Word embeddings are a type of word representation that allows words with similar meaning to have a similar representation.
They are a distributed representation for text that is perhaps one of the key breakthroughs for the impressive performance of deep learning methods on challenging natural language processing problems.
In this post, you will discover the word embedding approach for representing text data.
After completing this post, you will know:
What the word embedding approach for representing text is and how it differs from other feature extraction methods.
That there are 3 main algorithms for learning a word embedding from text data.
That you can either train a new embedding or use a pre-trained embedding on your natural language processing task.
What Are Word Embeddings for Text? Photo by Heather, some rights reserved.
Overview
This post is divided into 3 parts; they are:
What Are Word Embeddings?
Word Embedding Algorithms
Using Word Embeddings
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
What Are Word Embeddings?
A word embedding is a learned representation for text where words that have the same meaning have a similar representation.
It is this approach to representing words and documents that may be considered one of the key breakthroughs of deep learning on challenging natural language processing problems.
One of the benefits of using dense and low-dimensional vectors is computational: the majority of neural network toolkits do not play well with very high-dimensional, sparse vectors. … The main benefit of the dense representations is generalization power: if we believe some features may provide similar clues, it is worthwhile to provide a representation that is able to capture these similarities.
Word embeddings are in fact a class of techniques where individual words are represented as real-valued vectors in a predefined vector space. Each word is mapped to one vector and the vector values are learned in a way that resembles a neural network, and hence the technique is often lumped into the field of deep learning.
Key to the approach is the idea of using a dense distributed representation for each word.
Each word is represented by a real-valued vector, often tens or hundreds of dimensions. This is contrasted to the thousands or millions of dimensions required for sparse word representations, such as a one-hot encoding.
associate with each word in the vocabulary a distributed word feature vector … The feature vector represents different aspects of the word: each word is associated with a point in a vector space. The number of features … is much smaller than the size of the vocabulary
The distributed representation is learned based on the usage of words. This allows words that are used in similar ways to result in having similar representations, naturally capturing their meaning. This can be contrasted with the crisp but fragile representation in a bag of words model where, unless explicitly managed, different words have different representations, regardless of how they are used.
There is deeper linguistic theory behind the approach, namely the “distributional hypothesis” by Zellig Harris that could be summarized as: words that have similar context will have similar meanings. For more depth see Harris’ 1956 paper “Distributional structure“.
This notion of letting the usage of the word define its meaning can be summarized by an oft repeated quip by John Firth:
Word embedding methods learn a real-valued vector representation for a predefined fixed sized vocabulary from a corpus of text.
The learning process is either joint with the neural network model on some task, such as document classification, or is an unsupervised process, using document statistics.
This section reviews three techniques that can be used to learn a word embedding from text data.
1. Embedding Layer
An embedding layer, for lack of a better name, is a word embedding that is learned jointly with a neural network model on a specific natural language processing task, such as language modeling or document classification.
It requires that document text be cleaned and prepared such that each word is one-hot encoded. The size of the vector space is specified as part of the model, such as 50, 100, or 300 dimensions. The vectors are initialized with small random numbers. The embedding layer is used on the front end of a neural network and is fit in a supervised way using the Backpropagation algorithm.
… when the input to a neural network contains symbolic categorical features (e.g. features that take one of k distinct symbols, such as words from a closed vocabulary), it is common to associate each possible feature value (i.e., each word in the vocabulary) with a d-dimensional vector for some d. These vectors are then considered parameters of the model, and are trained jointly with the other parameters.
The one-hot encoded words are mapped to the word vectors. If a multilayer Perceptron model is used, then the word vectors are concatenated before being fed as input to the model. If a recurrent neural network is used, then each word may be taken as one input in a sequence.
This approach of learning an embedding layer requires a lot of training data and can be slow, but will learn an embedding both targeted to the specific text data and the NLP task.
2. Word2Vec
Word2Vec is a statistical method for efficiently learning a standalone word embedding from a text corpus.
It was developed by Tomas Mikolov, et al. at Google in 2013 as a response to make the neural-network-based training of the embedding more efficient and since then has become the de facto standard for developing pre-trained word embedding.
