
Text summarization is the task of creating short, accurate, and fluent summaries from larger text documents.
Recently deep learning methods have proven effective at the abstractive approach to text summarization.
In this post, you will discover three different models that build on top of the effective Encoder-Decoder architecture developed for sequence-to-sequence prediction in machine translation.
After reading this post, you will know:
- The Facebook AI Research model that uses the Encoder-Decoder model with a convolutional neural network encoder.
- The IBM Watson model that uses the Encoder-Decoder model with pointing and hierarchical attention.
- The Stanford / Google model that uses the Encoder-Decoder model with pointing and coverage.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Encoder-Decoder Deep Learning Models for Text Summarization
Photos by Hiếu Bùi, some rights reserved.
Models Overview
We will look at three different models for text summarization, named for the organizations with which the authors of the models were affiliated at the time of writing:
- Facebook Model
- IBM Model
- Google Model
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Facebook Model
This approach was described by Alexander Rush, et al. from Facebook AI Research (FAIR) in their 2015 paper “A Neural Attention Model for Abstractive Sentence Summarization“.
The model was developed for sentence summarization, specifically:
Given an input sentence, the goal is to produce a condensed summary. […] A summarizer takes x as input and outputs a shortened sentence y of length N < M. We will assume that the words in the summary also come from the same vocabulary
This is a simpler problem than, say, full document summarization.
The approach follows the general approach used for neural machine translation with an encoder and a decoder. Three different encodings are explored:
- Bag-of-Words Encoder. The input sentence is encoded using a bag-of-words model, discarding word order information.
- Convolutional Encoder. A word embedding representation is used followed by time-delay convolutional layers across words and pooling layers.
- Attention-Based Encoder. A word embedding representation is used with a simple attention mechanism over a context vector, providing a type of soft alignment between input sentence and output summary.
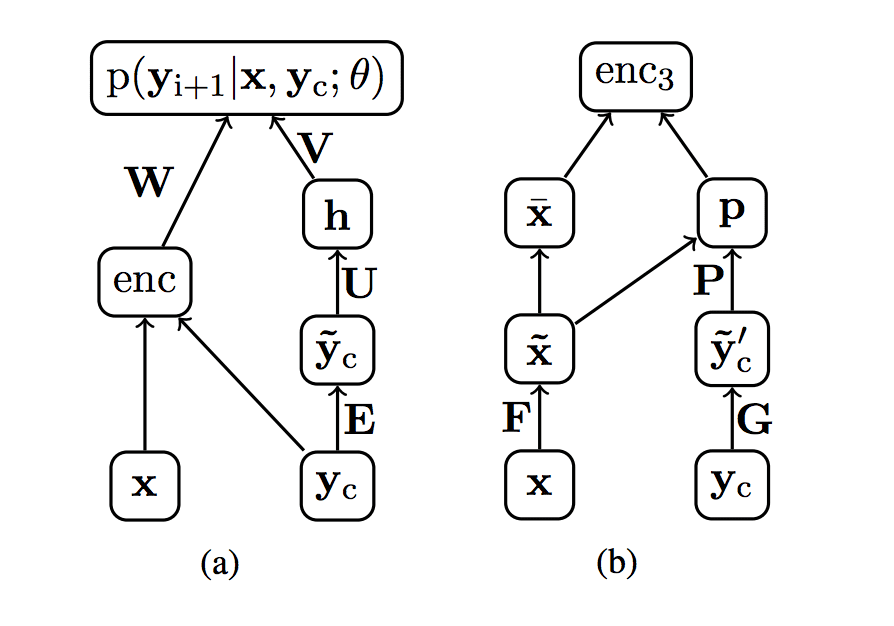
Network Diagram of Encoder and Decoder Elements
Taken from “A Neural Attention Model for Abstractive Sentence Summarization”.
A beam search is then used in the generation of text summaries, not unlike the approach used in machine translation.
The model was evaluated on the standard DUC-2014 dataset that involves generating approximately 14-word summaries for 500 news articles.
The data for this task consists of 500 news articles from the New York Times and Associated Press Wire services each paired with 4 different human-generated reference summaries (not actually headlines), capped at 75 bytes.
The model was also evaluated on the Gigaword dataset of approximately 9.5 million news articles, where a headline was generated given the first sentence of the news article.
Results were reported on both problems using the ROUGE-1, ROUGE-2, and ROUGE-L measures and the tuned system was shown to achieve state-of-the-art results on the DUC-2004 dataset.
The model shows significant performance gains on the DUC-2004 shared task compared with several strong baselines.
IBM Model
This approach was described by Ramesh Nallapati, et al. from IBM Watson in their 2016 paper “Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond“.
