
Indoor movement prediction involves using wireless sensor strength data to predict the location and motion of subjects within a building.
It is a challenging problem as there is no direct analytical model to translate the variable length traces of signal strength data from multiple sensors into user behavior.
The ‘indoor user movement‘ dataset is a standard and freely available time series classification problem.
In this tutorial, you will discover the indoor movement prediction time series classification problem and how to engineer features and evaluate machine learning algorithms for the problem.
After completing this tutorial, you will know:
- The time series classification problem of predicting the movement between rooms based on sensor strength.
- How to investigate the data in order to better understand the problem and how to engineer features from the raw data for predictive modeling.
- How to spot check a suite of classification algorithms and tune one algorithm to further lift performance on the problem.
Kick-start your project with my new book Deep Learning for Time Series Forecasting, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Sept/2018: Added a link to a mirror of the dataset.

Indoor Movement Time Series Classification with Machine Learning Algorithms
Photo by Nola Tularosa, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- Indoor User Movement Prediction
- Indoor Movement Prediction Dataset
- Model Evaluation
- Data Preparation
- Algorithm Spot-Check
Indoor User Movement Prediction
The ‘indoor user movement‘ prediction problem involves determining whether an individual has moved between rooms based on the change in signal strength measured by wireless detectors in the environment.
The dataset was collected and made available by Davide Bacciu, et al. from the University of Pisa in Italy and first described in their 2011 paper “Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing” as a dataset for exploring a methodology that seems like recurrent neural networks called ‘reservoir computing.’
The problem is a special case of the more generic problem of predicting indoor user localization and movement patterns.
Data was collected by positioning four wireless sensors in the environment and one on the subject. The subject moved through the environment while the four wireless sensors detected and recorded a time series of sensor strength.
The result is a dataset comprised of variable length time series with four variates describing trajectory through a well-defined static environment, and the classification of whether the movement led to the subject changing rooms in the environment.
It is a challenging problem because there is no obvious and generic way to relate signal strength data to subject location in an environment.
The relationship between the RSS and the location of the tracked object cannot be easily formulated into an analytical model, as it strongly depends on the characteristics of the environment as well as on the wireless devices involved. I
— Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing, 2011.
The data was collected under controlled experimental conditions.
Sensors were placed in three pairs of two connected rooms containing typical office furniture. Two sensors were placed in the corners of each of the two rooms and the subject walked one of six predefined paths through the rooms. Predictions are made at a point along each path that may or may not lead to a change of room.
The cartoon below makes this clear, showing the sensor locations (A1-A4), the six possible paths that may be walked, and the two points (M) where a prediction will be made.
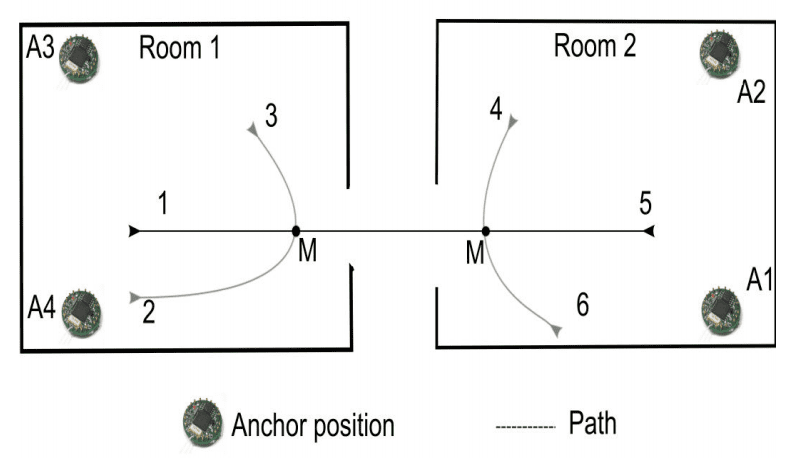
Overview of two rooms, sensor locations and the 6 pre-defined paths.
Taken from “Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing.”
Three datasets were collected from the three pairs of two rooms in which the paths were walked and sensor measurements taken, referred to as Dataset 1, Dataset 2, and Dataset 3.
The table below, taken from the paper, summarizes the number of paths walked in each of the three datasets, the total number of room changes and non-room-changes (class label), and the lengths of the time series inputs.

Summary of sensor data collected from the three pairs of two rooms.
Taken from “Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing.”
Technically, the data is comprised of multivariate time series inputs and a classification output and may be described as a time series classification problem.
The RSS values from the four anchors are organized into sequences of varying length corresponding to trajectory measurements from the starting point until marker M. A target classification label is associated to each input sequence to indicate whether the user is about to change its location (room) or not.
— Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing, 2011.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Indoor Movement Prediction Dataset
The dataset is freely available from the UCI Machine Learning Repository:
In case the above site goes down (which can happen), here is a direct link to a mirror of the dataset:
The data can be downloaded as a .zip file that contains the following salient files:
- dataset/MovementAAL_RSS_???.csv The RSS traces for each movement, where ‘???’ in the filename marks the trace number from 1 to 311.
- dataset/MovementAAL_target.csv The mapping of trace number to the output class value or target.
- groups/MovementAAL_DatasetGroup.csv The mapping of trace number to the dataset group 1, 2, or 3 marking the pair of rooms from which the trace was recorded.
- groups/MovementAAL_Paths.csv The mapping of trace number to the path type, 1-6, marked in the cartoon diagram above.
The provided data is already normalized.
Specifically, each input variable is normalized into the range [-1,1] per dataset (pair of rooms), and the output class variable is marked -1 for no transition between rooms and +1 for a transition through the rooms.
[…] put data comprises time series of 4 dimensional RSS measurements (NU = 4) corresponding to the 4 anchors […] normalized in the range [−1, 1] independently for each dataset
— Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing, 2011.
The scaling of data by dataset may (or may not) introduce additional challenges when combining observations across datasets if the pre-normalized distributions differ greatly.
The time series for one trace in a given trace file are provided in temporal order, where one row records the observations for a single time step. The data is recorded at 8Hz, meaning that one second of clock time elapses for eight time steps in the data.
Below is an example of a trace, taken from ‘dataset/MovementAAL_RSS_1.csv‘, which has the output target ‘1’ (a room transition occurred), from group 1 (the first pair of rooms) and is the path 1 (a straight shot from left to right between the rooms).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#RSS_anchor1, RSS_anchor2, RSS_anchor3, RSS_anchor4 -0.90476,-0.48,0.28571,0.3 -0.57143,-0.32,0.14286,0.3 -0.38095,-0.28,-0.14286,0.35 -0.28571,-0.2,-0.47619,0.35 -0.14286,-0.2,0.14286,-0.2 -0.14286,-0.2,0.047619,0 -0.14286,-0.16,-0.38095,0.2 -0.14286,-0.04,-0.61905,-0.2 -0.095238,-0.08,0.14286,-0.55 -0.047619,0.04,-0.095238,0.05 -0.19048,-0.04,0.095238,0.4 -0.095238,-0.04,-0.14286,0.35 -0.33333,-0.08,-0.28571,-0.2 -0.2381,0.04,0.14286,0.35 0,0.08,0.14286,0.05 -0.095238,0.04,0.095238,0.1 -0.14286,-0.2,0.14286,0.5 -0.19048,0.04,-0.42857,0.3 -0.14286,-0.08,-0.2381,0.15 -0.33333,0.16,-0.14286,-0.8 -0.42857,0.16,-0.28571,-0.1 -0.71429,0.16,-0.28571,0.2 -0.095238,-0.08,0.095238,0.35 -0.28571,0.04,0.14286,0.2 0,0.04,0.14286,0.1 0,0.04,-0.047619,-0.05 -0.14286,-0.6,-0.28571,-0.1 |
The datasets were used in two specific ways (experimental settings or ES) to evaluate predictive models on the problem, designated ES1 and ES2, as described in the first paper.
- ES1: Combines datasets 1 and 2, which is split into train (80%) and test (20%) sets to evaluate a model.
- ES2: Combines datasets 1 and 2 which are used as a training set (66%) and dataset 3 is used as a test set (34%) to evaluate a model.
The ES1 case evaluates a model to generalize movement within two pairs of known rooms, that is, rooms with known geometry. The ES2 case attempts to generalize movement from two rooms to a third unseen room: a harder problem.
The 2011 paper, reports performance of about 95% classification accuracy on ES1 and about 89% on ES2, which after some testing of a suite of algorithms myself is very impressive.
Load and Explore Dataset
In this section, we will load the data into memory and explore it with summarization and visualization to help better understand how the problem might be modeled.
First, download the dataset and unzip the downloaded archive into your current working directory.
Load Dataset
The targets, groups, and path files can be loaded directly as Pandas DataFrames.
|
1 2 3 4 5 |
# load mapping files from pandas import read_csv target_mapping = read_csv('dataset/MovementAAL_target.csv', header=0) group_mapping = read_csv('groups/MovementAAL_DatasetGroup.csv', header=0) paths_mapping = read_csv('groups/MovementAAL_Paths.csv', header=0) |
The signal strength traces are stored in separate files in the dataset/ directory.
