
Word embeddings are a modern approach for representing text in natural language processing.
Word embedding algorithms like word2vec and GloVe are key to the state-of-the-art results achieved by neural network models on natural language processing problems like machine translation.
In this tutorial, you will discover how to train and load word embedding models for natural language processing applications in Python using Gensim.
After completing this tutorial, you will know:
- How to train your own word2vec word embedding model on text data.
- How to visualize a trained word embedding model using Principal Component Analysis.
- How to load pre-trained word2vec and GloVe word embedding models from Google and Stanford.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

How to Develop Word Embeddings in Python with Gensim
Photo by dilettantiquity, some rights reserved.
Tutorial Overview
This tutorial is divided into 6 parts; they are:
- Word Embeddings
- Gensim Library
- Develop Word2Vec Embedding
- Visualize Word Embedding
- Load Google’s Word2Vec Embedding
- Load Stanford’s GloVe Embedding
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Word Embeddings
A word embedding is an approach to provide a dense vector representation of words that capture something about their meaning.
Word embeddings are an improvement over simpler bag-of-word model word encoding schemes like word counts and frequencies that result in large and sparse vectors (mostly 0 values) that describe documents but not the meaning of the words.
Word embeddings work by using an algorithm to train a set of fixed-length dense and continuous-valued vectors based on a large corpus of text. Each word is represented by a point in the embedding space and these points are learned and moved around based on the words that surround the target word.
It is defining a word by the company that it keeps that allows the word embedding to learn something about the meaning of words. The vector space representation of the words provides a projection where words with similar meanings are locally clustered within the space.
The use of word embeddings over other text representations is one of the key methods that has led to breakthrough performance with deep neural networks on problems like machine translation.
In this tutorial, we are going to look at how to use two different word embedding methods called word2vec by researchers at Google and GloVe by researchers at Stanford.
Gensim Python Library
Gensim is an open source Python library for natural language processing, with a focus on topic modeling.
It is billed as:
topic modelling for humans
Gensim was developed and is maintained by the Czech natural language processing researcher Radim Řehůřek and his company RaRe Technologies.
It is not an everything-including-the-kitchen-sink NLP research library (like NLTK); instead, Gensim is a mature, focused, and efficient suite of NLP tools for topic modeling. Most notably for this tutorial, it supports an implementation of the Word2Vec word embedding for learning new word vectors from text.
It also provides tools for loading pre-trained word embeddings in a few formats and for making use and querying a loaded embedding.
We will use the Gensim library in this tutorial.
If you do not have a Python environment setup, you can use this tutorial:
Gensim can be installed easily using pip or easy_install.
For example, you can install Gensim with pip by typing the following on your command line:
|
1 |
pip install --upgrade gensim |
If you need help installing Gensim on your system, you can see the Gensim Installation Instructions.
Develop Word2Vec Embedding
Word2vec is one algorithm for learning a word embedding from a text corpus.
There are two main training algorithms that can be used to learn the embedding from text; they are continuous bag of words (CBOW) and skip grams.
We will not get into the algorithms other than to say that they generally look at a window of words for each target word to provide context and in turn meaning for words. The approach was developed by Tomas Mikolov, formerly at Google and currently at Facebook.
Word2Vec models require a lot of text, e.g. the entire Wikipedia corpus. Nevertheless, we will demonstrate the principles using a small in-memory example of text.
Gensim provides the Word2Vec class for working with a Word2Vec model.
Learning a word embedding from text involves loading and organizing the text into sentences and providing them to the constructor of a new Word2Vec() instance. For example:
|
1 2 |
sentences = ... model = Word2Vec(sentences) |
Specifically, each sentence must be tokenized, meaning divided into words and prepared (e.g. perhaps pre-filtered and perhaps converted to a preferred case).
The sentences could be text loaded into memory, or an iterator that progressively loads text, required for very large text corpora.
There are many parameters on this constructor; a few noteworthy arguments you may wish to configure are:
- size: (default 100) The number of dimensions of the embedding, e.g. the length of the dense vector to represent each token (word).
- window: (default 5) The maximum distance between a target word and words around the target word.
- min_count: (default 5) The minimum count of words to consider when training the model; words with an occurrence less than this count will be ignored.
- workers: (default 3) The number of threads to use while training.
- sg: (default 0 or CBOW) The training algorithm, either CBOW (0) or skip gram (1).
The defaults are often good enough when just getting started. If you have a lot of cores, as most modern computers do, I strongly encourage you to increase workers to match the number of cores (e.g. 8).
After the model is trained, it is accessible via the “wv” attribute. This is the actual word vector model in which queries can be made.
For example, you can print the learned vocabulary of tokens (words) as follows:
|
1 2 |
words = list(model.wv.vocab) print(words) |
You can review the embedded vector for a specific token as follows:
|
1 |
print(model['word']) |
Finally, a trained model can then be saved to file by calling the save_word2vec_format() function on the word vector model.
By default, the model is saved in a binary format to save space. For example:
|
1 |
model.wv.save_word2vec_format('model.bin') |
When getting started, you can save the learned model in ASCII format and review the contents.
You can do this by setting binary=False when calling the save_word2vec_format() function, for example:
|
1 |
model.wv.save_word2vec_format('model.txt', binary=False) |
The saved model can then be loaded again by calling the Word2Vec.load() function. For example:
|
1 |
model = Word2Vec.load('model.bin') |
We can tie all of this together with a worked example.
Rather than loading a large text document or corpus from file, we will work with a small, in-memory list of pre-tokenized sentences. The model is trained and the minimum count for words is set to 1 so that no words are ignored.
After the model is learned, we summarize, print the vocabulary, then print a single vector for the word ‘sentence‘.
