
Automated Machine Learning (AutoML) refers to techniques for automatically discovering well-performing models for predictive modeling tasks with very little user involvement.
TPOT is an open-source library for performing AutoML in Python. It makes use of the popular Scikit-Learn machine learning library for data transforms and machine learning algorithms and uses a Genetic Programming stochastic global search procedure to efficiently discover a top-performing model pipeline for a given dataset.
In this tutorial, you will discover how to use TPOT for AutoML with Scikit-Learn machine learning algorithms in Python.
After completing this tutorial, you will know:
- TPOT is an open-source library for AutoML with scikit-learn data preparation and machine learning models.
- How to use TPOT to automatically discover top-performing models for classification tasks.
- How to use TPOT to automatically discover top-performing models for regression tasks.
Let’s get started.

TPOT for Automated Machine Learning in Python
Photo by Gwen, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
- TPOT for Automated Machine Learning
- Install and Use TPOT
- TPOT for Classification
- TPOT for Regression
TPOT for Automated Machine Learning
Tree-based Pipeline Optimization Tool, or TPOT for short, is a Python library for automated machine learning.
TPOT uses a tree-based structure to represent a model pipeline for a predictive modeling problem, including data preparation and modeling algorithms and model hyperparameters.
… an evolutionary algorithm called the Tree-based Pipeline Optimization Tool (TPOT) that automatically designs and optimizes machine learning pipelines.
— Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science, 2016.
An optimization procedure is then performed to find a tree structure that performs best for a given dataset. Specifically, a genetic programming algorithm, designed to perform a stochastic global optimization on programs represented as trees.
TPOT uses a version of genetic programming to automatically design and optimize a series of data transformations and machine learning models that attempt to maximize the classification accuracy for a given supervised learning data set.
— Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science, 2016.
The figure below taken from the TPOT paper shows the elements involved in the pipeline search, including data cleaning, feature selection, feature processing, feature construction, model selection, and hyperparameter optimization.
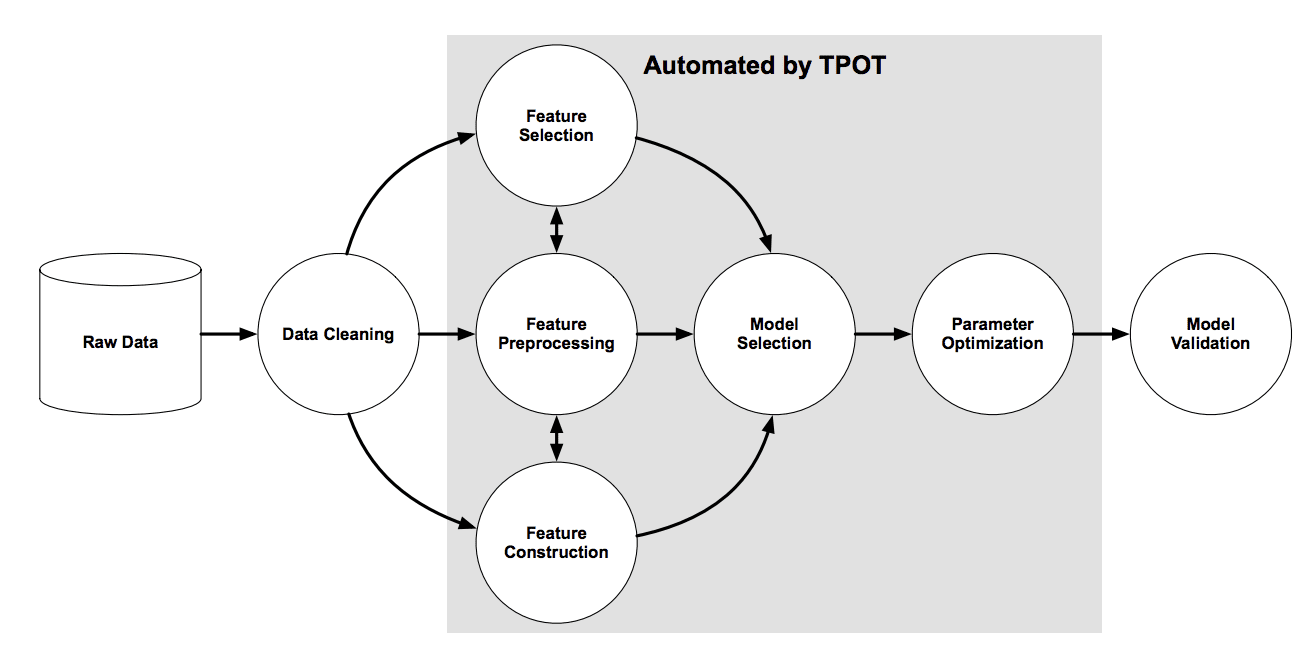
Overview of the TPOT Pipeline Search
Taken from: Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science, 2016.