These can be loaded by iterating over all files in the directory and loading the sequences as directly. Because each sequence has a variable length (variable number of rows), we can store the NumPy array for each trace in a list.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# load sequences and targets into memory from pandas import read_csv from os import listdir sequences = list() directory = 'dataset' target_mapping = None for name in listdir(directory): filename = directory + '/' + name if filename.endswith('_target.csv'): continue df = read_csv(filename, header=0) values = df.values sequences.append(values) |
We can tie all of this together into a function named load_dataset() and load the data into memory.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# load user movement dataset into memory from pandas import read_csv from os import listdir # return list of traces, and arrays for targets, groups and paths def load_dataset(prefix=''): grps_dir, data_dir = prefix+'groups/', prefix+'dataset/' # load mapping files targets = read_csv(data_dir + 'MovementAAL_target.csv', header=0) groups = read_csv(grps_dir + 'MovementAAL_DatasetGroup.csv', header=0) paths = read_csv(grps_dir + 'MovementAAL_Paths.csv', header=0) # load traces sequences = list() target_mapping = None for name in listdir(data_dir): filename = data_dir + name if filename.endswith('_target.csv'): continue df = read_csv(filename, header=0) values = df.values sequences.append(values) return sequences, targets.values[:,1], groups.values[:,1], paths.values[:,1] # load dataset sequences, targets, groups, paths = load_dataset() # summarize shape of the loaded data print(len(sequences), targets.shape, groups.shape, paths.shape) |
Running the example loads the data and shows that 314 traces were correctly loaded from disk along with their associated outputs (targets as -1 or +1), dataset number, (group as 1, 2 or 3) and path number (path as 1-6).
|
1 |
314 (314,) (314,) (314,) |
Basic Information
We can now take a closer look at the loaded data to better understand or confirm our understanding of the problem.
We know from the paper that the dataset is reasonably balanced in terms of the two classes. We can confirm this by summarizing the class breakdown of all observations.
|
1 2 3 4 |
# summarize class breakdown class1,class2 = len(targets[targets==-1]), len(targets[targets==1]) print('Class=-1: %d %.3f%%' % (class1, class1/len(targets)*100)) print('Class=+1: %d %.3f%%' % (class2, class2/len(targets)*100)) |
Next, we can review the distribution of the sensor strength values for each of the four anchor points by plotting a histogram of the raw values.
This requires that we create one array with all rows of observations so that we can plot the distribution of each column. The vstack() NumPy function will do this job for us.
|
1 2 3 4 5 6 7 8 |
# histogram for each anchor point all_rows = vstack(sequences) pyplot.figure() variables = [0, 1, 2, 3] for v in variables: pyplot.subplot(len(variables), 1, v+1) pyplot.hist(all_rows[:, v], bins=20) pyplot.show() |
Finally, another interesting aspect to look at is the distribution of the length of the traces.
We can summarize this distribution using a histogram.
|
1 2 3 4 |
# histogram for trace lengths trace_lengths = [len(x) for x in sequences] pyplot.hist(trace_lengths, bins=50) pyplot.show() |
Putting this all together, the complete example of loading and summarizing the data is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# summarize simple information about user movement data from os import listdir from numpy import array from numpy import vstack from pandas import read_csv from matplotlib import pyplot # return list of traces, and arrays for targets, groups and paths def load_dataset(prefix=''): grps_dir, data_dir = prefix+'groups/', prefix+'dataset/' # load mapping files targets = read_csv(data_dir + 'MovementAAL_target.csv', header=0) groups = read_csv(grps_dir + 'MovementAAL_DatasetGroup.csv', header=0) paths = read_csv(grps_dir + 'MovementAAL_Paths.csv', header=0) # load traces sequences = list() target_mapping = None for name in listdir(data_dir): filename = data_dir + name if filename.endswith('_target.csv'): continue df = read_csv(filename, header=0) values = df.values sequences.append(values) return sequences, targets.values[:,1], groups.values[:,1], paths.values[:,1] # load dataset sequences, targets, groups, paths = load_dataset() # summarize class breakdown class1,class2 = len(targets[targets==-1]), len(targets[targets==1]) print('Class=-1: %d %.3f%%' % (class1, class1/len(targets)*100)) print('Class=+1: %d %.3f%%' % (class2, class2/len(targets)*100)) # histogram for each anchor point all_rows = vstack(sequences) pyplot.figure() variables = [0, 1, 2, 3] for v in variables: pyplot.subplot(len(variables), 1, v+1) pyplot.hist(all_rows[:, v], bins=20) pyplot.show() # histogram for trace lengths trace_lengths = [len(x) for x in sequences] pyplot.hist(trace_lengths, bins=50) pyplot.show() |
Running the example first summarizes the class distribution for the observations.
The results confirm our expectations of the full dataset being nearly perfectly balanced in terms of observations of both class outcomes.
|
1 2 |
Class=-1: 156 49.682% Class=+1: 158 50.318% |
Next, a histogram of the sensor strength for each anchor point is created, summarizing the data distributions.
We can see that the distributions for each variable are close to normal showing Gaussian-like shapes. We can also see perhaps too many observations around -1. This might indicate a generic “no strength” observation that could be marked or even filtered out from the sequences.
It might be interesting to investigate whether the distributions change by path type or even dataset number.
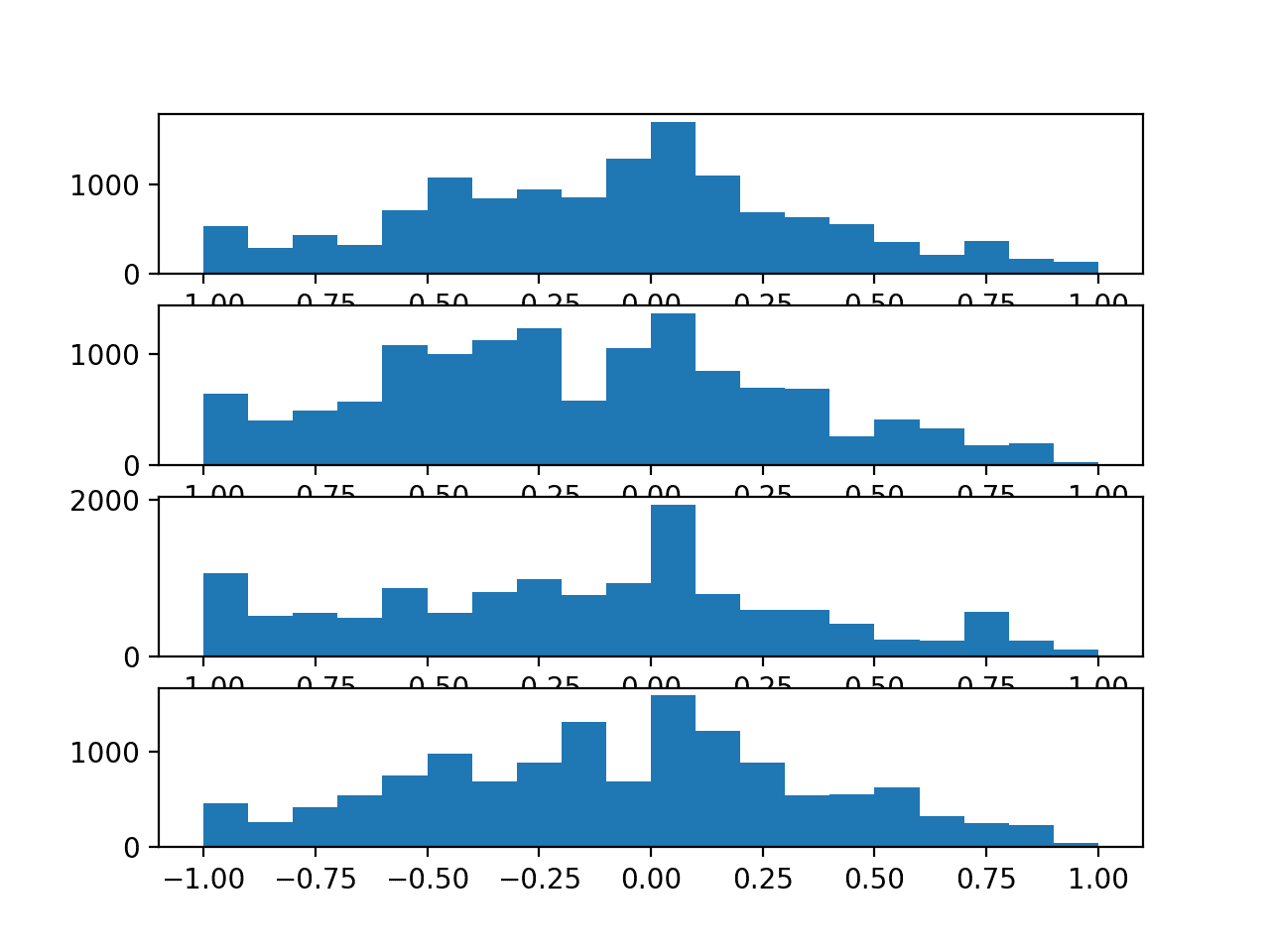
Histograms for the sensor strength values for each anchor point
Finally, a histogram of the sequence lengths is created.
We can see clusters of sequences with lengths around 25, 40, and 60. We can also see that if we wanted to trim long sequences that a maximum length of around 70 time steps might be appropriate. The smallest length appears to be 19.