Additionally, the work involved analysis of the learned vectors and the exploration of vector math on the representations of words. For example, that subtracting the “man-ness” from “King” and adding “women-ness” results in the word “Queen“, capturing the analogy “king is to queen as man is to woman“.
We find that these representations are surprisingly good at capturing syntactic and semantic regularities in language, and that each relationship is characterized by a relation-specific vector offset. This allows vector-oriented reasoning based on the offsets between words. For example, the male/female relationship is automatically learned, and with the induced vector representations, “King – Man + Woman” results in a vector very close to “Queen.”
Two different learning models were introduced that can be used as part of the word2vec approach to learn the word embedding; they are:
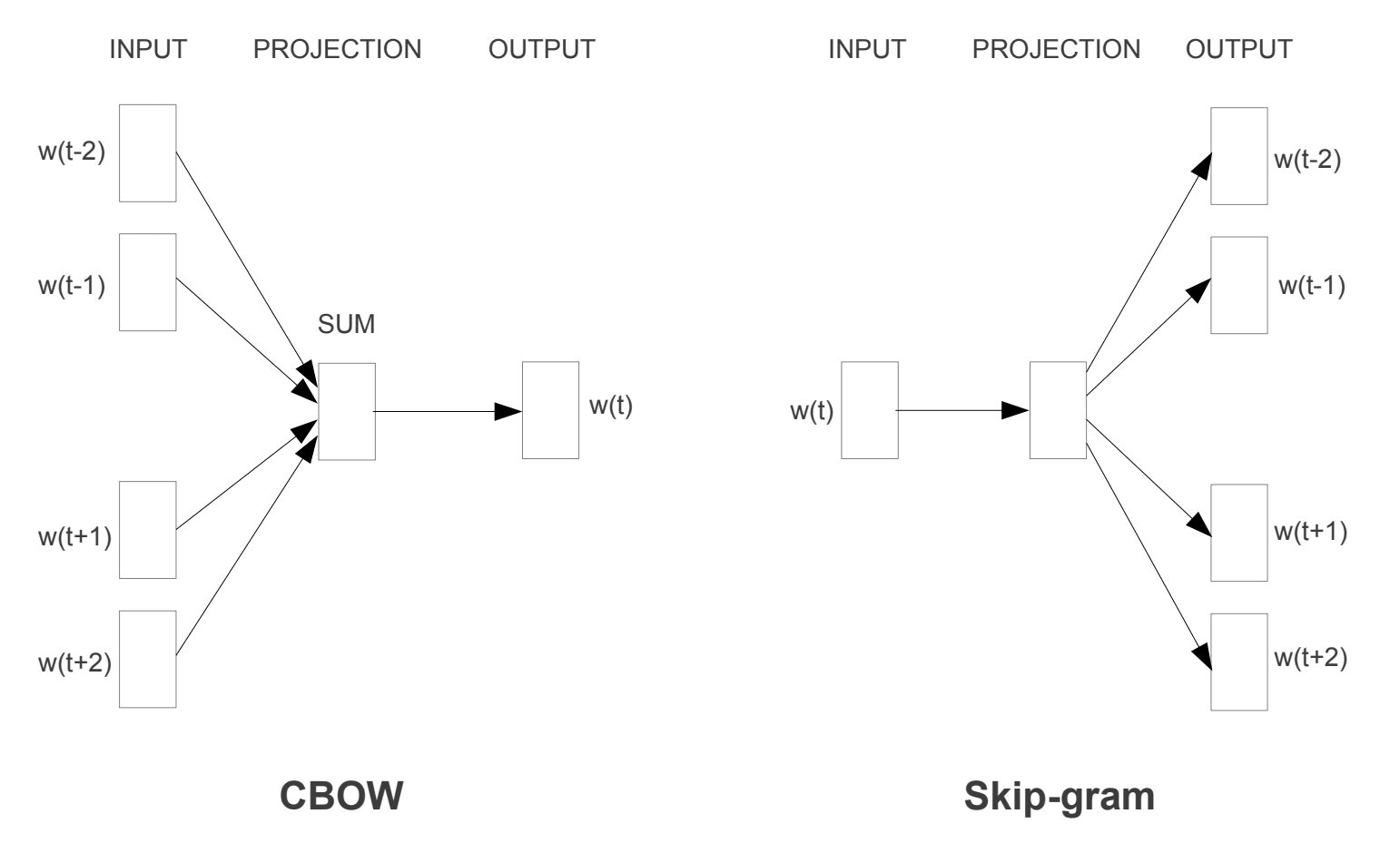
Continuous Bag-of-Words, or CBOW model.
