
There are a vast number of different types of data preparation techniques that could be used on a predictive modeling project.
In some cases, the distribution of the data or the requirements of a machine learning model may suggest the data preparation needed, although this is rarely the case given the complexity and high-dimensionality of the data, the ever-increasing parade of new machine learning algorithms and limited, although human, limitations of the practitioner.
Instead, data preparation can be treated as another hyperparameter to tune as part of the modeling pipeline. This raises the question of how to know what data preparation methods to consider in the search, which can feel overwhelming to experts and beginners alike.
The solution is to think about the vast field of data preparation in a structured way and systematically evaluate data preparation techniques based on their effect on the raw data.
In this tutorial, you will discover a framework that provides a structured approach to both thinking about and grouping data preparation techniques for predictive modeling with structured data.
After completing this tutorial, you will know:
- The challenge and overwhelm of framing data preparation as yet an additional hyperparameter to tune in the machine learning modeling pipeline.
- A framework that defines five groups of data preparation techniques to consider.
- Examples of data preparation techniques that belong to each group that can be evaluated on your predictive modeling project.
Kick-start your project with my new book Data Preparation for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Framework for Data Preparation Techniques in Machine Learning
Photo by Phil Dolby, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Challenge of Data Preparation
- Framework for Data Preparation
- Data Preparation Techniques
Challenge of Data Preparation
Data preparation refers to transforming raw data into a form that is better suited to predictive modeling.
This may be required because the data itself contains mistakes or errors. It may also be because the chosen algorithms have expectations regarding the type and distribution of the data.
To make the task of data preparation even more challenging, it is also common that the data preparation required to get the best performance from a predictive model may not be obvious and may bend or violate the expectations of the model that is being used.
As such, it is common to treat the choice and configuration of data preparation applied to the raw data as yet another hyperparameter of the modeling pipeline to be tuned.
This framing of data preparation is very effective in practice, as it allows you to use automatic search techniques like grid search and random search to discover unintuitive data preparation steps that result in skillful predictive models.
This framing of data preparation can also feel overwhelming to beginners given the large number and variety of data preparation techniques.
The solution to this overwhelm is to think about data preparation techniques in a systematic way.
Want to Get Started With Data Preparation?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Framework for Data Preparation
Effective data preparation requires that the data preparation techniques available are organized and considered in a structured and systematic way.
This allows you to ensure that approach techniques are explored for your dataset and that potentially effective techniques are not skipped or ignored.
This can be achieved using a framework to organize data preparation techniques that consider their effect on the raw dataset.
For example, structured machine learning data, such as data we might store in a CSV file for classification and regression, consists of rows, columns, and values. We might consider data preparation techniques that operate at each of these levels.
- Data Preparation for Rows
- Data Preparation for Columns
- Data Preparation for Values
Data preparation for rows may be techniques that add or remove rows of data from the dataset. Similarly, data preparation for columns may be techniques that add or remove columns (features or variables) from the dataset. Whereas data preparation for values may be techniques that change the values in the dataset, often for a given column.
There is one more type of data preparation that does not neatly fit into this structure, and that is dimensionality reduction techniques. These techniques change the columns and the values at the same time, e.g. projecting the data into a lower-dimensional space.
- Data Preparation for Columns + Values
This raises the question of techniques that might apply to rows and values at the same time. This might include data preparation that consolidates rows of data in some way.
- Data Preparation for Rows + Values
We can summarize this framework and some high-level groups of data preparation methods in the following image.