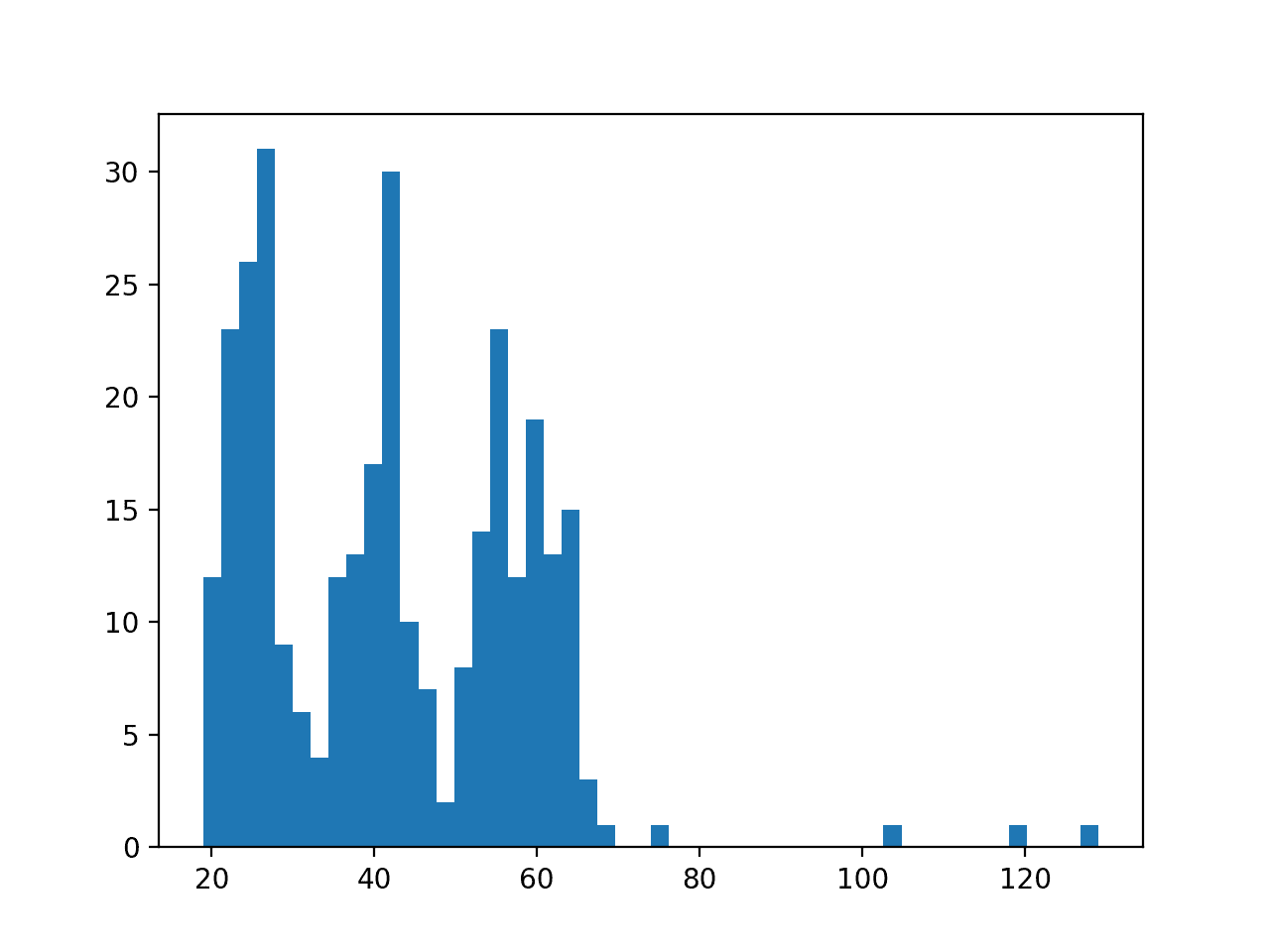
Histogram of sensor strength sequence lengths
Time Series Plots
We are working with time series data, so it is important that we actually review some examples of the sequences.
We can group traces by their path and plot an example of one trace for each path. The expectation is that traces for different paths may look different in some way.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# group sequences by paths paths = [1,2,3,4,5,6] seq_paths = dict() for path in paths: seq_paths[path] = [sequences[j] for j in range(len(paths)) if paths[j]==path] # plot one example of a trace for each path pyplot.figure() for i in paths: pyplot.subplot(len(paths), 1, i) # line plot each variable for j in [0, 1, 2, 3]: pyplot.plot(seq_paths[i][0][:, j], label='Anchor ' + str(j+1)) pyplot.title('Path ' + str(i), y=0, loc='left') pyplot.show() |
We can also plot each series from one trace along with the trend predicted by a linear regression model. This will make any trends in the series obvious.
We can fit a linear regression for a given series using the lstsq() NumPy Function.
The function regress() below takes a series as a single variable, fits a linear regression model via least squares, and predicts the output for each time step returning a sequence that captures the trend in the data.
|
1 2 3 4 5 6 7 8 9 |
# fit a linear regression function and return the predicted values for the series def regress(y): # define input as the time step X = array([i for i in range(len(y))]).reshape(len(y), 1) # fit linear regression via least squares b = lstsq(X, y)[0][0] # predict trend on time step yhat = b * X[:,0] return yhat |
We can use the function to plot the trend for the time series for each variable in a single trace.
|
1 2 3 4 5 6 7 8 9 10 11 |
# plot series for a single trace with trend seq = sequences[0] variables = [0, 1, 2, 3] pyplot.figure() for i in variables: pyplot.subplot(len(variables), 1, i+1) # plot the series pyplot.plot(seq[:,i]) # plot the trend pyplot.plot(regress(seq[:,i])) pyplot.show() |
Tying all of this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
# plot series data from os import listdir from numpy import array from numpy import vstack from numpy.linalg import lstsq from pandas import read_csv from matplotlib import pyplot # return list of traces, and arrays for targets, groups and paths def load_dataset(prefix=''): grps_dir, data_dir = prefix+'groups/', prefix+'dataset/' # load mapping files targets = read_csv(data_dir + 'MovementAAL_target.csv', header=0) groups = read_csv(grps_dir + 'MovementAAL_DatasetGroup.csv', header=0) paths = read_csv(grps_dir + 'MovementAAL_Paths.csv', header=0) # load traces sequences = list() target_mapping = None for name in listdir(data_dir): filename = data_dir + name if filename.endswith('_target.csv'): continue df = read_csv(filename, header=0) values = df.values sequences.append(values) return sequences, targets.values[:,1], groups.values[:,1], paths.values[:,1] # fit a linear regression function and return the predicted values for the series def regress(y): # define input as the time step X = array([i for i in range(len(y))]).reshape(len(y), 1) # fit linear regression via least squares b = lstsq(X, y)[0][0] # predict trend on time step yhat = b * X[:,0] return yhat # load dataset sequences, targets, groups, paths = load_dataset() # group sequences by paths paths = [1,2,3,4,5,6] seq_paths = dict() for path in paths: seq_paths[path] = [sequences[j] for j in range(len(paths)) if paths[j]==path] # plot one example of a trace for each path pyplot.figure() for i in paths: pyplot.subplot(len(paths), 1, i) # line plot each variable for j in [0, 1, 2, 3]: pyplot.plot(seq_paths[i][0][:, j], label='Anchor ' + str(j+1)) pyplot.title('Path ' + str(i), y=0, loc='left') pyplot.show() # plot series for a single trace with trend seq = sequences[0] variables = [0, 1, 2, 3] pyplot.figure() for i in variables: pyplot.subplot(len(variables), 1, i+1) # plot the series pyplot.plot(seq[:,i]) # plot the trend pyplot.plot(regress(seq[:,i])) pyplot.show() |
Running the example creates a plot containing six figures, one for each of the six paths. A given figure shows the line plots of a single trace with the four variables of the trace, one for each anchor point.
Perhaps the chosen traces are representative of each path, perhaps not.
We can see some clear differences with regards to:
- The grouping of variables over time. Pairs of variables may be grouped together or all variables may be grouped together at a given time.
- The trend of variables over time. Variables bunch together towards the middle or spread apart towards the extremes.
Ideally, if these changes in behavior are predictive, a predictive model must extract these features, or be presented with a summary of these features as input.