Continuous Skip-Gram Model.
The CBOW model learns the embedding by predicting the current word based on its context. The continuous skip-gram model learns by predicting the surrounding words given a current word.
The continuous skip-gram model learns by predicting the surrounding words given a current word.
Word2Vec Training Models Taken from “Efficient Estimation of Word Representations in Vector Space”, 2013
Both models are focused on learning about words given their local usage context, where the context is defined by a window of neighboring words. This window is a configurable parameter of the model.
The size of the sliding window has a strong effect on the resulting vector similarities. Large windows tend to produce more topical similarities […], while smaller windows tend to produce more functional and syntactic similarities.
The key benefit of the approach is that high-quality word embeddings can be learned efficiently (low space and time complexity), allowing larger embeddings to be learned (more dimensions) from much larger corpora of text (billions of words).
3. GloVe
The Global Vectors for Word Representation, or GloVe, algorithm is an extension to the word2vec method for efficiently learning word vectors, developed by Pennington, et al. at Stanford.
Classical vector space model representations of words were developed using matrix factorization techniques such as Latent Semantic Analysis (LSA) that do a good job of using global text statistics but are not as good as the learned methods like word2vec at capturing meaning and demonstrating it on tasks like calculating analogies (e.g. the King and Queen example above).
GloVe is an approach to marry both the global statistics of matrix factorization techniques like LSA with the local context-based learning in word2vec.
Rather than using a window to define local context, GloVe constructs an explicit word-context or word co-occurrence matrix using statistics across the whole text corpus. The result is a learning model that may result in generally better word embeddings.
GloVe, is a new global log-bilinear regression model for the unsupervised learning of word representations that outperforms other models on word analogy, word similarity, and named entity recognition tasks.
You have some options when it comes time to using word embeddings on your natural language processing project.
This section outlines those options.
1. Learn an Embedding
You may choose to learn a word embedding for your problem.
This will require a large amount of text data to ensure that useful embeddings are learned, such as millions or billions of words.
You have two main options when training your word embedding:
Learn it Standalone, where a model is trained to learn the embedding, which is saved and used as a part of another model for your task later. This is a good approach if you would like to use the same embedding in multiple models.
Learn Jointly, where the embedding is learned as part of a large task-specific model. This is a good approach if you only intend to use the embedding on one task.
2. Reuse an Embedding
It is common for researchers to make pre-trained word embeddings available for free, often under a permissive license so that you can use them on your own academic or commercial projects.
For example, both word2vec and GloVe word embeddings are available for free download.
These can be used on your project instead of training your own embeddings from scratch.
You have two main options when it comes to using pre-trained embeddings:
Static, where the embedding is kept static and is used as a component of your model. This is a suitable approach if the embedding is a good fit for your problem and gives good results.
Updated, where the pre-trained embedding is used to seed the model, but the embedding is updated jointly during the training of the model. This may be a good option if you are looking to get the most out of the model and embedding on your task.
Which Option Should You Use?
Explore the different options, and if possible, test to see which gives the best results on your problem.
Perhaps start with fast methods, like using a pre-trained embedding, and only use a new embedding if it results in better performance on your problem.
Word Embedding Tutorials
This section lists some step-by-step tutorials that you can follow for using word embeddings and bring word embedding to your project.
Good article. I am working with pre-trained word embedding to develop a chatbot model. I came across a problem, and I believe you also have come across the same problem, i.e. how to encode numbers in text such as 1 or 2017, or even worse, something like 1.847440343 which is unlikely inside the dictionary of pre-trained word embedding?