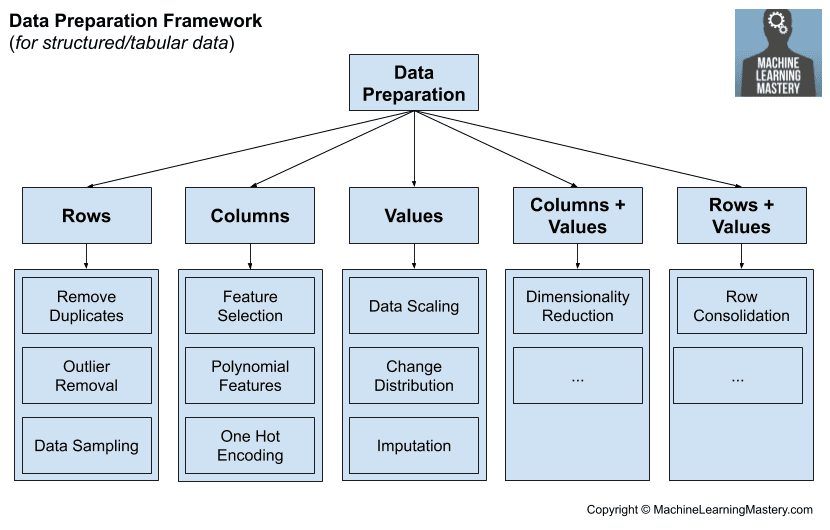
Machine Learning Data Preparation Framework
Now that we have a framework for thinking about data preparation based on their effect on the data, let’s look at examples of techniques that fit into each group.
Data Preparation Techniques
This section explores the five high-level groups of data preparation techniques defined in the previous section and suggests specific techniques that may fall within each group.
Did I miss one of your preferred or favorite data preparation techniques?
Let me know in the comments below.
Data Preparation for Rows
This group is for data preparation techniques that add or remove rows of data.
In machine learning, rows are often referred to as samples, examples, or instances.
These techniques are often used to augment a limited training dataset or to remove errors or ambiguity from the dataset.
The main class of techniques that come to mind are data preparation techniques that are often used for imbalanced classification.
This includes techniques such as SMOTE that create synthetic rows of training data for under-represented classes and random undersampling that remove examples for over-represented classes.
For more on SMOTE data sampling, see the tutorial:
It also includes more advanced combined over- and undersampling techniques that attempt to identify and remove ambiguous examples along the decision boundary of a classification problem and remove them or change their class label.
For more on these types of data preparation, see the tutorial:
This class of data preparation techniques also includes algorithms for identifying and removing outliers from the data. These are rows of data that may be far from the center of probability mass in the dataset and, in turn, may be unrepresentative of the data from the domain.
For more on outlier detection and removal methods, see the tutorial:
Data Preparation for Columns
This group is for data preparation techniques that add or remove columns of data.
In machine learning, columns are often referred to as variables or features.
These techniques are often required to either reduce the complexity (dimensionality) of a prediction problem or to unpack compound input variables or complex interactions between features.
The main class of techniques that come to mind are feature selection techniques.
This includes techniques that use statistics to score the relevance of input variables to the target variable based on the data type of each.
For more on these types of data preparation techniques, see the tutorial:
This also includes feature selection techniques that systematically test the impact of different combinations of input variables on the predictive skill of a machine learning model.
For more on these types of methods, see the tutorial:
Related are techniques that use a model to score the importance of input features based on their use by a predictive model, referred to as feature importance methods. These methods are often used for data interpretation, although they can also be used for feature selection.
For more on these types of methods, see the tutorial:
This group of methods also brings to mind techniques for creating or deriving new columns of data, new features. These are often referred to as feature engineering, although sometimes the whole field of data preparation is referred to as feature engineering.
For example, new features that represent values raised to exponents or multiplicative combinations of features can be created and added to the dataset as new columns.
For more on these types of data preparation techniques, see the tutorial:
This might also include data transforms that change a variable type, such as creating dummy variables for a categorical variable, often referred to as a one-hot encoding.
For more on these types of data preparation techniques, see the tutorial:
Data Preparation for Values
This group is for data preparation techniques that change the raw values in the data.
These techniques are often required to meet the expectations or requirements of specific machine learning algorithms.
The main class of techniques that come to mind is data transforms that change the scale or distribution of input variables.
For example, data transforms such as standardization and normalization change the scale of numeric input variables. Data transforms like ordinal encoding change the type of categorical input variables.
There are also many data transforms for changing the distribution of input variables.