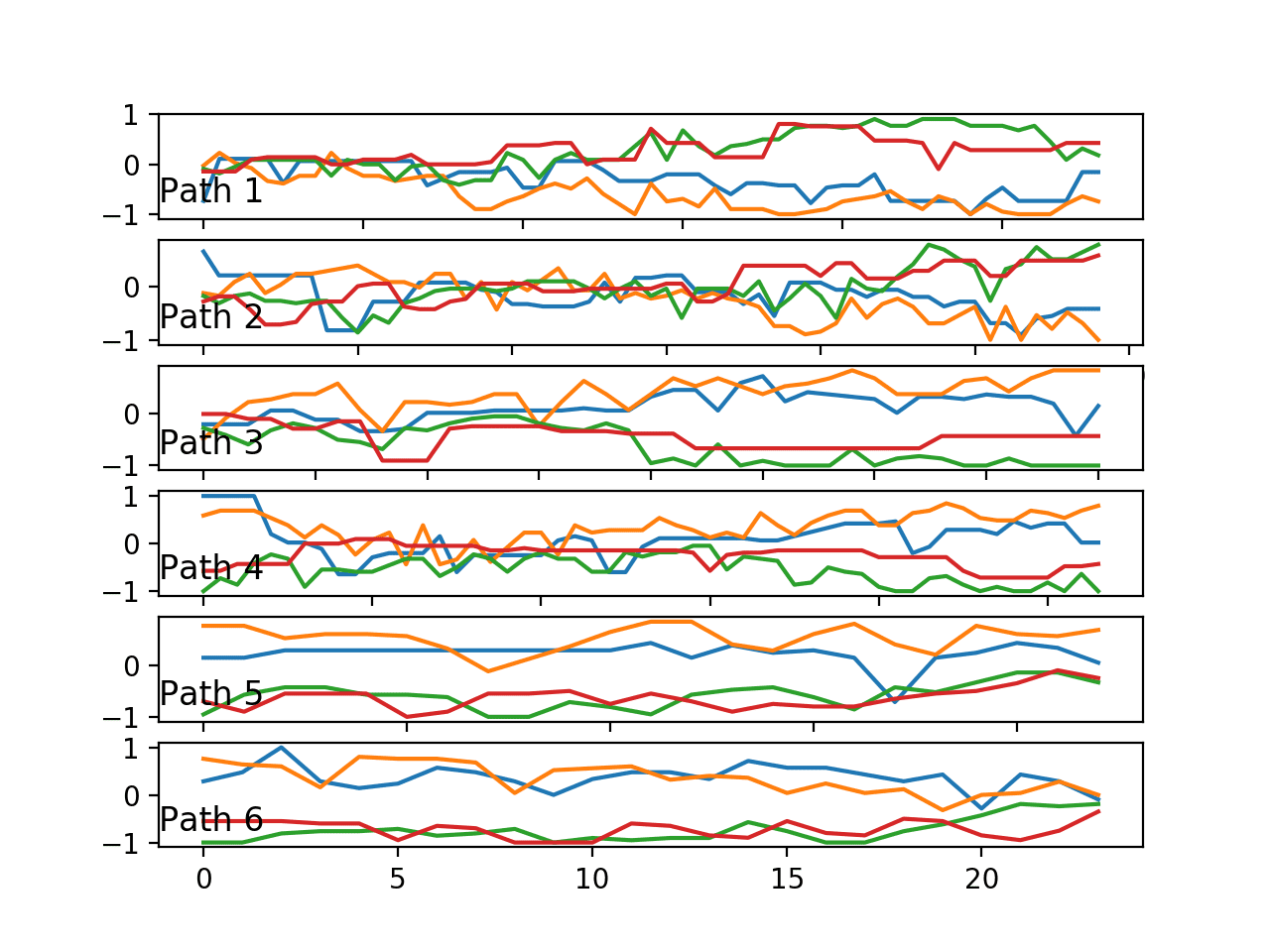
Line plots of one trace (4 variables) for each of the six paths.
A second plot is created showing the line plots for the four series in a single trace along with the trend lines.
We can see that, at least for this trace, there is a clear trend in the sensor strength data as the user moves around the environment. This may suggest the opportunity to make the data stationary prior to modeling or using the trend for each series in a trace (observations or coefficients) as inputs to a predictive model.
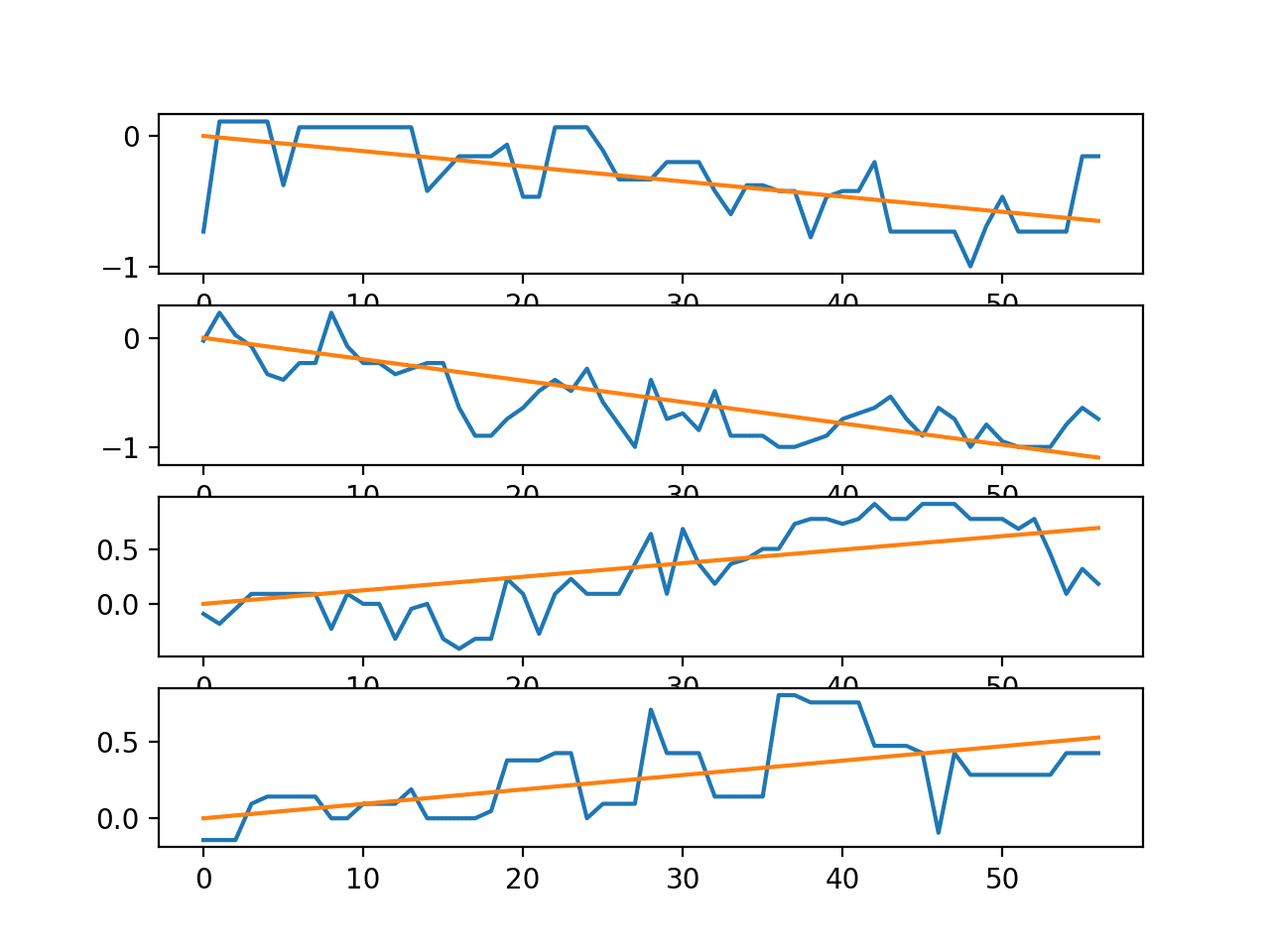
Line plots for the time series in a single trace with trend lines
Model Evaluation
There are many ways to fit and evaluate a model on this data.
Classification accuracy seems like a good first-cut evaluation metric given the balance of the classes. More nuance can be sought in the future by predicting probabilities and exploring thresholds on an ROC curve.
I see two main themes in using this data:
- Same Room: Can a model trained on traces in a room predict the outcome of new traces in that room?
- Different Room: Can a model trained on traces in one or two rooms predict the outcome of new traces in a different room?
The ES1 and ES2 cases described in the paper and summarized above explore these questions and provide a useful starting point.
First, we must partition the loaded traces and targets into the three groups.
|
1 2 3 4 5 6 7 8 9 10 |
# separate traces seq1 = [sequences[i] for i in range(len(groups)) if groups[i]==1] seq2 = [sequences[i] for i in range(len(groups)) if groups[i]==2] seq3 = [sequences[i] for i in range(len(groups)) if groups[i]==3] print(len(seq1),len(seq2),len(seq3)) # separate target targets1 = [targets[i] for i in range(len(groups)) if groups[i]==1] targets2 = [targets[i] for i in range(len(groups)) if groups[i]==2] targets3 = [targets[i] for i in range(len(groups)) if groups[i]==3] print(len(targets1),len(targets2),len(targets3)) |
In the case of ES1, we can use k-fold cross-validation where k=5 to use the same ratio from the paper and the repeated evaluation provides some robustness to the evaluation.
We can use the cross_val_score() function from scikit-learn to evaluate a model and then calculate the mean and standard deviation of the scores.
|
1 2 3 4 5 6 7 |
# evaluate model for ES1 from numpy import mean from numpy import std from sklearn.model_selection import cross_val_score ... scores = cross_val_score(model, X, y, scoring='accuracy', cv=5, n_jobs=-1) m, s = mean(scores), std(scores) |
In the case of ES2, we can fit the model on datasets 1 and 2 and test model skill on dataset 3 directly.
Data Preparation
There is flexibility in how the input data is framed for the prediction problem.