Finally, the model is saved to a file in binary format, loaded, and then summarized.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from gensim.models import Word2Vec # define training data sentences = [['this', 'is', 'the', 'first', 'sentence', 'for', 'word2vec'], ['this', 'is', 'the', 'second', 'sentence'], ['yet', 'another', 'sentence'], ['one', 'more', 'sentence'], ['and', 'the', 'final', 'sentence']] # train model model = Word2Vec(sentences, min_count=1) # summarize the loaded model print(model) # summarize vocabulary words = list(model.wv.vocab) print(words) # access vector for one word print(model['sentence']) # save model model.save('model.bin') # load model new_model = Word2Vec.load('model.bin') print(new_model) |
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the following output.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
Word2Vec(vocab=14, size=100, alpha=0.025) ['second', 'sentence', 'and', 'this', 'final', 'word2vec', 'for', 'another', 'one', 'first', 'more', 'the', 'yet', 'is'] [ -4.61881841e-03 -4.88735968e-03 -3.19508743e-03 4.08568839e-03 -3.38211656e-03 1.93076557e-03 3.90265253e-03 -1.04349572e-03 4.14286414e-03 1.55219622e-03 3.85653134e-03 2.22428422e-03 -3.52565176e-03 2.82056746e-03 -2.11121864e-03 -1.38054823e-03 -1.12888147e-03 -2.87318649e-03 -7.99703528e-04 3.67874932e-03 2.68940022e-03 6.31021452e-04 -4.36326629e-03 2.38655557e-04 -1.94210222e-03 4.87691024e-03 -4.04118607e-03 -3.17813386e-03 4.94802603e-03 3.43150692e-03 -1.44031656e-03 4.25637932e-03 -1.15106850e-04 -3.73274647e-03 2.50349124e-03 4.28692997e-03 -3.57313151e-03 -7.24728088e-05 -3.46099050e-03 -3.39612062e-03 3.54845310e-03 1.56780297e-03 4.58260969e-04 2.52689526e-04 3.06256465e-03 2.37558200e-03 4.06933809e-03 2.94650183e-03 -2.96231941e-03 -4.47433954e-03 2.89590308e-03 -2.16034567e-03 -2.58548348e-03 -2.06163677e-04 1.72605237e-03 -2.27384618e-04 -3.70194600e-03 2.11557443e-03 2.03793868e-03 3.09839356e-03 -4.71800892e-03 2.32995977e-03 -6.70911541e-05 1.39375112e-03 -3.84263694e-03 -1.03898917e-03 4.13251948e-03 1.06330717e-03 1.38514000e-03 -1.18144893e-03 -2.60811858e-03 1.54952740e-03 2.49916781e-03 -1.95435272e-03 8.86975031e-05 1.89820060e-03 -3.41996481e-03 -4.08187555e-03 5.88635216e-04 4.13103355e-03 -3.25899688e-03 1.02130906e-03 -3.61028523e-03 4.17646067e-03 4.65870230e-03 3.64110398e-04 4.95479070e-03 -1.29743712e-03 -5.03367570e-04 -2.52546836e-03 3.31060472e-03 -3.12870182e-03 -1.14580349e-03 -4.34387522e-03 -4.62882593e-03 3.19007039e-03 2.88707414e-03 1.62976081e-04 -6.05802808e-04 -1.06368808e-03] Word2Vec(vocab=14, size=100, alpha=0.025) |
You can see that with a little work to prepare your text document, you can create your own word embedding very easily with Gensim.
Visualize Word Embedding
After you learn word embedding for your text data, it can be nice to explore it with visualization.
You can use classical projection methods to reduce the high-dimensional word vectors to two-dimensional plots and plot them on a graph.
The visualizations can provide a qualitative diagnostic for your learned model.
We can retrieve all of the vectors from a trained model as follows:
|
1 |
X = model[model.wv.vocab] |
We can then train a projection method on the vectors, such as those methods offered in scikit-learn, then use matplotlib to plot the projection as a scatter plot.
Let’s look at an example with Principal Component Analysis or PCA.
Plot Word Vectors Using PCA
We can create a 2-dimensional PCA model of the word vectors using the scikit-learn PCA class as follows.
|
1 2 |
pca = PCA(n_components=2) result = pca.fit_transform(X) |
The resulting projection can be plotted using matplotlib as follows, pulling out the two dimensions as x and y coordinates.
|
1 |
pyplot.scatter(result[:, 0], result[:, 1]) |
We can go one step further and annotate the points on the graph with the words themselves. A crude version without any nice offsets looks as follows.
|
1 2 3 |
words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1])) |
Putting this all together with the model from the previous section, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from gensim.models import Word2Vec from sklearn.decomposition import PCA from matplotlib import pyplot # define training data sentences = [['this', 'is', 'the', 'first', 'sentence', 'for', 'word2vec'], ['this', 'is', 'the', 'second', 'sentence'], ['yet', 'another', 'sentence'], ['one', 'more', 'sentence'], ['and', 'the', 'final', 'sentence']] # train model model = Word2Vec(sentences, min_count=1) # fit a 2d PCA model to the vectors X = model[model.wv.vocab] pca = PCA(n_components=2) result = pca.fit_transform(X) # create a scatter plot of the projection pyplot.scatter(result[:, 0], result[:, 1]) words = list(model.wv.vocab) for i, word in enumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1])) pyplot.show() |
Running the example creates a scatter plot with the dots annotated with the words.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
It is hard to pull much meaning out of the graph given such a tiny corpus was used to fit the model.
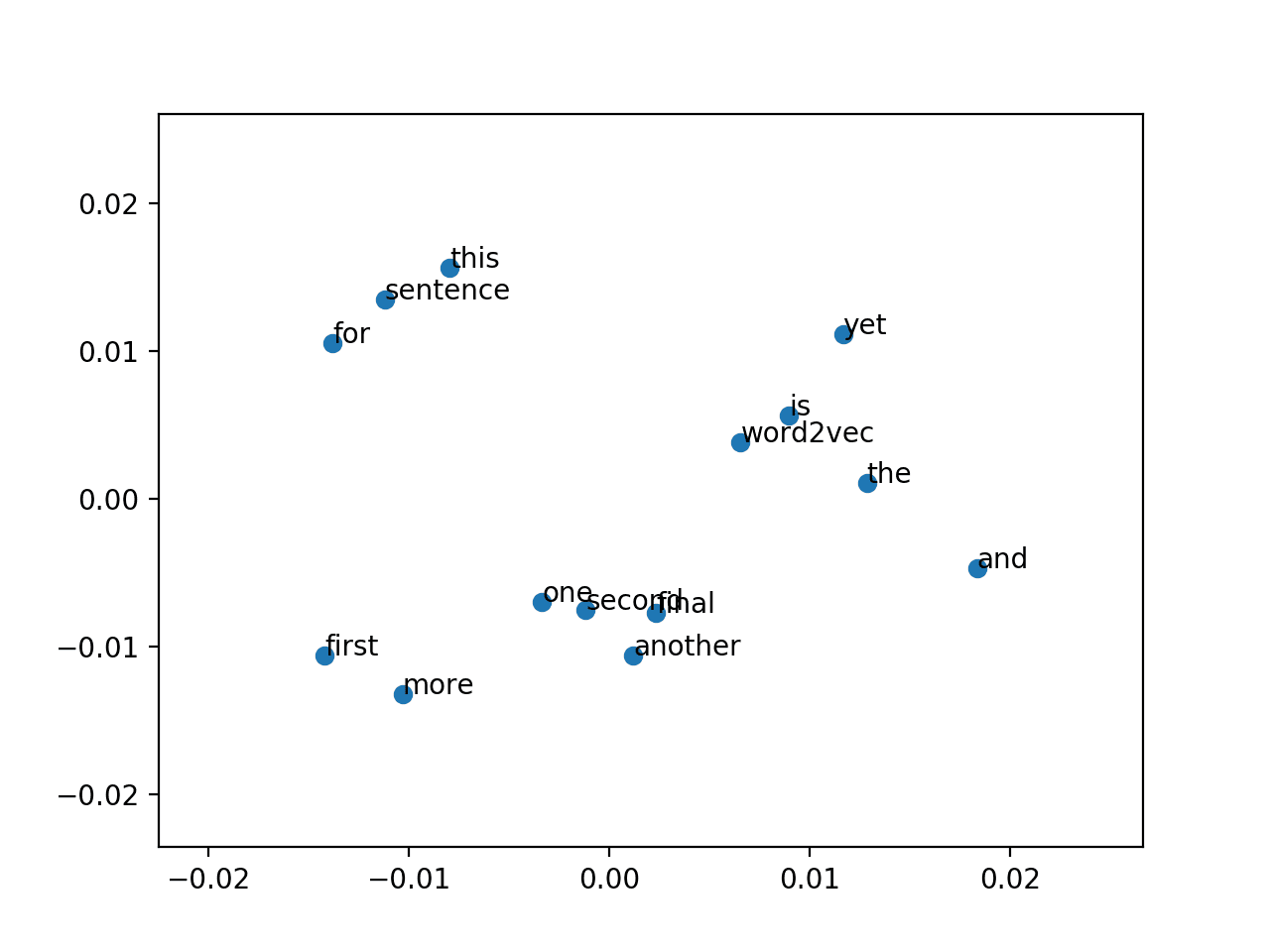
Scatter Plot of PCA Projection of Word2Vec Model
Load Google’s Word2Vec Embedding
Training your own word vectors may be the best approach for a given NLP problem.