For example, discretization or binning change the distribution of numerical input variables into categorical variables with an ordinal ranking.
For more on this type of data transform, see the tutorial:
The power transform can be used to change the distribution of data to remove a skew and make the distribution more normal (Gaussian).
For more on this method, see the tutorial:
The quantile transform is a flexible type of data preparation technique that can map a numerical input variable or to different types of distributions such as normal or Gaussian.
You can learn more about this data preparation technique here:
Another type of data preparation technique that belongs to this group are methods that systematically change values in the dataset.
This includes techniques that identify and replace missing values, often referred to as missing value imputation. This can be achieved using statistical methods or more advanced model-based methods.
For more on these methods, see the tutorial:
All of the methods discussed could also be considered feature engineering methods (e.g. fitting into the previously discussed group of data preparation methods) if the results of the transforms are appended to the raw data as new columns.
Data Preparation for Columns + Values
This group is for data preparation techniques that change both the number of columns and the values in the data.
The main class of techniques that this brings to mind are dimensionality reduction techniques that specifically reduce the number of columns and the scale and distribution of numerical input variables.
This includes matrix factorization methods used in linear algebra as well as manifold learning algorithms used in high-dimensional statistics.
For more information on these techniques, see the tutorial:
Although these techniques are designed to create projections of rows in a lower-dimensional space, perhaps this also leaves the door open to techniques that do the inverse. That is, use all or a subset of the input variables to create a projection into a higher-dimensional space, perhaps decompiling complex non-linear relationships.
Perhaps polynomial transforms where the results replace the raw dataset would fit into this class of data preparation methods.
Do you know of other methods that fit into this group?
Let me know in the comments below.
Data Preparation for Rows + Values
This group is for data preparation techniques that change both the number of rows and the values in the data.
I have not explicitly considered data transforms of this type before, but it falls out of the framework as defined.
A group of methods that come to mind are clustering algorithms where all or subsets of rows of data in the dataset are replaced with data samples at the cluster centers, referred to as cluster centroids.
Related might be replacing rows with exemplars (aggregates of rows) taken from specific machine learning algorithms, such as support vectors from a support vector machine, or the codebook vectors taken from a learning vector quantization.
Naturally, these aggregate rows are simply added to the dataset rather than replacing rows, then they would naturally fit into the “Data Preparation for Rows” group described above.
Do you know of other methods that fit into this group?
Let me know in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
Summary
In this tutorial, you discovered a framework for systematically grouping data preparation techniques based on their effect on raw data.
Specifically, you learned:
- The challenge and overwhelm of framing data preparation as yet an additional hyperparameter to tune in the machine learning modeling pipeline.
- A framework that defines five groups of data preparation techniques to consider.
- Examples of data preparation techniques that belong to each group that can be evaluated on your predictive modeling project.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Get a Handle on Modern Data Preparation!

Prepare Your Machine Learning Data in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Data Preparation for Machine Learning
It provides self-study tutorials with full working code on:
Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction,
and much more...






This is fantastic ! That chart alone explains almost everything . Thank you for posting such informative articles
You’re welcome. I’m happy it helps!
Exactly, the chart is amazing. Thank you very much, Jason!
You’re welcome.
A small feedback to the chart: I think the icing on the cake would be if the steps in the columns would be ordered like “for rows, first we usually do this…, secondly this…”, and so on.
Thanks for the suggestion!
Thank you for this very informativa article!
I invite you to read the article on Medium.com “A framework for feature engineering and machine learning pipelines”. I think it complements with yours very well. Although the author adresses just the “feature engineering” part of the pipeline, he suggests a framework where new features may be computed by a specific order (features that are just ‘row wise operations’, ‘column wise operations’, etc).
This is the link: https://medium.com/manomano-tech/a-framework-for-feature-engineering-and-machine-learning-pipelines-ddb53867a420
PS: just finished my Master’s thesis. I would like to thank you for all the code and explanations you share in this site, as they were very useful in adressing some of the problems I had to face (such as using SMOTE for imbalanced classification)
Thanks for sharing Filipe.
