability to capture long-term dependencies since hidden states are overwritten whenever an element is processed
The Transformer architecture, introduced in the 2017 paper “Attention is All You Need”, overcomes these limitations. It can use the self-attention mechanism to capture dependencies between any position in the sequence. It can process the entire sequence in parallel. The sequence processing ability of a transformer model does not depend on recurrent connections.
Data Preparation and Tokenization
In this post, you will build a transformer model for translation, as this is the typical use case of a full transformer.
The dataset you will use is the English-French translation dataset from Anki, which contains pairs of English and French sentences. This is the same dataset you used in a previous post, and the preparation steps are similar.
French text contains accents and complex verb conjugations, requiring more sophisticated tokenization than simple word splitting. Byte-Pair Encoding (BPE) effectively handles these subword units and morphologically rich languages. It is also a good solution to handle unknown words.
Firstly, you would like to download the dataset and read it into memory. The dataset is a plain text file, and each line is an English and French sentence separated by a tab character. Below is how you can download and read the dataset:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import os
import unicodedata
import zipfile
import requests
# Download dataset provided by Anki: https://www.manythings.org/anki/ with requests
French sentences use Unicode characters, which can have multiple representation forms. We normalize the text to the “NFKC” form for consistent representation before processing. This is a good practice to make sure the text is “clean” so that the model can focus on the actual content of the text.
The translation pairs in text_pairs are pairs of strings of the complete sentences. You can use them to train a tokenizer in BPE, which you can use for the tokenization of future sentences:
The code above uses the tokenizers library from Hugging Face to train the tokenizers. The trained tokenizers are saved as a JSON file for reuse. When you trained the tokenizers, you added three special tokens: [start], [end], and [pad]. These tokens are used to mark the beginning and end of the sentence and to pad the sequence to the same length. The tokenizers are set with enable_padding() such that when you use the tokenizer to process a string, padding tokens will be added. You will see how they are used in the following sections.
Below is an example of how you can use the tokenizer:
The tokenizer not only splits the text into tokens, but also provides a way to encode the tokens into integer IDs. This is essential for the transformer model, as the model needs to process the input sequence as a sequence of numbers.
Design of a Transformer Model
A transformer combines an encoder and decoder. The encoder features multiple layers of self-attention and feed-forward networks, while the decoder incorporates cross-attention as well. The encoder processes the input sequence, and the decoder generates the output sequence, just like the case of the seq2seq model. Yet, there are many variations in a transformer model. Common architectural variations include:
Positional Encoding: Provides positional information, as transformers process sequences in parallel. There are multiple strategies for passing the position of an element in the sequence to the model.
Attention Mechanism: While scaled dot-product attention is standard, variations in its implementation, such as multi-head attention (MHA), multi-query attention (MQA), grouped query attention (GQA), and multi-head latent attention (MLA), exist at the model level. This is because each attention layer in a transformer model consists of multiple attention “heads” operating in parallel. These are the different ways to apply the input to the different heads.
Feed-forward Network: This is a multi-layer perceptron network, but you can pick a different activation function or number of layers. In cases where a large model needs to handle a wide variety of inputs, a mixture-of-experts network can be used as an alternative to the feed-forward network.
Layer Normalization: Layer norm or RMS norm should be applied between the attention and feed-forward networks. You can either use the “pre-norm” or “post-norm” with skip connections.
Hyperparameters: For the same design, you can scale the model by adjusting the size of the hidden dimension, the number of heads/layers, the dropout rate, and the maximum sequence length that the model should support.
In this post, let’s use the following:
Positional Encoding: Rotary Positional Encoding, with the maximum sequence length of 768
Attention Mechanism: Grouped-Query Attention, with 8 query heads and 4 key-value heads
Feed-forward Network: Two-layer SwiGLU, with a dimension of 512 in the hidden layer
Layer Normalization: RMS Norm, in pre-norm
Hidden dimension: 128
Number of encoder and decoder layers: 4
Dropout rate: 0.1
The transformer model to be built
The model you will build is illustrated as follows:
Building the Transformer Model
Various positional encoding methods and their implementations are covered in the previous post. For RoPE, this is the PyTorch implementation:
For $\mathbf{x}_m$ representing a pair $(i, d/2+i)$ of elements in the vector at position $m$. The exact matrix used depends on the position $m$ of the vector in the sequence.
RoPE differs from the original Transformer’s sinusoidal positional encoding in that it is applied within the attention sublayer rather than outside it.
The attention you will use is the Grouped-Query Attention (GQA). PyTorch supports GQA, but in the attention sublayer, you should implement the projection of the query, key, and value. An implementation of GQA is covered in a previous post but below is an extended version that allows you to use it not only in self-attention, but also in cross-attention:
Note that in the forward() method of the GQA class, you can specify the positional encoding module in the rope argument. This makes the positional encoding optional. In PyTorch, for an optimized attention computation, the input tensors should be a contiguous block in memory. The line q = q.contiguous() is used to restructure the tensor if it is not already contiguous.