Now that we are familiar with what TPOT is, let’s look at how we can install and use TPOT to find an effective model pipeline.
Install and Use TPOT
The first step is to install the TPOT library, which can be achieved using pip, as follows:
|
1 |
pip install tpot |
Once installed, we can import the library and print the version number to confirm it was installed successfully:
|
1 2 3 |
# check tpot version import tpot print('tpot: %s' % tpot.__version__) |
Running the example prints the version number.
Your version number should be the same or higher.
|
1 |
tpot: 0.11.1 |
Using TPOT is straightforward.
It involves creating an instance of the TPOTRegressor or TPOTClassifier class, configuring it for the search, and then exporting the model pipeline that was found to achieve the best performance on your dataset.
Configuring the class involves two main elements.
The first is how models will be evaluated, e.g. the cross-validation scheme and performance metric. I recommend explicitly specifying a cross-validation class with your chosen configuration and the performance metric to use.
For example, RepeatedKFold for regression with ‘neg_mean_absolute_error‘ metric for regression:
|
1 2 3 4 5 |
... # define evaluation procedure cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) # define search model = TPOTRegressor(... scoring='neg_mean_absolute_error', cv=cv) |
Or a RepeatedStratifiedKFold for regression with ‘accuracy‘ metric for classification:
|
1 2 3 4 5 |
... # define evaluation procedure cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # define search model = TPOTClassifier(... scoring='accuracy', cv=cv) |
The other element is the nature of the stochastic global search procedure.
As an evolutionary algorithm, this involves setting configuration, such as the size of the population, the number of generations to run, and potentially crossover and mutation rates. The former importantly control the extent of the search; the latter can be left on default values if evolutionary search is new to you.
For example, a modest population size of 100 and 5 or 10 generations is a good starting point.
|
1 2 3 |
... # define search model = TPOTClassifier(generations=5, population_size=50, ...) |
At the end of a search, a Pipeline is found that performs the best.
This Pipeline can be exported as code into a Python file that you can later copy-and-paste into your own project.
|
1 2 3 |
... # export the best model model.export('tpot_model.py') |
Now that we are familiar with how to use TPOT, let’s look at some worked examples with real data.
TPOT for Classification
In this section, we will use TPOT to discover a model for the sonar dataset.
The sonar dataset is a standard machine learning dataset comprised of 208 rows of data with 60 numerical input variables and a target variable with two class values, e.g. binary classification.
Using a test harness of repeated stratified 10-fold cross-validation with three repeats, a naive model can achieve an accuracy of about 53 percent. A top-performing model can achieve accuracy on this same test harness of about 88 percent. This provides the bounds of expected performance on this dataset.
The dataset involves predicting whether sonar returns indicate a rock or simulated mine.
No need to download the dataset; we will download it automatically as part of our worked examples.
The example below downloads the dataset and summarizes its shape.
|
1 2 3 4 5 6 7 8 9 |
# summarize the sonar dataset from pandas import read_csv # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv' dataframe = read_csv(url, header=None) # split into input and output elements data = dataframe.values X, y = data[:, :-1], data[:, -1] print(X.shape, y.shape) |
Running the example downloads the dataset and splits it into input and output elements. As expected, we can see that there are 208 rows of data with 60 input variables.
|
1 |
(208, 60) (208,) |
Next, let’s use TPOT to find a good model for the sonar dataset.