But it can take a long time, a fast computer with a lot of RAM and disk space, and perhaps some expertise in finessing the input data and training algorithm.
An alternative is to simply use an existing pre-trained word embedding.
Along with the paper and code for word2vec, Google also published a pre-trained word2vec model on the Word2Vec Google Code Project.
A pre-trained model is nothing more than a file containing tokens and their associated word vectors. The pre-trained Google word2vec model was trained on Google news data (about 100 billion words); it contains 3 million words and phrases and was fit using 300-dimensional word vectors.
It is a 1.53 Gigabytes file. You can download it from here:
Unzipped, the binary file (GoogleNews-vectors-negative300.bin) is 3.4 Gigabytes.
The Gensim library provides tools to load this file. Specifically, you can call the KeyedVectors.load_word2vec_format() function to load this model into memory, for example:
|
1 2 3 |
from gensim.models import KeyedVectors filename = 'GoogleNews-vectors-negative300.bin' model = KeyedVectors.load_word2vec_format(filename, binary=True) |
On my modern workstation, it takes about 43 seconds to load.
Another interesting thing that you can do is do a little linear algebra arithmetic with words.
For example, a popular example described in lectures and introduction papers is:
|
1 |
queen = (king - man) + woman |
That is the word queen is the closest word given the subtraction of the notion of man from king and adding the word woman. The “man-ness” in king is replaced with “woman-ness” to give us queen. A very cool concept.
Gensim provides an interface for performing these types of operations in the most_similar() function on the trained or loaded model.
For example:
|
1 2 |
result = model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) print(result) |
We can put all of this together as follows.
|
1 2 3 4 5 6 7 |
from gensim.models import KeyedVectors # load the google word2vec model filename = 'GoogleNews-vectors-negative300.bin' model = KeyedVectors.load_word2vec_format(filename, binary=True) # calculate: (king - man) + woman = ? result = model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) print(result) |
Running the example loads the Google pre-trained word2vec model and then calculates the (king – man) + woman = ? operation on the word vectors for those words.
The answer, as we would expect, is queen.
|
1 |
[('queen', 0.7118192315101624)] |
See some of the posts in the further reading section for more interesting arithmetic examples that you can explore.
Load Stanford’s GloVe Embedding
Stanford researchers also have their own word embedding algorithm like word2vec called Global Vectors for Word Representation, or GloVe for short.
I won’t get into the details of the differences between word2vec and GloVe here, but generally, NLP practitioners seem to prefer GloVe at the moment based on results.
Like word2vec, the GloVe researchers also provide pre-trained word vectors, in this case, a great selection to choose from.
You can download the GloVe pre-trained word vectors and load them easily with gensim.
The first step is to convert the GloVe file format to the word2vec file format. The only difference is the addition of a small header line. This can be done by calling the glove2word2vec() function. For example:
|
1 2 3 4 |
from gensim.scripts.glove2word2vec import glove2word2vec glove_input_file = 'glove.txt' word2vec_output_file = 'word2vec.txt' glove2word2vec(glove_input_file, word2vec_output_file) |
Once converted, the file can be loaded just like word2vec file above.
Let’s make this concrete with an example.
You can download the smallest GloVe pre-trained model from the GloVe website. It an 822 Megabyte zip file with 4 different models (50, 100, 200 and 300-dimensional vectors) trained on Wikipedia data with 6 billion tokens and a 400,000 word vocabulary.
The direct download link is here:
Working with the 100-dimensional version of the model, we can convert the file to word2vec format as follows:
|
1 2 3 4 |
from gensim.scripts.glove2word2vec import glove2word2vec glove_input_file = 'glove.6B.100d.txt' word2vec_output_file = 'glove.6B.100d.txt.word2vec' glove2word2vec(glove_input_file, word2vec_output_file) |
You now have a copy of the GloVe model in word2vec format with the filename glove.6B.100d.txt.word2vec.
Now we can load it and perform the same (king – man) + woman = ? test as in the previous section. The complete code listing is provided below. Note that the converted file is ASCII format, not binary, so we set binary=False when loading.
|
1 2 3 4 5 6 7 |
from gensim.models import KeyedVectors # load the Stanford GloVe model filename = 'glove.6B.100d.txt.word2vec' model = KeyedVectors.load_word2vec_format(filename, binary=False) # calculate: (king - man) + woman = ? result = model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) print(result) |
Running the example prints the same result of ‘queen’.
|
1 |
[('queen', 0.7698540687561035)] |
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Gensim
- gensim Python Library
- models.word2vec gensim API
- models.keyedvectors gensim API
- scripts.glove2word2vec gensim API
Posts
- Messing Around With Word2vec, 2016
- Vector Space Models for the Digital Humanities, 2015
- Gensim Word2vec Tutorial, 2014
Summary
In this tutorial, you discovered how to develop and load word embedding layers in Python using Gensim.
Specifically, you learned:
- How to train your own word2vec word embedding model on text data.
- How to visualize a trained word embedding model using Principal Component Analysis.
- How to load pre-trained word2vec and GloVe word embedding models from Google and Stanford.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning models for Text Data Today!

Develop Your Own Text models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Natural Language Processing
It provides self-study tutorials on topics like:
Bag-of-Words, Word Embedding, Language Models, Caption Generation, Text Translation and much more...
Finally Bring Deep Learning to your Natural Language Processing Projects
Skip the Academics. Just Results.






thank you for your wonderful tutorial, please sir can I download the pdf of these tutorials
regards
Try some web2pdf plug-ins.
Do you have an example?
I will release a book on this topic soon.
Hi Jason,
I started reading your website for my learning. It is written in a level such that any beginner like me can easily can understand these topics. Thanks and appreciate your sincere effort on this.
I would like to ask you for a help or suggestion,
I need to write an algorithm that converts or extracts the text into conditions, arguements and actions :
For Example:
Input to the algorithm : “If A is greater than 100 then set B as 200”
Output from the algorithm:
INPUT_VAR1 CONDITION INPUT1_VALUE1 ACTION OUTPUT_VAR1 OUTPUT1_VALUE1
—————————————————————————————————————–
A > 100 SET B 200
Basically what i am looking is how to intrepret the text and extract the actions, input and output told in the text.