The approach is based on the encoder-decoder recurrent neural network with attention, developed for machine translation.
Our baseline model corresponds to the neural machine translation model used in Bahdanau et al. (2014). The encoder consists of a bidirectional GRU-RNN (Chung et al., 2014), while the decoder consists of a uni-directional GRU-RNN with the same hidden-state size as that of the encoder, and an attention mechanism over the source-hidden states and a soft-max layer over target vocabulary to generate words.
A word embedding for input words is used, in addition to an embedding for tagged parts of speech and discretized TF and IDF features. This richer input representation was designed to give the model better performance on identifying key concepts and entities in the source text.
The model also uses a learned-switch mechanism to decide whether or not to generate an output word or point to a word in the input sequence, designed to handle rare and low-frequency words.
… the decoder is equipped with a ‘switch’ that decides between using the generator or a pointer at every time-step. If the switch is turned on, the decoder produces a word from its target vocabulary in the normal fashion. However, if the switch is turned off, the decoder instead generates a pointer to one of the word-positions in the source.
Finally, the model is hierarchical in that the attention mechanism operates both at the word-level and at the sentence level on the encoded input data.

Hierarchical encoder with hierarchical attention.
Taken from “Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond.”
A total of 6 variants of the approach were evaluated on the DUC-2003/2004 dataset and the Gigaword dataset, both used to evaluate the Facebook model.
The model was also evaluated on a new corpus of news articles from the CNN and Daily Mail websites.
The IBM approach achieved impressive results on the standard datasets compared to the Facebook approach and others.
… we apply the attentional encoder-decoder for the task of abstractive summarization with very promising results, outperforming state-of-the-art results significantly on two different datasets.
Google Model
This approach was described by Abigail See, et al. from Stanford in their 2017 paper “Get To The Point: Summarization with Pointer-Generator Networks.”
A better name might be the “Stanford Model,” but I am trying to tie this work in with the co-author Peter Liu (of Google Brain) 2016 post titled “Text summarization with TensorFlow” on the Google Research Blog.
In their blog post, Peter Liu, et al. at Google Brain introduce a TensorFlow model that directly applies the Encoder-Decoder model used for machine translation to generating summaries of short sentences for the Gigaword dataset. They claim better than state-of-the-art results for the model, although no formal write-up of the results is presented beyond a text document provided with the code.
In their paper, Abigail See, et al. describe two main shortcomings of the deep learning approaches to abstractive text summarization: they produce factual errors and they repeat themselves.
Though these systems are promising, they exhibit undesirable behavior such as inaccurately reproducing factual details, an inability to deal with out-of-vocabulary (OOV) words, and repeating themselves
Their approach is designed for summarizing multiple sentences rather than single-sentence summarization and is applied to the CNN/Daily Mail dataset used to demonstrate the IBM model. Articles in this dataset are comprised of approximately 39 sentences on average.