Two approaches come to mind:
- Automatic Feature Learning. Deep neural networks are capable of automatic feature learning and recurrent neural networks can directly support multivariate multi-step input data. A recurrent neural network could be used, such as an LSTM or 1D CNN. The sequences could be padded to be the same length, such as 70 time steps, and a Masking layer could be used to ignore the padded time steps.
- Feature Engineering. Alternately, the variable length sequences could be summarized as a single fixed length vector and provided to standard machine learning models for prediction. This would require careful feature engineering in order to provide a sufficient description of the trace for the model to learn a mapping to the output class.
Both are interesting approaches.
As a first pass, we will prepare the more traditional fixed-length vector input via manual feature engineering.
Below are some ideas on features that could be included in the vector:
- First, middle, or last n observations for a variable.
- Mean or standard deviation for the first, middle, or last n observations for a variable.
- Difference between the last and first n’th observations
- Differenced first, middle, or last n observations for a variable.
- Linear regression coefficients of all, first, middle, or last n observations for a variable.
- Linear regression predicted trend of first, middle, or last n observations for a variable.
Additionally, data scaling is probably not required of the raw values as the data has already been scaled to the range -1 to 1. Scaling may be required if new features are added with different units.
Some of the variables do show some trend, suggesting that perhaps a differencing of the variables may help in teasing out a signal.
The distribution of each variable is nearly Gaussian, so some algorithms may benefit from standardization, or perhaps even a Box-Cox transform.
Algorithm Spot-Check
In this section, we will spot-check the default configuration for a suite of standard machine learning algorithms with different sets of engineered features.
Spot-checking is a useful technique to flush out quickly whether there is any signal to be learned in the mapping between inputs and outputs with engineered features as most of the tested methods will pick something up. The method can also suggest methods that might be worth further investigating.
A downside is that each method is not given its best chance (configuration) to show what it can do on the problem, meaning any methods that are further investigated will be biased by the first results.
In these tests, we will look at a suite of six different types of algorithms, specifically:
- Logistic Regression.
- k-Nearest Neighbors.
- Decision Tree.
- Support Vector Machine.
- Random Forest.
- Gradient Boosting Machine.
We will test the default configurations of these methods on features that focus on the end of the time series variables as they are likely the most predictive of whether a room transition will occur or not.
Last n Observations
The last n observations are likely to be predictive of whether the movement leads to a transition in rooms.
The smallest number of time steps in the trace data is 19, therefore, we will use n=19 as a starting point.
The function below named create_dataset() will create a fixed-length vector using the last n observations from each trace in a flat one-dimensional vector, then add the target as the last element of the vector.
This flattening of the trace data is required for simple machine learning algorithms.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# create a fixed 1d vector for each trace with output variable def create_dataset(sequences, targets): # create the transformed dataset transformed = list() n_vars = 4 n_steps = 19 # process each trace in turn for i in range(len(sequences)): seq = sequences[i] vector = list() # last n observations for row in range(1, n_steps+1): for col in range(n_vars): vector.append(seq[-row, col]) # add output vector.append(targets[i]) # store transformed.append(vector) # prepare array transformed = array(transformed) transformed = transformed.astype('float32') return transformed |
We can load the dataset as before and sort it into the datasets 1, 2, and 3 as described in the “Model Evaluation” section.
We can then call the create_dataset() function to create the datasets required for the ES1 and ES2 cases, specifically ES1 combines datasets 1 and 2, whereas ES2 uses datasets 1 and 2 as a training set and dataset 3 as a test set.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
# prepare fixed length vector dataset from os import listdir from numpy import array from numpy import savetxt from pandas import read_csv # return list of traces, and arrays for targets, groups and paths def load_dataset(prefix=''): grps_dir, data_dir = prefix+'groups/', prefix+'dataset/' # load mapping files targets = read_csv(data_dir + 'MovementAAL_target.csv', header=0) groups = read_csv(grps_dir + 'MovementAAL_DatasetGroup.csv', header=0) paths = read_csv(grps_dir + 'MovementAAL_Paths.csv', header=0) # load traces sequences = list() target_mapping = None for name in listdir(data_dir): filename = data_dir + name if filename.endswith('_target.csv'): continue df = read_csv(filename, header=0) values = df.values sequences.append(values) return sequences, targets.values[:,1], groups.values[:,1], paths.values[:,1] # create a fixed 1d vector for each trace with output variable def create_dataset(sequences, targets): # create the transformed dataset transformed = list() n_vars = 4 n_steps = 19 # process each trace in turn for i in range(len(sequences)): seq = sequences[i] vector = list() # last n observations for row in range(1, n_steps+1): for col in range(n_vars): vector.append(seq[-row, col]) # add output vector.append(targets[i]) # store transformed.append(vector) # prepare array transformed = array(transformed) transformed = transformed.astype('float32') return transformed # load dataset sequences, targets, groups, paths = load_dataset() # separate traces seq1 = [sequences[i] for i in range(len(groups)) if groups[i]==1] seq2 = [sequences[i] for i in range(len(groups)) if groups[i]==2] seq3 = [sequences[i] for i in range(len(groups)) if groups[i]==3] # separate target targets1 = [targets[i] for i in range(len(groups)) if groups[i]==1] targets2 = [targets[i] for i in range(len(groups)) if groups[i]==2] targets3 = [targets[i] for i in range(len(groups)) if groups[i]==3] # create ES1 dataset es1 = create_dataset(seq1+seq2, targets1+targets2) print('ES1: %s' % str(es1.shape)) savetxt('es1.csv', es1, delimiter=',') # create ES2 dataset es2_train = create_dataset(seq1+seq2, targets1+targets2) es2_test = create_dataset(seq3, targets3) print('ES2 Train: %s' % str(es2_train.shape)) print('ES2 Test: %s' % str(es2_test.shape)) savetxt('es2_train.csv', es2_train, delimiter=',') savetxt('es2_test.csv', es2_test, delimiter=',') |
Running the example creates three new CSV files, specifically ‘es1.csv‘, ‘es2_train.csv‘, and ‘es2_test.csv‘ for the ES1 and ES2 cases respectively.
The shapes of these datasets are also summarized.
|
1 2 3 |
ES1: (210, 77) ES2 Train: (210, 77) ES2 Test: (104, 77) |
Next, we can evaluate models on the ES1 dataset.
After some testing, it appears that standardizing the dataset results in better model skill for those methods that rely on distance values (KNN and SVM) and generally has no effect on other methods. Therefore a Pipeline is used to evaluate each algorithm that first standardizes the dataset.
The complete example of spot checking algorithms on the new dataset is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# spot check for ES1 from numpy import mean from numpy import std from pandas import read_csv from matplotlib import pyplot from sklearn.model_selection import cross_val_score from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier # load dataset dataset = read_csv('es1.csv', header=None) # split into inputs and outputs values = dataset.values X, y = values[:, :-1], values[:, -1] # create a list of models to evaluate models, names = list(), list() # logistic models.append(LogisticRegression()) names.append('LR') # knn models.append(KNeighborsClassifier()) names.append('KNN') # cart models.append(DecisionTreeClassifier()) names.append('CART') # svm models.append(SVC()) names.append('SVM') # random forest models.append(RandomForestClassifier()) names.append('RF') # gbm models.append(GradientBoostingClassifier()) names.append('GBM') # evaluate models all_scores = list() for i in range(len(models)): # create a pipeline for the model s = StandardScaler() p = Pipeline(steps=[('s',s), ('m',models[i])]) scores = cross_val_score(p, X, y, scoring='accuracy', cv=5, n_jobs=-1) all_scores.append(scores) # summarize m, s = mean(scores)*100, std(scores)*100 print('%s %.3f%% +/-%.3f' % (names[i], m, s)) # plot pyplot.boxplot(all_scores, labels=names) pyplot.show() |
Running the example prints the estimated performance of each algorithm, including the mean and standard deviation over 5-fold cross-validation.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The results suggest SVM might be worth looking at in more detail at 58% accuracy.
|
1 2 3 4 5 6 |
LR 55.285% +/-5.518 KNN 50.897% +/-5.310 CART 50.501% +/-10.922 SVM 58.551% +/-7.707 RF 50.442% +/-6.355 GBM 55.749% +/-5.423 |
The results are also presented as box-and-whisker plots showing the distribution of scores.
Again, SVM appears to have good average performance and tight variance.