The feed-forward network you will use is the two-layer SwiGLU. The SwiGLU activation function is unique in that PyTorch does not support it, but it can be implemented using the SiLU activation. Below is an implementation of the feed-forward network using SwiGLU, from a previous post:
1
2
3
4
5
6
7
8
9
10
11
12
classSwiGLU(nn.Module):
def __init__(self,hidden_dim,intermediate_dim):
super().__init__()
self.gate=nn.Linear(hidden_dim,intermediate_dim)
self.up=nn.Linear(hidden_dim,intermediate_dim)
self.down=nn.Linear(intermediate_dim,hidden_dim)
self.act=nn.SiLU()
def forward(self,x):
x=self.act(self.gate(x))*self.up(x)
x=self.down(x)
returnx
With this, you can now build the encoder and decoder layers. The encoder layer is simpler, as it consists of a self-attention layer followed by a feed-forward network. However, you still need to implement skip connections and pre-norm using RMS norm. Below is the implementation of the encoder layer:
The feed-forward network was implemented as SwiGLU module defined previously. You can see that the intermediate dimension is defined as 4 times the size of the hidden dimension. This is a common design in the industry, but you can experiment with a different ratio.
The decoder layer is more complex, as it consists of a self-attention layer, followed by a cross-attention layer, and finally a feed-forward network. The implementation is as follows:
You can see that both the self-attention and cross-attention sublayers are implemented using the GQA class. The difference is in how they are used in the forward() method. RoPE is applied to both, but the mask is only used in the self-attention sublayer.
The transformer model is built to connect encoders and decoders, but before passing on the sequence into the encoders or decoders, the input sequence of token IDs are first converted into embedding vectors. It is implemented as follows:
You can see that the Transformer class has numerous parameters in its constructor. This is because it serves as the entry point to create the entire model, which the Transformer class will initiate all sub-layers. This is a good design since you can define a Python dictionary as a model config. Below is an example of how you can create the model using the classes defined above:
The first step in training the model is to create a dataset object that can be used to iterate over the dataset in batches and a random order. In the previous section, you read the dataset into a list text_pairs. You also created the tokenizers for English and French. Now you can use the Dataset class from PyTorch to create a dataset object. Below is an implementation of the dataset object:
The TranslationDataset class wraps text_pairs and adds [start] and [end] tokens to French sentences. The dataloader object provides batched, randomized samples after tokenization. The function collate_fn() handles tokenization and padding to ensure uniform sequence lengths within each batch.
For training, we use cross-entropy loss and Adam optimizer. The model employs teacher forcing technique, providing ground truth sequences to the decoder during training rather than reusing its own outputs. Note that in teacher forcing, the decoder should only see the first $N-1$ tokens when it generates the $N$-th token.
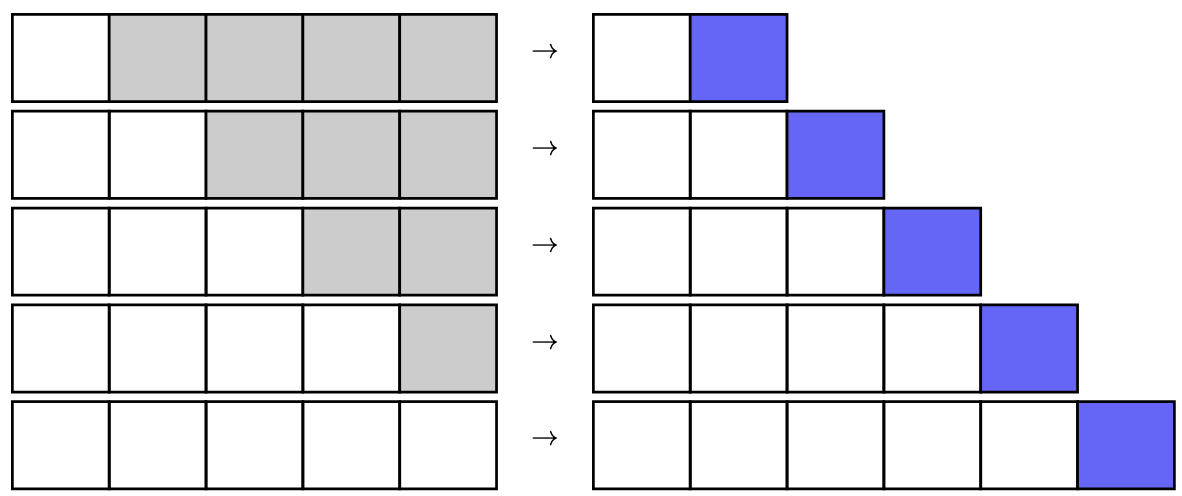
A transformer is an architecture that can be parallelized. When you provide a sequence of length $N$ to the decoder, it can process all elements of the sequence in parallel and output a sequence of length $N$. Usually, we consider only the last element of this output sequence as the output. Alternatively, to save computation, you can use the last element of the input sequence as the “query” in the attention, while using the full input sequence as both the “key” and “value”.
If you are careful, you will notice that for a sequence of length $N$, you can train the model $N$ times. If the model can be parallelized, you can generate $N$ outputs in parallel for the same input sequence $N$. However, there is a problem: when the model generates output $N$, you want it to use only the sequence up to position $N-1$, but not anything from position $N$ or later.