Good article and good link to the book for NN methods in NLP. I am planning to buy it.
But I have question how the word embeddings algorithms can be applied to detecting new emerging trend (or just trend analysis) in the text stream? Is it possible to use? Are there some papers or links?
Simply, you are the best. You have a talent explaining very complex concepts and make it simpler. Thanks a million for all your writings. I planning om buying some of your books, but I need to figure out what I need first. Thanks again!
Thanks for precise explanation of Word Embedding in NLP, till now I was concentrating DL use on dense data like image and audio, now I learnt some basics of how to convert the sparse text data to dense low dimensional vector, so thanks for making me to enter in to the world of NLP.
It was a very useful article for me. You have explained almost every key point in a simple and easy to understand manner. Many of my doubts were cleared.
A. Salaam to every one
Sir Jason i read your article this is really gain information from this article can you explain sentence level sentiment analysis?
Thank you for your explanation.
I have a question. what does dimension exactly mean?
First, I thought each letter of word means one dimension, but thinking of a hundred dimension…?!
Can you help me with that?
In this current article. Like here: “Each word is represented by a real-valued vector, often tens or hundreds of dimensions. This is contrasted to the thousands or millions of dimensions required for sparse word representations, such as a one-hot encoding.”
I don’t get what do you mean by dimensions
Thanks for your article and I learn a lot from it.
I have one question about the words you quoted in the embedding layer section.why the weights of the embedding layer can be regarded as the word vector of the one-hot encoded words.In my eyes, weights are just the parameters of the model and they don’t carry out any information from the raw input.
Can you please elaborate a bit what you exactly mean with “document statistics” in the sentence below (what is it exactly about):
The learning process is either joint with the neural network model on some task, such as document classification, or is an unsupervised process, using document statistics.
And in general both Word2Vec and GloVe are unsupervised learning, correct? In contract an example usage of Word Embedding in supervised learning would be Spam-Mail Detection, right?
Is it possible to concatenate (merge) two pre-trained word embeddings, trained with different text corpus and with different number of dimensions? Does it make sense?
Hi~ I have a question. Now what I like to do is to estimate the similarity between two embedded vectors. If those two vectors are embedded from the same dataset, dot production can be used to the calculate the similarity. However, If those two vectors are embedded from the different dataset, dot production can be used to the calculate the similarity?
Thanks dear Jason for your awesome posts.
I need to explain the word embedding layer of Keras in my paper, mathematically. I know that keras initialize the embedding vectors randomly and then update the parameters using the optimizer specified by programmer. Is there a paper that explains the method in details to reference it?
Hello, I have a question. Let say, I would like to use word embeddings (100 dimensions) with logistic regression. My features are twitters. I want to encode them into into an array with 100 columns. Twits are not only words, but sentences containing variable number of words. How can I bring each sentence to the same number of columns:
-> average of vectors for every word in the sentence,
-> sum of vectors for every word in the sentence?
Probably there are some some smarter way how to aggregate them so that they don’t lose their semantics?
Thank you in advance for your response.
Ouch, logistic regression might not be great for this.
Nevertheless. One sample or tweet is multiple words. Each word is converted to a vector and the vectors are concatenated to provide one long input to the model.
A better approach would be to use a model that support sequences, like an RNN or 1D CNN.
Hello Jason, thank you for reply. Actually here I am not interested in the logistic regression 🙂 rather I would like to understand how to encode text of different length so that it has the same vector length and can be fed to any ML algorithm.
As for concatenation of the vectors mentioned by you, here I see the problem.
Let say I have 5 words in the first sentence (tweet), then after concatenation I will have the vector of length 500.
Let assume another sentence (tweet) has 10 words so after the encoding and concatenation I will have the vector of length 1000.
So I cannot use these vectors together because they have different length (different number of columns in the table) so that they cannot be consumed by algorithm.