Sounds like a fun project.
Perhaps an Encoder-Decoder LSTM would be appropriate.
You can get started with LSTMs here:
https://machinelearningmastery.com/start-here/#lstm
You can get started with deep learning for NLP here:
https://machinelearningmastery.com/start-here/#nlp
Ran the example, however not sure what the 25 by 4 Vector represents or how the plot should be read.
The vectors are the learned representation for the words.
The plot may provide insight to the “natural” grouping of the words, perhaps it would be more clear with a larger dataset.
Thank you, Jason. Very clear, interest and igniting.
Thanks Alexander.
Thanks for great tutorial
I’ve question. ‘GoogleNews-vectors-negative300.bin.gz’ implemented by which algorithm skip-gram or CBOW?
I’m not sure Rose, I’m sure the details are on the w2v page:
https://code.google.com/archive/p/word2vec/
Very structured and even for a beginner to follow. Thanks a lot. I highly appreciate your work!
Thanks.
Hi Jason,
Thanks for your detail explanation !
For the “Scatter Plot of PCA Projection of Word2Vec Model” image, I had different result comparing with yours. I am not sure if there is any wrong with my code. Actually, I copied code from yours.
This is mine
http://prntscr.com/gvg5jz
Could you please take a look and give your comment ?
Thanks a lot !
The algorithm is stochastic:
https://machinelearningmastery.com/randomness-in-machine-learning/
Thanks a lot, Jason !
Great tutorial, thank you a lot! A question, is there similar to GloVe embeddings but based on other languages then English?
There may be, I am not aware of them, sorry.
You can train your own vector in minutes – it is a very fast algorithm.
Thanks for the simple explanation 🙂
I’m glad it helped.
hi,
I am trying to combine my own corpus with the above Glove embeddings. I haven’t really found a solution/example where I can leverage the GloVe 6b for the known embeddings and then ‘extend’ or train on my own Out of Vocab tokens (These tend to be non language words or machine generated).
Any help is appreciated.
Thanks
Hi Rob, one way would be to load the embeddings into an Embedding layer and tune them with your data while fitting the network.
Perhaps Gensim lets you update existing vectors, but I have not seen or tried to do that, sorry.
@Rob Hamilton-Smith, I’m working on a similar problem that I encountered,Can you help me with it if you had found a solution
Thanks
Thanks for the great tutorial (as usual). Are you going to make a post about word embeddings for complete documents using doc2vec and/or Fasttext?
I am particularly interested in using pre-trained word embeddings to represent documents (~500 words). This allows leveraging from huge corpuses. However, it’s well known that simple averaging is only as good (or even worse) than classic BOW in classification tasks. Apparently you could do better by first PCA-transforming word2vec dictionary (paper “In Defense of Word Embedding for Generic Text Representation”), but so far I haven’t seen anyone else using that trick…
I hope to cover Fasttext in the future.
When model skill is the goal, I recommend testing every trick you can find! Let me know how you go.
This tutorial helped me a lot !!
Thank you very much!
Thanks Guy, I’m glad to hear that.
Another excellent article. I have been struggling for a long time to get a knack of word2vec & this helped me a lot.
I’m glad to hear that!
Dear Sir,
1) I have an 8GB RAM and i5 processor system. How long should it take for the google news corpus to be trained using the model?
2) In the demo example you described, your dataset used was in the form you inputted on your own. If I want to train the model using any corpus, how do I process the corpus? Like the Brown corpus?
Or if I have any arbitrary corpus, how do I process it so as to feed the corpus to the word2vec model in a suitable form for processing?
I don’t know how long it takes to train on the google corpus sorry, perhaps ask the google researchers?
You should be able to load the learned google word vector in a minute, given sufficient resources.
To learn your own corpus, tokenize the text the way you need for your application and use the Gensim code above.
hats off to Jason for clear and pricise explanation of a very complicated topic
Thanks!
Hey Jason,
How do I incorporate ngrams into my vocabulary. Does gensim provide a function to do so ?
You can extract them from your dataset manually with a line or two of Python.
There may be tools in Gensim for this, I’m not aware of them though.
Thank you so much for such detailed explaination
You’re welcome.
Hi Jason, Could you give some idea about language modelling for Question , answer based model, Thanks in advance..
Thanks for the suggestion, I hope to cover it in the future.
I have small question , te glove based word to vector don’t provide model.score functionaloty
Correct.
how to convert a sentence into vector by using word2vec (google pre-trained).
Each word is converted int a vector.
Hello my name is Yazid a just wana know how to update googleNews model with new words
Best Regard
You could train vectors with your new works and take the union of the vectors for the words that interest you.
Thank you, such a great explanation.
Jason, a quick question please:
Suppose we are pretraining embeddings ourselves (without glove/google).
Which of the following would be better?
1) pretrain using gensim, and feed into the keras embedding layer, trainable=False.
2) train as part of the neural network in embedding layer?
Kindly advise.
These would be pre-trained word embeddings.
Sorry to tell, but gensim embedding pretraining proved to be actually worse. (In case of a dataset of 1.5 M small texts.)
So, those randomly initialized weights in case of Embedding layer as part of a NN show much better results.
My justification would be:
– It makes sense to use pretrained word embeddings only if using GloVe/Google or such.
– It makes sense to use pre-trained word embeddings only on dataset with relatively big texts. (i.e. not on tweets or small messages)
What would be your opinion please?
Cheers!
Nice. Sounds reasonable.
Very nice tutorial. Could you please let me know if there is a way of getting the sentences that were used in training a model? I have a doc2vec model M and I tried to fetch the list of sentences with M.documents, like one would use M.vector_size to get the size of the vectors.
Also, having a doc2vec model and wanting to infer new vectors, is there a way to use tagged sentences? I see on gensim page it says:
infer_vector(doc_words, alpha=0.1, min_alpha=0.0001, steps=5)¶
Infer a vector for given post-bulk training document.
Document should be a list of (word) tokens.
But I would like to use tagged sentences. Thank you very much!
I’m not sure I follow, sorry.
You will have the training data for the model that you can access directly?
I downloaded a doc2vec model trained on a wikipedia dump. I was wondering if the model stores the sentences too and if yes, how can I access them. Thank you very much.
Perhaps ask the person you downloaded it from?
How to generate word embeddings for a complete review sentence? I mean in word2vec we will get 300dim vector for each word.
Other than computing the average of vectors of all words in a sentence, any good technique to achieve good representation of vector for sentence.
I believe there are methods for this. Sorry, I don’t have examples at this stage.
Hi Jason,
Since past few days i had been facing issue regarding word embedding using word2vec and glove.
I went through alot of post, but its messy.
Yesterday i came across this post, and wow! it helped me alot!
I also came to know that you have a book “Deep Learning for Natural Language Processing”.Looks great!
I am interested to purchase it!
But i wanted to connect to you directly to understand whether this book fits my requirement.
Tasks that I work on like Word2Vec, Doc2Vec, mapping one document to another using embedding for recommendation,etc
I just need fundamental understanding so that i can take the next step and create by my own idea/analysis.