First, we can define the method for evaluating models. We will use a good practice of repeated stratified k-fold cross-validation with three repeats and 10 folds.
|
1 2 3 |
... # define model evaluation cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) |
We will use a population size of 50 for five generations for the search and use all cores on the system by setting “n_jobs” to -1.
|
1 2 3 |
... # define search model = TPOTClassifier(generations=5, population_size=50, cv=cv, scoring='accuracy', verbosity=2, random_state=1, n_jobs=-1) |
Finally, we can start the search and ensure that the best-performing model is saved at the end of the run.
|
1 2 3 4 5 |
... # perform the search model.fit(X, y) # export the best model model.export('tpot_sonar_best_model.py') |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# example of tpot for the sonar classification dataset from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import RepeatedStratifiedKFold from tpot import TPOTClassifier # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv' dataframe = read_csv(url, header=None) # split into input and output elements data = dataframe.values X, y = data[:, :-1], data[:, -1] # minimally prepare dataset X = X.astype('float32') y = LabelEncoder().fit_transform(y.astype('str')) # define model evaluation cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # define search model = TPOTClassifier(generations=5, population_size=50, cv=cv, scoring='accuracy', verbosity=2, random_state=1, n_jobs=-1) # perform the search model.fit(X, y) # export the best model model.export('tpot_sonar_best_model.py') |
Running the example may take a few minutes, and you will see a progress bar on the command line.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The accuracy of top-performing models will be reported along the way.
|
1 2 3 4 5 6 7 |
Generation 1 - Current best internal CV score: 0.8650793650793651 Generation 2 - Current best internal CV score: 0.8650793650793651 Generation 3 - Current best internal CV score: 0.8650793650793651 Generation 4 - Current best internal CV score: 0.8650793650793651 Generation 5 - Current best internal CV score: 0.8667460317460318 Best pipeline: GradientBoostingClassifier(GaussianNB(input_matrix), learning_rate=0.1, max_depth=7, max_features=0.7000000000000001, min_samples_leaf=15, min_samples_split=10, n_estimators=100, subsample=0.9000000000000001) |
In this case, we can see that the top-performing pipeline achieved the mean accuracy of about 86.6 percent. This is a skillful model, and close to a top-performing model on this dataset.
The top-performing pipeline is then saved to a file named “tpot_sonar_best_model.py“.
Opening this file, you can see that there is some generic code for loading a dataset and fitting the pipeline. An example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import numpy as np import pandas as pd from sklearn.ensemble import GradientBoostingClassifier from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.pipeline import make_pipeline, make_union from tpot.builtins import StackingEstimator from tpot.export_utils import set_param_recursive # NOTE: Make sure that the outcome column is labeled 'target' in the data file tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64) features = tpot_data.drop('target', axis=1) training_features, testing_features, training_target, testing_target = \ train_test_split(features, tpot_data['target'], random_state=1) # Average CV score on the training set was: 0.8667460317460318 exported_pipeline = make_pipeline( StackingEstimator(estimator=GaussianNB()), GradientBoostingClassifier(learning_rate=0.1, max_depth=7, max_features=0.7000000000000001, min_samples_leaf=15, min_samples_split=10, n_estimators=100, subsample=0.9000000000000001) ) # Fix random state for all the steps in exported pipeline set_param_recursive(exported_pipeline.steps, 'random_state', 1) exported_pipeline.fit(training_features, training_target) results = exported_pipeline.predict(testing_features) |
Note: as-is, this code does not execute, by design. It is a template that you can copy-and-paste into your project.
In this case, we can see that the best-performing model is a pipeline comprised of a Naive Bayes model and a Gradient Boosting model.
We can adapt this code to fit a final model on all available data and make a prediction for new data.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# example of fitting a final model and making a prediction on the sonar dataset from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import GradientBoostingClassifier from sklearn.naive_bayes import GaussianNB from sklearn.pipeline import make_pipeline from tpot.builtins import StackingEstimator from tpot.export_utils import set_param_recursive # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv' dataframe = read_csv(url, header=None) # split into input and output elements data = dataframe.values X, y = data[:, :-1], data[:, -1] # minimally prepare dataset X = X.astype('float32') y = LabelEncoder().fit_transform(y.astype('str')) # Average CV score on the training set was: 0.8667460317460318 exported_pipeline = make_pipeline( StackingEstimator(estimator=GaussianNB()), GradientBoostingClassifier(learning_rate=0.1, max_depth=7, max_features=0.7000000000000001, min_samples_leaf=15, min_samples_split=10, n_estimators=100, subsample=0.9000000000000001) ) # Fix random state for all the steps in exported pipeline set_param_recursive(exported_pipeline.steps, 'random_state', 1) # fit the model exported_pipeline.fit(X, y) # make a prediction on a new row of data row = [0.0200,0.0371,0.0428,0.0207,0.0954,0.0986,0.1539,0.1601,0.3109,0.2111,0.1609,0.1582,0.2238,0.0645,0.0660,0.2273,0.3100,0.2999,0.5078,0.4797,0.5783,0.5071,0.4328,0.5550,0.6711,0.6415,0.7104,0.8080,0.6791,0.3857,0.1307,0.2604,0.5121,0.7547,0.8537,0.8507,0.6692,0.6097,0.4943,0.2744,0.0510,0.2834,0.2825,0.4256,0.2641,0.1386,0.1051,0.1343,0.0383,0.0324,0.0232,0.0027,0.0065,0.0159,0.0072,0.0167,0.0180,0.0084,0.0090,0.0032] yhat = exported_pipeline.predict([row]) print('Predicted: %.3f' % yhat[0]) |
Running the example fits the best-performing model on the dataset and makes a prediction for a single row of new data.