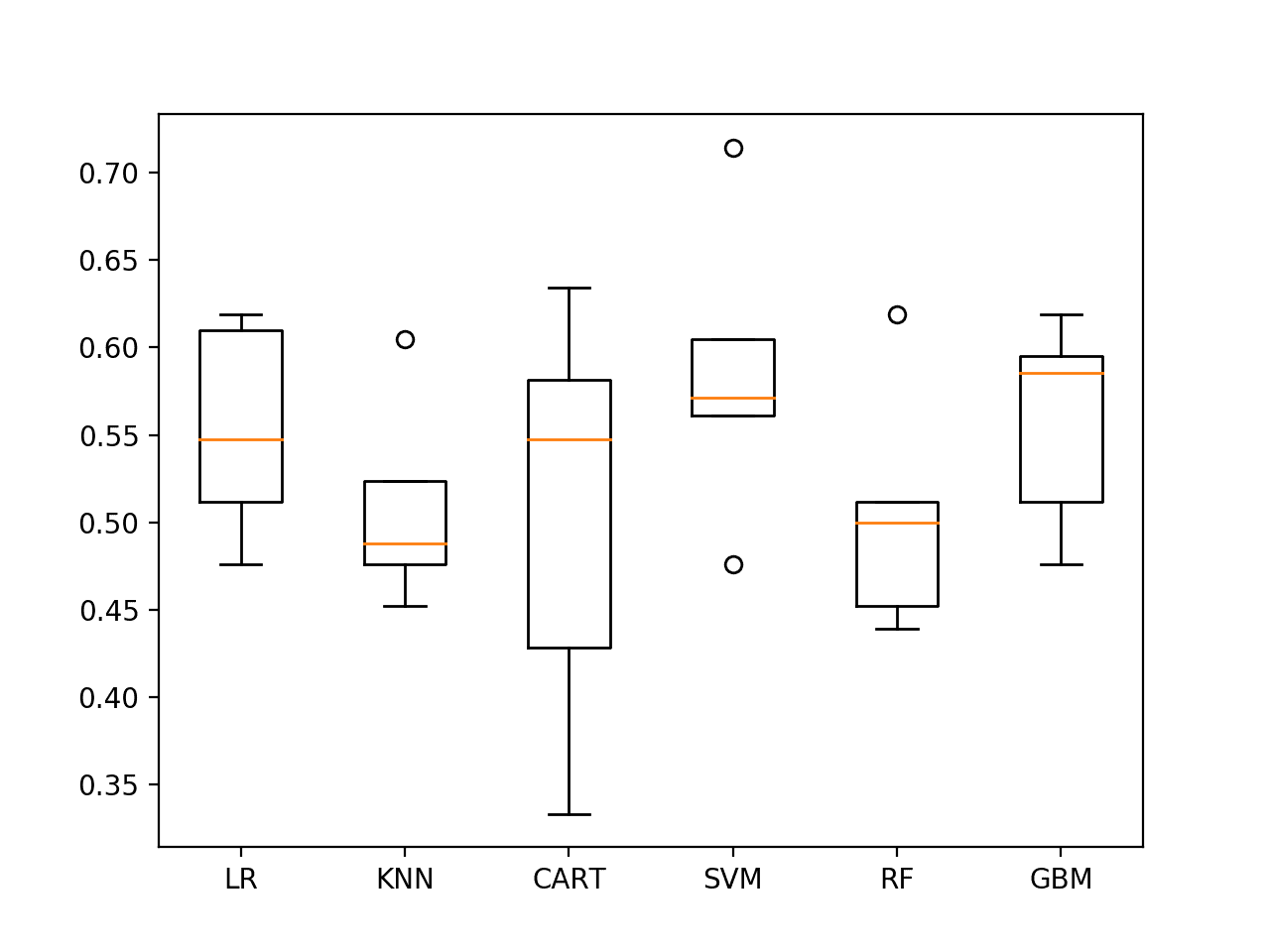
Spot-check Algorithms on ES1 with last 19 observations
Last n Observations With Padding
We can pad each trace to a fixed length.
This will then provide the flexibility to include more of the prior n observations in each sequence. The choice of n must also be balanced with the increase in padded values added to shorter sequences that in turn may negatively impact the performance of the model on those sequences.
We can pad each sequence by adding the 0.0 value to the beginning of each variable sequence until a maximum length, e.g. 200 time steps, is reached. We can do this using the pad() NumPy function.
|
1 2 3 4 5 |
from numpy import pad ... # pad sequences max_length = 200 seq = pad(seq, ((max_length-len(seq),0),(0,0)), 'constant', constant_values=(0.0)) |
The updated version of the create_dataset() function with padding support is below.
We will try n=25 to include 25 of the last observations in each sequence in each vector. This value was found with a little trial and error, although you may want to explore whether other configurations result in better skill.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# create a fixed 1d vector for each trace with output variable def create_dataset(sequences, targets): # create the transformed dataset transformed = list() n_vars, n_steps, max_length = 4, 25, 200 # process each trace in turn for i in range(len(sequences)): seq = sequences[i] # pad sequences seq = pad(seq, ((max_length-len(seq),0),(0,0)), 'constant', constant_values=(0.0)) vector = list() # last n observations for row in range(1, n_steps+1): for col in range(n_vars): vector.append(seq[-row, col]) # add output vector.append(targets[i]) # store transformed.append(vector) # prepare array transformed = array(transformed) transformed = transformed.astype('float32') return transformed |
Running the script again with the new function creates updated CSV files.
|
1 2 3 |
ES1: (210, 101) ES2 Train: (210, 101) ES2 Test: (104, 101) |
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Again, re-running the spot-check script on the data results in a small lift in model skill for SVM and also suggests that KNN might be worth investigating further.
|
1 2 3 4 5 6 |
LR 54.344% +/-6.195 KNN 58.562% +/-4.456 CART 52.837% +/-7.650 SVM 59.515% +/-6.054 RF 50.396% +/-7.069 GBM 50.873% +/-5.416 |
The box plots for KNN and SVM show good performance and relatively tight standard deviations.
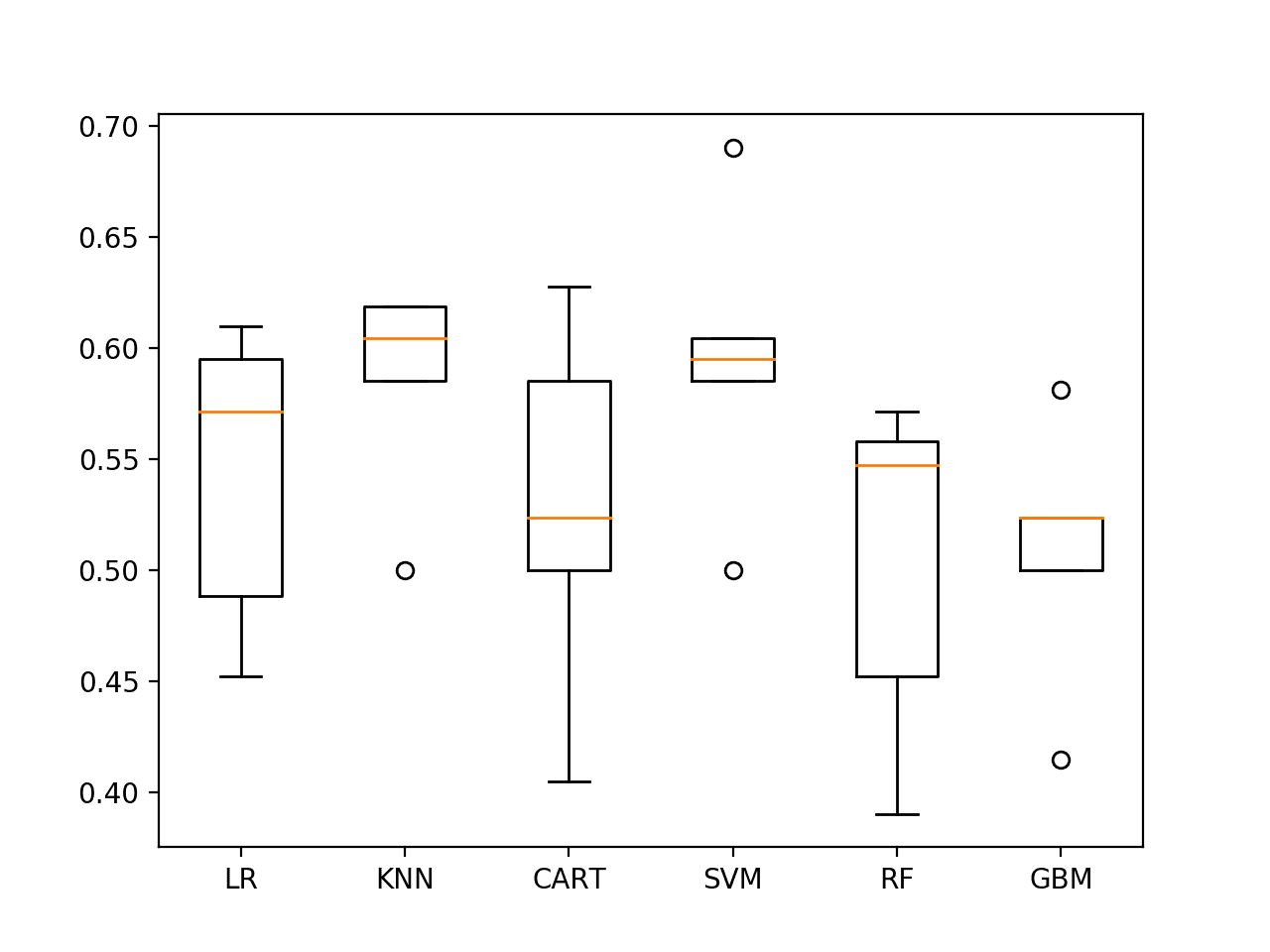
Spot-check Algorithms on ES1 with last 25 observations
We can update the spot-check to grid search a suite of k values for the KNN algorithm to see if the skill of the model can be further improved with a little tuning.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# spot check for ES1 from numpy import mean from numpy import std from pandas import read_csv from matplotlib import pyplot from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsClassifier from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler # load dataset dataset = read_csv('es1.csv', header=None) # split into inputs and outputs values = dataset.values X, y = values[:, :-1], values[:, -1] # try a range of k values all_scores, names = list(), list() for k in range(1,22): # evaluate scaler = StandardScaler() model = KNeighborsClassifier(n_neighbors=k) pipeline = Pipeline(steps=[('s',scaler), ('m',model)]) names.append(str(k)) scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=5, n_jobs=-1) all_scores.append(scores) # summarize m, s = mean(scores)*100, std(scores)*100 print('k=%d %.3f%% +/-%.3f' % (k, m, s)) # plot pyplot.boxplot(all_scores, labels=names) pyplot.show() |
Running the example prints the mean and standard deviation of the accuracy with k values from 1 to 21.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that a k=7 results in the best skill of 62.872%.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
k=1 49.534% +/-4.407 k=2 49.489% +/-4.201 k=3 56.599% +/-6.923 k=4 55.660% +/-6.600 k=5 58.562% +/-4.456 k=6 59.991% +/-7.901 k=7 62.872% +/-8.261 k=8 59.538% +/-5.528 k=9 57.633% +/-4.723 k=10 59.074% +/-7.164 k=11 58.097% +/-7.583 k=12 58.097% +/-5.294 k=13 57.179% +/-5.101 k=14 57.644% +/-3.175 k=15 59.572% +/-5.481 k=16 59.038% +/-1.881 k=17 59.027% +/-2.981 k=18 60.490% +/-3.368 k=19 60.014% +/-2.497 k=20 58.562% +/-2.018 k=21 58.131% +/-3.084 |
The box and whisker plots of accuracy scores for k values show that k values around seven, such as five and six, also produce stable and well-performing models on the dataset.