The book covers word2vec models and how to use them in deep learning. It does not cover doc2vec.
I always refer to your site when ever i start new topic.
Thank You
Thanks.
Can I build that model by Indonesian language?
Sure.
Nice post. Very easy to understand and very informative.
Thanks.
I have questions regards similarity. If I apply w2vec to convert words to vectors. How I can find similarities between words.
I know I can use most. Similar() function to find similarity for specific word but How I can achieve that among all words in documents.
Perhaps iterate over all words and calculate similarity manually to all other words in the vocab (e.g. write two for-loops).
Why wold you want this?
One more questions.
Can I apply w2vec to convert unigrams and bigrams to vectors ?
It might be easier to learn a bigram model and a unigram model separately, and if still needed, learn a mapping between them (e.g. a model).
Thanks Jason for amazing blog!
Do you know any paper or implementation of the bigram embedding?
Not offhand, sorry.
Thanks for replying!
No problem.
Hello, Jason i have a question about the selection of dimensions of word vectors.let say 300-dimensions they will be same for all words? On which criteria we select these dimensions?
Yes, all words will have the same dimensionality.
Hi,
it might be silly question but the sentences you pass to Word2Vec to train on ,they consist of all the sentences (i.e. train,validate as well as test) right?
Also when you create an embedding matrix/dictionary for your sentences,it should also contain the words of test sentences?
Thirdly when evaluating the model,test sentences would also be converted to sequences or integers?
Thanks
Yes, sentences are split, then encoded for use in modeling.
The training dataset should be representative of the broader domain. This applies generally, not just in NLP.
Thank you for this nice tutorial. is there a way to revert the word embedding transformation ? I am feeding the embedded matrix ‘ X = model[model.wv.vocab]’ to an autoencoder model. I will get also as result a matrix. I want to interpret that matrix by applying the inverse word2vec transformation so I can compare the input to the output results. Any ideas ?
Sure, you could search for the closest one or set of vectors for a given vector.
Thank you for the reply. But can you explain more.
Did you mean something like this :
for i in range(len(X)):
inverted.append([argmax(decoded_tags[i, :])])
You can use a distance measure like euclidean distance or dot product to find the closest vectors.
Can you provide an example please ? or a link that can help me do that
I’m eager to help, but I don’t have the capacity to write custom code for you, I explain more here:
https://machinelearningmastery.com/faq/single-faq/can-you-change-the-code-in-the-tutorial-to-___
Hi Jason,
the tutorial was awesome as the others, but tell you the truth when I applied your commands :
model = Word2Vec(sentences, min_count=1)
words = list(model.wv.vocab)
print(words)
it works fine when I use your dataset, but when I apply my own dataset which structure is such as this: a folder which name is diseases, in this folder I have 2 sub-folder which are blood cancer and breast cancer. in each subfolder such as blood cancer, there are many txt files which include at least 20 sentences, unfortunately when I apply your commands model = Word2Vec(vocab_dic, size=100, window=5, workers=8, min_count=1) and words = list(model.wv.vocab)
print (‘words’ , words)
the printed words are as follows: words [‘b’, ‘t’, ‘f’, ‘r’, ‘u’, ‘l’, ‘y’, ‘w’, ‘m’, ‘d’, ‘p’, ‘g’, ‘j’, ‘v’, ‘k’, ‘s’, ‘e’, ‘q’, ‘c’, ‘x’, ‘h’, ‘i’, ‘n’, ‘z’, ‘a’, ‘o’]
whereas I expect to have words instead of charachters.
I know you do not have the capacity to write custom code for me or check everyone’s commands but please look at my few commands to find out the problem as I am a beginner ans I have already tried to find it but I could not.
I use keras in ubuntu 17.10 to write commnads
breast= glob.glob(‘/home/mary/.config/spyder-py3/BinaryClassClassification/breastcancer/*.txt’)
blood=glob.glob(‘/home/mary/.config/spyder-py3/BinaryClassClassification/bloodcancer/*.txt’)
breast_samples_text = [load_file(file) for file in breast]
bloodـsamples_text= [load_file(file) for file in blood]
vocab_dic = breast_samples_text + blood_samples_text
model = Word2Vec(vocab_dic, size=100, window=5, workers=8, min_count=1)
words = list(model.wv.vocab)
printed words are as these: words [‘b’, ‘t’, ‘f’, ‘r’, ‘u’, ‘l’, ‘y’, ‘w’, ‘m’, ‘d’, ‘p’, ‘g’, ‘j’, ‘v’, ‘k’, ‘s’, ‘e’, ‘q’, ‘c’, ‘x’, ‘h’, ‘i’, ‘n’, ‘z’, ‘a’, ‘o’]
waiting for your answer as I need it necessarily.
Best Regards
Maryam
I believe your data is in a different format. Perhaps focus on data loading and confirm the data in memory has the same structure as the data in the tutorial first?
import re
from nltk.tokenize import TweetTokenizer, sent_tokenize
tokenizer_words = TweetTokenizer()
tokens_sentences = [tokenizer_words.tokenize(t) for t in
nltk.sent_tokenize(text)]
Use this piece of code and you’ll get the output you wanted. I had the same issue as you
Hi Jason,
I have modified it with this command and gave me a correct output::[
def load_file(file_name):
cleaned_txt = re.sub(“[^a-zA-Z]+”, ” “, open(file_name, ‘r’, encoding=”utf8”).read()).lower()
return cleaned_txt
def gen_vocab_dic(all_text):
voc = set()
for record in all_text:
for word in record.split():
voc.add(word)
voc_dic = {}
index = 1 # we start from 1
for i in voc:
voc_dic[i] = index
index = index + 1
return voc_dic,voc
breast= glob.glob(‘/home/mary/.config/spyder-py3/Dataset#2_BinaryClassClassification breasrcancer_disease/*.txt’)
bloodcancer=glob.glob(‘/home/mary/.config/spyder-py3/Dataset#2_BinaryClassClassification/bloodcancer_disease/*.txt’)
breast_samples_text = [load_file(file) for file in breast]
bloodـsamples_text= [load_file(file) for file in blood]
vocab_dic = gen_vocab_dic(breast_samples_text + bloodـsamples_text)
model = Word2Vec(vocab_dic, size=100, window=5, workers=8, min_count=1)
words_list = list(model.wv.vocab)
print (‘words_list’ , words_list)== ‘subcategory’, ‘disproportionally’, ‘alen’ and etc.
but I do not know how i can refer the label of each class to each word? in other words How to tag any sample which belongs to each class?
I have already provided x_train or x_ test but I do not know how I should provide y_dataset ??
Jason, please help me with this kind of dataset as I have never seen a tutorial to teach word2vec for this kind of structure for a dataset. the structure of my dataset is as follows: a folder which name is diseases, in this folder I have 2 sub-folder which are blood cancer and breast cancer. in each subfolder such as blood cancer, there are many txt files which include at least 20 sentences, as I mentioned in the latter post.
waiting for the reply as I need it and sorry to ask you the request.
Best
Maryam
Sorry, I don’t know about your prediction problem. Perhaps you could summarize it for me?