Probably I misunderstood the concept of word embeddings and try to approach it as bag-of-words model 🙂 could you suggest me some reading related to my problem because I feel that even after reading several articles on your blog and I still haven’t found the answer to my question.
Thank you!
Ros
The embedding network for classification,Is it related only to texts and words processing or it can be appied to other contexts ? if this is the case, what articles and papers you recommend me to read to know more about those applications.
I’m not in this field and have rusty math skills. Can you explain what sort of information is represented by each dimension of a typical vector space? My gut feeling is that the aim to reduce the number of dimensions, to gain computational benefits, catastrophically limits the meaning that can be recorded. Obviously, I’m wrong! This hopefully illustrates my confusion about how vectors in the vector space store information.
Hi Jason,
I am so glad I found your website!! Your way of explaining word embedding is easy and makes the ideas simple.
I have a question regarding NER using deep learning. Currently I am developing a NER system that uses word embedding to represent the corpus and then use deep learning extract Named Entities. I wonder if you have resources or tutorials in your website to clarify the idea to me using Python or at least guide me where I can find useful resources regarding my topic
Thanks a lot in advance.
Deena
I would like to clarify that there is a usecase such as generate missing code between code snippet, where researchers have used embedings on code model.
But, I would like to solve a problem related to next token prediction on the basis of previous user inputs.
For this problem, I need your advice, will there be any benefit to apply embedings and Bi-directional LSTM ?
Thank you! It was very useful to read your article.
is it possible to train more than one word embedding model for different corpora in order to compare the various embeddings between the corpora? bear in mind that they are from the same domain, the only difference is the author characteristics.
If yes, do you have an initial thoughts about how this can be done?
I’m trying to generate word embeddings for words specific to a subject but don’t have a large enough corpus to train.
Referring to the section – 2. “Reuse an Embedding”, I think that point 2 “Updated” (where the pre-trained embedding is used to seed the model…) might be the right option for me.
Can you share some pointers on how I can Update pre-existing models with specific words with a limited corpus?
I have a doubt, can we use word embeddings obtained using word2vec and pass it to machine learning model as a set of features ?
Actually, I am working on a Multi class classification problem. Earlier I used CountVectorizer and TfidfTransformer as feature extraction methods. Can I use word@vec instead of them and pass it on to SVM model ?
Hi dear Jason,
Firstly, I would to thank you about this amazing article,
Secondly, I have question,
If I want to do supervised multi-classes classification of specific domain such as history, using one of deep learning techniques. which is the best word embddings technique should I use?
1- Word2vec based on Continuous Bag-of-Words,
2- Word2 vector based on Continuous Skip-Gram Model,
3- Glove.
Many thanks…
Jason, you are “the Dude”!! Thank you so much, good man! Whenever I have a question on whatever subject in Machine Learning, or when I don’t understand something, or when something isn’t clear, I always come here and find a good and comprehensible answer.
Many thanks again.
Thanks for your article and I learn a lot from it.
I would like to classify the reports regarding RISK into higher or lower risk using NLP.
I was was wondering if you could advise me of any word embedding dictionary or library(which is pretrained based on a very huge corpus text, like a lookup table and and need to pay for it). By using this, those words that have the similar meaning have a similar representation (the most Negative meaning to the most Positive meaning regarding RISK).
I’m just starting out with word embeddings, playing around with pre-existing embeddings such as FastText. How do you handle words that do not have any vectors assigned and returned as null values? I fear the false impact of assigning 0 to replace the null values, or any other imputation method.







")

Thanks for simplified and better explanation
I’m glad it helped.
Good article. I am working with pre-trained word embedding to develop a chatbot model. I came across a problem, and I believe you also have come across the same problem, i.e. how to encode numbers in text such as 1 or 2017, or even worse, something like 1.847440343 which is unlikely inside the dictionary of pre-trained word embedding?
any suggestions?
In many cases I have seen numbers removed from text data.
That might be a good first step in order to get something working.
Good article and good link to the book for NN methods in NLP. I am planning to buy it.
But I have question how the word embeddings algorithms can be applied to detecting new emerging trend (or just trend analysis) in the text stream? Is it possible to use? Are there some papers or links?