|
1 |
Predicted: 1.000 |
TPOT for Regression
In this section, we will use TPOT to discover a model for the auto insurance dataset.
The auto insurance dataset is a standard machine learning dataset comprised of 63 rows of data with one numerical input variable and a numerical target variable.
Using a test harness of repeated stratified 10-fold cross-validation with three repeats, a naive model can achieve a mean absolute error (MAE) of about 66. A top-performing model can achieve a MAE on this same test harness of about 28. This provides the bounds of expected performance on this dataset.
The dataset involves predicting the total amount in claims (thousands of Swedish Kronor) given the number of claims for different geographical regions.
- Auto Insurance Dataset (auto-insurance.csv)
- Auto Insurance Dataset Description (auto-insurance.names)
No need to download the dataset; we will download it automatically as part of our worked examples.
The example below downloads the dataset and summarizes its shape.
|
1 2 3 4 5 6 7 8 9 |
# summarize the auto insurance dataset from pandas import read_csv # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/auto-insurance.csv' dataframe = read_csv(url, header=None) # split into input and output elements data = dataframe.values X, y = data[:, :-1], data[:, -1] print(X.shape, y.shape) |
Running the example downloads the dataset and splits it into input and output elements. As expected, we can see that there are 63 rows of data with one input variable.
|
1 |
(63, 1) (63,) |
Next, we can use TPOT to find a good model for the auto insurance dataset.
First, we can define the method for evaluating models. We will use a good practice of repeated k-fold cross-validation with three repeats and 10 folds.
|
1 2 3 |
... # define evaluation procedure cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) |
We will use a population size of 50 for 5 generations for the search and use all cores on the system by setting “n_jobs” to -1.
|
1 2 3 |
... # define search model = TPOTRegressor(generations=5, population_size=50, scoring='neg_mean_absolute_error', cv=cv, verbosity=2, random_state=1, n_jobs=-1) |
Finally, we can start the search and ensure that the best-performing model is saved at the end of the run.
|
1 2 3 4 5 |
... # perform the search model.fit(X, y) # export the best model model.export('tpot_insurance_best_model.py') |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# example of tpot for the insurance regression dataset from pandas import read_csv from sklearn.model_selection import RepeatedKFold from tpot import TPOTRegressor # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/auto-insurance.csv' dataframe = read_csv(url, header=None) # split into input and output elements data = dataframe.values data = data.astype('float32') X, y = data[:, :-1], data[:, -1] # define evaluation procedure cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) # define search model = TPOTRegressor(generations=5, population_size=50, scoring='neg_mean_absolute_error', cv=cv, verbosity=2, random_state=1, n_jobs=-1) # perform the search model.fit(X, y) # export the best model model.export('tpot_insurance_best_model.py') |
Running the example may take a few minutes, and you will see a progress bar on the command line.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The MAE of top-performing models will be reported along the way.
|
1 2 3 4 5 6 7 |
Generation 1 - Current best internal CV score: -29.147625969129034 Generation 2 - Current best internal CV score: -29.147625969129034 Generation 3 - Current best internal CV score: -29.147625969129034 Generation 4 - Current best internal CV score: -29.147625969129034 Generation 5 - Current best internal CV score: -29.147625969129034 Best pipeline: LinearSVR(input_matrix, C=1.0, dual=False, epsilon=0.0001, loss=squared_epsilon_insensitive, tol=0.001) |
In this case, we can see that the top-performing pipeline achieved the mean MAE of about 29.14. This is a skillful model, and close to a top-performing model on this dataset.
The top-performing pipeline is then saved to a file named “tpot_insurance_best_model.py“.