How do you decide how many negative words to use? which is the criteria?
What do you mean exactly?
Hi Jason,
thank you for offering us one of the best tutorials about word2vec. but I think there is a limitation in your tutorial as follows:
when you create a model via word2vec such this:
model = Word2Vec(sentences, size=100, window=5, workers=8, min_count=1)
you should have explained how we are able to apply vectors of words after embedding them by word2vec model. for example, when we use embedding keras layer,
z = Embedding(vocab_dic_size, 100, input_length=seq_length, name=”embedding”)
we can apply in this way. but I do not know how i can use the model which you created by word2vec in order to embed words and giving them weights??
sorry I got confused so if you write an instance about using the model = Word2Vec( ) like the example I wrote above by keras embedding layer, It will be a great guidance as I have already searched about it but I did not understand.
I am sorry to write a big comment such as this but plz consider that I a beginner and found your tutorial as the best one in clearness.
I show how to fit the model ten make predictions with the in this tutorial:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
Hi. I am a newbie in data science & going through your post I think you are the best person who can guide me for my project. I want to create a dictionary that incorporates all the words related to gold-market for which I am collecting text of 1000 articles on gold-news.
Can word2vec be used for this situation as simple word tokenization won’t help.
Perhaps you can extract all words from all articles, then see which are the 1000 most frequently used across all articles?
Hi Jason,
I love your articles. I built the following comparison for different document representations. Your feedback will be appreciated.
https://github.com/ahmed-mohamed-sn/DocumentRepresentations
I don’t have the capacity to review and debug your code sorry.
Hey,
The article is a great help. Thanks.
I require to train a RNN for classification of Name, Address, Age, DOB etc. from raw OCR output of an identity card. I want the classifier to be generic and work on most kind of id’s.
As names, address etc. won’t be available in a pre-trained model, I decided to train my own word embedding. I have around 50 variants of ID cards and will be generating training data from those by altering details in it.
I find out someone did similar –
“We hash the text of the word into a binary vector of size 2^18 which is embedded in a trainable 500 dimensional distributed representation using an embedding layer”
So I understand the “Word Hashing” part, but how they embedded those binary feature vectors in a 500 dims., I mean how will your convert those 2^18 dims. features to 500 dims.
Your help would be really appreciated. Please suggest some other alternative if you have.
Perhaps this intro on word embeddings will help:
https://machinelearningmastery.com/what-are-word-embeddings/
I have got caught up in a really results of gensim Word2Vec. I have formatted the question and asked here: https://stackoverflow.com/questions/51233632/word2vec-gensim-multiple-languagess . would it be possible to train gensim on multiple languages and still get the right similarity result? My Result says no.
Also I want to ask that the random weights when we train Word2Vec from gensim, do they remain same or they change every time we train the model ?
I don’t know about cross-language models. Sounds like deeper thought is required.
Weight are learned via training on the provided dataset.
what is the “alpha” in those code?
tell me more about that.
“alpha” is initialized “0.025” . what is the use of that ?
I am building a domain-specific word2vec model using more or less the same steps. Given a word, I know what the similar words should be. I also don’t have a dataset. What I am doing is trying to overfit the model based on very small variations. When I plot thegraph, I see that the words I need are grouped together. For eg, words a,b and c are grouped together in a single cluster. So I assume when I input a, I should get b and c as the similar words. However, words farther away from the cluster in question have a better score and are displayed first. How can I change this behaviour? Any help is appreciated. Thanks
The model has parameters, try tuning them and see if they have a desired effect?
Perhaps you need new/different training data?
Perhaps your assumptions or scoring have flaws?
Hi Jason,
Thank you for your awesome tutorials.
I have a question about dimensions of vectors. Can we visualize the dimensions. Kindly guide me.
What do you mean exactly? All vector have the same dimensions.
If you mean visualize the word vectors, the above tutorial shows you how.
Hi,
word2vec or Glove algorithm its usefull for non-english word/language (i.e.Russian)
Yes, as long as you have the data to train it.
I am trying to built a “text classifier” where I am trying to categorize it into two classes. I have created the model using word2vec but how can I use the model to predict the other data.
Other models like SVM, logistic regression have “predict” to do the work but word2vec doesn’t have it.
Any way that we can use word2vec along with SVM to use it?
The word2vec vectors can be used as an input to any model, including an SVM. I don’t have a worked example, sorry.
Hi Jason,
Would Word2Vec provide us with a vector if a new word out of corpus is given as input to the model trained with a set of corpus.
Thanks
No, new words cannot be mapped.
Can we give input as word vectors created by word2Vec algorithm to LDA modal training ?
Let me know.
Thank you in advance !!!
Maybe, I don’t know sorry.
How to prepare input for large corpus? I have a csv file with 50k arcticles (each row with an article). As mentioned in https://rare-technologies.com/word2vec-tutorial/ , Keeping the input as a Python built-in list is convenient, but can use up a lot of RAM when the input is large.
Perhaps load articles into memory progressively in order to prepare them, instead of all at once.
Is it possible to define my own loss function?
In Gensim? Perhaps. I would recommend checking the API documentation.
Mr. Jason I am working on a Project that does sentiment analysis on the social media platforms and helps in the detection of cyberbullying, can u tell me if I need to train my own word vectors or the GLoVe pre-trained word Vector on twitter tweets will do?
I recommend try both approaches and see what works best for your specific dataset.
Tthank you very much for your explanation.
I have a question please. Once we got the model how can we extract the vectors of a list of words?
I show in the above tutorial how to extract vectors for words.
Hey,
i want to have word embedding for a tagged corpus which is not in English but an Indian language. how to do that using gensim?
Sorry, I cannot help you with this.
nice post man. I do have a question can we check a whole new document for a word such as “java” with the trained word2vec model?
I don’t understand sorry, can you elaborate?
Hi Mr Jason,I’m working on the project sentiment analysis (categorization of aspects and their polarities in comments) and i use deep learning and skip-gram model of word embedding can you help me, i need some tutorials for these approaches .
Does the above tutorial help?
What problem are you having exactly?
Hey Jason,
I am having this code :
I am getting data in this format
I want to apply word2vec on data coming in filename only .
how can i do that?
Sounds like a simple programming question, rather than an ML question?
Perhaps post your code and error to stackoverflow?
hi Jason, thanks for your tutorial.
Very well explained.
I just wanna ask you one thing about my use-case.
I have a corpus of 1.8k sentences, with a vocabulary of 2k words.
Do you think are enough to train my own custom embedding with Gensim, or it’s better to use a pre-trained model?
because i’ve trained it (with gensim Fast-text), passing then the weights in thekeras embedding layer (trainable=True) with a Conv1D layer.
I got very good results.
Is it possible despite i have a small corpus? because usually these embedding are trained on very large vocabulary.
Thanks in advance for your answer
Perhaps try it and compare results to using a Keras learned embedding?
Fast-text pre-trained embedding –> 89 % of accuracy
Fast-text learning embedding with my own corpus with gensim train –> 93 % accuracy
it seems despite my corpus it’s not enough big, learning an embedding from scratch lead to better results.