I have not seen this use case sorry. Perhaps search google scholar.
Precise Intro to word embeddings! thanks a ton
I’m glad it helped!
Simply, you are the best. You have a talent explaining very complex concepts and make it simpler. Thanks a million for all your writings. I planning om buying some of your books, but I need to figure out what I need first. Thanks again!
Thank you so much mohamed! Hang in there.
Thanks for precise explanation of Word Embedding in NLP, till now I was concentrating DL use on dense data like image and audio, now I learnt some basics of how to convert the sparse text data to dense low dimensional vector, so thanks for making me to enter in to the world of NLP.
I’m glad it helped.
On handling numbers one option might be to convert them to text 1 = one etc.
Great suggestion Peter.
Is there any method for sentence embedding using Glove orWord2vec
Perhaps, I have not used them sorry. Try a google search.
It was a very useful article for me. You have explained almost every key point in a simple and easy to understand manner. Many of my doubts were cleared.
Thanks a lot, keep up the good word.
Thanks, I’m glad it helped.
A. Salaam to every one
Sir Jason i read your article this is really gain information from this article can you explain sentence level sentiment analysis?
This post will help you get started:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
Thank you for your explanation.
I have a question. what does dimension exactly mean?
First, I thought each letter of word means one dimension, but thinking of a hundred dimension…?!
Can you help me with that?
In what context exactly? I don’t follow sorry.
In this current article. Like here: “Each word is represented by a real-valued vector, often tens or hundreds of dimensions. This is contrasted to the thousands or millions of dimensions required for sparse word representations, such as a one-hot encoding.”
I don’t get what do you mean by dimensions
Each element in a vector is a new dimension.
thank you
Are the elements just features like masculinity, age, etc…? and what determines which feature to choose?
Thanks for your article and I learn a lot from it.
I have one question about the words you quoted in the embedding layer section.why the weights of the embedding layer can be regarded as the word vector of the one-hot encoded words.In my eyes, weights are just the parameters of the model and they don’t carry out any information from the raw input.
They are a consistent representation. Each word maps to one vector in a continuous space where the relationship between words (meaning) is expressed.
Thanks for writing a good, simple and clear article.
One quick question: Can word embeddings be used for information extraction from text documents? If so, any good reference that you suggest.
Thanks.
In what way exactly?
In its simplest form I mean: summarizing responses to a particular question.
Yes, I believe you’re asking about is called “text summarization”. You can learn more here:
https://machinelearningmastery.com/?s=text+summarization&post_type=post&submit=Search
Hi
Can you please elaborate a bit what you exactly mean with “document statistics” in the sentence below (what is it exactly about):
The learning process is either joint with the neural network model on some task, such as document classification, or is an unsupervised process, using document statistics.
And in general both Word2Vec and GloVe are unsupervised learning, correct? In contract an example usage of Word Embedding in supervised learning would be Spam-Mail Detection, right?
Thanks
Document stats just means statistics on how words are used – ordering.
Yes and no. Word embeddings are “unsupervised” but are really trained using a contrived supervised learning problem.
Great article! Thanks!
Is it possible to concatenate (merge) two pre-trained word embeddings, trained with different text corpus and with different number of dimensions? Does it make sense?
Yes, if there are different words in the embeddings. Not for the same words.
Hi~ I have a question. Now what I like to do is to estimate the similarity between two embedded vectors. If those two vectors are embedded from the same dataset, dot production can be used to the calculate the similarity. However, If those two vectors are embedded from the different dataset, dot production can be used to the calculate the similarity?
You can use the vector norm (e.g. L1 or L2) to calculate distance between any two vectors, regardless of their source.
Many thanks to you, Dr. Brownlee. Your explanation is very clear and helpful
Thanks, I’m glad it helped.
Thanks dear Jason for your awesome posts.
I need to explain the word embedding layer of Keras in my paper, mathematically. I know that keras initialize the embedding vectors randomly and then update the parameters using the optimizer specified by programmer. Is there a paper that explains the method in details to reference it?