Opening this file, you can see that there is some generic code for loading a dataset and fitting the pipeline. An example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVR # NOTE: Make sure that the outcome column is labeled 'target' in the data file tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64) features = tpot_data.drop('target', axis=1) training_features, testing_features, training_target, testing_target = \ train_test_split(features, tpot_data['target'], random_state=1) # Average CV score on the training set was: -29.147625969129034 exported_pipeline = LinearSVR(C=1.0, dual=False, epsilon=0.0001, loss="squared_epsilon_insensitive", tol=0.001) # Fix random state in exported estimator if hasattr(exported_pipeline, 'random_state'): setattr(exported_pipeline, 'random_state', 1) exported_pipeline.fit(training_features, training_target) results = exported_pipeline.predict(testing_features) |
Note: as-is, this code does not execute, by design. It is a template that you can copy-paste into your project.
In this case, we can see that the best-performing model is a pipeline comprised of a linear support vector machine model.
We can adapt this code to fit a final model on all available data and make a prediction for new data.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# example of fitting a final model and making a prediction on the insurance dataset from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVR # load dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/auto-insurance.csv' dataframe = read_csv(url, header=None) # split into input and output elements data = dataframe.values data = data.astype('float32') X, y = data[:, :-1], data[:, -1] # Average CV score on the training set was: -29.147625969129034 exported_pipeline = LinearSVR(C=1.0, dual=False, epsilon=0.0001, loss="squared_epsilon_insensitive", tol=0.001) # Fix random state in exported estimator if hasattr(exported_pipeline, 'random_state'): setattr(exported_pipeline, 'random_state', 1) # fit the model exported_pipeline.fit(X, y) # make a prediction on a new row of data row = [108] yhat = exported_pipeline.predict([row]) print('Predicted: %.3f' % yhat[0]) |
Running the example fits the best-performing model on the dataset and makes a prediction for a single row of new data.
|
1 |
Predicted: 389.612 |
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science, 2016.
- TPOT Documentation.
- TPOT GitHub Project.
Summary
In this tutorial, you discovered how to use TPOT for AutoML with Scikit-Learn machine learning algorithms in Python.
Specifically, you learned:
- TPOT is an open-source library for AutoML with scikit-learn data preparation and machine learning models.
- How to use TPOT to automatically discover top-performing models for classification tasks.
- How to use TPOT to automatically discover top-performing models for regression tasks.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Discover Fast Machine Learning in Python!

Develop Your Own Models in Minutes
...with just a few lines of scikit-learn code
Learn how in my new Ebook:
Machine Learning Mastery With Python
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, modeling, tuning, and much more...
Finally Bring Machine Learning To
Your Own Projects
Skip the Academics. Just Results.

 Libraries for Python")




perfect!!!
Thanks!
Thank you for your tutorial! Extremely useful!
The only thing that I get the following result for TPOT for Regression-code:
WARNING:stopit:Code block execution exceeded 2 seconds timeout
Traceback (most recent call last):
…
stopit.utils.TimeoutException
Is there something wrong?
Thanks.
Looks like a warning, perhaps ignore for now.
Is it good for high dimensions?
I don’t see why not.
Jason, very good tutorial. I like the AutoML series. The TPOT and Auto-Sklearn were one of the first AutoML packages. The ability to search for the best models is a really helpful and speed-up the data science process. Today, other aspects of ML become important, like explainability. The ML model cant be a black-box and should provide information about how it works and why is doing such predictions. This greatly helps to understand data and the model. There is an AutoML package that is producing extensive explanations for models: https://github.com/mljar/mljar-supervised I hope you will find it valuable and will present for your readers. Cheers.
Thanks for sharing.
Thanks for advancing my (non-technical) understanding of concepts used by developers.
For complex real world challenges such as climate change or urban logistics, how high an accuracy may result given that naivity is contrary to currently accepted theory in Physics, and that underlying technology and people’s and social philosophy changes over time?
You’re welcome.
I don’t follow your question, sorry. Not sure we can address climate change with simple predictive models.
I really appreciate this especially the fact that hyperparameter tuning is giving me headache right now.
However, in your classification model, you encoded y as a string. Any reasons for that? (I thought all model parameters are meant to be numeric.
# minimally prepare dataset
X = X.astype(‘float32’)
y = LabelEncoder().fit_transform(y.astype(‘str’))
Thanks.
Yes, I’m ensuring the variables provided to the label encoder prior to ordinal encoding are a string. It’s an old habit.