So thanks, i discovered that Fast-text using n-gram gives better results also with small vocabulary.
Nice finding, thanks for sharing.
result = model.most_similar(positive=[‘man’,’woman’], negative=[‘beer’], topn=1)
print(result)
[(‘victim’, 0.7144894003868103)]
really?? 🙂
That is surprising (if it was a real result)!
Remember the model and in turn the results are only as good or bad as the data used to train it.
Hello,
The post is very informative which i used to develop a model in python using keras. Later i want to use this model in java. I know how to load the model in java,but stuck with loading glove pretrained wordvector. The code is used in python is the same as mentioned above:
from gensim.scripts.glove2word2vec import glove2word2vec
glove_input_file = ‘glove.840B.300d.txt’
word2vec_output_file = ‘glove.word2vec’
glove2word2vec(glove_input_file, word2vec_output_file)
from gensim.models import KeyedVectors
glove_w2vec = KeyedVectors.load_word2vec_format(‘glove.word2vec’, binary=False)
I want to reproduce the same in java as well. I tried using dl4j how to start page. But i keep getting errors such as 1. no jnind4jcpu in java.library.path 2.no jnind4jcpu in java.library.path . I am not able to find solution anywhere.It would be very useful if you could help me with this if possible.
Perhaps load it in python then save it in a format that is easier for you to read in Java?
how i calculate the “average” word in sentence by using Word2Vec that is already trained model
Retrieve the vector for each word and calculate their average.
Hi,
I see that this post was posted on October 6, 2017.
Is it still up to date now?
i.e. Gensim is still the way for developing your own word embedings?
In the examples of the blog the list of sentences with separated words is of course a small one. you point out that when thre is a lot of data an iterator can be use.
That would be normally the case, i.e. a lot of data. The devil is in the details and I dont find in the net an example of code build as iterator passing sentences to word2vec model constructor.
The other thing that might be helpfull is how to know a bit about the practicalities of how to proceed when the calculation of the embedings are going to take many many hours, bucause it might be worth to save now an again what is already calculated just in case “SOMETHING HAPPEND”, am I right?
thanks
Yes.
Also Keras for learned embeddings in deep learning models:
https://machinelearningmastery.com/use-word-embedding-layers-deep-learning-keras/
Great suggestion, thanks.
Hi
I have a question about the plot that built based on W2V. It is not clear for me that what is axis?
They are a unit less, e.g. eigenvectors or a projection of the data.
Hi Jason,
First, I’d like to thank you about this useful tutorial.
I know the difference between both the cbow and the skip gram. However, I want to ask you about the difference between developing the embedding matrix in gensim using cbow and skip gram.
What do you mean exactly? The difference between the algorithms?
I mean the difference between using word2vec with cbow and using word2vec with skip gram
The difference is the choice of algorithm used to prepare the distributed representation.
Sir , what to do if a word is not present in one of these pre trained models?
It throws an error saying , word not in vocabulary
You can mark unknown words as “0” or unknown.
Hi Jason, Are there APIs available to use the word2vec (generated using gensim) with various sklearn classifiers (not keras neural networks with embedding layer) like MultinomialNB, MLPClassifier etc.?
Not as far as I know.
Hi Jason, thanks for the amazing tutorial. Is it possible to update your tutorial with a snippet that can visualize the GloVe embeddings in 2d without converting them to Word2Vec?
You could extract the vectors and create a PCA projection directly.
By the way, do you have a tutorial for skipgram with negative sampling? I read it is significantly better than GloVe.
I don’t believe so, sorry.
first of all, thank you very much for such an awesome article then I want to cluster the vocabularies based on similarities from top to bottom any idea is appreciated.
Sorry, I don’t have tutorials on clustering. Perhaps in the future.
Thank you for this amazing article. I am getting some warning in code. and while plotting, my corpus words are not visible.
getting warning on this line as:
X = model[model.wv.vocab]
DeprecationWarning: Call to deprecated
__getitem__(Method will be removed in 4.0.0, use self.wv.__getitem__() instead).and while plotting:
RuntimeWarning: Glyph 2414 missing from current font.
What I need to do to resolve it?
You can ignore them for now.
dear Jason thank you so much for a awesome explanation.
i have a doubt on:if we do in coding such as model = Word2Vec(sentences, min_count=4) and model = Word2Vec(sentences, min_count=3) will give the same result for vector representation of that example you have taken?
No, it is a stochastic method and will give different vectors each time it is run.
how could I convert my dataset to be in the same sentences format, I mean the senetences separated by column and each sentence in [], and the sentences words are tokenize?
This tutorial will help you prepare your data:
https://machinelearningmastery.com/clean-text-machine-learning-python/
I read in one of your articles how to print both predicted labels and actual labels, but I forgot in which one, could you please show me that portion of code, or that article..please?
thank you,
you are my inspirational
Sure, when you say labels, what are you referring to exactly?
Embeddings? Class labels?
class labels I want to see where the misclassification happens…
You can predict classes with model.predict_classes() then print the value.
Perhaps this will help:
https://machinelearningmastery.com/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
I trained my own word2vec model on my own dataset, I run the same code twice, in each time the vector of the same word has a different value, is this acceptable or not?
e.g. the word “country” appear in the first run with values
[-0.019637132 0.041940697 -0.06441503 0.0151868425 0.011437362 0.05516808 0.030604098 ….]
and second, run with values:
[-0.026120335 0.032587618 0.12853415 0.026889715 -0.02893926 0.013117478 0.06197646 …]
Yes, this is to be expected.
Why it is expected, I am looking to create my own word2vec model, like Glove and Google word2vec. However, if it is expected to get different vector for the word each time I run the code on the same dataset without any change in the code, why they make it general or universal?
I meant if Google and Glove run their code multiple times and they have got a different vector for the same word why they make their model general?
it seems that they have the same vector for the word each time, but I have extracted the wrong vector for my words…there is something wrong,
I followed exactly your way (4. Train word2vec Embedding) and at the end, I added this code to save the words and their corresponding vectors:
model.wv.save_word2vec_format(’embedding_word2vec_Mydata.txt’, binary=False)
and each time I run it I got a different vector for the same word, I feel like I missunderstand something …
sorry for this long question,
Thanks, prof.Jason
They are stochastic algorithms, they give a different result each time they are run, but the same general patterns on average.
The methods learn the general patterns in slightly different ways each time the code is run.
Hi Jason,
can you help me understand, when to use Word2Vec and for what purpose(i mean for cases like sentiment analysis, text classification).
and i also wanted to know how to convert word2vec into doc2vec in a simplest way.
this will be of great help to me.
thanks.
Word2Vec is a distributed representation for words, useful whenever you have words as input to your model.
I can’t help you with doc2vec, I don’ have examples yet sorry.
Hi Jason,
Do you have an example on how to train your own word embeddings on Glove model?
Thanks
Not at this stage.
I trained my own word2vec on 200000 sentences corpus, then I trained it on a 1 million sentence corpus, I am working on a classification problem using your tutorial, surprisingly the f1-score of my deep model remains the same… even though the corpus size becomes very large. what could be the problem?