Well done on your thesis! You’re very welcome.
Hi Jason, long time reader of your blog but first time commenter. I’m a data scientist and I refer to your posts/books almost every day.
I had to say thanks because these “Framework” posts are so helpful! These “Framework” posts are especially helpful to provide very high level overview of all the possibilities when performing a task, when revisiting an old topic or learning a new one. The simple chart solves the “I don’t know what I don’t know” question! These can be the entry point/roadmap for readers to each of your excellent topics.
A minor suggestion to make this post truly comprehensive (representative of all posts in the “Data preparation” topic is to add data leakage to this post and link your amazing article https://machinelearningmastery.com/data-preparation-without-data-leakage/
Keep going at it! Would love to see your plan for new “Framework” posts as I have been collecting resources on a couple of topics for personal use (explaining/debugging ML predictions for example) and can send them your way if you’re interested 🙂
Thanks!
You’re very welcome.
Thanks for the suggestion. Data leakage is more something to consider/avoid when using data preparation, rather than a data preparation technique. It does not fit in neatly, it’s orthogonal.
You should incorporate this framework in your “Data Preparation for Machine Learning” book too.
Thanks for the suggestion.
It felt too advanced or off topic for the book.
Perhaps pivoting could justify a rows+columns category?
Nice suggestion:
https://en.wikipedia.org/wiki/Pivot_table
I read your blog, really helpful for me. You explain very briefly about the machine learning course. Thanks for sharing this blog.
Thanks.
Hi Jason
Great work!
Just a minimal comment. As for data preparation for rows, I missed the technique named Instance selection. I think that is a very important topic to add.
Best
Thank you for the suggestion!
Hi Jason, Great article, well organized.
Can you please share good resources to know about the “codebook vectors taken from a learning vector quantization.”?
Thanks.
Perhaps start here:
https://machinelearningmastery.com/implement-learning-vector-quantization-scratch-python/
Thank you Jason.
You’re welcome.
Thank you Jason!
You’re welcome.
Thank you Jason, you are truly a Godsend
You’re welcome.
Hi Jason,
Great tuto, as always!
Thanks!
Great article! Thank you a lot for sharing your knowledge.
Thanks!
Great set of articles Jason. It will put a newbie to machine learning like me on a “becoming better at machine learning” course.
I am looking for simple techniques with examples to predict from the models I develop.If you could help. Thanks.
Thanks!
This will help you make predictions:
https://machinelearningmastery.com/make-predictions-scikit-learn/
Great article! Do you have a discussion for ‘data preparation framework for unstructured data’? I’m interested to see how your chart contents changes in the unstructured case.
Thanks!
What do you mean by unstructured data? Not tabular? Like images and text?
Hi Jason,
in which category would you put the operations “group by” and “join” in your framework (Row, Column, Value, Column+Value, Row+Value)?
Best,
Harald
Perhaps steps before “data preparation”, e.g. denormalization.
I see … so you see operations as “selection” (choose rows) or “projection” (choose columns) not belong to data preparation?
Would fit into your framework I guess because “projection” would also reduce the amount of columns … however, how would you group these operations? 🙂
They do, but gathering data or domain-specific denormalization might be a step before more generic methods.
Hi Jason,
I have examples of hyperparameter tuning ( e.g. Listing 9.15: Example of comparing the number of neighbors used in the KNNImputer transform when evaluating a model.) and comparing algorithms (e.g. Listing 13.1: Example of comparing multiple algorithms.), but would it be reasonable to extend to this and include various combinations of imputers and dimensionality reduction? In other words, for each algorithm, two or more imputation methods are tried, within these, two or more feature selection methods are tried, within these, hyperparameter tuning. Are you aware of an example like this? It also possible that what I’m proposing is unnecessary/there’s a better approach.
Thanks
Sure, try it and see if it helps.
hi, Jason. Good post. I have one question, which step should go first in data preparation? imuting missing data or scaling/standardization? THX!
It really depends.
Perhaps experiment with different orderings and see what works best for your data/model/pipeline.