How many algorithms or models within TPOT are there many or few? and do you prefer automatically discovering well-performing models or manually
It will search many combinations of sklearn models.
If you prefer automatically discovering well-performing models which one do you prefer and why? thank you.
1- Autosklearn
2- TPOT
3- Hyperopt-sklearn
Perhaps try each on your project and use the one you prefer or that best meets your requirements.
Good afternoon Jason,
Great article and examples!
Question: I understand the idea of stacking as: data -> several algorithms -> intermediate outputs -> next algorithm -> final prediction. In your classification example there is optimal model : stacking of GaussianNaiveBayes and later GradientBoosting. Is there inside only one GNB model (which looks too simple) or do I miss something?
Best regards!
Sometimes a simple model performs well or best.
Dear Dr Jason,
I ran the first example and the output was not the same.
Compared to your example
In other words why did I get MLPClassifier as my best classifier with score 0.877 and you got LinearSVR with score 0.8667 YET I am running the same code.
Thank you
Anthony of Sydney
Well done.
Yes, this is a common question:
https://machinelearningmastery.com/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
Dear Dr Jason,
Similarly for the regression I got:
and your experiment produced LinearBestSVR with score of -29.148
Same code used on my computer but slightly different results.
Thank you,
Anthony of Sydney
Yes, this is to be expected given the stochastic nature of the optimization algorithm.
AttributeError: ‘TPOTClassifier’ object has no attribute ‘_optimized_pipeline’
Perhaps some of these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Dear Dr Jason,
Is it possible to optimize also pipeline steps like scaler or encoder? Or it can optimize only model hyperparameters?
I think so – I believe TPOT does or supports this.
How does one now put this results from the tpot into production?
Perhaps discover the config used for the best model, then fit a final model with the config on all data:
https://machinelearningmastery.com/train-final-machine-learning-model/
Hi Jason, in the TPOT regressor example as with my trial of the code
from sklearn.model_selection import train_test_splitis automatically imported from the tpot boiler plate generated .py file it generates. Would it be good to make use of this to validate the model? Or in your example without using this what could be some other validations that can be used for regression? Also can tpot be applied regression problem that is made up of times series data?It might help as a starting point code for validation of the model.
It would be risky using this framework for time series as I don’t think the temporal ordering of samples would be respected making the evaluation invalid.
Hi Jason,
Thanks for the tutorial
I used TPOT for hyperparameter optimization for GradientBoostingRegressor. But I ran to the following error.
Terminals are required to have a unique name. Consider using the argument ‘name’ to rename your second GradientBoostingRegressor__learning_rate=0 terminal.
Could you please share your thoughts on that?
Cheers.
Perhaps try an alternate model type?
Perhaps check all your libraries are up to date?
Perhaps contact the tpot project?
Perhaps post code and error on stackoverflow?
Hi Jason,
Thank you very much for the tutorial.
I have two questions.
1. Is there any solution to see the details (For example, the tree structure of genetic programming etc.) of the best model or all the models which are built in each generation.
2. in genetic programming, the initial random population are generated from the defame given by us (real data) or not?
Thank you in advance,
If you want to get detail of each generation, consider the checkpoint parameter in tpot. But you may need to write some code to visualize the details from the checkpoints.
Dear Dr. Jason,
Your idea helps me a lot. However, I wonder How I can get the result with MSE instead of MAE. Looking forward to your reply
I appreciate any help you can provide.
Hi Jaret…You could modify the following:
scoring=’neg_mean_absolute_error’
to
scoring=’neg_mean_squared_error’
Dear Dr.Jason,
Thank you for your reply, now I have mastered scoring, but how to see the first model that reads CSV files ((n_splits=10, n_repeats=3, random_state=1 What does it mean)? As a new machine learning scholar, Your suggestion was really helpful to me, thank you for your generosity.
Hello,
Would it be necessary or make sense to run TPOT after receiving new training data or when we decide to retrain a current model? Thank you
-John
Dear Dr. Jason,
I tried the example for classification, but I am not getting the same output. Instead, I am getting the error “A pipeline has not yet been optimized. Please call fit() first”.
Hi Akansha…The following resource may be of interest:
https://stackoverflow.com/questions/57347026/runtimeerror-a-pipeline-has-not-yet-been-optimized-please-call-fit-first-pro
Hi James,
Thank you for your reply. I checked the resource. They have mentioned that there might be a problem with the data itself. So I checked the sonar dataset link and it was not working. I will try to use a dataset from my computer to see If it works.