Well done!
Perhaps the word2vec you trained does not add value to the model?
Hi,
How to use the created models using word2vec? I created a word2vec model but iam not able to find the syntax to find the score of other words by using this model. Can you explain me once.
What do you mean “the score”. a word2vec will return a vector for each word, not a score.
Do you have any tutorial of using word2vec with machine learning like SVM,LR..?
I don’t think so, off hand.
I need the source code. How can i download the code?
See this:
https://machinelearningmastery.com/faq/single-faq/how-do-i-copy-code-from-a-tutorial
hi, what if I only want to plot those words that occur at least n times overall sentences. Also how do I make the plot bigger such that you can actually see whats happening?
You can use an if-statement on the frequency counts of the words.
You can specify the size to matplotlib, perhaps check the API documentation.
How can I do the same if I store the glove file on s3?
Perhaps try it and see?
There’s a memory issue when you try to read the object the traditional way using
file.get()[‘Body’].read()
Will try some way to streamread it if possible
Good luck!
Hi jason, It would be very helpful for me if you give some examples in python to find semantic similarity between the medical terms. I am building disease predictor in nlp. For example,I want to find whether “fever” and “high temperature” or “fever” and “raise in temperature” are same. This is not possible with ordinary similarity measures. Please help me out. Eagerly expecting your reply. Thanks in advance
Why not start with euclidean distance between the word vectors?
Or if you mean because you have single word to multiple words, perhaps check the literature on word vectors to see how this case is handled? I don’t recall off hand sorry.
A word like “of ” do not exist in the model of google is it normal ?
Super common connecting words are often removed. They add little.
okay thank you
Dear Jason
Thanks for this interesting post. You mentioned “Rather than loading a large text document or corpus from file, we will work with a small, in-memory list of pre-tokenized sentences”. I run your code by loading the content of a text-file (each line with a sentence), but in this case, as the output put of print(words), letters are printed instead of words. Do you have any idea why it happens?
Sorry to hear that, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks. I know it is not reasonable to ask you debug our codes. Therefore I will do my best to find the error and I am sure I will.
Good luck!
Thanks for your positive energy. I solved the error by the help of stackoverflow! My mistake was using sentences = “” instead of sentences = [] before loading the content of my textfile into sentences variable.
Well done!
Hi Jason,
Thanks for this wonderful tutorial!
How can I use the below array you used above to train a neural network?
[ -4.61881841e-03 -4.88735968e-03 -3.19508743e-03 4.08568839e-03
-3.38211656e-03 1.93076557e-03 3.90265253e-03 -1.04349572e-03
4.14286414e-03 1.55219622e-03 3.85653134e-03 2.22428422e-03
-3.52565176e-03 2.82056746e-03 -2.11121864e-03 -1.38054823e-03
-1.12888147e-03 -2.87318649e-03 -7.99703528e-04 3.67874932e-03
2.68940022e-03 6.31021452e-04 -4.36326629e-03 2.38655557e-04
-1.94210222e-03 4.87691024e-03 -4.04118607e-03 -3.17813386e-03
4.94802603e-03 3.43150692e-03 -1.44031656e-03 4.25637932e-03
-1.15106850e-04 -3.73274647e-03 2.50349124e-03 4.28692997e-03
-3.57313151e-03 -7.24728088e-05 -3.46099050e-03 -3.39612062e-03
3.54845310e-03 1.56780297e-03 4.58260969e-04 2.52689526e-04
3.06256465e-03 2.37558200e-03 4.06933809e-03 2.94650183e-03
-2.96231941e-03 -4.47433954e-03 2.89590308e-03 -2.16034567e-03
-2.58548348e-03 -2.06163677e-04 1.72605237e-03 -2.27384618e-04
-3.70194600e-03 2.11557443e-03 2.03793868e-03 3.09839356e-03
-4.71800892e-03 2.32995977e-03 -6.70911541e-05 1.39375112e-03
-3.84263694e-03 -1.03898917e-03 4.13251948e-03 1.06330717e-03
1.38514000e-03 -1.18144893e-03 -2.60811858e-03 1.54952740e-03
2.49916781e-03 -1.95435272e-03 8.86975031e-05 1.89820060e-03
-3.41996481e-03 -4.08187555e-03 5.88635216e-04 4.13103355e-03
-3.25899688e-03 1.02130906e-03 -3.61028523e-03 4.17646067e-03
4.65870230e-03 3.64110398e-04 4.95479070e-03 -1.29743712e-03
-5.03367570e-04 -2.52546836e-03 3.31060472e-03 -3.12870182e-03
-1.14580349e-03 -4.34387522e-03 -4.62882593e-03 3.19007039e-03
2.88707414e-03 1.62976081e-04 -6.05802808e-04 -1.06368808e-03]
What do you mean?
hi
small doubt about Gensim train words some times how to handle this words machine learning
,artificial intelligence words how to spaces handling?
please any one help me
model.wv.most_similar(“Artificial intelligence”)
KeyError: “word ‘Artificial intelligence’ not in vocabulary”
how two words handling please help me
We typically remove spaces and just model the words.
Hi Jason,
I experimented with your code using the gensim library, the pca dimensional reduction and the visualization. I modified it a bit and fed it with the german play ‘Faust I’ from Goethe and visualized some interesting words like Himmel (heaven), Hölle (hell), Gott (god), Teufel (devil) and so on and was curious, what kind of neighbor relations I would see. First of all I was surprised that the 2d mapping changed on every run, even changing what was lying next to each other. So, I changed the pca command by defining the solver: pca = PCA(n_components=2, svd_solver=’full’). This led to more stability in the neighbor relations, but did not give a unique result. Actually, I do not really understand, why this is so.
Generally, I was a bit disappointed that my expectations like finding the devil close to the hell did not work out. Obviously, the maths behind the vectorization is not as philosophical as I hoped it would be.
Anyway, great tutorial! Thanks!
Nice investigation!
Perhaps the dataset is too small or the choice of the configuration for the model needs tuning to give a more stable model over multiple runs.
Best things are always free…
Thank you Dr Jason. You explain the things in a very simple and effective way.
Thanks!
Can you convert the tutorial to GenSim 4?
Here are some things that needs to be updated:
#GenSim 3
#words = list(model.wv.vocab)
#GenSim 4
words = model.wv.index_to_key
#GenSim 3
#print(model[‘sentence’])
#GenSim 4
normed_vector = model.wv.get_vector(“sentence”, norm=True)
# GenSim 3
#X = model[model.wv.vocab]
# GenSim 4
X = model.wv.get_normed_vectors()
Here is an example:
https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
make a tutorial on fasttext for multilingual sentimental anaklysis
Thanks for the suggestion.
Dear Jason,
I wonder if I can select results from the pre-trained model Glove and Google for a specific input year? If not, Can I train the Glove on my data (for a specific year)?
Probably not. For training your own embedding, please see if this helps: https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
But you would need a very powerful computer to make one on a par with Glove
This article is from 2017 but I hope is not too late,
thanks so much for this amazing and useful article @Jason Brownlee!!!
Hi Fede…The content is still very relevant!