Causal prediction when you train a transformer: Iteratively you provide a longer sequence to the decoder (white squares). Each step, the decoder predict one additional output (blue squares). The gray squares are not provided to the model in the corresponding step.
To achieve this, use a causal mask. The causal mask is a square matrix of shape $(N, N)$ for a sequence of length $N$. The causal mask nowadays is implemented as a triangular matrix, with all elements above the diagonal set to $-\infty$ and the diagonal or below set to $0$, like the following:
The causal mask is used in the decoder through the attention class GQA and in turn, used by the scaled_dot_product_attention() function in PyTorch. It will “mask out” the attention score at the position that is not allowed to attend to, i.e., the “future” positions, such that the softmax operation will set those positions to zero. The matrix $M$ illustrated above represents the “query” vertically and the “key” horizontally. The position of 0 in the matrix means the query can only attend to the key at a position no later than itself. Hence the name “causal”.
Causal mask is applied to the decoder’s self-attention, where the query and key are the same sequence. Hence, $M$ is a square matrix. You can create such a matrix in PyTorch as follows:
Besides the causal mask, you also want to skip the padding tokens in the sequence. Padding tokens are added when the sequences in a batch are not the same length. Since they are not supposed to carry any information, they should be excluded from the attention or loss computation at the output. The padding mask is also a square matrix for each sequence. The Python code to create one from a tensor of a batch of sequences is as follows:
This code first creates a 2D tensor padded that matches the shape of the tensor batch. The tensor padded is zero everywhere except where the original tensor batch is equal to the padding token ID. Then a 3D tensor mask is created, with the shape of $(batch_size, seq_len, seq_len)$. The tensor mask is a batch of square matrices. In each square matrix, the rows and columns are set with padded in such a way that the positions corresponding to the padding tokens are set to $-\infty$.
The function above uses the technique of dimension expansion in PyTorch. Indexing a tensor with None will add a new dimension at that position. It also uses the broadcasting feature of PyTorch to fill in mask with the padded tensor.
The padding mask created is of shape (batch_size, 1, seq_len, seq_len). The causal mask, however, is of shape (seq_len, seq_len). They can be broadcasted and added together when you apply self-attention.
Training and Evaluation
Now you can implement the training loop as follows:
print(f"Epoch {epoch+1}/{N_EPOCHS}; Avg loss {epoch_loss/len(dataloader)}; Latest loss {loss.item()}")
The training loop is implemented as a nested for-loop. Each epoch scans the entire dataset once. Each batch extracted from the dataset is used to create the masks. Then, the data and the mask are passed on to the model to generate the output. Then the loss is computed by comparing the output to the ground truth. The loss is backpropagated to update the model parameters.
The mask to use with the encoder is the padding mask from the source (English) sequence. The mask to use with the decoder is the causal mask plus the padding mask from the target (French) sequence. The gradient computed in the backward pass is clipped to mitigate the problem of exploding gradients.
While the training loop enables the model to learn to generate the target sequence, it is also beneficial to run an evaluation after each epoch to assess the model’s performance and save the best model. The evaluation is implemented as follows:
This evaluation reuses the same dataset as training because you do not have a separate test set. The code is similar to the training loop, except that you do not need the backward pass and run the model under torch.no_grad() context.
The loss is averaged over the entire dataset. The lowest loss is tracked by the variable best_loss. A copy of the model will be saved whenever the loss is improved.
A well-trained model should achieve an average loss of 0.1 or lower. Once the training is complete, your model is ready for use. Below is one example:
This is more sophisticated than the training loop because you are not using the forward() method from the model, but using the encoder and decoder separately. You first use the encoder to get the context as enc_out. Then you started with fr_ids as the start token and iteratively generated the output from the decoder half of the transformer. Each step will extend fr_ids by one token. The generation will end when the end token is generated or when the maximum length is reached.
You can also use the forward() method from the model, but you will call the encoder with the same source sequence in each step. This is the unnecessary computation that was optimized in the above code. In reality, you may want to implement a method in the model class just for inference.
When you run the code above, you will see the following output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
English: are there any bananas?
French: y a-t-il des bananes ?
Predicted: y a-t-il des bananes ?
English: tom helped you, didn't he?
French: tom t'a aidée, n'est-ce pas ?
Predicted: tom vous a aidées, n'est-ce pas ?
English: i miss my parents.
French: mes parents me manquent.
Predicted: mes parents me manquent. j'ai manqué.
English: the game's almost over.
French: la manche est presque terminée.
Predicted: la manche est presque terminée.
English: turn left at the second traffic light.
French: tourne au second feu à gauche !
Predicted: tournez au deuxième feu à gauche !
For completeness, the complete code is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
# Transformer model implementation in PyTorch
import random
import os
import re
import unicodedata
import zipfile
import requests
import torch
import torch.nn asnn
import torch.nn.functional asF
import torch.optim asoptim
import tokenizers
import tqdm
#
# Data preparation
#
# Download dataset provided by Anki: https://www.manythings.org/anki/ with requests








No comments yet.