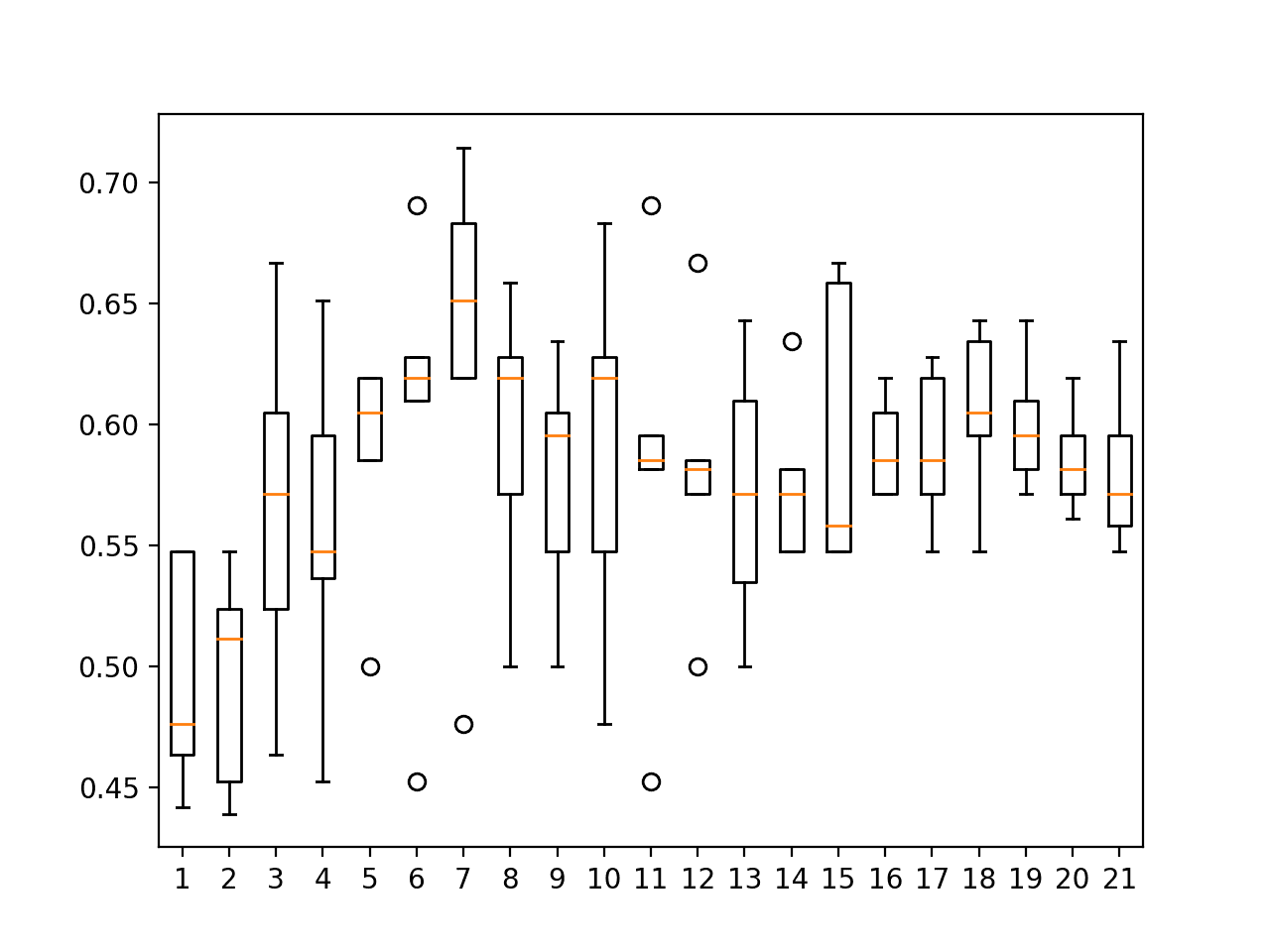
Spot-check KNN neighbors on ES1 with last 25 observations
Evaluate KNN on ES2
Now that we have some idea of a representation (n=25) and a model (KNN, k=7) that have some skill over a random prediction, we can test the approach on the harder ES2 dataset.
Each model is trained on the combination of dataset 1 and 2, then evaluated on dataset 3. The k-fold cross-validation procedure is not used, so we would expect the scores to be noisy.
The complete spot checking of algorithms for ES2 is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# spot check for ES2 from pandas import read_csv from matplotlib import pyplot from sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler # load dataset train = read_csv('es2_train.csv', header=None) test = read_csv('es2_test.csv', header=None) # split into inputs and outputs trainX, trainy = train.values[:, :-1], train.values[:, -1] testX, testy = test.values[:, :-1], test.values[:, -1] # create a list of models to evaluate models, names = list(), list() # logistic models.append(LogisticRegression()) names.append('LR') # knn models.append(KNeighborsClassifier()) names.append('KNN') # knn models.append(KNeighborsClassifier(n_neighbors=7)) names.append('KNN-7') # cart models.append(DecisionTreeClassifier()) names.append('CART') # svm models.append(SVC()) names.append('SVM') # random forest models.append(RandomForestClassifier()) names.append('RF') # gbm models.append(GradientBoostingClassifier()) names.append('GBM') # evaluate models all_scores = list() for i in range(len(models)): # create a pipeline for the model scaler = StandardScaler() model = Pipeline(steps=[('s',scaler), ('m',models[i])]) # fit # model = models[i] model.fit(trainX, trainy) # predict yhat = model.predict(testX) # evaluate score = accuracy_score(testy, yhat) * 100 all_scores.append(score) # summarize print('%s %.3f%%' % (names[i], score)) # plot pyplot.bar(names, all_scores) pyplot.show() |
Running the example reports the model accuracy on the ES2 scenario.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that KNN does well and that the KNN with seven neighbors found to perform well on ES1 also performs well on ES2.
|
1 2 3 4 5 6 7 |
LR 45.192% KNN 54.808% KNN-7 57.692% CART 53.846% SVM 51.923% RF 53.846% GBM 52.885% |
A bar chart of the accuracy scores helps to make the relative difference in performance between the methods clearer.