A baseline Encoder-Decoder model is used with a word embedding, bidirectional LSTMs for input, and attention. An extension is explored that uses pointing to words in the input data to address out of vocabulary words, similar to the approach used in the IBM model. Finally, a coverage mechanism is used to help reduce repetition in the output.
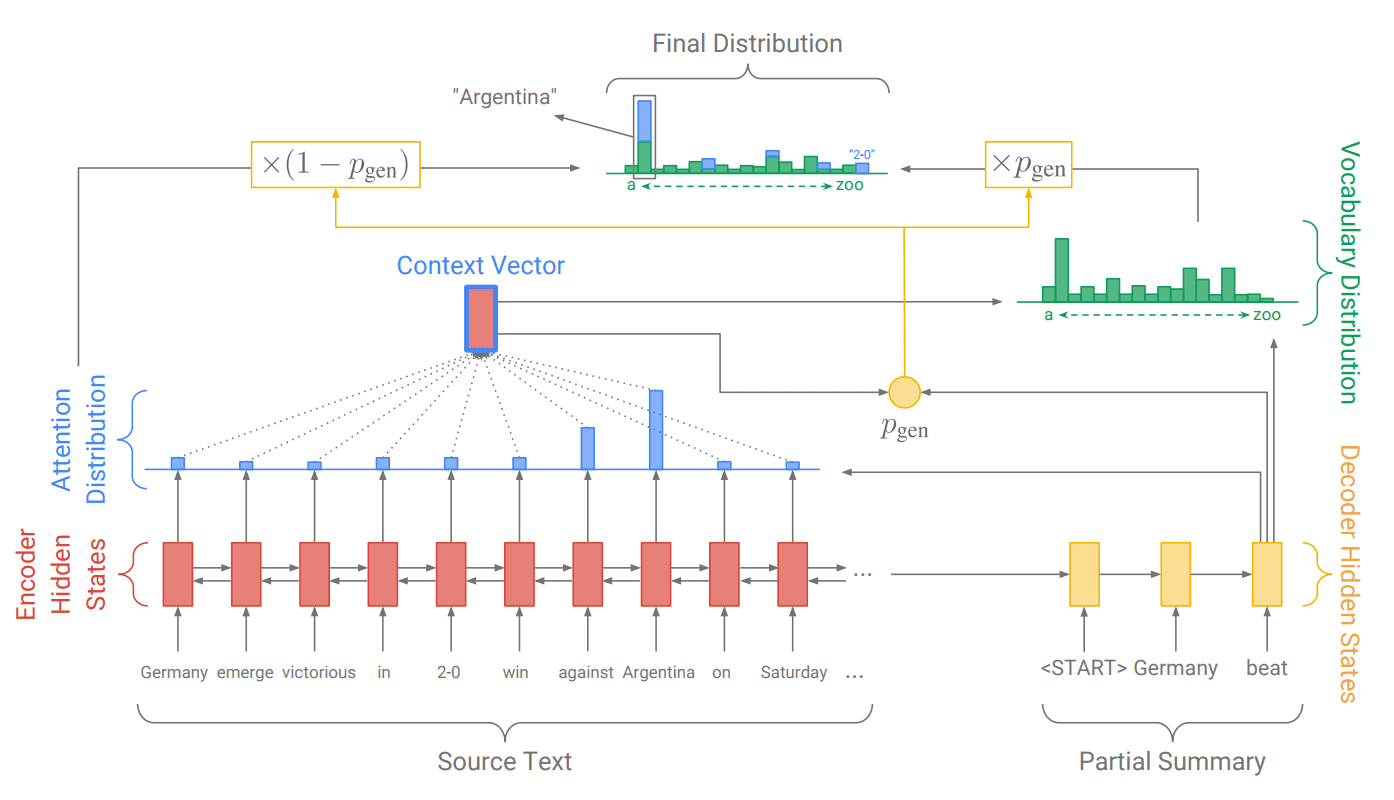
Pointer-generator model for Text Summarization
Taken from “Get To The Point: Summarization with Pointer-Generator Networks.”
Results are reported using ROUGE and METEOR scores, showing state-of-the-art performance compared to other abstractive methods and scores that challenge extractive models.
Our pointer-generator model with coverage improves the ROUGE and METEOR scores further, convincingly surpassing the best [compared] abstractive model …
Results do show that the baseline seq-to-seq model (Encoder-Decoder with attention) can be used but does not produce competitive results, showing the benefit of their extensions to the approach.
We find that both our baseline models perform poorly with respect to ROUGE and METEOR, and in fact the larger vocabulary size (150k) does not seem to help. … Factual details are frequently reproduced incorrectly, often replacing an uncommon (but in-vocabulary) word with a more common alternative.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
- A Neural Attention Model for Abstractive Sentence Summarization (see code), 2015.
- Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond, 2016.
- Get To The Point: Summarization with Pointer-Generator Networks (see code), 2017.
- Text summarization with TensorFlow (see code), 2016
- Taming Recurrent Neural Networks for Better Summarization, 2017.
Summary
In this post, you discovered deep learning models for text summarization.
Specifically, you learned:
- The Facebook AI Research model that uses Encoder-Decoder model with a convolutional neural network encoder.
- The IBM Watson model that uses the Encoder-Decoder model with pointing and hierarchical attention.
- The Stanford / Google model that uses the Encoder-Decoder model with pointing and coverage.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Text Data Today!

Develop Your Own Text models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Natural Language Processing
It provides self-study tutorials on topics like:
Bag-of-Words, Word Embedding, Language Models, Caption Generation, Text Translation and much more...
Finally Bring Deep Learning to your Natural Language Processing Projects
Skip the Academics. Just Results.






It would be better if the pointer network is explained in a bit more of detail.
Thanks for the suggestion, perhaps you could check the papers for more information?
Can you explain about BERT, and how BERT embedding can be used to build such networks instead of word2vec, glove which are fixed embeddings.
Thanks,
Thanks for the suggestion.
can i change the dimension of embedding size in pytorch pretrained bert model from 768 to 300?
if yes, then how?
if not, then is their any other way to do so?
please answer the question because i stuck in my project because of this. Thanx in advance!
Sorry, I don’t have tutorials on pytorch at this stage.
Perhaps try posting your question to stackoverflow?
Hi, please can you make tutorial on the BERT.
Thanks
Thanks for the suggestion.
“Three different decoders are explored:” should be edited to “Three different Encoders are explored:”
Thanks, fixed.