Yes, it is linked in the API documentation here:
https://keras.io/layers/embeddings/
Thank you for lucid and clear explanation of Word embedding for newbies in NLP like me. Thanks for the links also
Thanks, I’m glad it helped.
Hello, I have a question. Let say, I would like to use word embeddings (100 dimensions) with logistic regression. My features are twitters. I want to encode them into into an array with 100 columns. Twits are not only words, but sentences containing variable number of words. How can I bring each sentence to the same number of columns:
-> average of vectors for every word in the sentence,
-> sum of vectors for every word in the sentence?
Probably there are some some smarter way how to aggregate them so that they don’t lose their semantics?
Thank you in advance for your response.
Ouch, logistic regression might not be great for this.
Nevertheless. One sample or tweet is multiple words. Each word is converted to a vector and the vectors are concatenated to provide one long input to the model.
A better approach would be to use a model that support sequences, like an RNN or 1D CNN.
Hello Jason, thank you for reply. Actually here I am not interested in the logistic regression 🙂 rather I would like to understand how to encode text of different length so that it has the same vector length and can be fed to any ML algorithm.
As for concatenation of the vectors mentioned by you, here I see the problem.
Let say I have 5 words in the first sentence (tweet), then after concatenation I will have the vector of length 500.
Let assume another sentence (tweet) has 10 words so after the encoding and concatenation I will have the vector of length 1000.
So I cannot use these vectors together because they have different length (different number of columns in the table) so that they cannot be consumed by algorithm.
Probably I misunderstood the concept of word embeddings and try to approach it as bag-of-words model 🙂 could you suggest me some reading related to my problem because I feel that even after reading several articles on your blog and I still haven’t found the answer to my question.
Thank you!
Ros
Yes, typically we would choose a fixed length then trim or pad all examples to be the same length, then encode:
https://machinelearningmastery.com/data-preparation-variable-length-input-sequences-sequence-prediction/
I would recommend using a word embedding which involves encoding words as numbers then providing them as input to the embedding followed by a CNN:
https://machinelearningmastery.com/best-practices-document-classification-deep-learning/
Thank you kindly!
Hi Jason,
The embedding network for classification,Is it related only to texts and words processing or it can be appied to other contexts ? if this is the case, what articles and papers you recommend me to read to know more about those applications.
Thank you in advance.
Embeddings can be used to model any categorical data, not just text.
I hope to have some tutorials on this soon.
I hope so.
I’m not in this field and have rusty math skills. Can you explain what sort of information is represented by each dimension of a typical vector space? My gut feeling is that the aim to reduce the number of dimensions, to gain computational benefits, catastrophically limits the meaning that can be recorded. Obviously, I’m wrong! This hopefully illustrates my confusion about how vectors in the vector space store information.
Thank you!
It is an increase in dimensionality over the words, and a decrease in dimensionality compared to a one hot encoding.
The representation groups “like” words in the vector space.
How are word embeddings different from PCA using one-hot encoded words as individual features?
They are very different.
PCA remove linear dependence.
Embedding is a distributed representation.
great job!!!
Thanks.
Hi Jason,
I am so glad I found your website!! Your way of explaining word embedding is easy and makes the ideas simple.
I have a question regarding NER using deep learning. Currently I am developing a NER system that uses word embedding to represent the corpus and then use deep learning extract Named Entities. I wonder if you have resources or tutorials in your website to clarify the idea to me using Python or at least guide me where I can find useful resources regarding my topic
Thanks a lot in advance.
Deena
Thanks Deena!
Sorry, I don’t have tutorials on NER, I cannot give you good advice off the cuff.
No worries. Many Thanks again 🙂
Hi! from the above I understand that embedding is a numerical representation of words and the dimension of all the vectors are same.
my question is do all the words have same dimension name(column name) or it differs from one word to other?
All words have the same number of dimensions (vector with the same number of elements, e.g. 100).
Dear Jason,
Thanks for nice post.
I would like to ask can we use embedding for program language modeling for code generation or prediction?
Is there any benefit of using Embedding Layer or word2vec in that case?