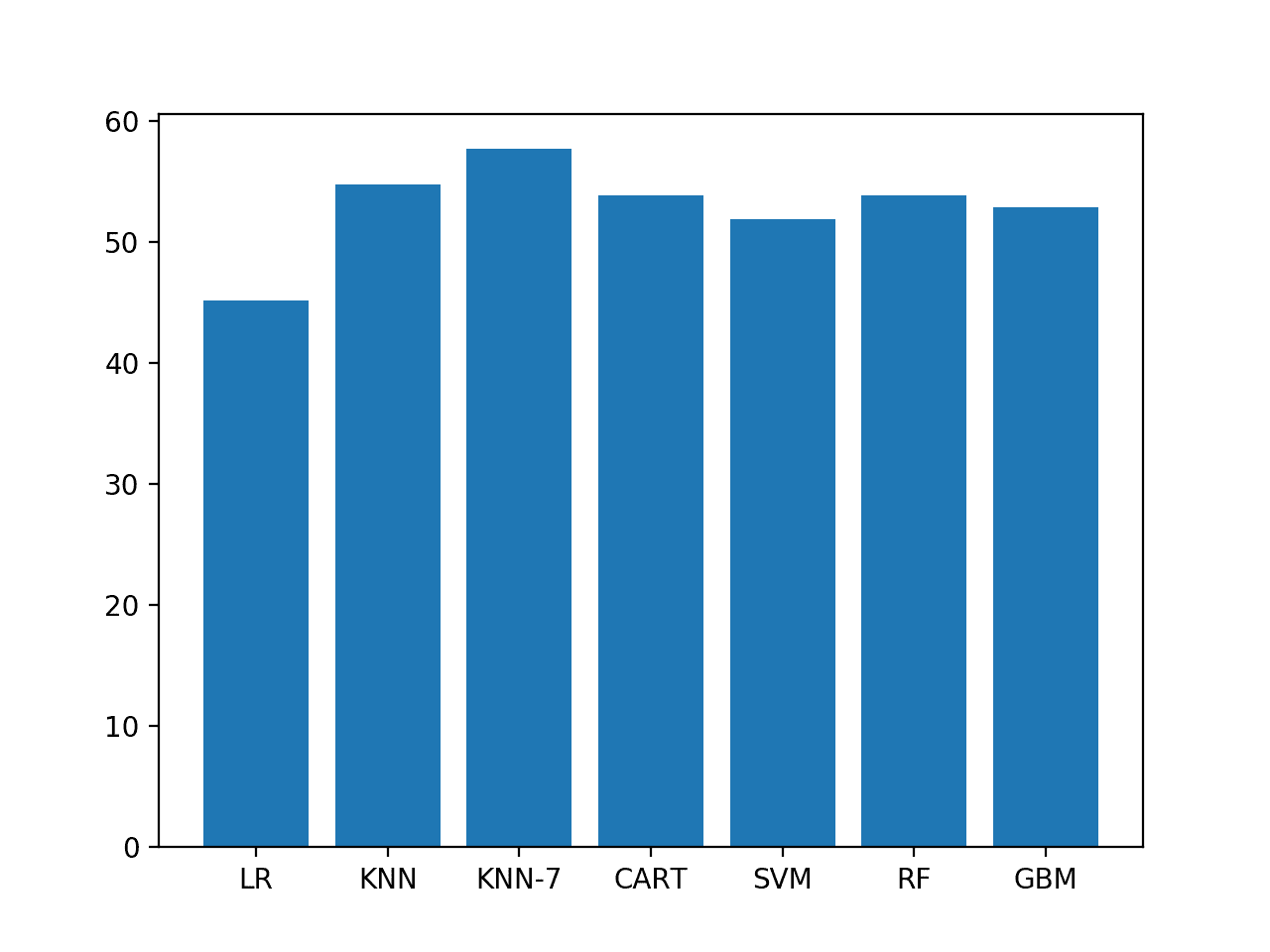
Bar chart of model accuracy on ES2
The chosen representation and model configurations do have skill over a naive prediction with 50% accuracy.
Further tuning may result in models with better skill, and we are a long way from the 95% and 89% accuracy reported in the paper on ES1 and ES2 respectively.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Data Preparation. There is a lot of opportunity to explore further data preparation methods such as normalization, differencing, and power transforms.
- Feature Engineering. Further feature engineering may result in better performing models, such as statistics for both the start, middle, and end of each sequence as well as trend information.
- Tuning. Only the KNN algorithm was given the opportunity for tuning; other models such as gradient boosting may benefit from fine tuning of hyperparameters.
- RNNs. This sequence classification task seems well suited to recurrent neural networks such as LSTMs that support variable length multivariate inputs. Some preliminary testing on this dataset (by myself) showed highly unstable results, but more extensive investigation may give better and even superior results.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- Predicting user movements in heterogeneous indoor environments by reservoir computing, 2011.
- An experimental characterization of reservoir computing in ambient assisted living applications, 2014.
API
Articles
- Indoor User Movement Prediction from RSS data Data Set, UCI Machine Learning Repository
- Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing, Paolo Barsocchi homepage.
- Indoor User Movement Prediction from RSS data Data Set, Laurae [French].
Summary
In this tutorial, you discovered the indoor movement prediction time series classification problem and how to engineer features and evaluate machine learning algorithms for the problem.
Specifically, you learned:
- The time series classification problem of predicting the movement between rooms based on sensor strength.
- How to investigate the data in order to better understand the problem and how to engineer features from the raw data for predictive modeling.
- How to spot check a suite of classification algorithms and tune one algorithm to further lift performance on the problem.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Time Series Today!

Develop Your Own Forecasting models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Time Series Forecasting
It provides self-study tutorials on topics like:
CNNs, LSTMs,
Multivariate Forecasting, Multi-Step Forecasting and much more...
Finally Bring Deep Learning to your Time Series Forecasting Projects
Skip the Academics. Just Results.

")




Hi Jason.
Many thanks for this great and helpful tutorial.
I went through the paper of Davide Bacciu, et al. (2011) “Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing”. His approach consisting in Reservoir Computing and LI-ESN seems impressively efficient.
Do you see any opporunity to implement such approach in Python?
All the best,
Remi
Not at this stage. I’m skeptical of the ability to reproduce the results in most papers.
Hello Jason,
Great tutorials on Multivariate Time Series and LSTM; really enjoyed reading them and learned a lot. I am new to the field (still taking online deep learning courses) and have a general question (I better say I need a general suggestion). Suppose I have a multivariate time series data, and I want to build a classifier model (three-class classification with values 0, 1, or 2). What is the best approach to tackle this problem? LSTM or multi-channel CNN? And have you written any other tutorials?
Thanks
I recommend testing a suite of methods in order to discover what works best for your specific dataset.
The links to the dataset do not seem to be working for me. Can anyone verify that the site is still up?
The site appears to be down, it does that some times. So sorry!
I have created a mirror of it here:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/IndoorMovement.zip
Thank you! Great work and thanks for sharing.
Thanks.
Hi Jason,
May I ask, is this a similar topic with Human Activity Recognition?
Best,
Allen
Not really, HAR is about “what is the person doing based on sensor data”, indoor movement is about “where are people in the building based on sensor data”.
hi jason, very nice tutorial!
I don’t get why you use “-row” in vector.append(seq[-row, col]) when you prepare the dataset.
We are adding the last “n” observations, working backward from the end of the dataset.
Ok but you are Reversing the order of the values. Why this choice?
Yes, the order does not matter for stateless machine learning algorithms – they are all seen as input variables.
Hi Jason , I don’t know why but when I use the function create_dataset I get the output
ES1: (1L, 77L)
ES2 Train: (1L, 77L)
ES2 Test: (1L, 77L)
instead of
ES1: (210, 77)
ES2 Train: (210, 77)
ES2 Test: (104, 77)
Are you able to confirm that you’re using Python 3.5+ and that your libraries are up to date?
yes I tryed both with python 2.7 and 3.6. However the problem was in the conversion to float32 in
transformed = transformed.astype(‘float32′)
i solved by converting the data directly when i cast to a numpy array by doing
transformed = np.array(transformed,dtype=’float32’)
Nice work!
Hi Jason
I got this error when I run cross_val_score() for the ES1 task.
TypeError(‘unbound method new_CreateProcess() must be called with _winapi instance as first argument (got str instance instead)’,)
Something odd might be going on with your Python environment.
Are you sure you’re running from the command line and not some notebook or IDE that is introducing new problems?
I m running with Visual Studio. The problem was the use of n_jobs=-1
Perhaps try setting n_jobs to 1.
Hi Jason.
just FYI i obtained the best performance for ES1 with naive gauss
Nice work!
Hi Jacob,
lassify the next 5 samples based on the past 20 observations in time. I was wondering if it is possible to do multi-step time series classification. And in case it is, if there is any example you could point me to.
Thank you.
I was talking to a Jacob while writing this question… and apparently cannot write and talk al the same time… Sorry about the mistake, Jason 🙂
No problem, zero offence taken!
Yes, you can frame the problem anyway you want.
I don’t think I have an example, sorry.
Hi Jason,
Great post! I have a question for you. When should I do normalization of time series data? Suppose I am using KNN, should I always do normalization?
Thanks.
When it improves model skill.
Hi Jason,
How about doing the feature engineering by TimeSeriesResampler in library tslearn?
Use this function to resample the sequences to be the same length. What’s pros and cons?
https://tslearn.readthedocs.io/en/latest/gen_modules/preprocessing/tslearn.preprocessing.TimeSeriesResampler.html#tslearn.preprocessing.TimeSeriesResampler
Thanks
Thanks for the suggestion.
Dear Jason,
Sorry for bothering, but some mistakes might be found.
Maybe your script has lost the right ID-sequences when the code reads the files. The sequence of the file reading does not correspond to the right ID-sequence in this case. The right ID-sequences have been put into filename.
Thank you for your attention.
Thanks for sharing.
Hi Jason
Will it be right to implement the kNN method on a Robot for Indoor localization with Wifi RSS fingerprinting? I have completed mapping and the localization is now possible with Triangulation/trilateration and fingerprinting. I would like to implement the localization based on AI at this point. I have used the same dataset with Random forest but the result is not good enough.
Perhaps try it and compare results to other methods.
Hi Jason,
Nice work. Could please clarify is it feasible or not for following use case.
A model to predict heart attack using ICU clinical time series data of multiple patients. I need to classify the patient based on past clinical data. binary classification using multivariate data for multiple patient.
Thank in Advance.
Hi Vanitha…We cannot speak to or recommend a specific path for you to take on your project, however we have content that will get you started along the right path for your models.
It seems you have various goals…time series forecasting, clustering, and binary classification. We have content that can help with understanding each concept.
The following is great starting point for all of our content:
https://machinelearningmastery.com/start-here/