Yes.
Yes, the learned embedding would likely be a better reprensetation of the symbols in the input than other methods.
Thanks Jason for your response,
I would like to clarify that there is a usecase such as generate missing code between code snippet, where researchers have used embedings on code model.
But, I would like to solve a problem related to next token prediction on the basis of previous user inputs.
For this problem, I need your advice, will there be any benefit to apply embedings and Bi-directional LSTM ?
Perhaps try it and compare results to other methods?
Hi Jason
Thank you! It was very useful to read your article.
is it possible to train more than one word embedding model for different corpora in order to compare the various embeddings between the corpora? bear in mind that they are from the same domain, the only difference is the author characteristics.
If yes, do you have an initial thoughts about how this can be done?
I’m happy it was useful.
Yes, perhaps try it and use it as the input to a multi-input model.
Thank you very much, it was useful for me to learn about this concept of word embedding.
Thank you again.
You’re welcome, I’m happy to hear that.
Great article, Jason!
I’m trying to generate word embeddings for words specific to a subject but don’t have a large enough corpus to train.
Referring to the section – 2. “Reuse an Embedding”, I think that point 2 “Updated” (where the pre-trained embedding is used to seed the model…) might be the right option for me.
Can you share some pointers on how I can Update pre-existing models with specific words with a limited corpus?
Google pre-trained:
https://code.google.com/archive/p/word2vec/
Glove pre-trained:
https://nlp.stanford.edu/projects/glove/
Hi Jason, thanks for this post!
to best of your knowledge, expect one-hot encoding, tokenizer API, and Word2Vec is there any other algorithms for word embedding?
Yes, you can use a standalone method like word2vec or glove, or learn an embedding as part of a model directly.
Hello,
thanks for the great tuto!
is BERT and xLNET are also a pre-trained word embeddings, that we can use in our model?
BERT is a pre-trained language model.
Thanks for a great ,comprehensive, yet simplified explanation of the embedding concept and approaches thereof.
You’re welcome!
Hi,
Great article!!.
I have a doubt, can we use word embeddings obtained using word2vec and pass it to machine learning model as a set of features ?
Actually, I am working on a Multi class classification problem. Earlier I used CountVectorizer and TfidfTransformer as feature extraction methods. Can I use word@vec instead of them and pass it on to SVM model ?
Thanks!
Sure.
Hi dear Jason,
Firstly, I would to thank you about this amazing article,
Secondly, I have question,
If I want to do supervised multi-classes classification of specific domain such as history, using one of deep learning techniques. which is the best word embddings technique should I use?
1- Word2vec based on Continuous Bag-of-Words,
2- Word2 vector based on Continuous Skip-Gram Model,
3- Glove.
Many thanks…
You’re welcome.
We cannot know a priori.
Perhaps try each with your dataset and use the method that results in best model performance.
Jason, you are “the Dude”!! Thank you so much, good man! Whenever I have a question on whatever subject in Machine Learning, or when I don’t understand something, or when something isn’t clear, I always come here and find a good and comprehensible answer.
Many thanks again.
Thanks!
Hi Jason,
Thanks for your article and I learn a lot from it.
I would like to classify the reports regarding RISK into higher or lower risk using NLP.
I was was wondering if you could advise me of any word embedding dictionary or library(which is pretrained based on a very huge corpus text, like a lookup table and and need to pay for it). By using this, those words that have the similar meaning have a similar representation (the most Negative meaning to the most Positive meaning regarding RISK).
Thank you, Jack
You’re welcome.
Perhaps try learning an embedding as part of the model directly – it would likely be more effective (in my experience).
I’m just starting out with word embeddings, playing around with pre-existing embeddings such as FastText. How do you handle words that do not have any vectors assigned and returned as null values? I fear the false impact of assigning 0 to replace the null values, or any other imputation method.
New words not in the vocab are encoded as a vector of all zero values, e.g. “unknown”.
This in incredible. After perusing your explanation I’m now in the unique position of understanding less about word embeddings than I did before.
Thank you for the support and feedback Gabriel! We greatly appreciate it!